Este artigo é a oitava parte de uma série sobre expressões de tabela. Até agora, forneci uma base para expressões de tabela, abordei os aspectos lógicos e de otimização de tabelas derivadas, os aspectos lógicos de CTEs e alguns dos aspectos de otimização de CTEs. Este mês continuo a cobertura dos aspectos de otimização de CTEs, abordando especificamente como várias referências CTE são tratadas.
Este artigo é a oitava parte de uma série sobre expressões de tabela. Até agora, forneci uma base para expressões de tabela, abordei os aspectos lógicos e de otimização de tabelas derivadas, os aspectos lógicos de CTEs e alguns dos aspectos de otimização de CTEs. Este mês continuo a cobertura dos aspectos de otimização de CTEs, abordando especificamente como várias referências CTE são tratadas. Em meus exemplos continuarei usando o banco de dados de exemplo TSQLV5. Você pode encontrar o script que cria e preenche o TSQLV5 aqui e seu diagrama ER aqui.
Múltiplas referências e não determinismo
No mês passado, expliquei e demonstrei que CTEs são desaninhadas, enquanto tabelas temporárias e variáveis de tabela realmente persistem os dados. Forneci recomendações sobre quando faz sentido usar CTEs versus quando faz sentido usar objetos temporários do ponto de vista do desempenho da consulta. Mas há outro aspecto importante da otimização do CTE, ou processamento físico, a ser considerado além do desempenho da solução – como várias referências ao CTE de uma consulta externa são tratadas. É importante perceber que, se você tiver uma consulta externa com várias referências ao mesmo CTE, cada uma será desaninhada separadamente. Se você tiver cálculos não determinísticos na consulta interna do CTE, esses cálculos podem ter resultados diferentes nas diferentes referências.
Digamos, por exemplo, que você invoque a função SYSDATETIME na consulta interna de um CTE, criando uma coluna de resultado chamada dt. Geralmente, supondo que não haja alteração nas entradas, uma função interna é avaliada uma vez por consulta e referência, independentemente do número de linhas envolvidas. Se você fizer referência ao CTE apenas uma vez em uma consulta externa, mas interagir com a coluna dt várias vezes, todas as referências deverão representar a mesma avaliação de função e retornar os mesmos valores. No entanto, se você se referir ao CTE várias vezes na consulta externa, seja com várias subconsultas referentes ao CTE ou uma junção entre várias instâncias do mesmo CTE (digamos, alias como C1 e C2), as referências a C1.dt e C2.dt representam diferentes avaliações da expressão subjacente e podem resultar em valores diferentes.
Para demonstrar isso, considere os três lotes a seguir:
-- Lote 1 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 SELECT @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Lote 2 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 COM C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 FROM C WHERE dt =dt; PRINT @i;GO -- Lote 3 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 WHERE (SELECT dt FROM C) =(SELECT dt FROM C); IMPRIMIR @i;GO
Com base no que acabei de explicar, você consegue identificar quais dos lotes têm um loop infinito e quais pararão em algum momento devido aos dois comparandos do predicado avaliando valores diferentes?
Lembre-se de que eu disse que uma chamada para uma função não determinística interna como SYSDATETIME é avaliada uma vez por consulta e referência. Isso significa que no Lote 1 você tem duas avaliações diferentes e, após iterações suficientes do loop, elas resultarão em valores diferentes. Tente. Quantas iterações o código relatou?
Quanto ao Lote 2, o código possui duas referências à coluna dt da mesma instância CTE, significando que ambas representam a mesma avaliação de função e devem representar o mesmo valor. Consequentemente, o Lote 2 tem um loop infinito. Execute-o pelo tempo que desejar, mas eventualmente será necessário interromper a execução do código.
