Um compromisso de ajuste de desempenho pode acabar dando muitas voltas à medida que você trabalha nele – tudo depende do que está aparecendo como o problema e do que os dados informam. Alguns dias, ele chega a uma consulta específica, ou conjunto de consultas, que pode ser aprimorada com índices – novos ou modificações em índices existentes. Uma das minhas partes favoritas do ajuste é trabalhar com índices e, enquanto estava pensando neste post, fiquei tentado a rotular o ajuste de índice como uma tarefa “mais fácil” … mas realmente não é.
Eu penso no ajuste de índice como uma arte e uma ciência. Você deve tentar pensar como o otimizador e deve entender o esquema da tabela e a consulta (ou consultas) que está tentando ajustar. Ambos são orientados por dados e, portanto, na categoria de ciência. O componente de arte entra em jogo quando você pensa no outro índices na tabela e todos o outro consultas que envolvem a tabela que pode ser afetada por alterações de índice.
Etapa 1:identifique a consulta e revise o plano
Quando identifico uma consulta que pode se beneficiar de um índice, recebo imediatamente seu plano. Costumo obter o Plano de Execução do cache do plano ou do Repositório de Consultas e, em seguida, uso o SSMS para obter o Plano de Execução mais as Estatísticas de Tempo de Execução (também conhecido como Plano de Execução Real). Muitas vezes, a forma desses dois planos é a mesma; mas não é uma garantia, e é por isso que gosto de ver os dois.
O plano pode ter uma recomendação de índice ausente, pode ter uma verificação de índice clusterizado (ou verificação de heap se não houver nenhum índice clusterizado), pode usar um índice não clusterizado, mas depois fazer uma pesquisa para recuperar colunas adicionais. Corrigir cada um desses problemas individualmente parece muito fácil. Basta adicionar o índice ausente, certo? Se houver uma varredura de um índice clusterizado ou heap, crie o índice que preciso para a consulta e pronto? Ou se houver um índice sendo usado, mas ele for para a tabela para obter as colunas adicionais, basta adicionar as colunas a esse índice?
Geralmente não é tão fácil e, mesmo quando é, ainda passo pelo processo que estou descrevendo aqui.
Etapa 2:determine quais tabelas revisar
Agora que tenho minha consulta, preciso descobrir quais tabelas não estão indexadas corretamente. Além de revisar o plano, também habilito estatísticas de IO e TEMPO no SSMS. Isso provavelmente é antiquado da minha parte, pois os planos de execução contêm mais e mais informações – incluindo duração e números de IO por operador – a cada versão, mas gosto das estatísticas de IO porque posso ver rapidamente as leituras de cada tabela. Para consultas complexas com várias junções, subconsultas, CTEs ou exibições aninhadas, entender onde o IO e/ou o tempo é gasto nas unidades de consulta em que gasto meu tempo. Sempre que possível, a partir deste ponto, pego a consulta maior e complexa e a reduzo à parte que está causando o maior problema.
Por exemplo, se houver uma consulta que se une a 10 tabelas e tem duas subconsultas, o plano (junto com as informações de IO e duração) me ajuda a identificar onde está o problema. Em seguida, retirarei essa parte da consulta – a tabela problemática e talvez algumas outras às quais ela se une – e focarei nela. Às vezes é apenas a subconsulta, então começo por aí.
Etapa 3:observe os índices existentes
Com a consulta (ou parte da consulta) definida, então foco nos índices existentes para as tabelas envolvidas. Para esta etapa, confio na versão de sp_helpindex da Kimberly. Eu prefiro a versão dela ao sp_helpindex padrão porque também lista as colunas INCLUDEd e a definição do filtro (se houver). Dependendo do número de índices que aparecem para uma tabela, geralmente copio isso e colo no Excel e, em seguida, ordeno com base na chave de índice e nas colunas incluídas. Isso me permite encontrar quaisquer redundâncias rapidamente.
