Em 2014, escrevi um artigo chamado Performance Tuning the Whole Query Plan. Ele procurou maneiras de encontrar um número relativamente pequeno de valores distintos de um conjunto de dados moderadamente grande e concluiu que uma solução recursiva poderia ser ótima. Esta postagem de acompanhamento revisita a questão do SQL Server 2019, usando um número maior de linhas.
Ambiente de teste
Usarei o banco de dados Stack Overflow 2013 de 50 GB, mas qualquer tabela grande com um número baixo de valores distintos serviria.
Estarei procurando valores distintos no
BountyAmount coluna do dbo.Votes tabela, apresentada em ordem crescente de quantidade de recompensa. A tabela Votos tem pouco menos de 53 milhões de linhas (52.928.720 para ser exato). Existem apenas 19 quantias de recompensas diferentes, incluindo NULL . O banco de dados Stack Overflow 2013 vem sem índices não clusterizados para minimizar o tempo de download. Há um índice de chave primária clusterizada no
Id coluna do dbo.Votes tabela. Ele vem configurado para compatibilidade com o SQL Server 2008 (nível 100), mas começaremos com uma configuração mais moderna do SQL Server 2017 (nível 140):ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Os testes foram realizados no meu laptop usando o SQL Server 2019 CU 2. Esta máquina possui quatro CPUs i7 (hiperthread para 8) com velocidade base de 2,4 GHz. Possui 32 GB de RAM, com 24 GB disponíveis para a instância do SQL Server 2019. O limite de custo para paralelismo é definido como 50.
Cada resultado de teste representa a melhor de dez execuções, com todos os dados necessários e páginas de índice na memória.
1. Índice agrupado de armazenamento de linhas
Para definir uma linha de base, a primeira execução é uma consulta serial sem nenhuma nova indexação (e lembre-se que isso é com o banco de dados definido para o nível de compatibilidade 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1); Isso verifica o índice clusterizado e usa uma agregação de hash de modo de linha para encontrar os valores distintos de
BountyAmount :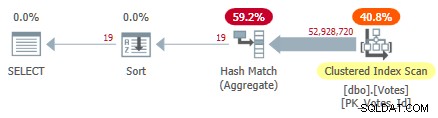 Plano de índice serial clusterizado
Plano de índice serial clusterizado Isso leva 10.500 ms para concluir, usando a mesma quantidade de tempo de CPU. Lembre-se que este é o melhor tempo em dez execuções com todos os dados na memória. Estatísticas de amostra criadas automaticamente no
BountyAmount coluna foram criadas na primeira execução. Cerca de metade do tempo decorrido é gasto no Clustered Index Scan e cerca de metade no Hash Match Aggregate. O Sort tem apenas 19 linhas para processar, portanto, consome apenas 1 ms ou mais. Todos os operadores neste plano usam a execução no modo de linha.
Removendo o
MAXDOP 1 dica dá um plano paralelo: Plano de índice clusterizado paralelo
Plano de índice clusterizado paralelo Este é o plano que o otimizador escolhe sem nenhuma dica na minha configuração. Ele retorna resultados em 4.200 ms usando um total de 32.800ms de CPU (no DOP 8).
2. Índice não clusterizado
Varrendo toda a tabela para encontrar apenas o
BountyAmount parece ineficiente, então é natural tentar adicionar um índice não clusterizado em apenas uma coluna que esta consulta precisa:CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Este índice demora um pouco para ser criado (1m 40s). O
MAXDOP 1 consulta agora usa um Stream Aggregate porque o otimizador pode usar o índice não clusterizado para apresentar linhas em BountyAmount pedido: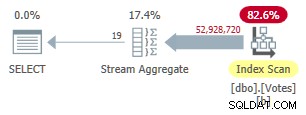 Plano de modo de linha serial não clusterizado
Plano de modo de linha serial não clusterizado Isso é executado por 9.300 ms (consumindo a mesma quantidade de tempo de CPU). Uma melhoria útil nos 10.500ms originais, mas dificilmente impressionante.
