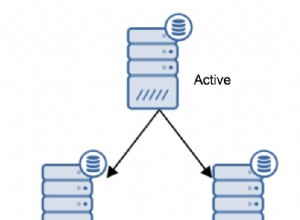
Introduzido pela primeira vez no SQL Server 2017 Enterprise Edition, uma junção adaptável permite uma transição de tempo de execução de uma junção de hash em modo de lote para uma junção indexada de loops aninhados correlacionados em modo de linha (aplicar) em tempo de execução. Para resumir, vou me referir a uma "junção indexada de loops aninhados correlacionados" como uma aplicação ao longo do restante deste artigo. Se você precisar de uma atualização sobre a diferença entre loops aninhados e aplicar, consulte meu artigo anterior.
A transição de uma junção adaptável de uma junção de hash para aplicação no tempo de execução depende de um valor rotulado como Adaptive Threshold Rows na União adaptável operador de plano de execução. Este artigo mostra como funciona uma junção adaptativa, inclui detalhes do cálculo de limite e aborda as implicações de algumas das escolhas de design feitas.
Introdução
Uma coisa que eu quero que você tenha em mente ao longo desta peça é uma junção adaptável sempre começa a ser executado como uma junção de hash no modo de lote. Isso é verdade mesmo se o plano de execução indicar que a junção adaptativa espera ser executada como uma aplicação de modo de linha.
Como qualquer junção de hash, uma junção adaptativa lê todas as linhas disponíveis em sua entrada de compilação e copia os dados necessários em uma tabela de hash. O tipo de modo de lote da junção de hash armazena essas linhas em um formato otimizado e as particiona usando uma ou mais funções de hash. Depois que a entrada de compilação for consumida, a tabela de hash será totalmente preenchida e particionada, pronta para que a junção de hash comece a verificar as linhas do lado do probe para correspondências.
Este é o ponto em que uma junção adaptativa toma a decisão de prosseguir com a junção de hash do modo de lote ou de fazer a transição para uma aplicação de modo de linha. Se o número de linhas na tabela de hash for menor que o limite valor, a junção muda para uma aplicação; caso contrário, a junção continua como uma junção de hash começando a ler as linhas da entrada do probe.
Se ocorrer uma transição para uma junção de aplicação, o plano de execução não relê as linhas usadas para preencher a tabela de hash para conduzir a operação de aplicação. Em vez disso, um componente interno conhecido como leitor de buffer adaptável expande as linhas já armazenadas na tabela de hash e as disponibiliza sob demanda para a entrada externa do operador apply. Há um custo associado ao leitor de buffer adaptável, mas é muito menor do que o custo de rebobinar completamente a entrada de compilação.
Escolhendo uma junção adaptável
A otimização de consulta envolve um ou mais estágios de exploração lógica e implementação física de alternativas. Em cada estágio, quando o otimizador explora as opções físicas de um lógico join, ele pode considerar as alternativas de junção de hash de modo de lote e aplicação de modo de linha.
Se uma dessas opções de junção física fizer parte da solução mais barata encontrada durante o estágio atual—e o outro tipo de junção pode fornecer as mesmas propriedades lógicas necessárias. O otimizador marca o grupo de junção lógica como potencialmente adequado para uma junção adaptativa. Caso contrário, a consideração de uma junção adaptativa termina aqui (e nenhum evento estendido de junção adaptável é acionado).
A operação normal do otimizador significa que a solução mais barata encontrada incluirá apenas uma das opções de junção física - hash ou apply, a que tiver o menor custo estimado. A próxima coisa que o otimizador faz é construir e custar uma nova implementação do tipo de junção que não era escolhido como mais barato.
Como a fase de otimização atual já terminou com uma solução mais barata encontrada, uma rodada especial de exploração e implementação de grupo único é realizada para a junção adaptativa. Por fim, o otimizador calcula o limite adaptativo .
Se algum dos trabalhos anteriores não for bem-sucedido, o evento estendido adaptive_join_skipped será acionado com um motivo.
