Os bancos de dados que atendem a aplicativos de negócios geralmente devem oferecer suporte a dados temporais. Por exemplo, suponha que um contrato com um fornecedor seja válido apenas por tempo limitado. Ele pode ser válido a partir de um ponto específico no tempo ou pode ser válido para um intervalo de tempo específico – de um ponto de tempo inicial a um ponto de tempo final. Além disso, muitas vezes você precisa auditar todas as alterações em uma ou mais tabelas. Você também pode precisar mostrar o estado em um momento específico ou todas as alterações feitas em uma tabela em um período específico. Da perspectiva de integridade de dados, pode ser necessário implementar muitas restrições específicas temporais adicionais.
Apresentando dados temporais
Em uma tabela com suporte temporal, o cabeçalho representa um predicado com um parâmetro de pelo menos uma vez que representa o intervalo quando o restante do predicado é válido — o predicado completo é, portanto, um predicado com carimbo de data/hora. As linhas representam proposições com carimbo de data/hora, e o período de tempo válido da linha normalmente é expresso com dois atributos:de e para , ou começar e fim .
Tipos de Tabelas Temporais
Você deve ter notado durante a parte da introdução que existem dois tipos de questões temporais. O primeiro é o tempo de validade da proposição – em que período a proposição que uma linha com timestamp em uma tabela representa era realmente verdadeira. Por exemplo, um contrato com um fornecedor era válido apenas do ponto de tempo 1 ao ponto de tempo 2. Esse tipo de tempo de validade é significativo para as pessoas, significativo para o negócio. O tempo de validade também é chamado de tempo de aplicação ou tempo humano . Podemos ter vários períodos válidos para a mesma entidade. Por exemplo, o contrato acima mencionado que era válido do ponto 1 ao ponto 2 também pode ser válido do ponto 7 ao ponto 9.
A segunda questão temporal é o tempo de transação . Uma linha para o contrato mencionado acima foi inserida no ponto de tempo 1 e era a única versão da verdade conhecida pelo banco de dados até que alguém o alterasse, ou mesmo até o final do tempo. Quando a linha é atualizada no ponto de tempo 2, a linha original era conhecida como verdadeira para o banco de dados do ponto de tempo 1 ao ponto de tempo 2. Uma nova linha para a mesma proposição é inserida com tempo válido para o banco de dados do ponto de tempo 2 até o fim dos tempos. O horário da transação também é conhecido como horário do sistema ou hora do banco de dados .
Obviamente, você também pode implementar tabelas com versão do aplicativo e do sistema. Essas tabelas são chamadas de bitemporais mesas.
No SQL Server 2016, você obtém suporte para o tempo do sistema pronto para uso com tabelas temporais com versão do sistema . Se você precisar implementar o tempo de aplicação, precisará desenvolver uma solução por conta própria.
Operadores de intervalo de Allen
A teoria dos dados temporais em um modelo relacional começou a evoluir há mais de trinta anos. Vou apresentar alguns operadores booleanos úteis e alguns operadores que funcionam em intervalos e retornam um intervalo. Esses operadores são conhecidos como operadores de Allen, em homenagem a J. F. Allen, que definiu vários deles em um trabalho de pesquisa de 1983 sobre intervalos temporais. Todos eles ainda são aceitos como válidos e necessários. Um sistema de gerenciamento de banco de dados pode ajudá-lo a lidar com os tempos de aplicação implementando esses operadores prontos para uso.
Deixe-me primeiro apresentar a notação que usarei. Vou trabalhar em dois intervalos, denotados i1 e i2 . O ponto de tempo inicial do primeiro intervalo é b1 , e o final é e1 ; o ponto inicial do segundo intervalo é b2 e o final é e2 . Os operadores booleanos de Allen são definidos na tabela a seguir.
[table id=2 /]
Além dos operadores booleanos, existem os três operadores de Allen que aceitam intervalos como parâmetros de entrada e retornam um intervalo. Esses operadores constituem uma álgebra intervalar simples . Observe que esses operadores têm o mesmo nome dos operadores relacionais com os quais você provavelmente já está familiarizado:Union, Intersect e Minus. No entanto, eles não se comportam exatamente como suas contrapartes relacionais. Em geral, usando qualquer um dos três operadores de intervalo, se a operação resultar em um conjunto vazio de pontos de tempo ou em um conjunto que não pode ser descrito por um intervalo, o operador deve retornar NULL. Uma união de dois intervalos só faz sentido se os intervalos se encontrarem ou se sobrepuserem. Uma interseção só faz sentido se os intervalos se sobrepuserem. O operador de intervalo menos faz sentido apenas em alguns casos. Por exemplo, (3:10) Menos (5:7) retorna NULL porque o resultado não pode ser descrito por um intervalo. A tabela a seguir resume a definição dos operadores da álgebra intervalar.
