Há tanto que você pode dizer sobre história e importância. História de um país, de civilização, de cada um de nós. Adoro citações e gosto dessa do Teddy Roosevelt (cara legal):
Quanto mais você souber sobre o passado, mais preparado estará para o futuro.
Por que estou sendo poético (ou tentando) sobre a história em um blog sobre SQL Server? Porque o histórico no SQL Server também é importante. Quando existe um problema de desempenho no SQL Server, é ideal solucionar o problema ao vivo, mas em alguns casos, as informações históricas podem fornecer uma arma fumegante ou pelo menos um ponto de partida. Uma ótima fonte de informações históricas no SQL Server é o ERRORLOG. Eu mencionei no meu post original, Performance Issues:The First Encounter, que o ERRORLOG costumava ser uma reflexão tardia para mim. Não mais. Durante as auditorias do cliente, sempre capturamos os ERRORLOGs e, embora sejamos notificados sobre quaisquer alertas de alta gravidade (que são gravados no log), não é inédito encontrar outras informações interessantes no log. Nós nos preparamos para o futuro usando as informações históricas nos logs; as informações podem nos ajudar a corrigir um problema, ou potencial problema, antes que se torne catastrófico.
Visualizando o ERRORLOG
Primeiramente, revisaremos algumas opções para visualizar o ERROLOG. Se eu estiver conectado a uma instância, normalmente navegarei até ela por meio do SSMS (Gerenciamento | Logs do SQL Server, clique com o botão direito do mouse em um log e selecione Exibir log do SQL Server). Nessa janela, posso simplesmente rolar pelo log ou usar as opções de Filtro ou Pesquisa para restringir o conjunto de resultados. Também posso visualizar vários arquivos selecionando-os no painel esquerdo.
Se estou analisando os dados capturados em uma de nossas auditorias de saúde, apenas abro os arquivos de log em um editor de texto e os reviso (tenho a opção de entrar no visualizador e carregá-los também). Os arquivos de log existem na pasta de log (local padrão:C:\Arquivos de Programas\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log) se eu quisesse vê-los no servidor. Muitos de vocês podem preferir exibir e/ou pesquisar o log usando o procedimento não documentado sp_readerrorlog ou o procedimento armazenado estendido xp_readerrorlog.
E, finalmente, se você gosta do PowerShell, essa também é uma opção para ler o log dessa maneira (consulte esta postagem:Use o PowerShell para analisar logs de erro do SQL Server 2012). O método depende de você – use o que você sabe e o que funciona para você – é o conteúdo que realmente importa. E lembre-se de que há momentos em que você precisará simplesmente ler o log para entender a ordem dos eventos, e há outros momentos em que você pode pesquisar para encontrar um erro ou informação específica.
O que há no ERRORLOG?
Então, quais informações podemos encontrar no ERRORLOG, além de erros? Eu listei muitos dos itens que achei mais úteis abaixo. Observe que esta não é uma lista exaustiva (e tenho certeza de que muitos de vocês terão sugestões do que poderia ser adicionado – sinta-se à vontade para postar um comentário e posso atualizar isso!), mas, novamente, é isso que estou procurando primeiro quando estou olhando proativamente para uma instância.
- Se o servidor é físico ou virtual (procure a entrada do fabricante do sistema)
- Sinalizadores de rastreamento ativados na inicialização
- Na entrada dos parâmetros de inicialização do Registro, se você rolar até a direita, verá se algum sinalizador de rastreamento está ativado:
 Sinalizadores de rastreamento ativados na inicialização
Sinalizadores de rastreamento ativados na inicialização
- Na entrada dos parâmetros de inicialização do Registro, se você rolar até a direita, verá se algum sinalizador de rastreamento está ativado:
- Sinalizadores de rastreamento ativados ou desativados após o início da instância
- Se os usuários (ou um aplicativo) habilitarem ou desabilitarem um sinalizador de rastreamento usando DBCC TRACEON ou DBCC TRACEOFF, uma entrada aparecerá no log
- Número de núcleos e soquetes detectados pelo SQL Server
- Sempre gosto de verificar se o SQL Server vê todo o hardware disponível – e se não, isso é uma bandeira vermelha para investigar mais. Para obter um bom exemplo, consulte a postagem de Jonathan, Problemas de desempenho com o SQL Server 0212 Enterprise Edition sob licenciamento de CAL, e a postagem de Glenn, Balancing Your Available SQL Server Core Licenses Evenly Across NUMA Nodes, que também inclui alguns TSQL úteis para consultar o log.
- Observe que o texto dessa entrada varia entre as versões do SQL Server.
- Quantidade de memória detectada pelo SQL Server
- Novamente, quero verificar se o SQL Server vê toda a memória disponível para ele.
- Confirmação de que as páginas bloqueadas na memória (LPIM) estão ativadas
- Embora esta opção esteja habilitada por meio da Política de Segurança do Windows, você pode confirmar que ela está habilitada procurando a mensagem "Usando páginas bloqueadas no gerenciador de memória" no log.
- Observe que, se você tiver o sinalizador de rastreamento 834 em uso, a mensagem não mostrará páginas bloqueadas, mas sim que páginas grandes estão sendo usadas para o pool de buffers.