Se o processamento da junção adaptável for bem-sucedido, uma Concat O operador é adicionado ao plano interno acima do hash e aplica alternativas com o leitor de buffer adaptável e quaisquer adaptadores de modo de lote/linha necessários. Lembre-se, apenas uma das alternativas de junção será executada em tempo de execução, dependendo do número de linhas realmente encontradas em comparação com o limite adaptativo.
O Concat operador e alternativas individuais de hash/apply normalmente não são mostradas no plano de execução final. Em vez disso, recebemos uma única União adaptável operador. Esta é apenas uma decisão de apresentação, o Concat e junções ainda estão presentes no código executado pelo mecanismo de execução do SQL Server. Você pode encontrar mais detalhes sobre isso nas seções Apêndice e Leitura Relacionada deste artigo.
O limite adaptativo
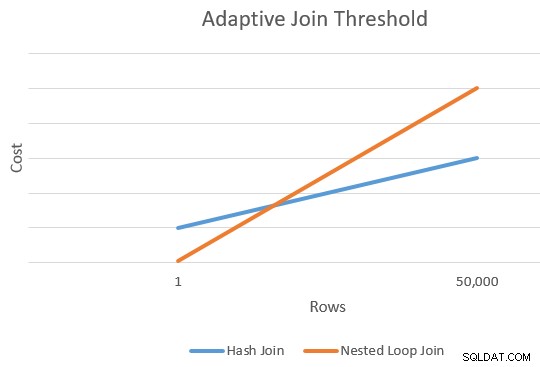
Uma aplicação geralmente é mais barata do que uma junção de hash para um número menor de linhas de condução. A junção de hash tem um custo de inicialização extra para construir sua tabela de hash, mas um custo por linha menor quando começa a sondar as correspondências.
Geralmente, há um ponto em que o custo estimado de uma junção de aplicação e hash será igual. Essa ideia foi bem ilustrada por Joe Sack em seu artigo, Introdução às junções adaptáveis do modo de lote:
Cálculo do limite
Neste ponto, o otimizador tem uma única estimativa para o número de linhas que entram na entrada de construção da junção de hash e aplicam alternativas. Ele também tem o custo estimado do hash e aplica os operadores como um todo.
Isso nos dá um único ponto na extremidade direita das linhas laranja e azul no diagrama acima. O otimizador precisa de outro ponto de referência para cada tipo de junção para que possa “desenhar as linhas” e encontrar a interseção (não desenha linhas literalmente, mas você entendeu).
Para encontrar um segundo ponto para as linhas, o otimizador solicita que as duas junções produzam uma nova estimativa de custo com base em uma cardinalidade de entrada diferente (e hipotética). Se a primeira estimativa de cardinalidade tiver mais de 100 linhas, ele solicitará que as junções estimem novos custos para uma linha. Se a cardinalidade original for menor ou igual a 100 linhas, o segundo ponto é baseado em uma cardinalidade de entrada de 10.000 linhas (portanto, há um intervalo decente o suficiente para extrapolar).
De qualquer forma, o resultado são dois custos e contagens de linhas diferentes para cada tipo de junção, permitindo que as linhas sejam “desenhadas”.
A Fórmula da Interseção
Encontrar a interseção de duas linhas com base em dois pontos para cada linha é um problema com várias soluções bem conhecidas. O SQL Server usa um baseado em determinantes conforme descrito na Wikipedia:
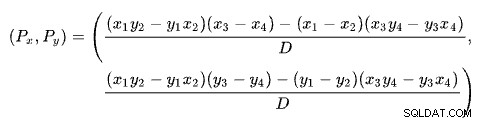
Onde:
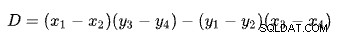
A primeira linha é definida pelos pontos (x1 , s1 ) e (x2 , e2 ). A segunda linha é dada pelos pontos (x3 , e3 ) e (x4 , e4 ). A interseção está em (Px , Ps ).
Nosso esquema tem o número de linhas no eixo x e o custo estimado no eixo y. Estamos interessados no número de linhas onde as linhas se cruzam. Isso é dado pela fórmula para Px . Se quiséssemos saber o custo estimado no cruzamento, seria Py .
Para Px linhas, os custos estimados das soluções de aplicação e junção de hash seriam iguais. Este é o limite adaptativo que precisamos.
