Na Parte 1 desta série, você usou o Flask e o Connexion para criar uma API REST fornecendo operações CRUD para uma estrutura simples na memória chamada
PEOPLE . Isso funcionou para demonstrar como o módulo Connexion ajuda você a criar uma API REST interessante junto com a documentação interativa. Como alguns observaram nos comentários da Parte 1, as
PEOPLE A estrutura é reinicializada toda vez que o aplicativo é reiniciado. Neste artigo, você aprenderá a armazenar as PEOPLE estrutura e as ações que a API fornece para um banco de dados usando SQLAlchemy e Marshmallow. SQLAlchemy fornece um Object Relational Model (ORM), que armazena objetos Python em uma representação de banco de dados dos dados do objeto. Isso pode ajudá-lo a continuar a pensar de maneira Pythonica e não se preocupar com a forma como os dados do objeto serão representados em um banco de dados.
O Marshmallow fornece funcionalidade para serializar e desserializar objetos Python à medida que eles saem e entram em nossa API REST baseada em JSON. Marshmallow converte instâncias de classe Python em objetos que podem ser convertidos em JSON.
Você pode encontrar o código Python para este artigo aqui.
Bônus grátis: Clique aqui para baixar uma cópia do Guia "Exemplos de API REST" e obter uma introdução prática aos princípios Python + API REST com exemplos acionáveis.
Para quem é este artigo
Se você gostou da Parte 1 desta série, este artigo expande ainda mais o seu cinto de ferramentas. Você usará SQLAlchemy para acessar um banco de dados de uma maneira mais Pythonica do que SQL direto. Você também usará o Marshmallow para serializar e desserializar os dados gerenciados pela API REST. Para fazer isso, você usará os recursos básicos de Programação Orientada a Objetos disponíveis em Python.
Você também usará o SQLAlchemy para criar um banco de dados e interagir com ele. Isso é necessário para colocar a API REST em funcionamento com o
PEOPLE dados usados na Parte 1. O aplicativo Web apresentado na Parte 1 terá seus arquivos HTML e JavaScript modificados em pequenas formas para oferecer suporte às alterações também. Você pode revisar a versão final do código da Parte 1 aqui.
Dependências Adicionais
Antes de começar a criar essa nova funcionalidade, você precisará atualizar o virtualenv criado para executar o código da Parte 1 ou criar um novo para este projeto. A maneira mais fácil de fazer isso depois de ativar seu virtualenv é executar este comando:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Isso adiciona mais funcionalidades ao seu virtualenv:
-
Flask-SQLAlchemyadiciona SQLAlchemy, junto com alguns tie-ins para Flask, permitindo que programas acessem bancos de dados.
-
flask-marshmallowadiciona as partes Flask do Marshmallow, que permite que os programas convertam objetos Python de e para estruturas serializáveis.
-
marshmallow-sqlalchemyadiciona alguns ganchos Marshmallow no SQLAlchemy para permitir que os programas serializem e desserializem objetos Python gerados pelo SQLAlchemy.
-
marshmallowadiciona a maior parte da funcionalidade Marshmallow.
Dados de pessoas
Como mencionado acima, as
PEOPLE estrutura de dados no artigo anterior é um dicionário Python na memória. Nesse dicionário, você usou o sobrenome da pessoa como chave de pesquisa. A estrutura de dados ficou assim no código:# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
As modificações que você fará no programa moverão todos os dados para uma tabela de banco de dados. Isso significa que os dados serão salvos em seu disco e existirão entre as execuções do
server.py programa. Como o sobrenome era a chave do dicionário, o código restringia a alteração do sobrenome de uma pessoa:apenas o primeiro nome podia ser alterado. Além disso, a mudança para um banco de dados permitirá que você altere o sobrenome, pois ele não será mais usado como chave de pesquisa para uma pessoa.
Conceitualmente, uma tabela de banco de dados pode ser pensada como uma matriz bidimensional onde as linhas são registros e as colunas são campos nesses registros.