Removendo o
MAXDOP 1 dica fornece um plano paralelo com agregação local (por thread): Plano de modo de linha paralela não clusterizada
Plano de modo de linha paralela não clusterizada Isso é executado em 3.400 ms usando 25.800ms de tempo de CPU. Podemos melhorar com a compactação de linha ou página no novo índice, mas quero passar para opções mais interessantes.
3. Modo de lote na loja de linha (BMOR)
Agora defina o banco de dados para o modo de compatibilidade do SQL Server 2019 usando:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Isso dá ao otimizador liberdade para escolher o modo de lote no armazenamento de linha, se achar que vale a pena. Isso pode fornecer alguns dos benefícios da execução no modo de lote sem exigir um índice de armazenamento de colunas. Para detalhes técnicos profundos e opções não documentadas, veja o excelente artigo de Dmitry Pilugin sobre o assunto.
Infelizmente, o otimizador ainda escolhe a execução no modo de linha completo usando agregados de fluxo para as consultas de teste serial e paralela. Para obter um modo de lote no plano de execução do armazenamento de linhas, podemos adicionar uma dica para incentivar a agregação usando a correspondência de hash (que pode ser executada no modo de lote):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Isso nos dá um plano com todos os operadores rodando em modo batch:
 Modo de lote serial no plano de armazenamento de linha
Modo de lote serial no plano de armazenamento de linha Os resultados são retornados em 2.600 ms (toda a CPU como de costume). Isso já é mais rápido que o paralelo plano de modo de linha (3.400ms decorridos) usando muito menos CPU (2.600ms versus 25.800ms).
Removendo o
MAXDOP 1 dica (mas mantendo HASH GROUP ) fornece um modo de lote paralelo no plano de armazenamento de linha: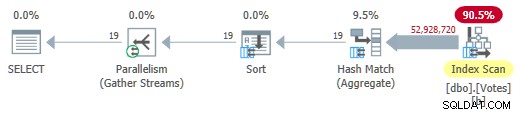 Modo de lote paralelo no plano de armazenamento de linha
Modo de lote paralelo no plano de armazenamento de linha Isso é executado em apenas 725 ms usando 5.700ms de CPU.
4. Modo Lote no Armazenamento de Coluna
O modo de lote paralelo no resultado do armazenamento de linha é uma melhoria impressionante. Podemos fazer ainda melhor fornecendo uma representação de armazenamento de colunas dos dados. Para manter tudo igual, adicionarei um não clusterizado índice de armazenamento de colunas apenas na coluna que precisamos:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Isso é preenchido a partir do índice não clusterizado de árvore b existente e leva apenas 15s para ser criado.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); O otimizador escolhe um plano de modo totalmente em lote, incluindo uma verificação de índice de armazenamento de colunas:
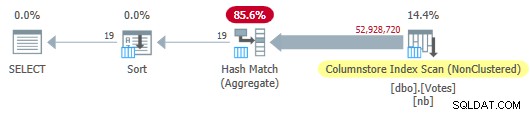 Plano de armazenamento de coluna serial
Plano de armazenamento de coluna serial Isso é executado em 115 ms usando a mesma quantidade de tempo de CPU. O otimizador escolhe este plano sem nenhuma dica sobre a configuração do meu sistema porque o custo estimado do plano está abaixo do limite de custo para paralelismo .
Para obter um plano paralelo, podemos reduzir o limite de custo ou usar uma dica não documentada:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Em qualquer caso, o plano paralelo é:
 Plano de armazenamento de colunas paralelas
Plano de armazenamento de colunas paralelas O tempo decorrido da consulta agora foi reduzido para 30 ms , enquanto consome 210ms de CPU.
5. Modo Lote no Armazenamento de Colunas com Push Down
O melhor tempo de execução atual de 30ms é impressionante, especialmente quando comparado aos 10.500ms originais. No entanto, é uma pena que tenhamos que passar quase 53 milhões de linhas (em 58.868 lotes) do Scan para o Hash Match Aggregate.