- Versão do CLR em uso
- Sucesso ou falha no registro do nome principal do serviço (SPN)
- Quanto tempo leva para um banco de dados ficar online
- O log registra quando o banco de dados é inicializado e quando está on-line – verifico se algum banco de dados demora muito para ser ativado.
- Status do Service Broker e endpoints de espelhamento de banco de dados – importante se você estiver usando qualquer um dos recursos
- Confirmação de que a inicialização instantânea de arquivos (IFI) está ativada*
- Por padrão, essas informações não são registradas, mas se você habilitar Trace Flag 3004 (e 3605 para forçar a saída para o log), ao criar ou aumentar um arquivo de dados, você verá mensagens no log para indicar se IFI está em uso ou não.
- Status de rastreamentos SQL
- Quando você inicia ou interrompe um rastreamento de SQL, ele é registrado e eu procuro ver se existem rastreamentos além do rastreamento padrão (temporário ou de longo prazo). Se você estiver executando uma ferramenta de monitoramento de terceiros, como o Performance Advisor do SQL Sentry, poderá ver um rastreamento ativo que está sempre em execução, mas apenas capturando eventos específicos, ou poderá ver um rastreamento iniciar, executado por um curto período e, em seguida, Pare. Não estou preocupado com um ou dois rastreamentos extras, a menos que estejam capturando muitos eventos, mas definitivamente presto atenção quando vários rastreamentos estão em execução.
- A última vez que CHECKDB foi concluído
- Esta mensagem é muitas vezes mal interpretada pelas pessoas – quando a instância é inicializada, ela lê a página de inicialização de cada banco de dados e observa quando o CHECKDB foi executado com sucesso pela última vez. A maioria das pessoas não lê a mensagem inteira:
 Data em que o último DBCC CHECKDB foi concluído com êxito
Data em que o último DBCC CHECKDB foi concluído com êxito
A data de conclusão do CHECKDB é 11 de novembro de 2012, mas a data do ERRORLOG é 7 de julho de 2015. É importante entender que o SQL Server não execute CHECKDB em bancos de dados na inicialização, ele verifica o valor dbcclastknowngood na página de inicialização (para ver quando isso é atualizado, confira meu post, What Checks Update dbcclastknowngood. Além disso, se DBCC CHECKDB nunca foi executado em um banco de dados, nenhuma entrada aparecerá para o banco de dados aqui.
- Esta mensagem é muitas vezes mal interpretada pelas pessoas – quando a instância é inicializada, ela lê a página de inicialização de cada banco de dados e observa quando o CHECKDB foi executado com sucesso pela última vez. A maioria das pessoas não lê a mensagem inteira:
- Conclusão de CHECKDB
- Quando CHECKDB é executado em um banco de dados, a saída é registrada no log.
- Alterações nas configurações de instância
- Se você alterar as configurações de nível de instância (por exemplo, memória máxima do servidor, limite de custo para paralelismo) usando sp_configure ou por meio da interface do usuário (observe que ele não registra who mudou).
- Mudanças nas configurações do banco de dados
- Alguém ativou AUTO_SHRINK? Altere a opção RECOVERY para SIMPLE e depois volte para FULL? Você o encontrará aqui.
- Mudanças no status do banco de dados
- Se alguém colocar um banco de dados OFFLINE (ou colocá-lo ONLINE), isso será registrado.
- Informações de impasse*
- Se você precisa capturar informações de impasse, não deseja executar um rastreamento, e estiver executando o SQL Server 2005 a 2008R2, use o sinalizador de rastreamento 1222 para gravar informações de impasse no log no formato XML. Para aqueles que usam o SQL Server 2000 e inferior, você pode rastrear o sinalizador 1204 (esse sinalizador de rastreamento também está disponível no SQL Server 2005+, mas gera informações mínimas). Se você estiver executando o SQL Server 2012 ou superior, isso não é necessário, pois a sessão do evento system_health captura essas informações (e está lá em 2008 e 20082 também, mas você precisa extraí-lo do ring_buffer versus o destino event_file).
- Mensagens do FlushCache
- Se o cache estiver sendo liberado pelo SQL Server porque o processo de ponto de verificação excede o intervalo de recuperação do banco de dados, você verá um conjunto de mensagens FlushCache no log (consulte esta postagem de Bob Dorr para obter mais informações). Não confunda essas mensagens com as que aparecem quando você executa DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE:
 Mensagem após executar DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE
Mensagem após executar DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE
- Se o cache estiver sendo liberado pelo SQL Server porque o processo de ponto de verificação excede o intervalo de recuperação do banco de dados, você verá um conjunto de mensagens FlushCache no log (consulte esta postagem de Bob Dorr para obter mais informações). Não confunda essas mensagens com as que aparecem quando você executa DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE:
- Mensagens de descarregamento de AppDomain
- O log também informa quando os AppDomains são criados, e você só verá se estiver usando o CLR. Se eu vir mensagens de descarregamento do AppDomain devido à pressão da memória, é algo a ser investigado.