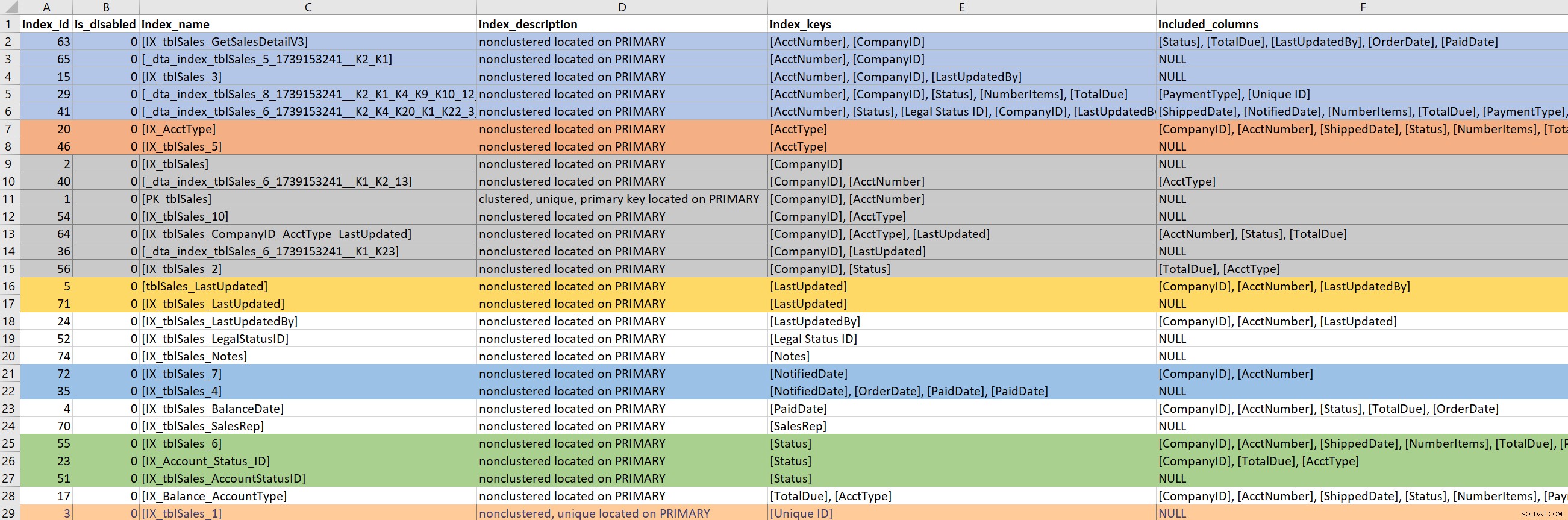
Com base na saída de exemplo acima, há sete índices que começam com CompanyID, cinco que começam com AcctNumber e algumas outras redundâncias potenciais. Embora pareça ideal ter apenas um índice que leva em uma coluna específica (por exemplo, CompanyID), para alguns padrões de consulta que não são suficientes.
Quando estou olhando para os índices existentes, é muito fácil entrar em uma toca de coelho. Eu olho para a saída acima e imediatamente começo a perguntar por que existem sete índices que começam com CompanyID e quero saber quem os criou, por que e para qual consulta. Mas… se minha consulta problemática não usa CompanyID, devo me importar? Sim… porque em geral estou lá para melhorar o desempenho, e se isso significa olhar para outros índices na mesa ao longo do caminho, que assim seja. Mas é aqui que é fácil perder a noção do tempo (e do verdadeiro propósito).
Se minha consulta problemática precisar de um índice que conduza a PaidDate, só tenho que lidar com um índice existente. Se minha consulta problemática precisar de um índice que conduza AcctNumber, fica complicado. Quando os índices existentes cobrem uma consulta e estou procurando expandir um índice (adicionar mais colunas) ou consolidar (mesclar dois ou talvez três índices em um), então tenho que me aprofundar.
Etapa 4:Estatísticas de uso do índice
Acho que muitas pessoas não capturam estatísticas de uso do índice continuamente. Isso é lamentável, porque considero os dados úteis ao decidir quais índices manter e quais descartar ou mesclar. No caso em que não tenho estatísticas de uso histórico, pelo menos verifico como está o uso atualmente (desde a última reinicialização do serviço):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales'); 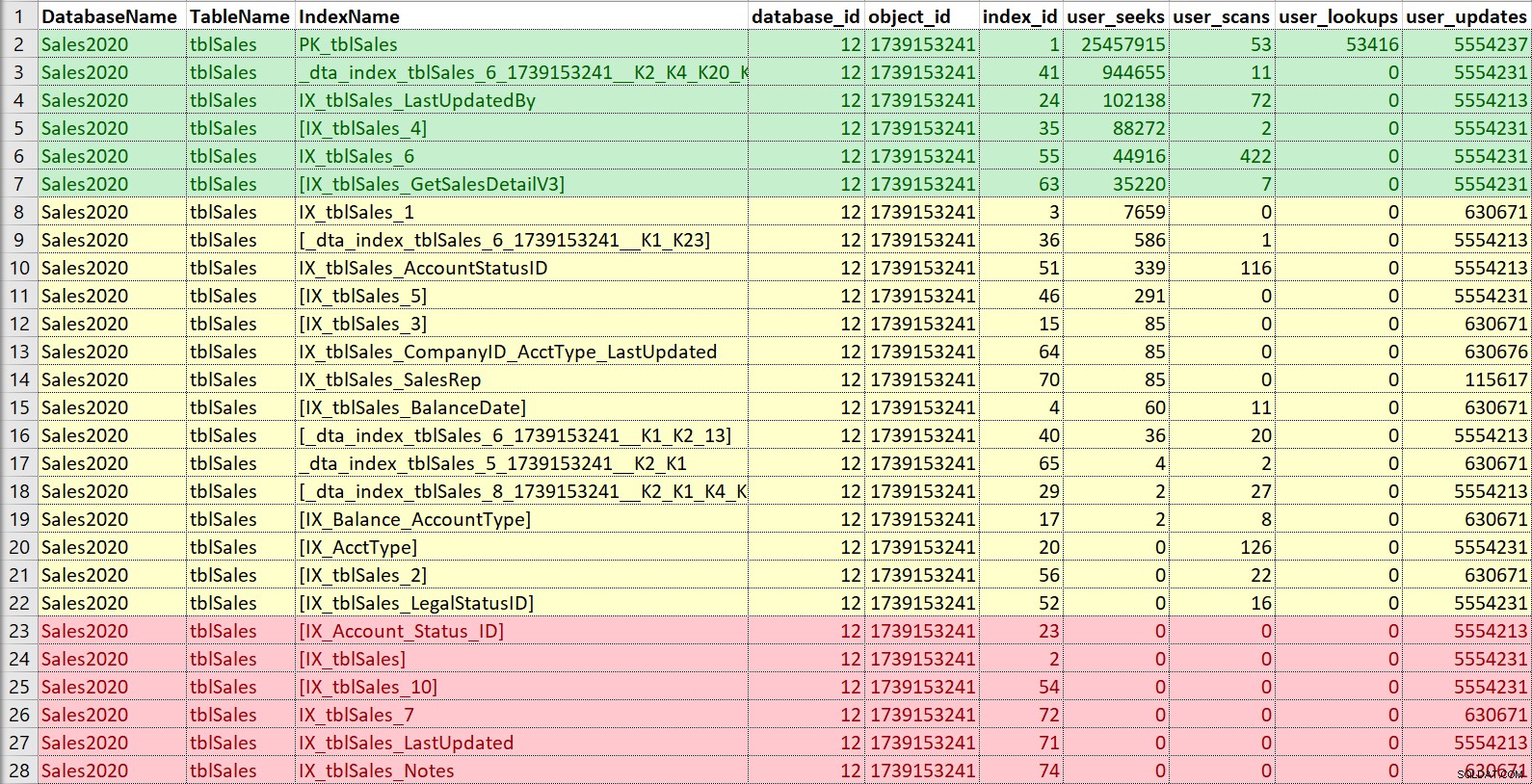