Quanto ao Lote 3, a consulta externa tem duas subconsultas diferentes interagindo com o CTE C, cada uma representando uma instância diferente que passa por um processo de desaninhamento separadamente. O código não atribui explicitamente aliases diferentes para as diferentes instâncias do CTE porque as duas subconsultas aparecem em escopos independentes, mas para facilitar o entendimento, você pode pensar nos dois como usando aliases diferentes, como C1 em uma subconsulta e C2 no outro. Então é como se uma subconsulta interagisse com C1.dt e a outra com C2.dt. As diferentes referências representam diferentes avaliações da expressão subjacente e, portanto, podem resultar em valores diferentes. Tente executar o código e veja se ele pára em algum momento. Quantas iterações foram necessárias até parar?
É interessante tentar identificar os casos em que você tem uma avaliação única versus várias avaliações da expressão subjacente no plano de execução da consulta. A Figura 1 apresenta os planos gráficos de execução para os três lotes (clique para ampliar).
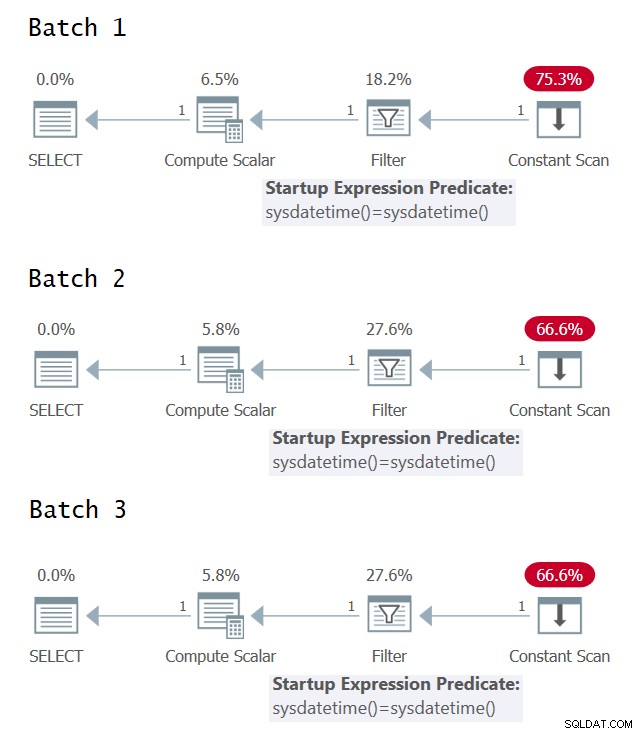 Figura 1:planos de execução gráfica para o Lote 1, Lote 2 e Lote 3
Figura 1:planos de execução gráfica para o Lote 1, Lote 2 e Lote 3 Infelizmente, nenhuma alegria com os planos de execução gráfica; todos parecem idênticos, embora, semanticamente, os três lotes não tenham significados idênticos. Graças a @CodeRecce e Forrest (@tsqladdict), como comunidade, conseguimos chegar ao fundo disso com outros meios.
Como o @CodeRecce descobriu, os planos XML contêm a resposta. Aqui estão as partes relevantes do XML para os três lotes:
−− Lote 1
…
…
−− Lote 2
…
…
−− Lote 3
…
…
Você pode ver claramente no plano XML para o Lote 1 que o predicado de filtro compara os resultados de duas chamadas diretas separadas da função SYSDATETIME intrínseca.
No plano XML para o Lote 2, o predicado de filtro compara a expressão constante ConstExpr1002 que representa uma chamada da função SYSDATETIME consigo mesma.
No plano XML para o Lote 3, o predicado de filtro compara duas expressões constantes diferentes chamadas ConstExpr1005 e ConstExpr1006, cada uma representando uma chamada separada da função SYSDATETIME.
Como outra opção, Forrest (@tsqladdict) sugeriu usar o sinalizador de rastreamento 8605, que mostra a representação inicial da árvore de consulta criada pelo SQL Server, após habilitar o sinalizador de rastreamento 3604 que faz com que a saída do TF 8605 seja direcionada ao cliente SSMS. Use o código a seguir para habilitar os dois sinalizadores de rastreamento:
DBCC TRACEON(3604); -- saída direta para clientGO DBCC TRACEON(8605); -- mostra a árvore de consulta inicialGO
Em seguida, você executa o código para o qual deseja obter a árvore de consulta. Aqui estão as partes relevantes da saída que obtive do TF 8605 para os três lotes:
−− Lote 1
*** Árvore convertida:***
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [vazio]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Não possui,Value=1)
−− Lote 2
*** Árvore convertida:***
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [vazio]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Não possui,Value=1)
−− Lote 3
*** Árvore convertida:***
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [vazio]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [vazio]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [vazio]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Não possui,Value=1)
No Lote 1, você pode ver uma comparação entre os resultados de duas avaliações separadas da função intrínseca SYSDATETIME.
