Em um blog anterior, discutimos como migrar uma configuração autônoma do Moodle para uma configuração escalável baseada em um banco de dados em cluster. A próxima etapa na qual você precisará pensar é o mecanismo de failover - o que você faz se e quando o serviço de banco de dados ficar inativo.
Um servidor de banco de dados com falha não é incomum se você tiver o MySQL Replication como seu banco de dados Moodle de back-end e, se isso acontecer, você precisará encontrar uma maneira de recuperar sua topologia, por exemplo, promovendo um servidor em espera para tornar-se um novo servidor primário. Ter failover automático para seu banco de dados MySQL do Moodle ajuda no tempo de atividade do aplicativo. Explicaremos como os mecanismos de failover funcionam e como criar o failover automático em sua configuração.
Arquitetura de alta disponibilidade para banco de dados MySQL
A arquitetura de alta disponibilidade pode ser alcançada agrupando seu banco de dados MySQL de duas maneiras diferentes. Você pode usar a Replicação MySQL, configurar várias réplicas que seguem de perto seu banco de dados primário. Além disso, você pode colocar um balanceador de carga de banco de dados para dividir o tráfego de leitura/gravação e distribuir o tráfego entre nós de leitura-gravação e somente leitura. A arquitetura de banco de dados de alta disponibilidade usando a Replicação MySQL pode ser descrita abaixo:
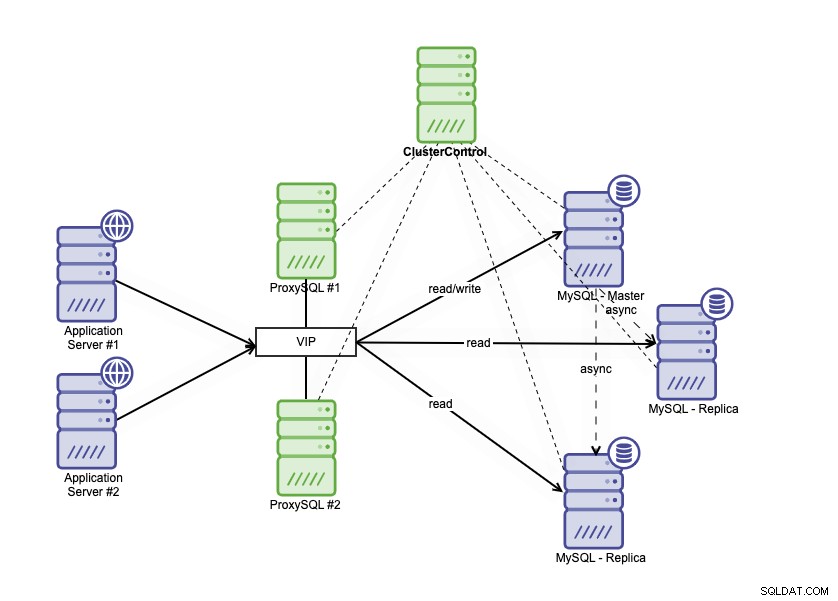
Ele consiste em um banco de dados primário, duas réplicas de banco de dados e balanceadores de carga de banco de dados (neste blog, usamos ProxySQL como balanceadores de carga de banco de dados) e keepalived como um serviço para monitorar os processos do ProxySQL. Usamos o Endereço IP Virtual como uma única conexão do aplicativo. O tráfego será distribuído para o balanceador de carga ativo com base no sinalizador de função em keepalived.
O ProxySQL é capaz de analisar o tráfego e entender se uma solicitação é uma leitura ou uma gravação. Em seguida, ele encaminhará a solicitação para o(s) host(s) apropriado(s).
Failover na replicação do MySQL
A Replicação MySQL usa log binário para replicar dados do primário para as réplicas. As réplicas se conectam ao nó principal e cada alteração é replicada e gravada nos registros de retransmissão dos nós de réplica por meio de IO_THREAD. Após as alterações serem armazenadas no log de retransmissão, o processo SQL_THREAD prosseguirá com a aplicação de dados no banco de dados de réplica.
A configuração padrão para o parâmetro read_only em uma réplica é ATIVADO. Ele é usado para proteger a própria réplica de qualquer gravação direta, portanto, as alterações sempre virão do banco de dados primário. Isso é importante, pois não queremos que a réplica divirja do servidor primário. O cenário de failover na Replicação do MySQL acontece quando o primário não está acessível. Pode haver muitas razões para isso; por exemplo, falhas no servidor ou problemas de rede.
