[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Muito tem sido escrito ao longo dos anos sobre como entender e otimizar
SELECT consultas, mas menos sobre modificação de dados. Esta série de postagens aborda um problema específico de INSERT , UPDATE , DELETE e MERGE perguntas – o problema do Halloween. A frase “Halloween Problem” foi originalmente cunhada com referência a um SQL
UPDATE consulta que deveria dar um aumento de 10% a cada funcionário que ganhasse menos de US$ 25.000. O problema era que a consulta continuava dando 10% de aumento até que todos ganhou pelo menos US $ 25.000. Veremos mais adiante nesta série que o problema subjacente também se aplica a INSERT , DELETE e MERGE consultas, mas para esta primeira entrada, será útil examinar o UPDATE problema com um pouco de detalhe. Plano de fundo
A linguagem SQL fornece uma maneira para os usuários especificarem alterações no banco de dados usando um
UPDATE instrução, mas a sintaxe não diz nada sobre como o mecanismo de banco de dados deve executar as alterações. Por outro lado, o padrão SQL especifica que o resultado de um UPDATE deve ser o mesmo como se tivesse sido executado em três fases distintas e não sobrepostas:- Uma pesquisa somente leitura determina os registros a serem alterados e os novos valores de coluna
- As alterações são aplicadas aos registros afetados
- As restrições de consistência do banco de dados são verificadas
A implementação dessas três fases literalmente em um mecanismo de banco de dados produziria resultados corretos, mas o desempenho pode não ser muito bom. Os resultados intermediários em cada estágio exigirão memória do sistema, reduzindo o número de consultas que o sistema pode executar simultaneamente. A memória necessária também pode exceder a que está disponível, exigindo que pelo menos parte do conjunto de atualizações seja gravado no armazenamento em disco e lido novamente mais tarde. Por último, mas não menos importante, cada linha da tabela precisa ser tocada várias vezes nesse modelo de execução.
Uma estratégia alternativa é processar o
UPDATE uma linha de cada vez. Isso tem a vantagem de tocar em cada linha apenas uma vez e geralmente não requer memória para armazenamento (embora algumas operações, como uma classificação completa, devam processar o conjunto de entrada completo antes de produzir a primeira linha de saída). Esse modelo iterativo é aquele usado pelo mecanismo de execução de consulta do SQL Server. O desafio para o otimizador de consulta é encontrar um plano de execução iterativo (linha por linha) que satisfaça o
UPDATE semântica exigida pelo padrão SQL, mantendo os benefícios de desempenho e simultaneidade da execução em pipeline. Atualizar processamento
Para ilustrar o problema original, aplicaremos um aumento de 10% a cada funcionário que ganhe menos de US$ 25.000 usando o campo
Employees tabela abaixo:
CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Estratégia de atualização em três fases
A primeira fase somente leitura encontra todos os registros que atendem ao
WHERE predicado da cláusula e salva informações suficientes para que a segunda fase faça seu trabalho. Na prática, isso significa registrar um identificador exclusivo para cada linha qualificada (as chaves de índice clusterizadas ou o identificador de linha de heap) e o novo valor do salário. Concluída a fase um, todo o conjunto de informações de atualização é passado para a segunda fase, que localiza cada registro a ser atualizado usando o identificador exclusivo e altera o salário para o novo valor. A terceira fase verifica se nenhuma restrição de integridade do banco de dados foi violada pelo estado final da tabela. Estratégia iterativa
Essa abordagem lê uma linha por vez da tabela de origem. Se a linha satisfizer o
WHERE predicado da cláusula, aplica-se o aumento salarial. Esse processo se repete até que todas as linhas tenham sido processadas da origem. Um exemplo de plano de execução usando este modelo é mostrado abaixo:
Como é usual para o pipeline controlado por demanda do SQL Server, a execução começa no operador mais à esquerda – o
UPDATE nesse caso. Ele solicita uma linha do Table Update, que solicita uma linha do Compute Scalar e desce a cadeia para o Table Scan: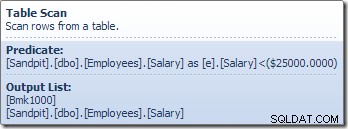
O operador Table Scan lê uma linha de cada vez do mecanismo de armazenamento, até encontrar uma que satisfaça o predicado Salary. A lista de saída no gráfico acima mostra o operador Table Scan retornando um identificador de linha e o valor atual da coluna Salário para esta linha. Uma única linha contendo referências a essas duas informações é passada para o Compute Scalar:
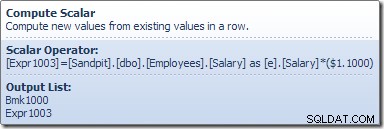
O Compute Scalar define uma expressão que aplica o aumento de salário à linha atual. Ele retorna uma linha contendo referências ao identificador de linha e o salário modificado para a Atualização da Tabela, que chama o mecanismo de armazenamento para realizar a modificação dos dados. Esse processo iterativo continua até que a Verificação de Tabela fique sem linhas. O mesmo processo básico é seguido se a tabela tiver um índice clusterizado:
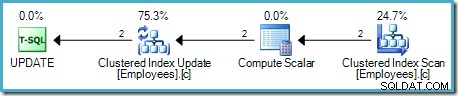
A principal diferença é que a(s) chave(s) de índice clusterizado e o unificador (se houver) são usados como o identificador de linha em vez de um RID de heap.
O problema
A mudança da operação lógica trifásica definida no padrão SQL para o modelo físico de execução iterativa introduziu uma série de mudanças sutis, apenas uma das quais examinaremos hoje. Um problema pode ocorrer em nosso exemplo em execução se houver um índice não clusterizado na coluna Salary, que o otimizador de consulta decide usar para encontrar linhas qualificadas (Salary <$ 25.000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
O modelo de execução linha por linha agora pode produzir resultados incorretos ou até mesmo entrar em um loop infinito. Considere um plano de execução iterativo (imaginário) que busca o índice Salary, retornando uma linha por vez para o Compute Scalar e, finalmente, para o operador Update:

Há alguns Compute Scalars extras neste plano devido a uma otimização que ignora a manutenção do índice não clusterizado se o valor do Salário não for alterado (possível apenas para um salário zero neste caso).
Ignorando isso, o recurso importante deste plano é que agora temos uma varredura de índice parcial ordenada passando uma linha de cada vez para um operador que modifica o mesmo índice (o destaque em verde no gráfico SQL Sentry Plan Explorer acima deixa claro o Clustered O operador Index Update mantém a tabela base e o índice não clusterizado).
De qualquer forma, o problema é que, processando uma linha por vez, o Update pode mover a linha atual à frente da posição de varredura usada pelo Index Seek para localizar as linhas a serem alteradas. Trabalhar com o exemplo deve tornar essa declaração um pouco mais clara:
O índice não clusterizado é codificado e classificado em ordem crescente no valor do salário. O índice também contém um ponteiro para a linha pai na tabela base (um RID de heap ou as chaves de índice clusterizado mais o unificador, se necessário). Para tornar o exemplo mais fácil de seguir, suponha que a tabela base agora tenha um índice clusterizado exclusivo na coluna Nome, de modo que o conteúdo do índice não clusterizado no início do processamento de atualização seja:
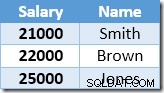
A primeira linha retornada pelo Index Seek é o salário de US$ 21.000 de Smith. Esse valor é atualizado para $ 23.100 na tabela base e no índice não clusterizado pelo operador Clustered Index. O índice não clusterizado agora contém:
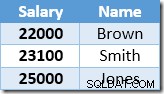
A próxima linha retornada pelo Index Seek será a entrada de US$ 22.000 para Brown, que é atualizada para US$ 24.200:
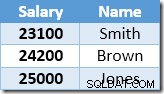
Agora, o Index Seek encontra o valor de US$ 23.100 para Smith, que é atualizado novamente , para US$ 25.410. Esse processo continua até que todos os funcionários tenham um salário de pelo menos US$ 25.000 – o que não é um resultado correto para o
UPDATE fornecido inquerir. O mesmo efeito em outras circunstâncias pode levar a uma atualização descontrolada que só termina quando o servidor fica sem espaço de log ou ocorre um erro de estouro (pode ocorrer neste caso se alguém tivesse um salário zero). Este é o problema do Dia das Bruxas, pois se aplica a atualizações. Evitando o problema do Halloween para atualizações
Leitores atentos devem ter notado que as porcentagens de custo estimadas no plano imaginário Index Seek não somavam 100%. Isso não é um problema com o Plan Explorer – eu removi deliberadamente um operador-chave do plano:

O otimizador de consulta reconhece que esse plano de atualização em pipeline é vulnerável ao problema de Halloween e introduz um Eager Table Spool para evitar que isso ocorra. Não há dica ou sinalizador de rastreamento para impedir a inclusão do spool neste plano de execução porque é necessário para correção.