Seria bom se o SQL Server pudesse empurrar a agregação para baixo na varredura e apenas retornar valores distintos diretamente do armazenamento de colunas. Você pode pensar que precisamos expressar o
DISTINCT como um GROUP BY para obter o Empilhamento Agregado Agrupado, mas isso é logicamente redundante e não toda a história em qualquer caso. Com a implementação atual do SQL Server, precisamos calcular um agregado para ativar o pushdown agregado. Mais do que isso, precisamos usar o resultado agregado de alguma forma, ou o otimizador apenas o removerá como desnecessário.
Uma maneira de escrever a consulta para obter empilhamento agregado é adicionar um requisito de pedido secundário logicamente redundante:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); O plano serial agora é:
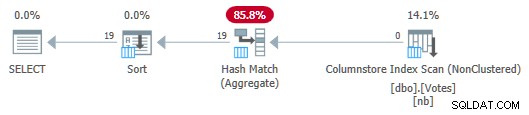 Plano de armazenamento de coluna serial com push down agregado
Plano de armazenamento de coluna serial com push down agregado Observe que nenhuma linha é passada do Scan para o Aggregate! Nos bastidores, agregados parciais do
BountyAmount os valores e suas contagens de linhas associadas são passados para o Hash Match Aggregate, que soma as agregações parciais para formar a agregação final (global) necessária. Isso é muito eficiente, conforme confirmado pelo tempo decorrido de 13ms (tudo isso é tempo de CPU). Como lembrete, o plano serial anterior levava 115ms. Para completar o conjunto, podemos obter uma versão paralela da mesma forma que antes:
 Plano de armazenamento de colunas paralelas com push down agregado
Plano de armazenamento de colunas paralelas com push down agregado Isso é executado por 7ms usando 40ms de CPU no total.
É uma pena que precisemos calcular e usar um agregado que não precisamos apenas para ser empurrado para baixo. Talvez isso seja melhorado no futuro para que
DISTINCT e GROUP BY sem agregados podem ser enviados para a varredura. 6. Expressão de tabela comum recursiva de modo de linha
No início, prometi revisitar a solução CTE recursiva usada para encontrar um pequeno número de duplicatas em um grande conjunto de dados. Implementar o requisito atual usando essa técnica é bastante simples, embora o código seja necessariamente mais longo do que qualquer coisa que vimos até agora:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); A ideia tem suas raízes em uma chamada varredura de salto de índice:encontramos o menor valor de interesse no início do índice de b-tree de ordem crescente, depois procuramos encontrar o próximo valor na ordem do índice e assim por diante. A estrutura de um índice b-tree torna a localização do próximo valor mais alto muito eficiente — não há necessidade de varrer as duplicatas.
O único truque real aqui é convencer o otimizador a nos permitir usar
TOP na parte 'recursiva' do CTE para retornar uma cópia de cada valor distinto. Por favor, veja meu artigo anterior se você precisar de uma atualização sobre os detalhes. O plano de execução (explicado em geral por Craig Freedman aqui) é:
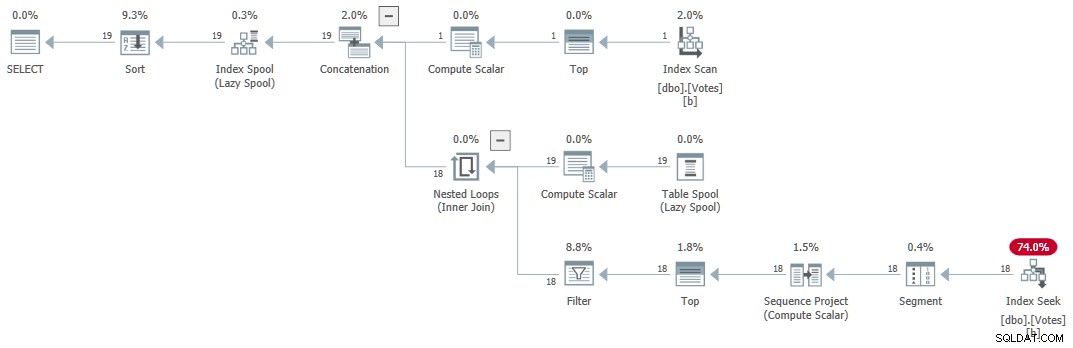 Serial Recursive CTE
Serial Recursive CTE A consulta retorna resultados corretos em 1 ms usando 1ms de CPU, de acordo com o Sentry One Plan Explorer.
