A replicação desempenha um papel crucial na manutenção da alta disponibilidade. Os servidores podem falhar, o sistema operacional ou o software de banco de dados pode precisar ser atualizado. Isso significa reorganizar as funções de servidor e mover os links de replicação, mantendo a consistência dos dados em todos os bancos de dados. Mudanças de topologia serão necessárias e existem diferentes maneiras de realizá-las.
Promovendo um servidor em espera
Indiscutivelmente, esta é a operação mais comum que você precisará executar. Há vários motivos - por exemplo, manutenção de banco de dados no servidor primário que afetaria a carga de trabalho de maneira inaceitável. Pode haver tempo de inatividade planejado devido a algumas operações de hardware. A falha do servidor primário que o torna inacessível ao aplicativo. Esses são todos os motivos para realizar um failover, planejado ou não. Em todos os casos, você terá que promover um dos servidores em espera para se tornar um novo servidor primário.
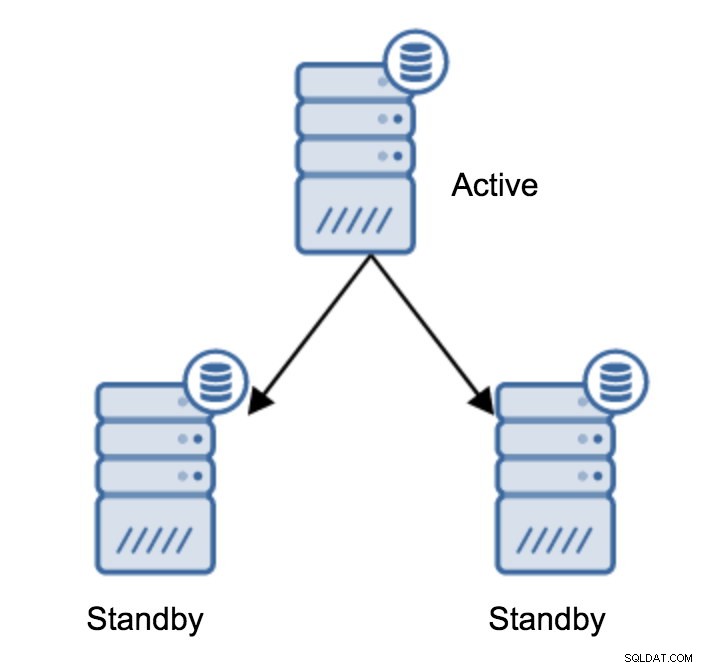
Para promover um servidor em espera, você precisa executar:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
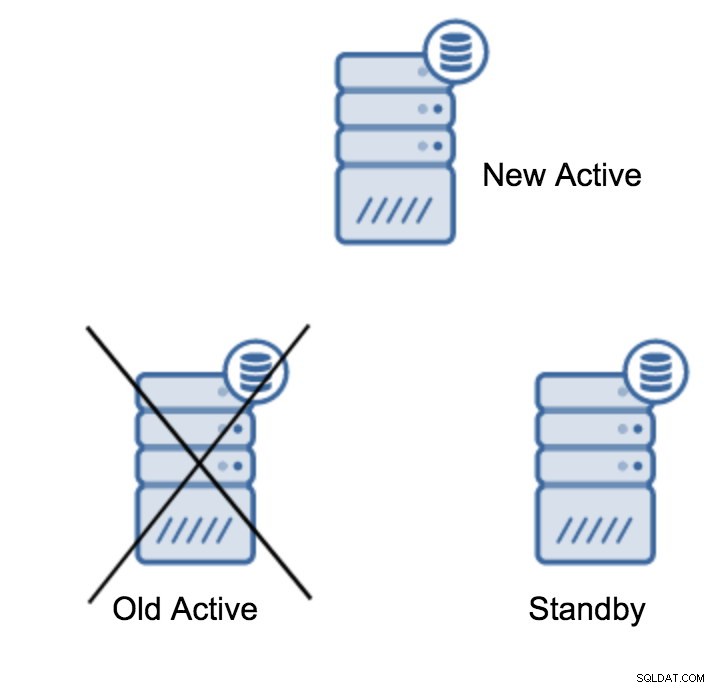