Um exemplo trabalhado
Aqui está um exemplo usando o banco de dados de amostra AdventureWorks2017 e o seguinte truque de indexação de Itzik Ben-Gan para obter consideração incondicional da execução do modo de lote:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123; O plano de execução mostra uma junção adaptativa com um limite de 1502,07 linhas:
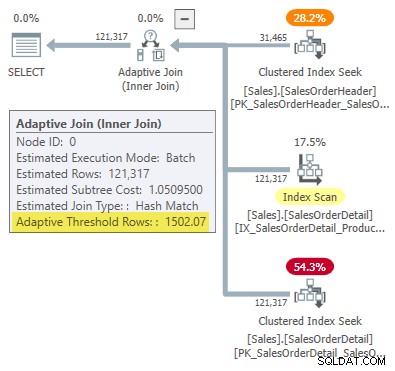
O número estimado de linhas que impulsionam a junção adaptativa é 31.465 .
Custos de adesão
Nesse caso simplificado, podemos encontrar os custos estimados de subárvore para o hash e aplicar alternativas de junção usando dicas:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1); 
-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1); 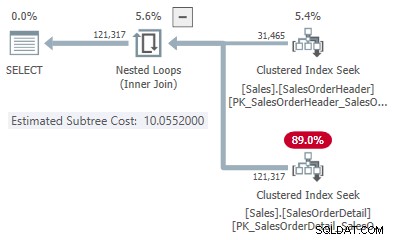
Isso nos dá um ponto na linha para cada tipo de junção:
- 31.465 linhas
- Custo de hash 1,05083
- Aplicar custo 10,0552
O segundo ponto na linha
Como o número estimado de linhas é superior a 100, os segundos pontos de referência vêm de estimativas internas especiais baseadas em uma linha de entrada de junção. Infelizmente, não há uma maneira fácil de obter os números de custo exatos para esse cálculo interno (falarei mais sobre isso em breve).
Por enquanto, mostrarei apenas os números de custo (usando a precisão interna completa em vez dos seis algarismos significativos apresentados nos planos de execução):
- Uma linha (cálculo interno)
- Custo de hash 0,999027422729
- Aplicar custo 0,547927305023
- 31.465 linhas
- Custo de hash 1,05082787359
- Aplicar custo 10.0552890166
Como esperado, a junção de aplicação é mais barata que o hash para uma cardinalidade de entrada pequena, mas muito mais cara para a cardinalidade esperada de 31.465 linhas.
O cálculo da interseção
Conectar esses números de cardinalidade e custo à fórmula de interseção de linha fornece o seguinte:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Arredondado para seis algarismos significativos, este resultado corresponde a 1502,07 linhas mostradas no plano de execução de junção adaptável:
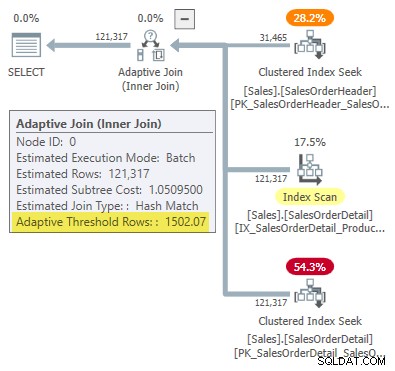
Defeito ou design?
Lembre-se, o SQL Server precisa de quatro pontos para “desenhar” a contagem de linhas versus as linhas de custo para encontrar o limite de junção adaptável. No presente caso, isso significa encontrar estimativas de custo para as cardinalidades de uma linha e 31.465 linhas para implementações de aplicação e junção de hash.
O otimizador chama uma rotina chamada
sqllang!CuNewJoinEstimate para calcular esses quatro custos para uma junção adaptativa. Infelizmente, não há sinalizadores de rastreamento ou eventos estendidos para fornecer uma visão geral útil dessa atividade. Os sinalizadores de rastreamento normais usados para investigar o comportamento do otimizador e os custos de exibição não funcionam aqui (consulte o Apêndice se estiver interessado em mais detalhes). A única maneira de obter as estimativas de custo de uma linha é anexar um depurador e definir um ponto de interrupção após a quarta chamada para
CuNewJoinEstimate no código para sqllang!CardSolveForSwitch . Eu usei o WinDbg para obter essa pilha de chamadas no SQL Server 2019 CU12:
Nesse ponto do código, os custos de pontos flutuantes de precisão dupla são armazenados em quatro locais de memória apontados por endereços em
rsp+b0 , rsp+d0 , rsp+30 e rsp+28 (onde rsp é um registrador de CPU e os deslocamentos estão em hexadecimal):
Os números de custo de subárvore do operador mostrados correspondem aos usados na fórmula de cálculo de limite de junção adaptável.