No Lote 2, você vê uma avaliação da função resultando em uma coluna chamada Expr1000 e, em seguida, uma comparação entre essa coluna e ela mesma.
No Lote 3, você vê duas avaliações separadas da função. Uma na coluna chamada Expr1000 (mais tarde projetada pela coluna de subconsulta chamada Expr1001). Outra na coluna chamada Expr1002 (mais tarde projetada pela coluna de subconsulta chamada Expr1003). Você então tem uma comparação entre Expr1001 e Expr1003.
Portanto, com um pouco mais de escavação além do que o plano de execução gráfico expõe, você pode realmente descobrir quando uma expressão subjacente é avaliada apenas uma vez versus várias vezes. Agora que você entende os diferentes casos, você pode desenvolver suas soluções com base no comportamento desejado que você procura.
Funções de janela com ordem não determinística
Há outra classe de cálculos que podem causar problemas quando usados em soluções com várias referências ao mesmo CTE. Essas são funções de janela que dependem de ordenação não determinística. Tome a função de janela ROW_NUMBER como exemplo. Quando usado com pedido parcial (ordenando por elementos que não identificam exclusivamente a linha), cada avaliação da consulta subjacente pode resultar em uma atribuição diferente dos números da linha, mesmo que os dados subjacentes não sejam alterados. Com várias referências de CTE, lembre-se de que cada uma é desaninhada separadamente e você pode obter diferentes conjuntos de resultados. Dependendo do que a consulta externa faz com cada referência, por exemplo, com quais colunas de cada referência ele interage e como, o otimizador pode decidir acessar os dados para cada uma das instâncias usando diferentes índices com diferentes requisitos de ordenação.
Considere o seguinte código como exemplo:
USE TSQLV5; WITH C AS(SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Essa consulta pode retornar um conjunto de resultados não vazio? Talvez sua reação inicial seja que não pode. Mas pense no que acabei de explicar com um pouco mais de cuidado e você perceberá que, pelo menos em teoria, devido aos dois processos separados de desaninhamento de CTE que ocorrerão aqui - um de C1 e outro de C2 - é possível. No entanto, uma coisa é teorizar que algo pode acontecer e outra é demonstrá-lo. Por exemplo, quando executei este código sem criar novos índices, continuei obtendo um conjunto de resultados vazio:
orderid shipcountry orderid----------- --------------- -----------(0 linhas afetadas)
Eu obtive o plano mostrado na Figura 23 para esta consulta.
Figura 2:primeiro plano para consulta com duas referências CTE
O que é interessante notar aqui é que o otimizador optou por usar índices diferentes para lidar com as diferentes referências de CTE porque foi o que considerou ideal. Afinal, cada referência na consulta externa está relacionada a um subconjunto diferente das colunas CTE. Uma referência resultou em uma varredura direta ordenada do índice idx_nc_orderedate e a outra em uma varredura não ordenada do índice clusterizado seguida por uma operação de classificação por ordem crescente de data. Embora o índice idx_nc_orderedate seja explicitamente definido apenas na coluna orderdate como a chave, na prática ele é definido em (orderdate, orderid) como suas chaves, pois orderid é a chave do índice clusterizado e é incluída como a última chave em todos os índices não clusterizados. Assim, uma varredura ordenada do índice realmente emite as linhas ordenadas por orderdate, orderid. Quanto à verificação não ordenada do índice clusterizado, no nível do mecanismo de armazenamento, os dados são verificados em ordem de chave de índice (com base em orderid) para atender às expectativas de consistência mínima do nível de isolamento padrão lido confirmado. O operador Sort, portanto, ingere os dados ordenados por orderid, ordena as linhas por orderdate e, na prática, acaba emitindo as linhas ordenadas por orderdate, orderid.