7. T-SQL iterativo
Lógica semelhante pode ser expressa usando um
WHILE ciclo. O código pode ser mais fácil de ler e entender do que o CTE recursivo. Também evita ter que usar truques para contornar as muitas restrições na parte recursiva de um CTE. O desempenho é competitivo em cerca de 15ms. Este código é fornecido para juros e não está incluído na tabela de resumo de desempenho. SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabela de resumo de desempenho
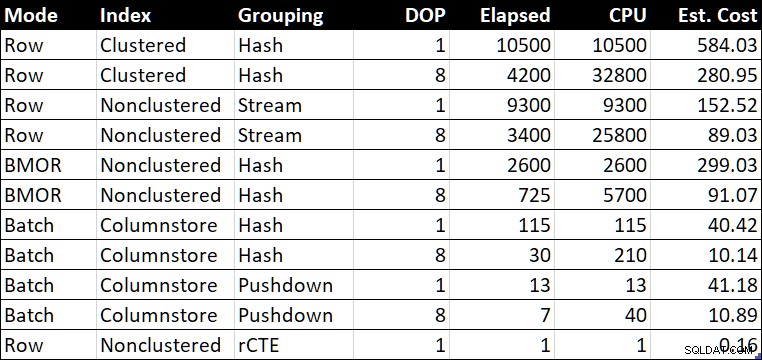 Tabela de resumo de desempenho (duração / CPU em milissegundos)
Tabela de resumo de desempenho (duração / CPU em milissegundos) O “Est. Cost” mostra a estimativa de custo do otimizador para cada consulta conforme relatado no sistema de teste.
Considerações finais
Encontrar um pequeno número de valores distintos pode parecer um requisito bastante específico, mas eu o encontrei com bastante frequência ao longo dos anos, geralmente como parte do ajuste de uma consulta maior.
Os últimos vários exemplos foram bastante próximos em desempenho. Muitas pessoas ficariam felizes com qualquer um dos resultados em menos de um segundo, dependendo das prioridades. Mesmo o modo de lote serial no resultado de armazenamento de linha de 2.600 ms se compara bem com o melhor paralelo planos de modo de linha, o que é um bom presságio para acelerações significativas apenas atualizando para o SQL Server 2019 e habilitando o nível de compatibilidade de banco de dados 150. Nem todos poderão migrar para o armazenamento de armazenamento de coluna rapidamente e nem sempre será a solução certa de qualquer maneira . O modo de lote no armazenamento de linha fornece uma maneira elegante de obter alguns dos ganhos possíveis com armazenamentos de coluna, supondo que você possa convencer o otimizador a optar por usá-lo.
O resultado de push down agregado do armazenamento de colunas paralelas de 57 milhões de linhas processado em 7ms (usando 40ms de CPU) é notável, especialmente considerando o hardware. O resultado de push down agregado em série de 13 ms é igualmente impressionante. Seria ótimo se eu não tivesse que adicionar um resultado agregado sem sentido para obter esses planos.
Para aqueles que ainda não podem migrar para o SQL Server 2019 ou armazenamento de armazenamento de colunas, o CTE recursivo ainda é uma solução viável e eficiente quando existe um índice de árvore b adequado e o número de valores distintos necessários é garantido como bastante pequeno. Seria legal se o SQL Server pudesse acessar uma b-tree como esta sem precisar escrever um CTE recursivo (ou código T-SQL de loop iterativo equivalente usando
WHILE ). Outra possível solução para o problema é criar uma visualização indexada. Isso fornecerá valores distintos com grande eficiência. A desvantagem, como de costume, é que cada alteração na tabela subjacente precisará atualizar a contagem de linhas armazenada na visualização materializada.
Cada uma das soluções apresentadas aqui tem seu lugar, dependendo dos requisitos. Ter uma ampla gama de ferramentas disponíveis geralmente é uma coisa boa ao ajustar as consultas. Na maioria das vezes, eu escolheria uma das soluções de modo de lote porque seu desempenho será bastante previsível, não importa quantas duplicatas estejam presentes.