Como o próprio nome sugere, o spool consome avidamente todas as linhas de seu operador filho (o Index Seek) antes de retornar uma linha para seu pai Compute Scalar. O efeito disso é introduzir uma separação de fases completa – todas as linhas qualificadas são lidas e salvas no armazenamento temporário antes que qualquer atualização seja executada.
Isso nos aproxima da semântica lógica trifásica do padrão SQL, embora observe que a execução do plano ainda é fundamentalmente iterativa, com operadores à direita do spool formando o cursor de leitura , e operadores à esquerda formando o cursor de escrita . O conteúdo do carretel ainda é lido e processado linha por linha (não é passado em massa como a comparação com o padrão SQL pode levar você a acreditar).
As desvantagens da separação de fases são as mesmas mencionadas anteriormente. O Spool de Tabela consome tempdb espaço (páginas no conjunto de buffers) e pode exigir leituras e gravações físicas no disco sob pressão de memória. O otimizador de consulta atribui um custo estimado ao spool (sujeito a todas as ressalvas usuais sobre estimativas) e escolherá entre os planos que exigem proteção contra o problema do Halloween versus aqueles que não exigem com base no custo estimado normalmente. Naturalmente, o otimizador pode escolher incorretamente entre as opções por qualquer um dos motivos normais.
Nesse caso, o trade-off é entre o aumento de eficiência buscando diretamente os registros de qualificação (aqueles com salário <$ 25.000) versus o custo estimado do carretel necessário para evitar o problema do Halloween. Um plano alternativo (neste caso específico) é uma varredura completa do índice clusterizado (ou heap). Esta estratégia não requer a mesma proteção de Halloween porque as chaves do índice clusterizado não são modificados:

Como as chaves de índice são estáveis, as linhas não podem mover a posição no índice entre as iterações, evitando o problema de Halloween no presente caso. Dependendo do custo de tempo de execução do Clustered Index Scan comparado com a combinação Index Seek mais Eager Table Spool vista anteriormente, um plano pode ser executado mais rapidamente que o outro. Outra consideração é que o plano com Proteção de Halloween adquirirá mais bloqueios do que o plano totalmente em pipeline, e os bloqueios serão mantidos por mais tempo.
Considerações finais
Compreender o problema do Halloween e os efeitos que ele pode ter nos planos de consulta de modificação de dados ajudará você a analisar os planos de execução de alteração de dados e pode oferecer oportunidades para evitar os custos e os efeitos colaterais da proteção desnecessária onde uma alternativa estiver disponível.
Existem várias formas do Problema de Halloween, nem todas causadas pela leitura e escrita nas chaves de um índice comum. O problema do Halloween também não se limita a
UPDATE consultas. O otimizador de consulta tem mais truques na manga para evitar o problema do Halloween, além da separação de fase de força bruta usando um Eager Table Spool. Esses pontos (e mais) serão explorados nas próximas partes desta série. [ Parte 1 | Parte 2 | Parte 3 | Parte 4]