Sobre essas estimativas de custo de uma linha
Você deve ter notado que os custos estimados de subárvore para as junções de uma linha parecem bastante altos para a quantidade de trabalho envolvida na junção de uma linha:
- Uma linha
- Custo de hash 0,999027422729
- Aplicar custo 0,547927305023
Se você tentar produzir planos de execução de entrada de uma linha para a junção de hash e aplicar exemplos, verá muito custos de subárvore estimados mais baixos na junção do que os mostrados acima. Da mesma forma, executar a consulta original com uma meta de linha de um (ou o número de linhas de saída de junção esperadas para uma entrada de uma linha) também produzirá um custo estimado maneira inferior ao mostrado.
O motivo é o
CuNewJoinEstimate rotina estima a uma linha caso de uma forma que eu acho que a maioria das pessoas não acharia intuitivo. O custo final é composto por três componentes principais:
- O custo da subárvore de entrada da compilação
- O custo local da associação
- O custo da subárvore de entrada do probe
Os itens 2 e 3 dependem do tipo de junção. Para uma junção de hash, eles contabilizam o custo de ler todas as linhas da entrada do probe, combinando-as (ou não) com uma linha na tabela de hash e passando os resultados para o próximo operador. Para uma aplicação, os custos cobrem uma busca na entrada mais baixa para a junção, o custo interno da própria junção e o retorno das linhas correspondentes ao operador pai.
Nada disso é incomum ou surpreendente.
A surpresa de custo
A surpresa vem do lado da construção da junção (item 1 da lista). Pode-se esperar que o otimizador faça algum cálculo sofisticado para dimensionar o custo da subárvore já calculado para 31.465 linhas para uma linha média, ou algo assim.
Na verdade, as estimativas de junção de hash e aplicação de uma linha simplesmente usam todo o custo da subárvore para o original estimativa de cardinalidade de 31.465 linhas. Em nosso exemplo em execução, essa "subárvore" é o 0,54456 custo da busca de índice clusterizado no modo de lote na tabela de cabeçalho:
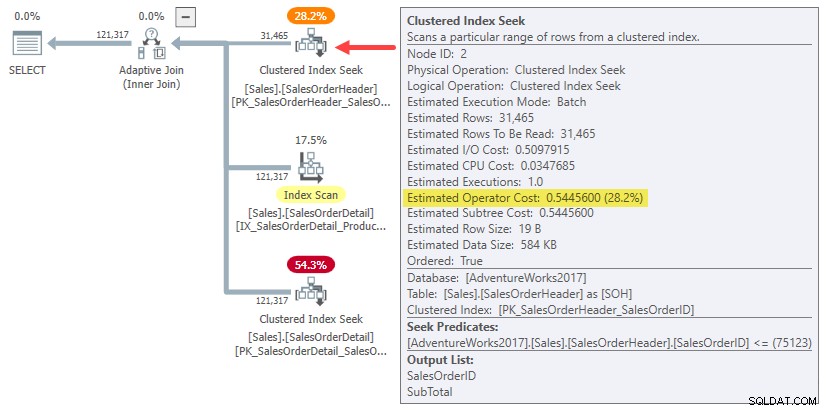
Para ser claro:os custos estimados do lado da construção para as alternativas de junção de uma linha usam um custo de entrada calculado para 31.465 linhas. Isso deve lhe parecer um pouco estranho.
Como lembrete, os custos de uma linha calculados por
CuNewJoinEstimate foram os seguintes:- Uma linha
- Custo de hash 0,999027422729
- Aplicar custo 0,547927305023
Você pode ver que o custo total de aplicação (~0,54793) é dominado pelo 0,54456 custo da subárvore do lado da construção, com uma pequena quantia extra para a única busca do lado interno, processando o pequeno número de linhas resultantes dentro da junção e passando-as para o operador pai.