As tabelas de banco de dados geralmente têm um valor inteiro de incremento automático como a chave de pesquisa para as linhas. Isso é chamado de chave primária. Cada registro na tabela terá uma chave primária cujo valor é exclusivo em toda a tabela. Ter uma chave primária independente dos dados armazenados na tabela libera você para modificar qualquer outro campo na linha.
Observação:
A chave primária de incremento automático significa que o banco de dados cuida de:
- Incrementar o maior campo de chave primária existente sempre que um novo registro for inserido na tabela
- Usando esse valor como chave primária para os dados recém-inseridos
Isso garante uma chave primária exclusiva à medida que a tabela cresce.
Você seguirá uma convenção de banco de dados de nomear a tabela como singular, então a tabela será chamada de
person . Traduzindo nossas PEOPLE estrutura acima em uma tabela de banco de dados chamada person te dá isso:| person_id | lnome | fnome | carimbo de data e hora |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Páscoa | Coelho | 2018-08-08 21:16:01.886834 |
Cada coluna na tabela tem um nome de campo da seguinte forma:
person_id: campo de chave primária para cada pessoalname: sobrenome da pessoafname: nome da pessoatimestamp: carimbo de data/hora associado a ações de inserção/atualização
Interação do banco de dados
Você usará o SQLite como o mecanismo de banco de dados para armazenar o
PEOPLE dados. SQLite é o banco de dados mais amplamente distribuído no mundo e vem com o Python gratuitamente. É rápido, executa todo o seu trabalho usando arquivos e é adequado para muitos projetos. É um RDBMS (Relational Database Management System) completo que inclui SQL, a linguagem de muitos sistemas de banco de dados. Por enquanto, imagine a
person tabela já existe em um banco de dados SQLite. Se você já teve alguma experiência com RDBMS, provavelmente conhece o SQL, a Linguagem de Consulta Estruturada que a maioria dos RDBMSs usa para interagir com o banco de dados. Ao contrário de linguagens de programação como Python, SQL não define como para obter os dados:descreve o que dados são desejados, deixando o como até o mecanismo de banco de dados.
Uma consulta SQL obtendo todos os dados em nossa
person tabela, classificada pelo sobrenome, ficaria assim:SELECT * FROM person ORDER BY 'lname';
Esta consulta diz ao mecanismo de banco de dados para obter todos os campos da tabela pessoa e classificá-los na ordem crescente padrão usando o
lname campo. Se você executar esta consulta em um banco de dados SQLite contendo a
person tabela, os resultados seriam um conjunto de registros contendo todas as linhas da tabela, com cada linha contendo os dados de todos os campos formando uma linha. Abaixo está um exemplo usando a ferramenta de linha de comando SQLite executando a consulta acima no person tabela de banco de dados:sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
A saída acima é uma lista de todas as linhas no
person tabela de banco de dados com caracteres de barra vertical (‘|’) separando os campos na linha, o que é feito para fins de exibição pelo SQLite. O Python é completamente capaz de fazer interface com muitos mecanismos de banco de dados e executar a consulta SQL acima. Os resultados provavelmente seriam uma lista de tuplas. A lista externa contém todos os registros na
person tabela. Cada tupla interna individual conteria todos os dados que representam cada campo definido para uma linha da tabela. Obter dados dessa maneira não é muito Pythonico. A lista de registros está correta, mas cada registro individual é apenas uma tupla de dados. Cabe ao programa saber o índice de cada campo para poder recuperar um determinado campo. O código Python a seguir usa SQLite para demonstrar como executar a consulta acima e exibir os dados:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
O programa acima faz o seguinte:
-
Linha 1 importa osqlite3módulo.
-
Linha 3 cria uma conexão com o arquivo de banco de dados.
-
Linha 4 cria um cursor a partir da conexão.
-
Linha 5 usa o cursor para executar umSQLconsulta expressa como uma string.
-
Linha 6 obtém todos os registros retornados peloSQLconsulta e os atribui àspeoplevariável.
-
Linha 7 e 8 iterar sobre aspeoplelist e imprima o nome e sobrenome de cada pessoa.
