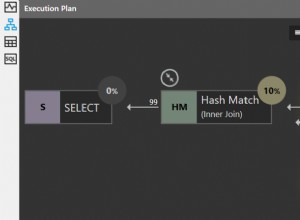
Estamos no meio do ciclo entre os lançamentos, onde ainda não ouvimos sobre nenhum dos recursos planejados para SQL Server vNext. Este é provavelmente o melhor momento para pressionar a Microsoft por melhorias, desde que possamos apoiar nossas solicitações com casos de negócios legítimos. No SQL Server 2016,
Estamos no meio do ciclo entre os lançamentos, onde ainda não ouvimos sobre nenhum dos recursos planejados para SQL Server vNext. Este é provavelmente o melhor momento para pressionar a Microsoft por melhorias, desde que possamos apoiar nossas solicitações com casos de negócios legítimos. No SQL Server 2016, STRING_SPLIT resolveu uma lacuna há muito perdida em uma linguagem que, reconhecidamente, não se destinava ao processamento complicado de strings. E é isso que quero trazer hoje. Durante anos antes do SQL Server 2016 (e desde então), escrevemos nossas próprias versões, as melhoramos ao longo do tempo e até discutimos sobre quem era mais rápido. Nós escrevemos sobre cada microssegundo que podíamos ganhar e eu, por exemplo, afirmei várias vezes, "este é meu último post sobre dividir strings!" No entanto, aqui estamos.
Sempre argumentarei que os parâmetros com valor de tabela são a maneira certa de separar strings. Mas enquanto eu acredito que esses blobs de texto separados por vírgulas nunca devem ser expostos ao banco de dados dessa forma, a divisão de strings continua a ser um caso de uso predominante - alguns dos meus posts aqui estão no top 5 em visualizações todos os dias .
Então, por que as pessoas ainda estão tentando dividir strings com funções com valor de tabela quando existe uma substituição superior? Alguns, tenho certeza, porque ainda estão em versões mais antigas, presos em um nível de compatibilidade mais antigo ou não conseguem evitar a divisão de strings porque os TVPs não são suportados por seu idioma ou ORM. Para o resto, enquanto
STRING_SPLIT é conveniente e eficiente, não é perfeito. Ele tem restrições que trazem algum atrito e que tornam a substituição de chamadas de função existentes por uma chamada nativa complicada ou impossível. Aqui está minha lista.
Essas limitações não são exaustivas, mas listei as mais importantes em meu ordem de prioridade (e Andy Mallon escreveu sobre isso hoje também):
- Delimitador de caractere único
Parece que a função foi criada com apenas o caso de uso simples em mente:CSV. As pessoas têm strings mais complexas que1,2,3ouA|B|C, e eles geralmente são alimentados em seus bancos de dados de sistemas fora de seu controle. Como descrevo nesta resposta e nesta dica, existem maneiras de contornar isso (operações de substituição realmente ineficientes), mas elas são realmente feias e, francamente, desfazem todos os benefícios de desempenho oferecidos pela implementação nativa. Além disso, alguns dos atritos com este se resumem especificamente a:"Bem, ostring_to_arraydo PostgreSQL lida com vários delimitadores de caracteres, então por que o SQL Server não pode?" Implementação:Aumente o tamanho máximo doseparator. - Sem indicação de ordem de entrada
A saída da função é um conjunto e, inerentemente, os conjuntos não têm ordem. E enquanto na maioria dos casos você verá uma string de entrada comobob,ted,franksair nessa ordem (bobtedfrank), não há garantia (com ou sem um(ORDER BY (SELECT NULL))hack). Muitas funções internas incluem uma coluna de saída para indicar a posição ordinal na string, o que pode ser importante se a lista estiver organizada em uma ordem definida ou a posição ordinal exata tiver algum significado.Implementação:Adicione uma opção para incluir a coluna de posição ordinal em a saída. - O tipo de saída é baseado apenas na entrada
