Há muito tempo defendo a escolha do tipo de dados correto. Falei sobre alguns exemplos em uma postagem anterior do blog "Bad Habits", mas neste fim de semana no SQL Saturday #162 (Cambridge, Reino Unido), o tópico de uso de
DATETIME por padrão surgiu. Em uma conversa após minha apresentação T-SQL:Bad Habits and Best Practices, um usuário afirmou que eles apenas usam DATETIME mesmo que eles precisem apenas de granularidade para o minuto ou dia, dessa forma as colunas de data/hora em toda a empresa são sempre do mesmo tipo de dados. Eu sugeri que isso poderia ser um desperdício, e que a consistência poderia não valer a pena, mas hoje eu decidi provar minha teoria. TL;versão DR
Meus testes abaixo revelam que certamente existem cenários em que você pode querer considerar o uso de um tipo de dados mais fino em vez de ficar com
DATETIME em toda parte. Mas é importante ver onde meus testes para isso apontaram para o outro lado, e também é importante testar esses cenários em seu esquema, em seu ambiente, com hardware e dados o mais fiel possível à produção. Seus resultados podem, e quase certamente irão, variar. As tabelas de destino
Vamos considerar o caso em que a granularidade é importante apenas para o dia (não nos importamos com horas, minutos, segundos). Para isso, podemos escolher
DATETIME (como o usuário proposto) ou SMALLDATETIME , ou DATE no SQL Server 2008+. Há também dois tipos diferentes de dados que eu queria considerar:- Dados que seriam inseridos aproximadamente sequencialmente em tempo real (por exemplo, eventos que estão acontecendo agora);
- Dados que seriam inseridos aleatoriamente (por exemplo, datas de nascimento de novos membros).
Comecei com 2 tabelas como a seguinte, depois criei mais 4 (2 para SMALLDATETIME, 2 para DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Em seguida, repita para DATE e SMALLDATETIME.
E meu objetivo era testar o desempenho da inserção em lote dessas duas maneiras diferentes, bem como o impacto no tamanho e na fragmentação geral do armazenamento e, finalmente, no desempenho das consultas de intervalo.
Dados de amostra
Para gerar alguns dados de amostra, usei uma das minhas técnicas úteis para gerar algo significativo a partir de algo que não é:as visualizações de catálogo. No meu sistema, isso retornou 971 valores de data/hora distintos (1.000.000 linhas no total) em cerca de 12 segundos:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIF(DAY, x, 0), '20120101')) FROM (SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECT DISTINCT d FROM y;
Eu coloquei esses milhões de linhas em uma tabela para que eu pudesse simular inserções sequenciais/aleatórias usando diferentes métodos de acesso para exatamente os mesmos dados de três janelas de sessão diferentes:
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Esse processo demorou um pouco mais para ser concluído (20 segundos). Em seguida, criei uma segunda tabela para armazenar os mesmos dados, mas distribuídos aleatoriamente (para que eu pudesse repetir a mesma distribuição em todas as inserções).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Consultas para preencher as tabelas
Em seguida, escrevi um conjunto de consultas para preencher as outras tabelas com esses dados, usando três janelas de consulta para simular pelo menos um pouco de simultaneidade:
WAITFOR TIME '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- dependendo do método / tipo de dados SELECT source_date FROM dbo.Staging[_Random] -- dependendo do destino WHERE ID % 3 =<0,1,2> -- dependendo da janela de consulta ORDER POR ID; SELECT DATEDIFF(MILISECOND, @d, SYSDATETIME()); Como no meu último post, pré-expandi o banco de dados para evitar que qualquer tipo de evento de crescimento automático de arquivo de dados interfira nos resultados. Eu percebo que não é completamente realista realizar inserções de milhões de linhas em uma passagem, pois não posso impedir que a atividade de log para uma transação tão grande interfira, mas isso deve ser feito de forma consistente em cada método. Dado que o hardware com o qual estou testando é completamente diferente do hardware que você está usando, os resultados absolutos não devem ser uma conclusão importante, apenas a comparação relativa.
(Em um teste futuro, também tentarei isso com lotes reais vindos de arquivos de log com dados relativamente mistos e usando pedaços da tabela de origem em loops - acho que esses seriam experimentos interessantes também. E, claro, adicionando compressão na mistura.)