As
people variável da Linha 6 acima ficaria assim em Python:people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
A saída do programa acima é assim:
Kent Brockman
Bunny Easter
Doug Farrell
No programa acima, você precisa saber que o primeiro nome de uma pessoa está no índice
2 , e o sobrenome de uma pessoa está no índice 1 . Pior ainda, a estrutura interna de person também deve ser conhecido sempre que você passar a variável de iteração person como um parâmetro para uma função ou método. Seria muito melhor se o que você recebesse de
person era um objeto Python, onde cada um dos campos é um atributo do objeto. Esta é uma das coisas que o SQLAlchemy faz. Mesinhas do pequeno Bobby
No programa acima, a instrução SQL é uma string simples passada diretamente ao banco de dados para execução. Nesse caso, isso não é um problema porque o SQL é uma string literal completamente sob o controle do programa. No entanto, o caso de uso para sua API REST receberá a entrada do usuário do aplicativo da Web e a usará para criar consultas SQL. Isso pode abrir seu aplicativo para atacar.
Você se lembrará da Parte 1 que a API REST para obter uma única
person das PEOPLE os dados ficaram assim:GET /api/people/{lname}
Isso significa que sua API está esperando uma variável,
lname , no caminho do endpoint de URL, que ele usa para encontrar uma única person . Modificar o código Python SQLite acima para fazer isso seria algo assim: 1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
O trecho de código acima faz o seguinte:
-
Linha 1 define olnamevariável para'Farrell'. Isso viria do caminho do endpoint da URL da API REST.
-
Linha 2 usa a formatação de string Python para criar uma string SQL e executá-la.
Para manter as coisas simples, o código acima define o
lname variável para uma constante, mas na verdade viria do caminho do endpoint da URL da API e poderia ser qualquer coisa fornecida pelo usuário. O SQL gerado pela formatação da string se parece com isso:SELECT * FROM person WHERE lname = 'Farrell'
Quando este SQL é executado pelo banco de dados, ele busca a
person tabela para um registro onde o sobrenome é igual a 'Farrell' . Isso é o que se pretende, mas qualquer programa que aceite a entrada do usuário também está aberto a usuários mal-intencionados. No programa acima, onde o lname variável é definida pela entrada fornecida pelo usuário, isso abre seu programa para o que é chamado de ataque de injeção de SQL. Isto é o que é carinhosamente conhecido como Little Bobby Tables: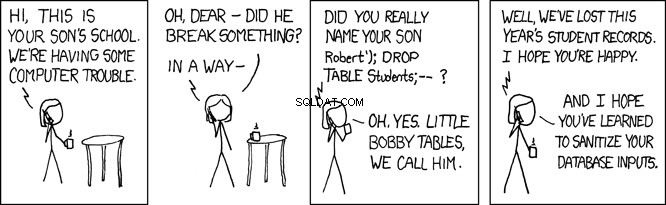
Por exemplo, imagine um usuário mal-intencionado chamado sua API REST desta forma:
GET /api/people/Farrell');DROP TABLE person;
A solicitação da API REST acima define o
lname variável para 'Farrell');DROP TABLE person;' , que no código acima geraria esta instrução SQL:SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
A instrução SQL acima é válida e, quando executada pelo banco de dados, encontrará um registro onde
lname corresponde a 'Farrell' . Em seguida, ele encontrará o caractere delimitador da instrução SQL ; e irá em frente e derrubará a mesa inteira. Isso basicamente destruiria seu aplicativo. Você pode proteger seu programa limpando todos os dados obtidos dos usuários de seu aplicativo. Sanitizar dados neste contexto significa fazer com que seu programa examine os dados fornecidos pelo usuário e certifique-se de que não contém nada perigoso para o programa. Isso pode ser complicado de fazer corretamente e teria que ser feito em todos os lugares em que os dados do usuário interagem com o banco de dados.
Existe outra maneira muito mais fácil:use SQLAlchemy. Ele irá higienizar os dados do usuário para você antes de criar instruções SQL. É outra grande vantagem e motivo para usar SQLAlchemy ao trabalhar com bancos de dados.