server promotedÉ fácil executar este comando, mas primeiro certifique-se de evitar qualquer perda de dados. Se estamos falando de um cenário de “servidor primário inativo”, talvez você não tenha muitas opções. Se for uma manutenção planejada, é possível se preparar para ela. Você precisa interromper o tráfego no servidor primário e, em seguida, verificar se o servidor em espera recebeu e aplicou todos os dados. Isso pode ser feito no servidor em espera, usando a consulta abaixo:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Quando tudo estiver bem, você pode parar o servidor primário antigo e promover o servidor em espera.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
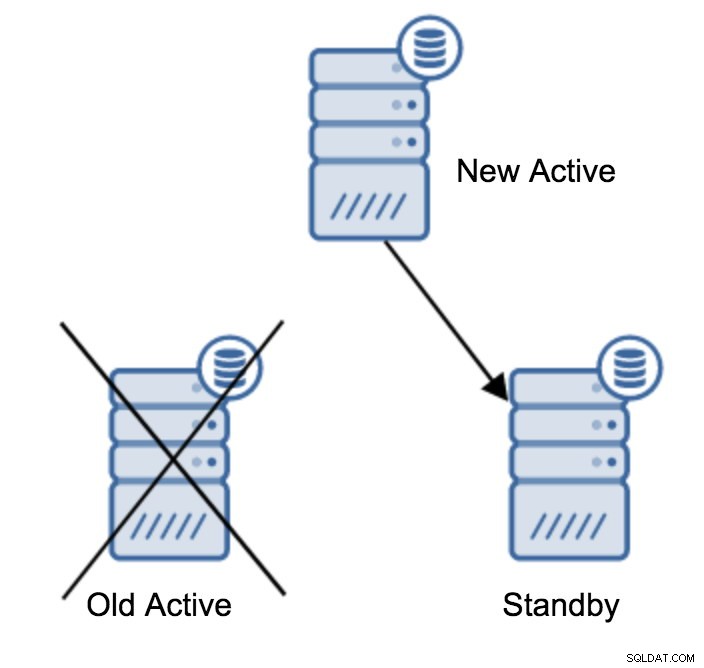
Rescravizando um servidor em espera de um novo servidor principal
Você pode ter mais de um servidor em espera escravizando seu servidor primário. Afinal, os servidores em espera são úteis para descarregar o tráfego somente leitura. Depois de promover um servidor em espera para um novo servidor primário, você precisa fazer algo sobre os servidores em espera restantes que ainda estão conectados (ou que estão tentando se conectar) ao servidor primário antigo. Infelizmente, você não pode simplesmente alterar o recovery.conf e conectá-lo ao novo servidor primário. Para conectá-los, primeiro você precisa reconstruí-los. Existem dois métodos que você pode tentar aqui:backup básico padrão ou pg_rewind.