O custo estimado de junção de hash de uma linha é mais alto porque o lado da sondagem do plano consiste em uma varredura de índice completa, em que todas as linhas resultantes devem passar pela junção. O custo total da junção de hash de uma linha é um pouco menor que o custo original de 1,05095 para o exemplo de 31.465 linhas porque agora há apenas uma linha na tabela de hash.
Implicações
Seria de esperar que uma estimativa de junção de uma linha fosse baseada, em parte, no custo de entrega de uma linha para a entrada de junção de acionamento. Como vimos, esse não é o caso de uma junção adaptativa:as alternativas de aplicação e de hash estão sobrecarregadas com o custo total estimado para 31.465 linhas. O restante da junção custa praticamente como seria de esperar para uma entrada de compilação de uma linha.
Esse arranjo intuitivamente estranho é o motivo pelo qual é difícil (talvez impossível) mostrar um plano de execução que reflita os custos calculados. Precisaríamos construir um plano entregando 31.465 linhas para a entrada de junção superior, mas custando a própria junção e sua entrada interna como se apenas uma linha estivesse presente. Uma pergunta difícil.
O efeito de tudo isso é elevar o ponto mais à esquerda em nosso diagrama de linhas de interseção no eixo y. Isso afeta a inclinação da linha e, portanto, o ponto de interseção.
Outro efeito prático é que o limite de junção adaptável calculado agora depende da estimativa de cardinalidade original na entrada de compilação de hash, conforme observado por Joe Obbish em sua postagem de blog de 2017. Por exemplo, se alterarmos o
WHERE cláusula na consulta de teste para SOH.SalesOrderID <= 55000 , o limite adaptativo reduz de 1502,07 para 1259,8 sem alterar o hash do plano de consulta. Mesmo plano, limite diferente. Isso ocorre porque, como vimos, a estimativa interna de custo de uma linha depende do custo de entrada de construção para a estimativa de cardinalidade original. Isso significa que diferentes estimativas iniciais do lado da construção darão um “impulso” diferente do eixo y para a estimativa de uma linha. Por sua vez, a linha terá uma inclinação diferente e um ponto de interseção diferente.
A intuição sugere que a estimativa de uma linha para a mesma junção deve sempre fornecer o mesmo valor, independentemente da outra estimativa de cardinalidade na linha (dada a mesma junção exata com as mesmas propriedades e tamanhos de linha, tem uma relação quase linear entre direcionar linhas e custo). Este não é o caso de uma junção adaptativa.
Por Design?
Posso dizer com segurança o que o SQL Server faz ao calcular o limite de junção adaptável. Não tenho informações especiais sobre por que ele faz assim.
Ainda assim, existem algumas razões para pensar que esse arranjo é deliberado e surgiu após a devida consideração e feedback dos testes. O restante desta seção abrange alguns dos meus pensamentos sobre esse aspecto.
Uma junção adaptável não é uma escolha direta entre uma junção de hash de modo de aplicação normal e em lote. Uma junção adaptativa sempre começa preenchendo totalmente a tabela de hash. Somente quando este trabalho estiver concluído é tomada a decisão de mudar para uma implementação de aplicação ou não.
A essa altura, já incorremos em custos potencialmente significativos ao preencher e particionar a junção de hash na memória. Isso pode não importar muito para o caso de uma linha, mas se torna progressivamente mais importante à medida que a cardinalidade aumenta. O “impulso” inesperado pode ser uma maneira de incorporar essas realidades ao cálculo, mantendo um custo computacional razoável.
O modelo de custo do SQL Server tem sido um pouco tendencioso contra a junção de loops aninhados, sem dúvida com alguma justificativa. Mesmo o caso de aplicação indexado ideal pode ser lento na prática se os dados necessários ainda não estiverem na memória e o subsistema de E/S não for flash, especialmente com um padrão de acesso aleatório. Quantidades limitadas de memória e E/S lentas não serão totalmente desconhecidas para usuários de mecanismos de banco de dados baseados em nuvem de baixo custo, por exemplo.