Há outras informações no log que são úteis, como o modo de autenticação em uso, se a conexão de administrador dedicada (DAC) está habilitada ou não, etc. Discuti anteriormente (Verificações de integridade proativas do SQL Server, Parte 3:Configurações de instância e banco de dados).
O que não está no ERROLOG, que você poderia esperar?
Esta é uma pequena lista, por enquanto, pois acho que alguns de vocês podem ter encontrado outras coisas que achavam que estariam no log, mas não estavam…
- Adicionar ou remover arquivos de banco de dados ou grupos de arquivos
- Iniciar ou interromper sessões de eventos estendidos
- No entanto, se você implantar um acionador DDL no nível do servidor ou uma notificação de evento, poderá registrar essas informações. Veja a postagem de Jonathan, Logging Extended Events changes to the ERRORLOG, para mais detalhes.
- A execução do DBCC DROPCLEANBUFFERS aparece no ERRORLOG
Gerenciando o registro
Lembre-se de que, por padrão, o SQL Server mantém apenas os seis (6) arquivos de log mais recentes (além do arquivo atual), e o arquivo de log é revertido toda vez que o SQL Server é reiniciado. Como resultado, às vezes você pode ter arquivos de log extremamente grandes que demoram um pouco para serem abertos e são difíceis de vasculhar. Por outro lado, se você se deparar com um caso em que a instância for reiniciada algumas vezes, poderá perder informações importantes. É recomendável aumentar o número de arquivos retidos para um valor mais alto (por exemplo, 30) e criar um trabalho de agente para substituir o arquivo uma vez por semana usando sp_cycle_errorlog.
Além de gerenciar os arquivos, você pode afetar quais informações são gravadas no log. Uma das entradas mais comuns que cria confusão no ERRORLOG é a entrada de backup bem-sucedida:
 Backup concluído com sucesso
Backup concluído com sucesso Se você tiver uma instância com vários bancos de dados e os backups de log de transações forem feitos com alguma regularidade (por exemplo, a cada 15 minutos), verá o log rapidamente se encher de mensagens, o que dificulta a localização de um problema real. Felizmente, você pode usar o sinalizador de rastreamento 3226 para desabilitar mensagens de backup bem-sucedidas (os erros ainda serão exibidos no log e todas as entradas ainda existirão no msdb).
Outro conjunto de mensagens que atrapalham o log são as mensagens de login bem-sucedidas. Esta é uma opção que você configura para a instância na guia Segurança:
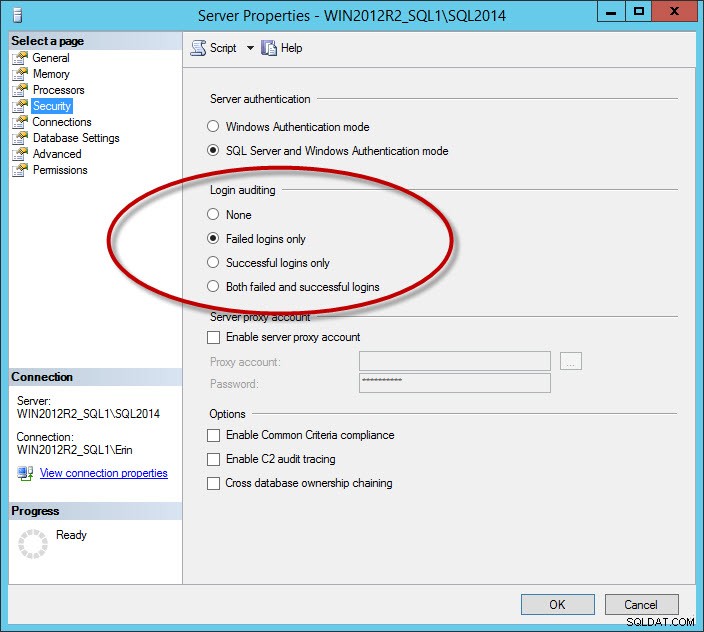 Opção de segurança para registrar logins bem-sucedidos e/ou com falha
Opção de segurança para registrar logins bem-sucedidos e/ou com falha Se você registrar logins bem-sucedidos ou logins malsucedidos e bem-sucedidos, poderá ter arquivos de log muito grandes, mesmo se você fizer rollover dos arquivos diariamente (dependerá de quantos usuários se conectarem). Eu recomendo capturar apenas logins com falha. Para empresas que precisam registrar logons bem-sucedidos, considere usar o recurso de auditoria, adicionado no SQL Server 2008. Observação:se você alterar a configuração de auditoria de logon, ela não terá efeito até que você reinicie a instância.
Não subestime o ERRORLOG
Como você pode ver, há ótimas informações no ERRORLOG para você usar não apenas quando estiver solucionando problemas de desempenho ou investigando erros, mas também quando estiver monitorando uma instância de forma proativa. Você pode encontrar informações no log que não são encontradas em nenhum outro lugar; certifique-se de verificar regularmente e não deixá-lo como uma reflexão tardia.
Veja as outras partes desta série:
- Parte 1:Espaço em disco
- Parte 2:Manutenção
- Parte 3:configurações de instância e banco de dados