Não entraremos em detalhes sobre como fazer um backup básico - nós o abordamos em nossa postagem de blog anterior, que se concentrou em fazer backups e restaurá-los no PostgreSQL. Se você usar o ClusterControl, também poderá usá-lo para criar um backup básico:
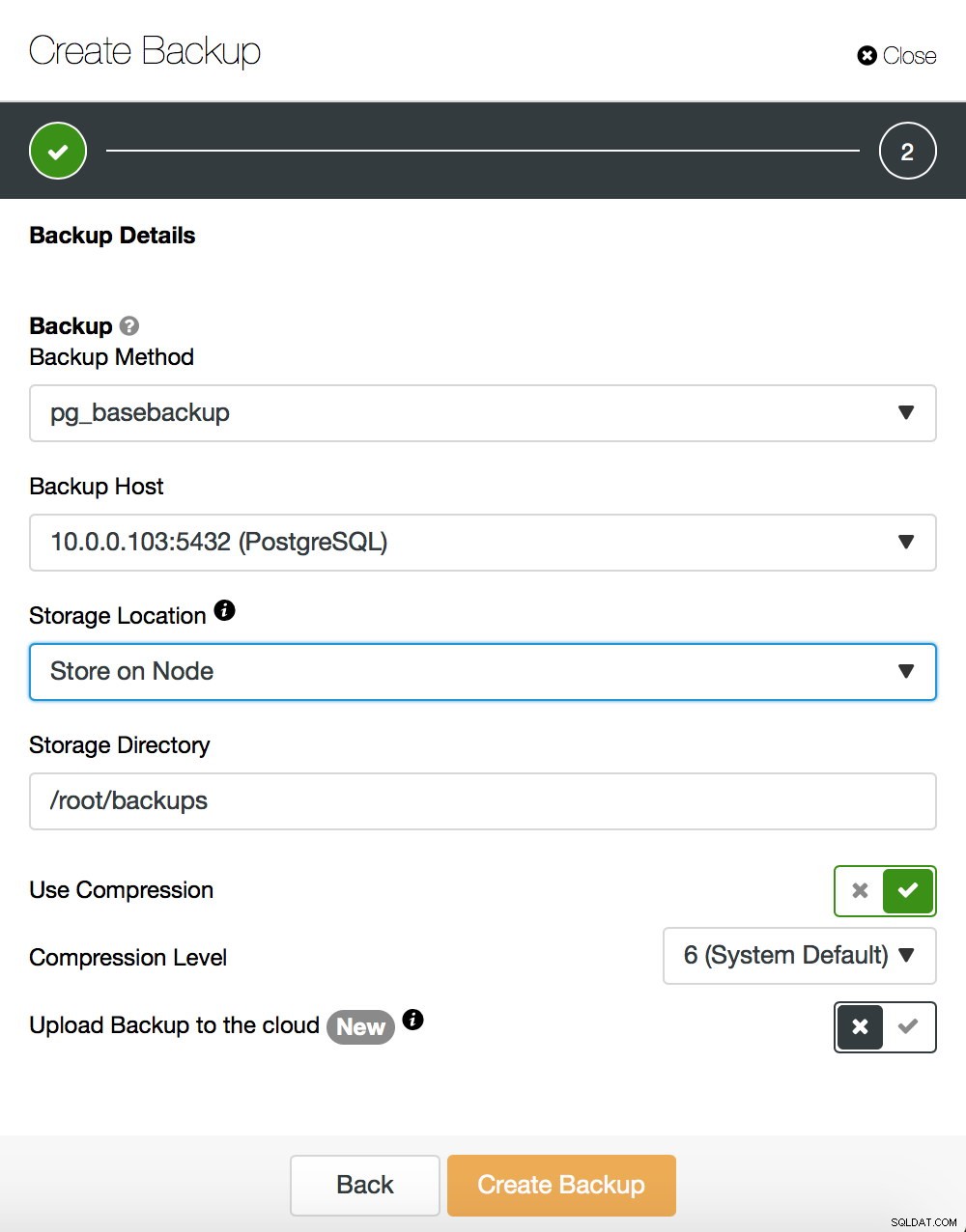
Por outro lado, vamos dizer algumas palavras sobre pg_rewind. A principal diferença entre os dois métodos é que o backup básico cria uma cópia completa do conjunto de dados. Se estamos falando de conjuntos de dados pequenos, pode ser bom, mas para conjuntos de dados com centenas de gigabytes de tamanho (ou até maiores), isso pode se tornar rapidamente um problema. No final, você quer ter seus servidores em espera rapidamente funcionando - para descarregar seu servidor ativo e ter outro em espera para fazer failover, caso seja necessário. O Pg_rewind funciona de forma diferente - ele copia apenas os blocos que foram modificados. Em vez de copiar tudo, ele copia apenas as alterações, acelerando bastante o processo. Vamos supor que seu novo mestre tenha um IP de 10.0.0.103. É assim que você pode executar pg_rewind. Observe que você precisa parar o servidor de destino - o PostgreSQL não pode ser executado lá.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Isso fará um ensaio , testando o processo, mas não fazendo nenhuma alteração. Se tudo estiver bem, tudo o que você terá que fazer será executá-lo novamente, desta vez sem o parâmetro ‘--dry-run’. Feito isso, o último passo restante será criar um arquivo recovery.conf, que apontará para o novo mestre. Pode parecer assim:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Agora você está pronto para iniciar seu servidor em espera e ele será replicado no novo servidor ativo.