É possível que testes práticos em tais ambientes revelaram que uma junção adaptativa com custo intuitivo era muito rápida para fazer a transição para uma aplicação. A teoria às vezes só é ótima na teoria.
Ainda assim, a situação atual não é ideal; armazenar em cache um plano com base em uma estimativa de cardinalidade excepcionalmente baixa produzirá uma junção adaptativa muito mais relutante em mudar para uma aplicação do que seria com uma estimativa inicial maior. Essa é uma variedade do problema de sensibilidade de parâmetros, mas será uma nova consideração desse tipo para muitos de nós.
Agora, também é possível usar o custo total da subárvore de entrada de construção para o ponto mais à esquerda das linhas de custo de interseção é simplesmente um erro ou descuido não corrigido. Meu sentimento é que a implementação atual é provavelmente um compromisso prático deliberado, mas você precisaria de alguém com acesso aos documentos de design e código-fonte para ter certeza.
Resumo
Uma junção adaptável permite que o SQL Server faça a transição de uma junção de hash de modo de lote para uma aplicação após a tabela de hash ser totalmente preenchida. Ele toma essa decisão comparando o número de linhas na tabela de hash com um limite adaptativo pré-calculado.
O limite é calculado prevendo onde os custos de aplicação e junção de hash são iguais. Para encontrar esse ponto, o SQL Server produz uma segunda estimativa de custo de junção interna para uma cardinalidade de entrada de compilação diferente — normalmente, uma linha.
Surpreendentemente, o custo estimado para a estimativa de uma linha inclui o custo total da subárvore do lado da construção para a estimativa de cardinalidade original (não dimensionada para uma linha). Isso significa que o valor do limite depende da estimativa de cardinalidade original na entrada de compilação.
Consequentemente, uma junção adaptativa pode ter um valor de limite inesperadamente baixo, o que significa que a junção adaptativa tem muito menos probabilidade de sair de uma junção de hash. Não está claro se esse comportamento é por design.
Leitura Relacionada
- Apresentando as associações adaptáveis do modo em lote por Joe Sack
- Noções básicas sobre Adaptive Joins na documentação do produto
- Adaptive Join Internals por Dima Pilugin
- Como funcionam as associações adaptáveis do modo em lote? sobre Database Administrators Stack Exchange por Erik Darling
- Uma regressão de junção adaptável por Joe Obbish
- Se você deseja junções adaptáveis, precisa de índices mais amplos e é maior melhor? por Erik Darling
- Sniffing de parâmetros:Adaptive Joins por Brent Ozar
- Perguntas e respostas sobre processamento inteligente de consultas por Joe Sack
Apêndice
Esta seção abrange alguns aspectos da junção adaptativa que eram difíceis de incluir no texto principal de maneira natural.
O plano adaptável expandido
Você pode tentar ver uma representação visual do plano interno usando o sinalizador de rastreamento não documentado 9415, conforme fornecido por Dima Pilugin em seu excelente artigo interno de junção adaptativa vinculado acima. Com este sinalizador ativo, o plano de junção adaptável para nosso exemplo em execução se torna o seguinte:
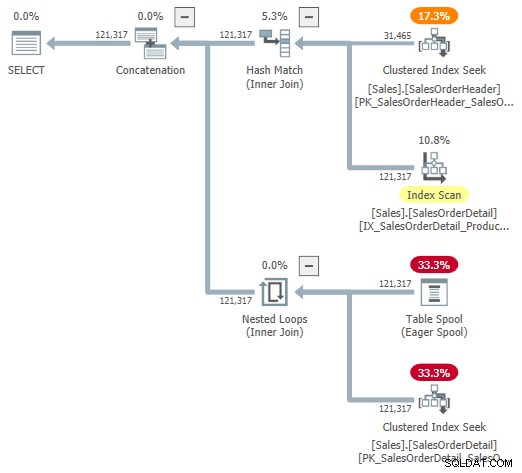
Essa é uma representação útil para ajudar na compreensão, mas não é totalmente precisa, completa ou consistente. Por exemplo, o Table Spool não existe. É uma representação padrão para o leitor de buffer adaptável lendo linhas diretamente da tabela de hash do modo de lote.