Modelagem de dados com SQLAlchemy
SQLAlchemy é um grande projeto e fornece muitas funcionalidades para trabalhar com bancos de dados usando Python. Uma das coisas que ele fornece é um ORM, ou Object Relational Mapper, e é isso que você vai usar para criar e trabalhar com a
person tabela de banco de dados. Isso permite mapear uma linha de campos da tabela do banco de dados para um objeto Python. A Programação Orientada a Objetos permite conectar dados com comportamento, as funções que operam nesses dados. Ao criar classes SQLAlchemy, você pode conectar os campos das linhas da tabela do banco de dados ao comportamento, permitindo que você interaja com os dados. Aqui está a definição da classe SQLAlchemy para os dados no
person tabela de banco de dados:class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
A classe
Person herda de db.Model , que você acessará quando começar a construir o código do programa. Por enquanto, significa que você está herdando de uma classe base chamada Model , fornecendo atributos e funcionalidades comuns a todas as classes derivadas dele. O restante das definições são atributos de nível de classe definidos da seguinte forma:
-
__tablename__ = 'person'conecta a definição de classe àpersontabela de banco de dados.
-
person_id = db.Column(db.Integer, primary_key=True)cria uma coluna de banco de dados contendo um inteiro atuando como chave primária para a tabela. Isso também informa ao banco de dados queperson_idserá um valor inteiro de autoincremento.
-
lname = db.Column(db.String)cria o campo de sobrenome, uma coluna de banco de dados contendo um valor de string.
-
fname = db.Column(db.String)cria o campo de nome, uma coluna de banco de dados contendo um valor de string.
-
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)cria um campo de carimbo de data/hora, uma coluna de banco de dados contendo um valor de data/hora. Odefault=datetime.utcnowO parâmetro padroniza o valor do timestamp para outcnowatual valor quando um registro é criado. Oonupdate=datetime.utcnowO parâmetro atualiza o timestamp com o atualutcnowvalor quando o registro é atualizado.
Observação:carimbos de data/hora UTC
Você pode estar se perguntando por que o timestamp na classe acima é padronizado e é atualizado pelo
datetime.utcnow() método, que retorna um UTC, ou Tempo Universal Coordenado. Essa é uma maneira de padronizar a origem do seu carimbo de data/hora. A fonte, ou tempo zero, é uma linha que vai de norte a sul do pólo norte ao sul da Terra através do Reino Unido. Este é o fuso horário zero do qual todos os outros fusos horários são deslocados. Ao usar isso como fonte de tempo zero, seus registros de data e hora são deslocamentos desse ponto de referência padrão.
Caso seu aplicativo seja acessado de fusos horários diferentes, você tem uma maneira de realizar cálculos de data/hora. Tudo o que você precisa é um carimbo de data/hora UTC e o fuso horário de destino.
Se você usar fusos horários locais como sua fonte de carimbo de data/hora, não poderá realizar cálculos de data/hora sem informações sobre os fusos horários locais deslocados do horário zero. Sem as informações da fonte do carimbo de data/hora, você não poderia fazer nenhuma comparação de data/hora ou matemática.
Trabalhar com timestamps baseados em UTC é um bom padrão a seguir. Aqui está um site de kit de ferramentas para trabalhar e entendê-los melhor.