Você precisa promover uma das réplicas para primária, desabilitar o parâmetro somente leitura na réplica promovida para que possa ser gravável. Você também precisa alterar a outra réplica para se conectar ao novo primário. No modo GTID, você não precisa anotar o nome do log binário e a posição de onde retomar a replicação. No entanto, na replicação tradicional baseada em log binário, você definitivamente precisa saber o nome e a posição do último log binário a partir do qual continuar. O failover na replicação baseada em log binário é um processo bastante complexo, mas mesmo o failover na replicação baseada em GTID também não é trivial, pois você precisa observar coisas como transações errôneas. Detectar uma falha é uma coisa e, em seguida, reagir à falha em um pequeno atraso provavelmente não é possível sem automação.
Como o ClusterControl permite o failover automático
ClusterControl tem a capacidade de executar failover automático para seu banco de dados MySQL do Moodle. Há um recurso de recuperação automática para cluster e nó que acionará o processo de failover quando o banco de dados primário falhar.
Vamos simular como o Failover Automático acontece no ClusterControl. Faremos o crash do banco de dados primário, e só veremos no painel do ClusterControl. Abaixo está a topologia atual do cluster:
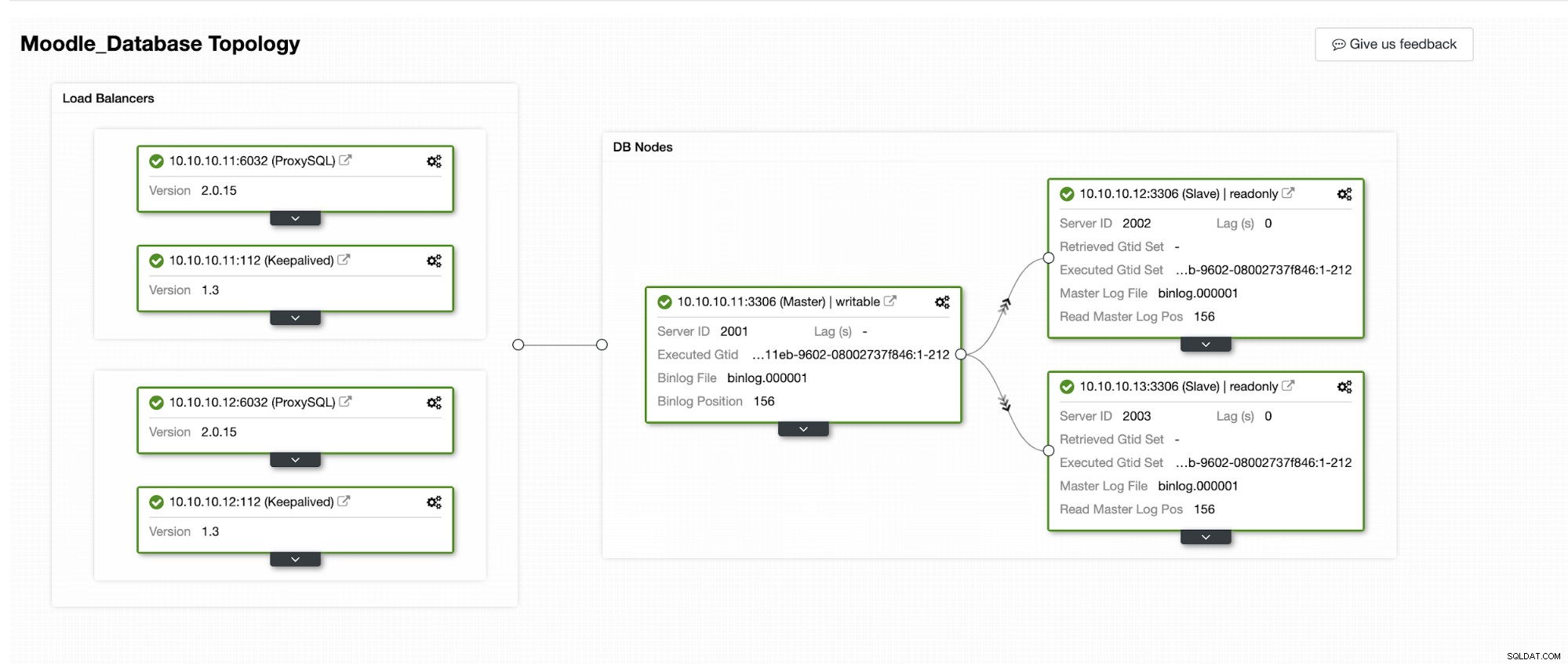
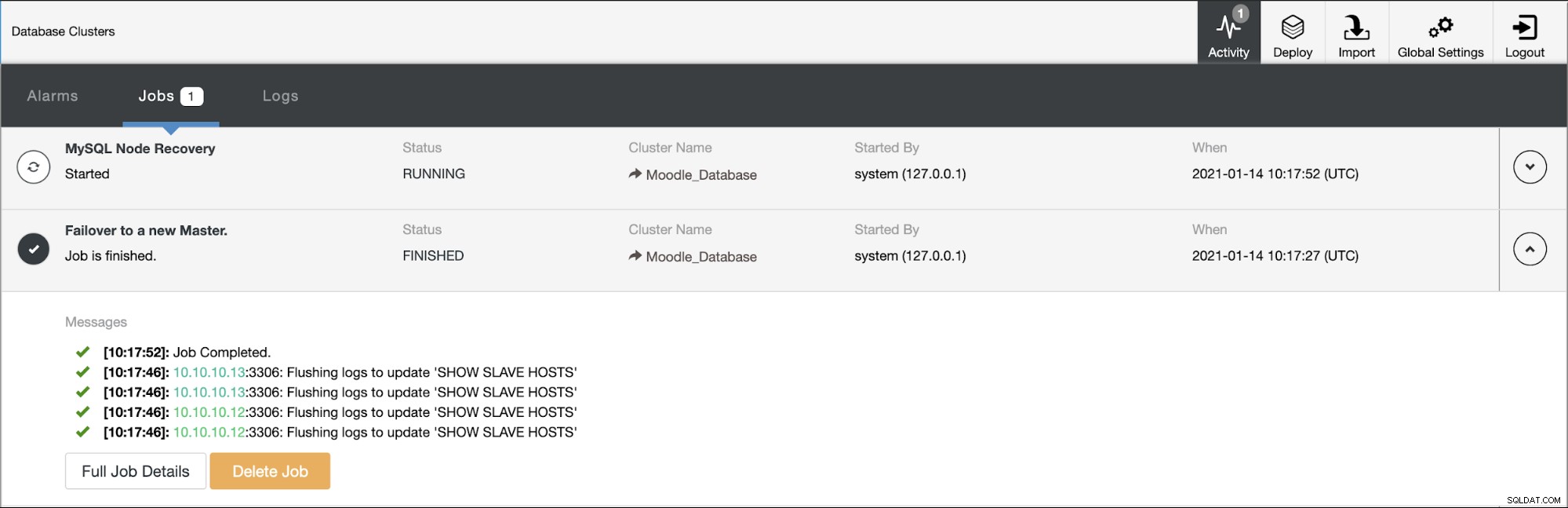
O banco de dados primário está usando o endereço IP 10.10.10.11 e as réplicas são:10.10.10.12 e 10.10.10.13. Quando a falha ocorre no primário, o ClusterControl aciona um alerta e um failover é iniciado conforme mostrado na imagem abaixo:
Uma das réplicas será promovida para primária, resultando na topologia como na imagem abaixo:
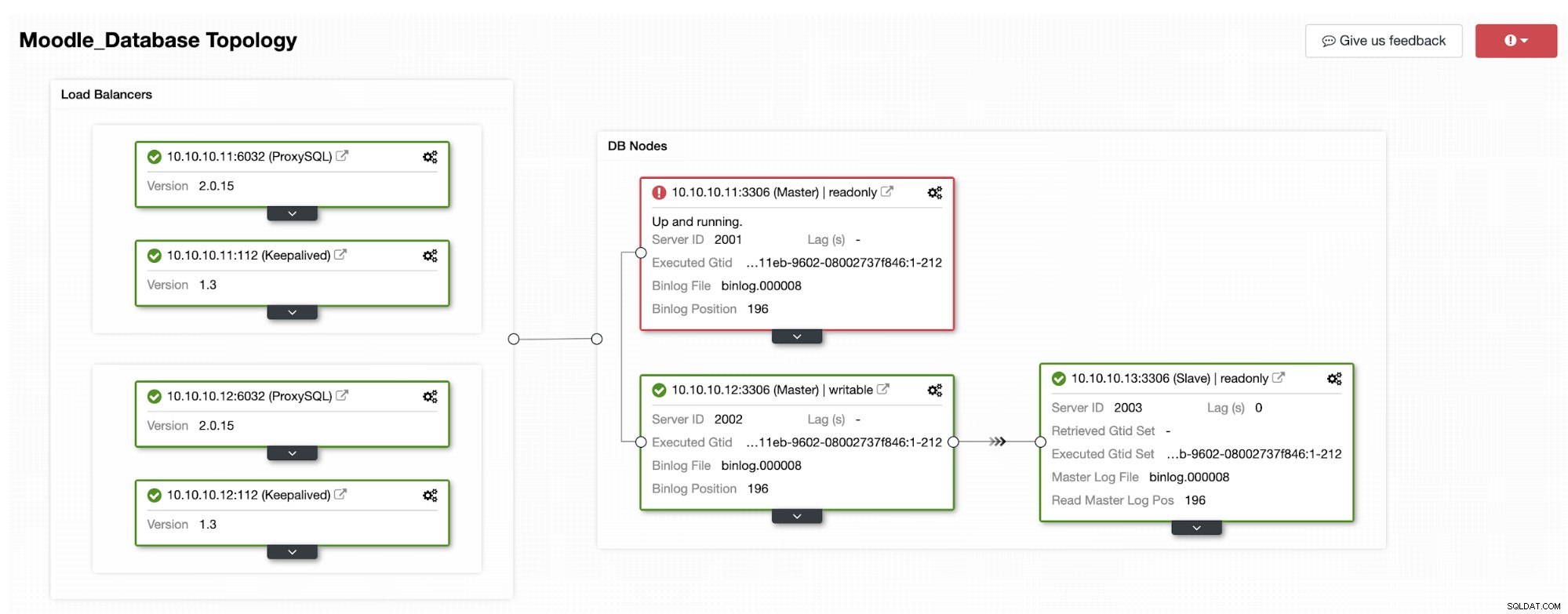