Os resultados:
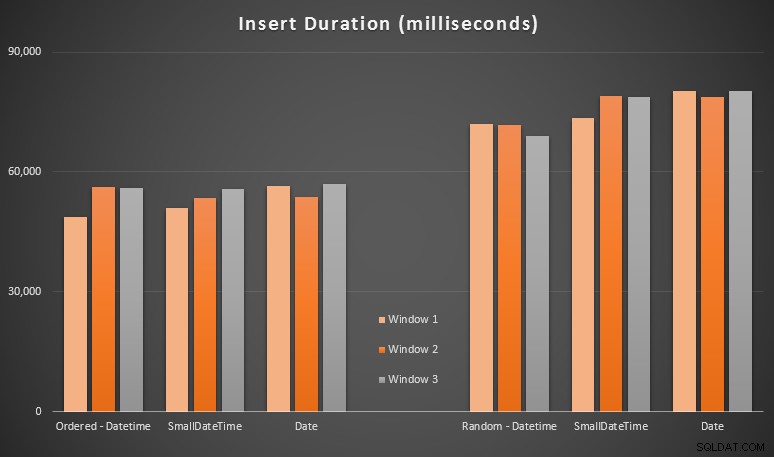
Esses resultados não foram tão surpreendentes para mim – inserir em ordem aleatória levou a tempos de execução mais longos do que inserir sequencialmente, algo que todos podemos levar de volta às nossas raízes de entender como os índices no SQL Server funcionam e como mais divisões de página "ruins" podem acontecer em esse cenário (não monitorei especificamente as divisões de página neste exercício, mas é algo que considerarei em testes futuros).
Percebi que, no lado aleatório, as conversões implícitas nos dados recebidos podem ter um impacto nos tempos, pois pareciam um pouco mais altas que o
DATETIME -> DATETIME nativo inserções. Então decidi construir duas novas tabelas contendo dados de origem:uma usando DATE e um usando SMALLDATETIME . Isso simularia, até certo ponto, converter seu tipo de dados corretamente antes de passá-lo para a instrução insert, de modo que uma conversão implícita não seja necessária durante a inserção. Aqui estão as novas tabelas e como elas foram preenchidas:CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Isso não teve o efeito que eu esperava – os tempos foram semelhantes em todos os casos. Então isso foi uma caça ao ganso selvagem.
Espaço usado e fragmentação
Executei a seguinte consulta para determinar quantas páginas foram reservadas para cada tabela:
SELECT nome ='dbo.' + OBJECT_NAME([object_id]), páginas =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY páginas;
Os resultados:
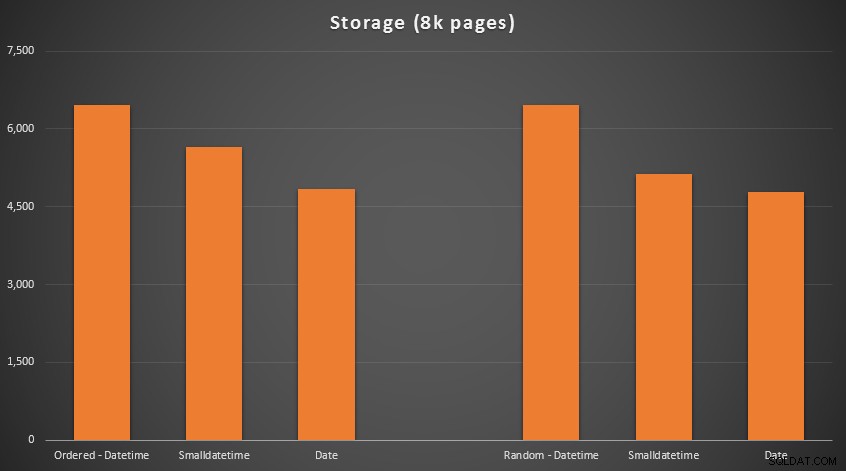
Nenhuma ciência de foguetes aqui; usar um tipo de dados menor, você deve usar menos páginas. Mudando de
DATETIME para DATE gerou consistentemente uma redução de 25% no número de páginas usadas, enquanto SMALLDATETIME reduziu a exigência em 13-20%. Agora, para fragmentação e densidade de página nos índices não clusterizados (havia muito pouca diferença para os índices clusterizados):
SELECT '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED' ) WHERE index_level =0 AND index_id =2;
Resultados:
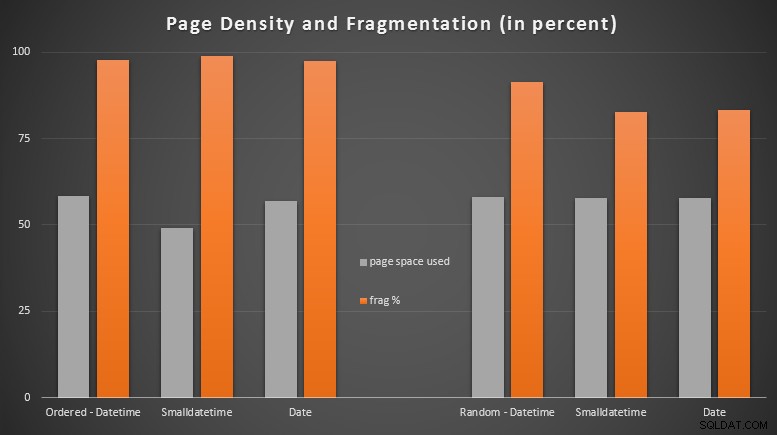