Para onde você está indo com esta
Person definição de classe? O objetivo final é poder executar uma consulta usando SQLAlchemy e obter de volta uma lista de instâncias do Person aula. Como exemplo, vejamos a instrução SQL anterior:SELECT * FROM people ORDER BY lname;
Mostre o mesmo pequeno programa de exemplo acima, mas agora usando SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Ignorando a linha 1 por enquanto, o que você quer é toda a
person registros classificados em ordem crescente pelo lname campo. O que você obtém das instruções SQLAlchemy Person.query.order_by(Person.lname).all() é uma lista de Person objetos para todos os registros na person tabela de banco de dados nessa ordem. No programa acima, as people variável contém a lista de Person objetos. O programa itera sobre as
people variável, levando cada person por sua vez e imprimindo o nome e sobrenome da pessoa do banco de dados. Observe que o programa não precisa usar índices para obter o fname ou lname valores:usa os atributos definidos no Person objeto. Usar SQLAlchemy permite que você pense em termos de objetos com comportamento em vez de
SQL bruto . Isso se torna ainda mais benéfico quando suas tabelas de banco de dados se tornam maiores e as interações mais complexas. Serialização/desserialização de dados modelados
Trabalhar com dados modelados SQLAlchemy dentro de seus programas é muito conveniente. É especialmente conveniente em programas que manipulam os dados, talvez fazendo cálculos ou usando-os para criar apresentações na tela. Seu aplicativo é uma API REST essencialmente fornecendo operações CRUD nos dados e, como tal, não realiza muita manipulação de dados.
A API REST funciona com dados JSON e aqui você pode encontrar um problema com o modelo SQLAlchemy. Como os dados retornados por SQLAlchemy são instâncias de classe Python, o Connexion não pode serializar essas instâncias de classe para dados formatados em JSON. Lembre-se da Parte 1 que o Connexion é a ferramenta que você usou para projetar e configurar a API REST usando um arquivo YAML e conectar métodos Python a ele.
Nesse contexto, serializar significa converter objetos Python, que podem conter outros objetos Python e tipos de dados complexos, em estruturas de dados mais simples que podem ser analisadas em tipos de dados JSON, listados aqui:
string: um tipo de stringnumber: números suportados pelo Python (inteiros, floats, longs)object: um objeto JSON, que é aproximadamente equivalente a um dicionário Pythonarray: aproximadamente equivalente a uma lista Pythonboolean: representado em JSON comotrueoufalse, mas em Python comoTrueouFalsenull: essencialmente umNoneem Python
Como exemplo, sua
Person classe contém um timestamp, que é um Python DateTime . Não há definição de data/hora em JSON, portanto, o carimbo de data/hora deve ser convertido em uma string para existir em uma estrutura JSON. Sua
Person class é bastante simples, então obter os atributos de dados dele e criar um dicionário manualmente para retornar de nossos endpoints de URL REST não seria muito difícil. Em um aplicativo mais complexo com muitos modelos SQLAlchemy maiores, esse não seria o caso. Uma solução melhor é usar um módulo chamado Marshmallow para fazer o trabalho para você. Marshmallow ajuda você a criar um
PersonSchema class, que é como o SQLAlchemy Person classe que criamos. Aqui, no entanto, em vez de mapear tabelas de banco de dados e nomes de campo para a classe e seus atributos, o PersonSchema class define como os atributos de uma classe serão convertidos em formatos compatíveis com JSON. Aqui está a definição da classe Marshmallow para os dados em nossa person tabela:class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
A classe
PersonSchema herda de ma.ModelSchema , que você acessará quando começar a construir o código do programa. Por enquanto, isso significa PersonSchema está herdando de uma classe base Marshmallow chamada ModelSchema , fornecendo atributos e funcionalidades comuns a todas as classes derivadas dele. O resto da definição é a seguinte:
-
class Metadefine uma classe chamadaMetadentro de sua classe. OModelSchemaclasse que oPersonSchemaclasse herda de procura por esteMetainterno class e a usa para encontrar o modelo SQLAlchemyPersone odb.session. É assim que o Marshmallow encontra atributos noPersonclass e o tipo desses atributos para que saiba como serializá-los/desserializá-los.
-
modelinforma à classe qual modelo SQLAlchemy usar para serializar/desserializar dados de e para.
-
db.sessioninforma à classe qual sessão de banco de dados usar para introspecção e determinar tipos de dados de atributo.
Onde você está indo com esta definição de classe? Você deseja serializar uma instância de uma
Person class em dados JSON e desserializar dados JSON e criar um Person instâncias de classe dele. Criar o banco de dados inicializado
O SQLAlchemy lida com muitas das interações específicas de bancos de dados específicos e permite que você se concentre nos modelos de dados e em como usá-los.