Replicação encadeada
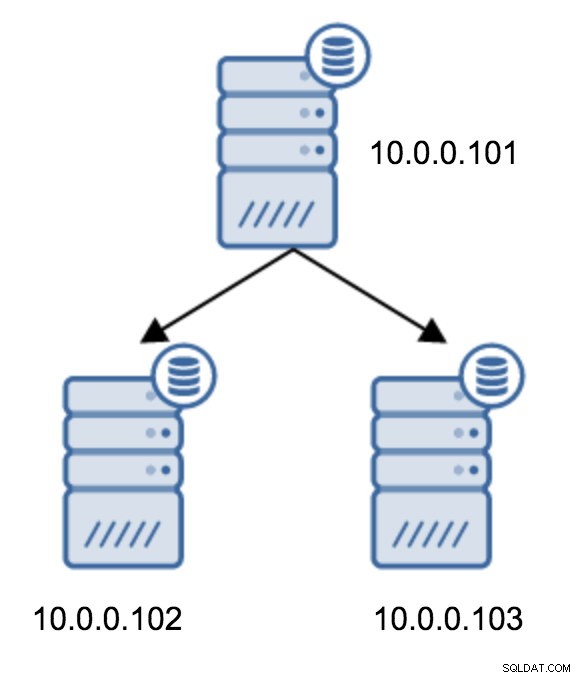
Há vários motivos pelos quais você pode querer criar uma replicação encadeada, embora isso normalmente seja feito para reduzir a carga no servidor primário. Servir o WAL para servidores em espera adiciona alguma sobrecarga. Não é um grande problema se você tiver um ou dois em espera, mas se estivermos falando de um grande número de servidores em espera, isso pode se tornar um problema. Por exemplo, podemos minimizar o número de servidores em espera replicando diretamente do ativo criando uma topologia conforme abaixo:
A mudança de uma topologia de dois servidores em espera para uma replicação encadeada é bastante direta.
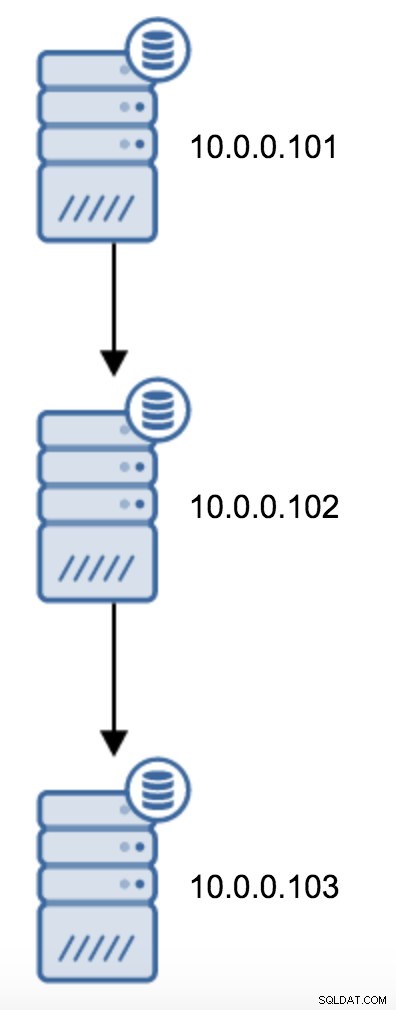
Você precisaria modificar recovery.conf em 10.0.0.103, apontar para 10.0.0.102 e então reiniciar o PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Após a reinicialização, o 10.0.0.103 deve começar a aplicar as atualizações do WAL.
Estes são alguns casos comuns de alterações de topologia. Um tópico que não foi discutido, mas que ainda é importante, é o impacto dessas mudanças nas aplicações. Abordaremos isso em uma postagem separada, além de como tornar essas alterações de topologia transparentes para os aplicativos.