A coluna de saída da função é fixada emvarcharounvarchar, e é determinado precisamente pelo comprimento de toda a string de entrada, não pelo comprimento do elemento mais longo. Então, você tem uma lista de 25 letras, o tipo de saída é pelo menosvarchar(51). Para strings mais longas, isso pode resultar em problemas com concessões de memória, dependendo do uso, e pode apresentar problemas se o consumidor depender de outro tipo de dados sendo gerado (digamos,int, que funções às vezes especificam para evitar conversões implícitas posteriormente). Como solução alternativa, os usuários às vezes criam suas próprias tabelas temporárias ou variáveis de tabela e despejam a saída da função antes de interagir com ela, o que pode levar a problemas de desempenho. Implementação:Adicione uma opção para especificar o tipo de saída do valorvalue. - Não é possível ignorar elementos vazios ou delimitadores à direita
Quando você tem uma string comoa,,,b,, você pode esperar que apenas dois elementos sejam gerados, já que os outros três estão vazios. A maioria dos TVFs personalizados que vi cortam delimitadores à direita e/ou filtram strings de comprimento zero, masSTRING_SPLITretorna todas as 5 linhas. Isso dificulta a troca na função nativa porque você também precisa adicionar lógica de encapsulamento para eliminar essas entidades. Implementação:Adicione uma opção para ignorar elementos vazios. - Não é possível filtrar duplicatas
Esta é provavelmente uma solicitação menos comum e fácil de resolver usandoDISTINCTouGROUP BY, mas muitas funções fazem isso automaticamente para você. Não há diferença real no desempenho nesses casos, mas existe se for algo que você mesmo esqueceu de adicionar (pense em uma lista grande, com muitas duplicatas, juntando-se a uma tabela grande).
Implementação:adicione uma opção para filtrar duplicatas.
Aqui está o caso de negócios.
Tudo isso parece teórico, mas aqui está o caso de negócios, que posso garantir que é muito real. Na Wayfair, temos uma propriedade substancial do SQL Server e temos literalmente dezenas de equipes diferentes que criaram suas próprias funções com valor de tabela ao longo dos anos. Alguns são melhores que outros, mas todos são chamados a partir de milhares e milhares de linhas de código. Recentemente, iniciamos um projeto em que estamos tentando substituí-los por chamadas para
STRING_SPLIT , mas encontramos casos de bloqueio envolvendo várias das limitações acima. Alguns são fáceis de contornar, usando uma função wrapper. Mas o delimitador de caractere único limitação nos forçou a avaliar a terrível solução usando
REPLACE , e isso provou eliminar o benefício de desempenho que esperávamos, fazendo com que pudéssemos pisar nos freios. E nesses casos, perdemos uma chave de barganha ao pressionar por atualizações para o nível de compatibilidade (nem todos os bancos de dados estão em 130, muito menos em 140). Nesses casos, estamos perdendo não apenas em STRING_SPLIT melhorias, mas também em outras mais de 130 melhorias de desempenho que gostaríamos se STRING_SPLIT tinha sido convincente o suficiente por si só para empurrar para a atualização do nível de compatibilidade. Então, peço sua ajuda.
Visite este item de feedback:
- STRING_SPLIT não está completo
Vote! Mais importante, deixe um comentário descrevendo casos de uso reais que você tem que fazem
STRING_SPLIT uma dor ou um non-starter para você. Os votos por si só não são suficientes, mas, com feedback tangível e qualitativo suficiente, há uma chance de que eles comecem a levar essas lacunas a sério. Tenho vontade de dar suporte a delimitadores de vários caracteres (até mesmo, digamos, expandindo de
[n]varchar(1) para [n]varchar(5) ) é uma melhoria não intrusiva que desbloqueará muitas pessoas que compartilham meu cenário. Outros aprimoramentos podem ser mais difíceis de implementar, alguns exigindo sobrecargas e/ou aprimoramentos de linguagem, portanto, não espero todas essas correções no vNext. Mas mesmo uma pequena melhoria reiteraria que STRING_SPLIT foi um investimento que valeu a pena, e que não vai ser abandonado (como, digamos, bancos de dados contidos, um dos recursos drive-by mais famosos). Obrigado por ouvir!