As propriedades do operador e as estimativas de cardinalidade também estão um pouco espalhadas. A saída do leitor de buffer adaptável (“spool”) deve ter 31.465 linhas, não 121.317. O custo da subárvore da aplicação é limitado incorretamente pelo custo do operador pai. Isso é normal para o showplan, mas não faz sentido em um contexto de junção adaptável.
Existem outras inconsistências também — muitas para listar de maneira útil — mas isso pode acontecer com sinalizadores de rastreamento não documentados. O plano expandido mostrado acima não se destina ao uso por usuários finais, portanto, talvez não seja totalmente surpreendente. A mensagem aqui é não confiar muito nos números e propriedades mostrados neste formulário não documentado.
Também devo mencionar que o operador de plano de junção adaptável padrão finalizado não é totalmente sem seus próprios problemas de consistência. Estes decorrem praticamente exclusivamente dos detalhes ocultos.
Por exemplo, as propriedades de junção adaptável exibidas vêm de uma mistura do Concat subjacente , Hash Join e Aplicar operadores. Você pode ver uma execução de modo de lote de relatórios de junção adaptável para junção de loops aninhados (o que é impossível), e o tempo decorrido mostrado é realmente copiado do Concat oculto , não a junção específica executada em tempo de execução.
Os suspeitos habituais
Nós podemos obtenha algumas informações úteis dos tipos de sinalizadores de rastreamento não documentados normalmente usados para examinar a saída do otimizador. Por exemplo:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Saída (fortemente editada para facilitar a leitura):
*** Árvore de saída:***
PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Custo=1,05095
- PhyOp_Concat (lote) Card=121317 Custo=1,05325
- PhyOp_HashJoinx_jtInner (lote) Cartão=121317 Custo=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Custo=0,54456
- PhyOp_Filter(lote) Cartão=121317 Custo=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Custo=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Cartão=121317 Custo=10,0798
- PhyOp_Apply Card=121317 Custo=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Custo=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Custo=0,54456 [** 3 **]
- PhyOp_Filter Card=3.85562 Custo=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 Custo=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Custo=0,544623
- PhyOp_Apply Card=121317 Custo=10,0553
Isso fornece algumas informações sobre os custos estimados para o caso de cardinalidade total com hash e aplica alternativas sem escrever consultas separadas e usar dicas. Conforme mencionado no texto principal, esses sinalizadores de rastreamento não são eficazes em
CuNewJoinEstimate , portanto, não podemos ver diretamente os cálculos repetidos para o caso de 31.465 linhas ou qualquer um dos detalhes das estimativas de uma linha dessa maneira. Mesclar Join e Row Mode Hash Join
As junções adaptativas oferecem apenas uma transição da junção de hash do modo de lote para a aplicação do modo de linha. Para saber os motivos pelos quais a junção de hash no modo de linha não é compatível, consulte as perguntas e respostas do processamento de consulta inteligente na seção de leitura relacionada. Em suma, acredita-se que as junções de hash no modo de linha seriam muito propensas a regressões de desempenho.
Alternar para uma junção de mesclagem de modo de linha seria outra opção, mas o otimizador não considera isso no momento. Pelo que entendi, é improvável que seja expandido nessa direção no futuro.
Algumas das considerações são as mesmas para a junção de hash no modo de linha. Além disso, os planos de junção de mesclagem tendem a ser menos facilmente intercambiáveis com a junção de hash, mesmo se nos limitarmos à junção de mesclagem indexada (sem classificação explícita).
Há também uma distinção muito maior entre hash e apply do que entre hash e merge. Tanto o hash quanto o merge são adequados para entradas maiores e o apply é mais adequado para uma entrada de condução menor. A junção de mesclagem não é tão facilmente paralelizada quanto a junção de hash e não é dimensionada tão bem com o aumento da contagem de encadeamentos.
Considerando que a motivação para junções adaptáveis é lidar melhor com significativamente tamanhos de entrada variados - e apenas a junção de hash suporta processamento em modo de lote - a escolha de hash em lote versus aplicação de linha é a mais natural. Finalmente, ter três opções de junção adaptativa complicaria significativamente o cálculo do limite para ganho potencialmente pequeno.