Mais uma vez, gosto de colocar isso no Excel, classificar por buscas e varreduras, e também anotar as atualizações. Para este exemplo, os índices em vermelho são aqueles sem buscas, varreduras ou pesquisas... apenas atualizações. Esses são candidatos a serem desativados e potencialmente descartados, se realmente não forem usados (novamente, ter histórico de uso ajudaria aqui). Os índices em verde estão definitivamente sendo usados, eu quero mantê-los (embora talvez em alguns casos eles possam ser ajustados). As de amarelo... algumas estão meio usadas, outras mal usadas. Novamente, o histórico seria útil aqui, ou o contexto de outros — às vezes, um índice pode ser crucial para um relatório ou processo que não é executado o tempo todo.
Se estou apenas procurando modificar ou adicionar um novo índice, em vez de uma verdadeira limpeza e consolidação, estou mais preocupado com quaisquer índices semelhantes ao que desejo adicionar ou alterar. No entanto, vou me certificar de apontar as informações de uso para o cliente e, se houver tempo, ajudar na estratégia geral de indexação da tabela.
O que vem a seguir?
Nós não terminamos! Esta é a parte 1 da minha abordagem para ajuste de índice, e minha próxima parte listará o restante dos meus passos. Enquanto isso, se você não estiver capturando estatísticas de uso do índice, isso é algo que você pode implementar usando a consulta acima ou outra variação. Eu recomendaria capturar estatísticas de uso para todos os bancos de dados de usuários, não apenas para uma tabela e banco de dados específicos, como fiz acima, portanto, modifique o predicado conforme necessário. E, finalmente, como parte desse trabalho agendado para capturar essas informações em uma tabela, não se esqueça de outra etapa para limpar a tabela depois que os dados estiverem lá por um tempo (eu os mantenho por pelo menos seis meses; alguns podem dizer que um ano é necessário).