[ID da tabela=3 /]
Problema de desempenho de consultas sobrepostasUm dos operadores mais complexos de implementar são as sobreposições operador. Consultas que precisam encontrar intervalos sobrepostos não são simples de serem otimizadas. No entanto, essas consultas são bastante frequentes em tabelas temporais. Neste e nos próximos dois artigos, mostrarei algumas maneiras de otimizar essas consultas. Mas antes de apresentar as soluções, deixe-me apresentar o problema.
Para explicar o problema, preciso de alguns dados. O código a seguir mostra um exemplo de como criar uma tabela com intervalos de validade expressos com o b e e colunas, onde o início e o fim de um intervalo são representados como números inteiros. A tabela é preenchida com dados de demonstração da tabela WideWorldImporters.Sales.OrderLines. Observe que existem várias versões do WideWorldImporters banco de dados, então você pode obter resultados ligeiramente diferentes. Eu usei o arquivo de backup WideWorldImporters-Standard.bak de https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 para restaurar esse banco de dados de demonstração na minha instância do SQL Server .
Criando os dados de demonstração
Criei uma tabela de demonstração dbo.Intervals no tempd banco de dados com o seguinte código.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Observe também os índices criado. Os dois índices são ideais para pesquisas no início de um intervalo ou no final de um intervalo. Você pode verificar o início mínimo e o final máximo de todos os intervalos com o código a seguir.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Você pode ver nos resultados que o ponto de tempo inicial mínimo é 1 e o ponto de tempo final máximo é 1155.
Fornecendo o contexto aos dados
Você pode notar que eu represento os pontos de tempo iniciais e finais como inteiros. Agora eu preciso dar aos intervalos algum contexto de tempo. Nesse caso, um único ponto no tempo representa um dia . O código a seguir cria uma tabela de pesquisa de data e o povoa. Observe que a data de início é 1º de julho de 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Agora, você pode unir a tabela dbo.Intervals à tabela dbo.DateNums duas vezes, para dar o contexto aos inteiros que representam o início e o fim dos intervalos.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Apresentando o problema de desempenho
O problema com consultas temporais é que, ao ler uma tabela, o SQL Server pode usar apenas um índice e eliminar com êxito as linhas que não são candidatas ao resultado apenas de um lado e, em seguida, verifica o restante dos dados. Por exemplo, você precisa encontrar todos os intervalos na tabela que se sobrepõem a um determinado intervalo. Lembre-se, dois intervalos se sobrepõem quando o início do primeiro é menor ou igual ao final do segundo e o início do segundo é menor ou igual ao final do primeiro, ou matematicamente quando (b1 ≤ e2) E (b2 ≤ e1).
A consulta a seguir pesquisou todos os intervalos que se sobrepõem ao intervalo (10, 30). Observe que a segunda condição (b2 ≤ e1) é invertida para (e1 ≥ b2) para uma leitura mais simples (o início e o fim dos intervalos da tabela estão sempre no lado esquerdo da condição). O intervalo fornecido ou pesquisado está no início da linha do tempo para todos os intervalos na tabela.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
A consulta usou 36 leituras lógicas. Se você verificar o plano de execução, poderá ver que a consulta usou o índice search no índice idx_b com o predicado de busca [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) e, em seguida, digitalizar as linhas e selecione as linhas resultantes usando o predicado residual [tempdb].[dbo].[Intervals].[e]>=(10). Como o intervalo pesquisado está no início da linha do tempo, o predicado de busca eliminou com êxito a maioria das linhas; apenas alguns intervalos na tabela têm o ponto inicial menor ou igual a 30.
Você obteria uma consulta igualmente eficiente se o intervalo pesquisado estivesse no final da linha do tempo, apenas que o SQL Server usaria o índice idx_e para buscar. No entanto, o que acontece se o intervalo pesquisado estiver no meio da linha do tempo, como mostra a consulta a seguir?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Desta vez, a consulta usou 111 leituras lógicas. Com uma tabela maior, a diferença com a primeira consulta seria ainda maior. Se você verificar o plano de execução, poderá descobrir que o SQL Server usou o índice idx_e com o predicado de busca [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) e [tempdb].[ dbo].[Intervalos].[b]<=(590) predicado residual. O predicado de busca exclui aproximadamente metade das linhas de um lado, enquanto metade das linhas do outro lado é varrida e as linhas resultantes extraídas com o predicado residual.
Solução T-SQL aprimorada
Existe uma solução que usaria esse índice para a eliminação das linhas de ambos os lados do intervalo pesquisado usando um único índice. A figura a seguir mostra essa lógica.