Agora que você vai realmente criar um banco de dados, como mencionado anteriormente, você usará o SQLite. Você está fazendo isso por alguns motivos. Ele vem com Python e não precisa ser instalado como um módulo separado. Ele salva todas as informações do banco de dados em um único arquivo e, portanto, é fácil de configurar e usar.
A instalação de um servidor de banco de dados separado como MySQL ou PostgreSQL funcionaria bem, mas exigiria a instalação desses sistemas e sua colocação em funcionamento, o que está além do escopo deste artigo.
Como o SQLAlchemy lida com o banco de dados, de muitas maneiras, realmente não importa qual é o banco de dados subjacente.
Você vai criar um novo programa utilitário chamado
build_database.py para criar e inicializar o SQLite people.db arquivo de banco de dados contendo sua person tabela de banco de dados. Ao longo do caminho, você criará dois módulos Python, config.py e models.py , que será usado por build_database.py e o server.py modificado da Parte 1. Aqui é onde você pode encontrar o código-fonte dos módulos que você está prestes a criar, que são apresentados aqui:
-
config.pyobtém os módulos necessários importados para o programa e configurados. Isso inclui Flask, Connexion, SQLAlchemy e Marshmallow. Porque será usado tanto porbuild_database.pyeserver.py, algumas partes da configuração serão aplicadas apenas aoserver.pyinscrição.
-
models.pyé o módulo onde você criará aPersonSQLAlchemy ePersonSchemaDefinições de classe de marshmallow descritas acima. Este módulo depende deconfig.pypara alguns dos objetos criados e configurados lá.
Módulo de configuração
O
config.py módulo, como o nome indica, é onde todas as informações de configuração são criadas e inicializadas. Vamos usar este módulo para nosso build_database.py arquivo de programa e o arquivo server.py que será atualizado em breve arquivo do artigo da Parte 1. Isso significa que vamos configurar Flask, Connexion, SQLAlchemy e Marshmallow aqui. Mesmo que o
build_database.py O programa não usa Flask, Connexion ou Marshmallow, ele usa SQLAlchemy para criar nossa conexão com o banco de dados SQLite. Aqui está o código para o config.py módulo: 1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Veja o que o código acima está fazendo:
-
Linhas 2 a 4 importe o Connexion como você fez noserver.pyprograma da Parte 1. Ele também importaSQLAlchemydoflask_sqlalchemymódulo. Isso dá acesso ao banco de dados do seu programa. Por fim, importaMarshmallowdoflask_marshamllowmódulo.
-
Linha 6 cria a variávelbasedirapontando para o diretório em que o programa está sendo executado.
-
Linha 9 usa obasedirvariável para criar a instância do aplicativo Connexion e fornecer o caminho para oswagger.ymlArquivo.
-
Linha 12 cria uma variávelapp, que é a instância do Flask inicializada pelo Connexion.
-
Linhas 15 usa oappvariável para configurar os valores usados pelo SQLAlchemy. Primeiro ele defineSQLALCHEMY_ECHOparaTrue. Isso faz com que o SQLAlchemy ecoe as instruções SQL que ele executa no console. Isso é muito útil para depurar problemas ao construir programas de banco de dados. Defina isso comoFalsepara ambientes de produção.
-
Linha 16 defineSQLALCHEMY_DATABASE_URIparasqlite:////' + os.path.join(basedir, 'people.db'). Isso diz ao SQLAlchemy para usar o SQLite como banco de dados e um arquivo chamadopeople.dbno diretório atual como o arquivo de banco de dados. Diferentes mecanismos de banco de dados, como MySQL e PostgreSQL, terão diferentesSQLALCHEMY_DATABASE_URIstrings para configurá-los.
-
Linha 17 defineSQLALCHEMY_TRACK_MODIFICATIONSparaFalse, desativando o sistema de eventos SQLAlchemy, que está ativado por padrão. O sistema de eventos gera eventos úteis em programas orientados a eventos, mas adiciona uma sobrecarga significativa. Como você não está criando um programa orientado a eventos, desative esse recurso.