Novamente, em teoria, não há garantia de que as duas referências sempre representarão o mesmo conjunto de resultados, mesmo que os dados subjacentes não sejam alterados. Uma maneira simples de demonstrar isso é organizar dois índices ótimos diferentes para as duas referências, mas ter um ordenar os dados por orderdate ASC, orderid ASC e o outro ordenar os dados por orderdate DESC, orderid ASC (ou exatamente o oposto). Já temos o antigo índice em vigor. Aqui está o código para criar o último:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
Execute o código uma segunda vez depois de criar o índice:
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
Eu obtive a seguinte saída ao executar este código depois de criar o novo índice:
orderid shipcountry orderid---------- --------------- -----------10251 França 1025010250 Brasil 1025110261 Brasil 1026010260 Alemanha 1026110271 EUA 10270...11070 Alemanha 1107311077 EUA 1107411076 França 1107511075 Suíça 1107611074 Dinamarca 11077(546 linhas afetadas)
Ops.
Examine o plano de consulta para esta execução, conforme mostrado na Figura 3:
Figura 3:segundo plano para consulta com duas referências CTE
Observe que a ramificação superior do plano varre o índice idx_nc_orderdate de forma ordenada, fazendo com que o operador Sequence Project, que calcula os números das linhas, ingira os dados na prática ordenados por orderdate ASC, orderid ASC. A ramificação inferior do plano varre o novo índice idx_nc_odD_oid_I_sc de forma ordenada para trás, fazendo com que o operador Sequence Project ingira os dados na prática ordenados por orderdate ASC, orderid DESC. Isso resulta em um arranjo diferente de números de linha para as duas referências CTE sempre que houver mais de uma ocorrência do mesmo valor orderdate. Consequentemente, a consulta gera um conjunto de resultados não vazio.
Se você quiser evitar esses bugs, uma opção óbvia é persistir o resultado da consulta interna em um objeto temporário como uma tabela temporária ou variável de tabela. No entanto, se você tiver uma situação em que prefere usar CTEs, uma solução simples é usar a ordem total na função de janela adicionando um desempate. Em outras palavras, certifique-se de ordenar por uma combinação de expressões que identifica exclusivamente uma linha. No nosso caso, você pode simplesmente adicionar orderid explicitamente como um desempate, assim:
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
Você obtém um conjunto de resultados vazio conforme o esperado:
orderid shipcountry orderid----------- --------------- -----------(0 linhas afetadas)
Sem adicionar mais índices, você obtém o plano mostrado na Figura 4:
Figura 4:Terceiro plano para consulta com duas referências CTE
A ramificação superior do plano é a mesma do plano anterior mostrado na Figura 3. A ramificação inferior é um pouco diferente. O novo índice criado anteriormente não é realmente ideal para a nova consulta no sentido de que não possui os dados ordenados como a função ROW_NUMBER precisa (orderdate, orderid). Ainda é o índice de cobertura mais estreito que o otimizador pode encontrar para sua respectiva referência CTE, então é selecionado; no entanto, ele é escaneado no modo Ordered:False. Um operador Sort explícito então classifica os dados por orderdate, orderid como a computação ROW_NUMBER precisa. Obviamente, você pode alterar a definição do índice para que orderdate e orderid usem a mesma direção e, dessa forma, a classificação explícita será eliminada do plano. O ponto principal, porém, é que, ao usar o pedido total, você evita problemas devido a esse bug específico.
Quando terminar, execute o seguinte código para limpeza:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;Conclusão
É importante entender que várias referências ao mesmo CTE de uma consulta externa resultam em avaliações separadas da consulta interna do CTE. Tenha especial cuidado com cálculos não determinísticos, pois as diferentes avaliações podem resultar em valores diferentes.
Ao usar funções de janela como ROW_NUMBER e agregações com um quadro, certifique-se de usar a ordem total para evitar obter resultados diferentes para a mesma linha nas diferentes referências de CTE.