O endereço IP 10.10.10.12 agora está atendendo o tráfego de gravação como primário, e também ficamos com apenas uma réplica que tem o endereço IP 10.10.10.13. No lado do ProxySQL, o proxy detectará o novo primário automaticamente. O Hostgroup (HG10) ainda atende o tráfego de gravação que possui o membro 10.10.10.12 conforme mostrado abaixo:

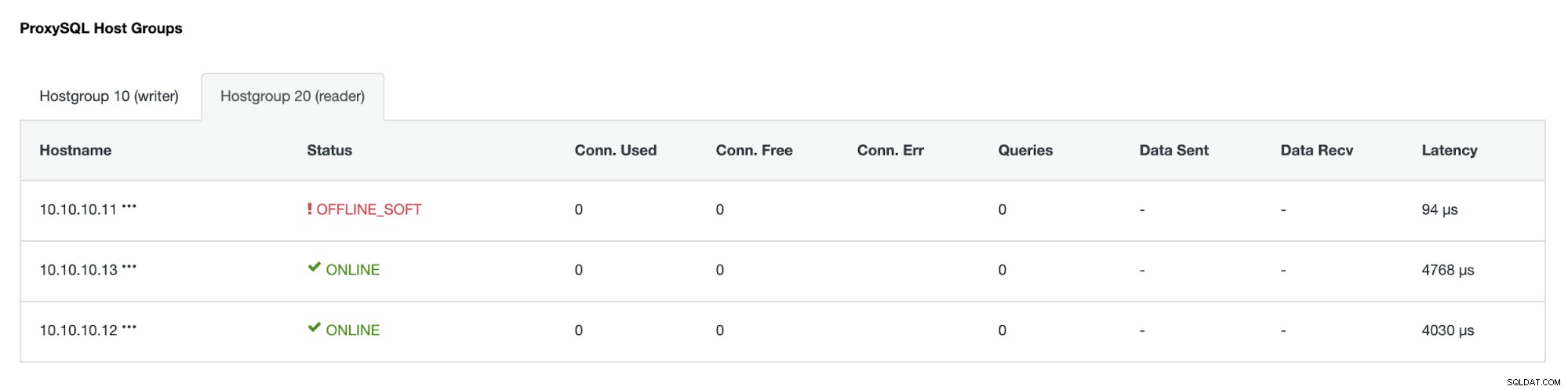
Hostgroup (HG20) ainda pode servir o tráfego de leitura, mas como você pode ver o nó 10.10.10.11 está offline por causa da falha:
Depois que o servidor principal com falha voltar a ficar online, ele não será reiniciado automaticamente -introduzido na topologia de banco de dados. Isso é para evitar a perda de informações de solução de problemas, pois a reintrodução do nó como uma réplica pode exigir a substituição de alguns logs ou outras informações. Mas é possível configurar o reingresso automático do nó com falha.