-
Linha 19 cria odbvariável chamandoSQLAlchemy(app). Isso inicializa o SQLAlchemy passando oappinformações de configuração acabou de definir. Odbvariável é o que é importado para obuild_database.pyprograma para dar acesso ao SQLAlchemy e ao banco de dados. Ele servirá ao mesmo propósito noserver.pyprogram epeople.pymódulo.
-
Linha 23 cria omavariável chamandoMarshmallow(app). Isso inicializa o Marshmallow e permite que ele introspecione os componentes SQLAlchemy anexados ao aplicativo. É por isso que o Marshmallow é inicializado após o SQLAlchemy.
Módulo de modelos
O
models.py módulo é criado para fornecer a Person e PersonSchema classes exatamente como descrito nas seções acima sobre modelagem e serialização dos dados. Segue o código desse módulo: 1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Veja o que o código acima está fazendo:
-
Linha 1 importa odatetimeobjeto dodatetimemódulo que vem com o Python. Isso oferece uma maneira de criar um carimbo de data/hora noPersonaula.
-
Linha 2 importa odbemavariáveis de instância definidas noconfig.pymódulo. Isso dá ao módulo acesso aos atributos e métodos SQLAlchemy anexados aodbvariável e os atributos e métodos do Marshmallow anexados aomavariável.
-
Linhas 4 a 9 defina aPersonclass conforme discutido na seção de modelagem de dados acima, mas agora você sabe onde odb.Modelque a classe herda origina. Isso dá àPersonrecursos de classe SQLAlchemy, como uma conexão com o banco de dados e acesso às suas tabelas.
-
Linhas 11 a 14 defina oPersonSchemaclass como foi discutido na seção de serialização de dados acima. Esta classe herda dema.ModelSchemae fornece oPersonSchemarecursos de classe Marshmallow, como introspecção daPersonclass para ajudar a serializar/desserializar instâncias dessa classe.
Criando o banco de dados
Você viu como as tabelas de banco de dados podem ser mapeadas para classes SQLAlchemy. Agora use o que você aprendeu para criar o banco de dados e preenchê-lo com dados. You’re going to build a small utility program to create and build the database with the
People data. Here’s the build_database.py program: 1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports thedbinstance from theconfig.pymodule.
-
Line 3 imports thePersonclass definition from themodels.pymodule.
-
Lines 6 – 10 create thePEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space.
-
Lines 13 &14 perform some simple housekeeping to delete thepeople.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database.
-
Line 17 creates the database with thedb.create_all()ligar. This creates the database by using thedbinstance imported from theconfigmodule. Odbinstance is our connection to the database.
-
Lines 20 – 22 iterate over thePEOPLElist and use the dictionaries within to instantiate aPersonaula. After it is instantiated, you call thedb.session.add(p)function. This uses the database connection instancedbto access thesessionobjeto. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobjeto.
-
Line 24 callsdb.session.commit()to actually save all the person objects created to the database.
Observação: At Line 22, no data has been added to the database. Everything is being saved within the
session objeto. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it. In SQLAlchemy, the
session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program. Now you’re ready to run the
build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting
SQLALCHEMY_ECHO to True in the config.py Arquivo. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the
person_id primary key value in our database as the unique identifier rather than the lname valor. Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the
person_id variable in the URL path:| Action | HTTP Verb | URL Path | Descrição |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an
lname value, they now require the person_id (primary key) for the person record in the people tabela. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name. In order for you to implement these changes, the
swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT respostas. You can check out the updated swagger.yml Arquivo. Update the REST API Handlers
With the
swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname . Here’s part of the updated
person.py module showing the handler for the REST URL endpoint GET /api/people : 1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing thedbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results.
-
Line 11 starts the definition ofread_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name.
-
Lines 19 – 22 tell SQLAlchemy to query thepersondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople.
-
Line 24 is where the MarshmallowPersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is.