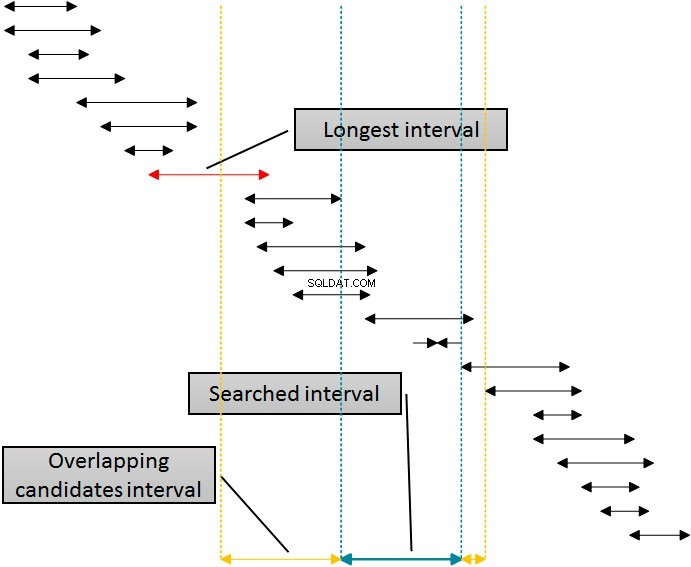
Os intervalos na figura são classificados pelo limite inferior, representando o uso do SQL Server do índice idx_b. Eliminar intervalos do lado direito do intervalo dado (pesquisado) é simples:basta eliminar todos os intervalos onde o início é pelo menos uma unidade maior (mais à direita) do final do intervalo dado. Você pode ver esse limite na figura indicada com a linha pontilhada mais à direita. No entanto, eliminar da esquerda é mais complexo. Para usar o mesmo índice, o índice idx_b para eliminação da esquerda, preciso usar o início dos intervalos na tabela na cláusula WHERE da consulta. Eu tenho que ir para o lado esquerdo longe do início do intervalo fornecido (pesquisado) pelo menos durante o intervalo mais longo na tabela, que está marcado com um texto explicativo na figura. Os intervalos que começam antes da linha amarela esquerda não podem se sobrepor ao intervalo fornecido (azul).
Como já sei que o comprimento do intervalo mais longo é 20, posso escrever uma consulta aprimorada de maneira bastante simples.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Esta consulta recupera as mesmas linhas que a anterior com 20 leituras lógicas somente. Se você verificar o plano de execução, poderá ver que o idx_b foi usado, com o predicado de busca Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , End:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), que eliminou com sucesso as linhas de ambos os lados da linha do tempo e, em seguida, o predicado residual [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) foi usado para selecionar linhas de uma varredura parcial muito limitada.
Claro, a figura poderia ser invertida para cobrir os casos em que o índice idx_e seria mais útil. Com este índice, a eliminação pela esquerda é simples – elimine todos os intervalos que terminam pelo menos uma unidade antes do início do intervalo dado. Desta vez, a eliminação da direita é mais complexa – o final dos intervalos na tabela não pode estar mais à direita do que o final do intervalo fornecido mais o comprimento máximo de todos os intervalos na tabela.
Observe que esse desempenho é consequência dos dados específicos da tabela. O comprimento máximo de um intervalo é 20. Dessa forma, o SQL Server pode eliminar intervalos de ambos os lados com muita eficiência. No entanto, se houvesse apenas um intervalo longo na tabela, o código se tornaria muito menos eficiente, pois o SQL Server não seria capaz de eliminar muitas linhas de um lado, esquerdo ou direito, dependendo de qual índice ele usaria . De qualquer forma, na vida real, a duração do intervalo não varia muito muitas vezes, então essa técnica de otimização pode ser muito útil, principalmente por ser simples.
Conclusão
Por favor, note que esta é apenas uma solução possível. Você pode encontrar uma solução mais complexa, mas com desempenho previsível, independentemente da duração do intervalo mais longo no artigo Interval Queries in SQL Server de Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-queries). No entanto, gosto muito do T-SQL aprimorado solução que apresentei neste artigo. A solução é muito simples; tudo o que você precisa fazer é adicionar dois predicados à cláusula WHERE de suas consultas sobrepostas. No entanto, este não é o fim das possibilidades. Fique atento, nos próximos dois artigos vou te mostrar mais soluções, assim você terá um rico conjunto de possibilidades em sua caixa de ferramentas de otimização.
Ferramenta útil:
dbForge Query Builder for SQL Server – permite que os usuários criem consultas SQL complexas de maneira rápida e fácil por meio de uma interface visual intuitiva sem escrita manual de código.