Fiquei bastante surpreso ao ver os dados ordenados se tornarem quase completamente fragmentados, enquanto os dados que foram inseridos aleatoriamente na verdade acabaram com um uso de página um pouco melhor. Fiz uma observação de que isso garante uma investigação mais aprofundada fora do escopo desses testes específicos, mas pode ser algo que você queira verificar se tiver índices não clusterizados que dependem de inserções em grande parte sequenciais.
[Uma reconstrução online dos índices não agrupados em todas as 6 tabelas foi executada em 7 segundos, colocando a densidade da página de volta ao intervalo de 99,5% e reduzindo a fragmentação para menos de 1%. Mas eu não executei isso até realizar os testes de consulta abaixo…]
Teste de consulta de intervalo
Por fim, eu queria ver o impacto nos tempos de execução de consultas simples de intervalo de datas em relação aos diferentes índices, tanto com a fragmentação inerente causada pela atividade de gravação do tipo OLTP, quanto em um índice limpo que é reconstruído. A consulta em si é bem simples:
SELECT TOP (200000) dt FROM dbo.{table_name} WHERE dt>='20110101' ORDER BY dt;
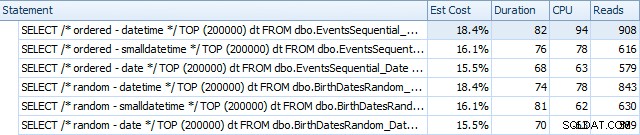
Aqui estão os resultados antes dos índices serem reconstruídos, usando o SQL Sentry Plan Explorer:
E eles diferem um pouco após as reconstruções:
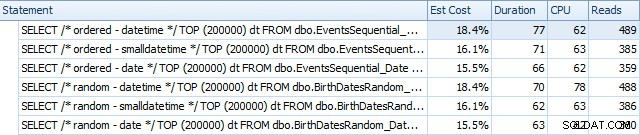
Essencialmente, vemos uma duração e leituras um pouco mais altas para as versões DATETIME, mas muito pouca diferença na CPU. E as diferenças entre SMALLDATETIME e DATE são insignificantes em comparação. Todas as consultas tinham planos de consulta simplistas como este:

(A busca é, obviamente, uma varredura de alcance ordenada.)
Conclusão
Embora esses testes sejam bastante fabricados e possam ter se beneficiado de mais permutações, eles mostram aproximadamente o que eu esperava ver:os maiores impactos nesta escolha específica estão no espaço ocupado pelo índice não clusterizado (onde a escolha de um tipo de dados mais certamente se beneficiarão) e no tempo necessário para realizar inserções em ordem arbitrária, em vez de sequencial (onde DATETIME tem apenas uma aresta marginal).
Eu adoraria ouvir suas ideias sobre como colocar opções de tipo de dados como essas em testes mais completos e punitivos. Pretendo entrar em mais detalhes em posts futuros.