-
Line 25 uses thePersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Observação: The
people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:TypeError: Object of type Person is not JSON serializable
Here’s another part of the
person.py module that makes a request for a single person from the person base de dados. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} : 1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use theperson_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found.
-
Line 15 determines whether apersonwas found or not.
-
Line 17 shows that, ifpersonwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instância. Instead, you passmany=Falsebecause only a single object is passed in to serialize.
-
Line 18 is where thedumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned.
-
Line 23 shows that, ifpersonwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to
person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objeto. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people : 1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set thefnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request.
-
Lines 12 – 15 use the SQLAlchemyPersonclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson.
-
Line 18 addresses whetherexisting_personisNone. (existing_personwas not found.)
-
Line 21 creates aPersonSchema()instance calledschema.
-
Line 22 uses theschemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person.
-
Line 25 adds thenew_personinstance to thedb.session.
-
Line 26 commits thenew_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp.
-
Line 33 shows that, ifexisting_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the
GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this: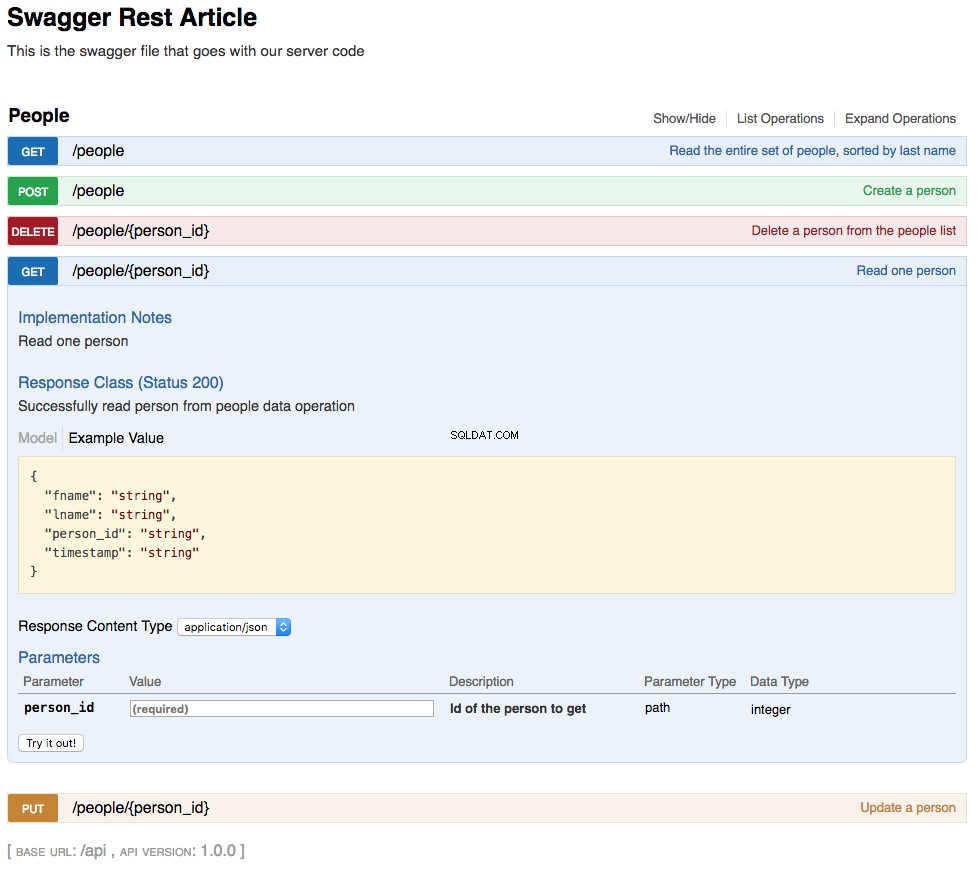
As shown in the above screenshot, the path parameter
lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that. Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using
person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code. This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the
build_database.py utility program and the server.py modified example program from Part 1. Conclusão
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the
R part of RDBMS :relationships, which provide even more power when you are using a database. « Part 1:REST APIs With Flask + ConnexionPart 2:Database PersistencePart 3:Database Relationships »