No início desta semana, postei uma continuação da minha postagem recente sobre
STRING_SPLIT() no SQL Server 2016, abordando vários comentários deixados no post e/ou enviados diretamente para mim:STRING_SPLIT()no SQL Server 2016:Acompanhamento nº 1
Depois que esse post foi escrito principalmente, houve uma pergunta de última hora de Doug Ellner:
Como essas funções se comparam com os parâmetros com valor de tabela?
Agora, testar TVPs já estava na minha lista de projetos futuros, após uma recente troca de twitter com @Nick_Craver no Stack Overflow. Ele disse que estava empolgado com o fato de
STRING_SPLIT() tiveram um bom desempenho, porque estavam insatisfeitos com o desempenho de enviar ~ 7.000 valores por meio de um parâmetro com valor de tabela. Meus testes
Para esses testes, usei o SQL Server 2016 RC3 (13.0.1400.361) em uma VM Windows 10 de 8 núcleos, com armazenamento PCIe e 32 GB de RAM.
Eu criei uma tabela simples que imitava o que eles estavam fazendo (selecionando cerca de 10.000 valores de uma tabela de mais de 3 milhões de postagens de linha), mas para meus testes, ela tem muito menos colunas e menos índices:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Também criei uma versão In-Memory, porque estava curioso para saber se alguma abordagem funcionaria de maneira diferente lá:
CREATE TABLE dbo.Posts_InMemory( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) WITH (MEMORY_OPTIMIZED =ON);
Agora, eu queria criar um aplicativo C# que passasse 10.000 valores exclusivos, seja como uma string separada por vírgulas (criada usando um StringBuilder) ou como um TVP (passado de um DataTable). O objetivo seria recuperar ou atualizar uma seleção de linhas com base em uma correspondência, seja para um elemento produzido pela divisão da lista ou um valor explícito em um TVP. Portanto, o código foi escrito para anexar cada 300º valor à string ou DataTable (o código C# está em um apêndice abaixo). Peguei as funções que criei no post original, alterei-as para lidar com
varchar(max) , e adicionou duas funções que aceitavam um TVP – uma delas otimizada para memória. Aqui estão os tipos de tabela (as funções estão no apêndice abaixo):CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =1000000)) WITH (MEMORY_OPTIMIZED =ON); GO
Eu também tive que aumentar a tabela Numbers para lidar com strings> 8K e com> 8K elementos (fiz 1MM de linhas). Então eu criei sete procedimentos armazenados:cinco deles pegando umvarchar(max)e juntando-se com a saída da função para atualizar a tabela base, e depois dois para aceitar o TVP e juntar-se diretamente a isso. O código C# chama cada um desses sete procedimentos, com a lista de 10.000 postagens para selecionar ou atualizar, 1.000 vezes. Esses procedimentos também estão no apêndice abaixo. Então, apenas para resumir, os métodos que estão sendo testados são:
- Nativo (
STRING_SPLIT()) - XML
- CLR
- Tabela de números
- JSON (com
intexplícito saída) - Parâmetro com valor de tabela
- Parâmetro com valor de tabela otimizado para memória
Testaremos a recuperação de 10.000 valores, 1.000 vezes, usando um DataReader – mas não iterando sobre o DataReader, pois isso apenas tornaria o teste mais demorado e seria a mesma quantidade de trabalho para o aplicativo C#, independentemente de como o banco de dados produziu o conjunto. Também testaremos a atualização das 10.000 linhas, 1.000 vezes cada, usando
ExecuteNonQuery() . E testaremos as versões regular e otimizada para memória da tabela Posts, que podemos alternar com muita facilidade sem precisar alterar nenhuma das funções ou procedimentos, usando um sinônimo:CRIAR SINÔNIMO dbo.Posts PARA dbo.Posts_Regular; -- para testar a versão com otimização de memória:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- para testar a versão baseada em disco novamente:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Iniciei o aplicativo, executei-o várias vezes para cada combinação para garantir que a compilação, o armazenamento em cache e outros fatores não fossem injustos com o lote executado primeiro e, em seguida, analisei os resultados da tabela de log (também verifiquei sys. dm_exec_procedure_stats para garantir que nenhuma das abordagens tenha uma sobrecarga significativa baseada em aplicativo, e eles não tiveram).
Resultados – Tabelas baseadas em disco
Às vezes, tenho dificuldades com a visualização de dados – tentei realmente encontrar uma maneira de representar essas métricas em um único gráfico, mas acho que havia muitos pontos de dados para destacar os mais importantes.
Você pode clicar para ampliar qualquer um deles em uma nova guia/janela, mas mesmo se você tiver uma janela pequena, tentei deixar claro o vencedor através do uso de cores (e o vencedor foi o mesmo em todos os casos). Para ser claro, por "Duração média" quero dizer o tempo médio que o aplicativo levou para concluir um loop de 1.000 operações.
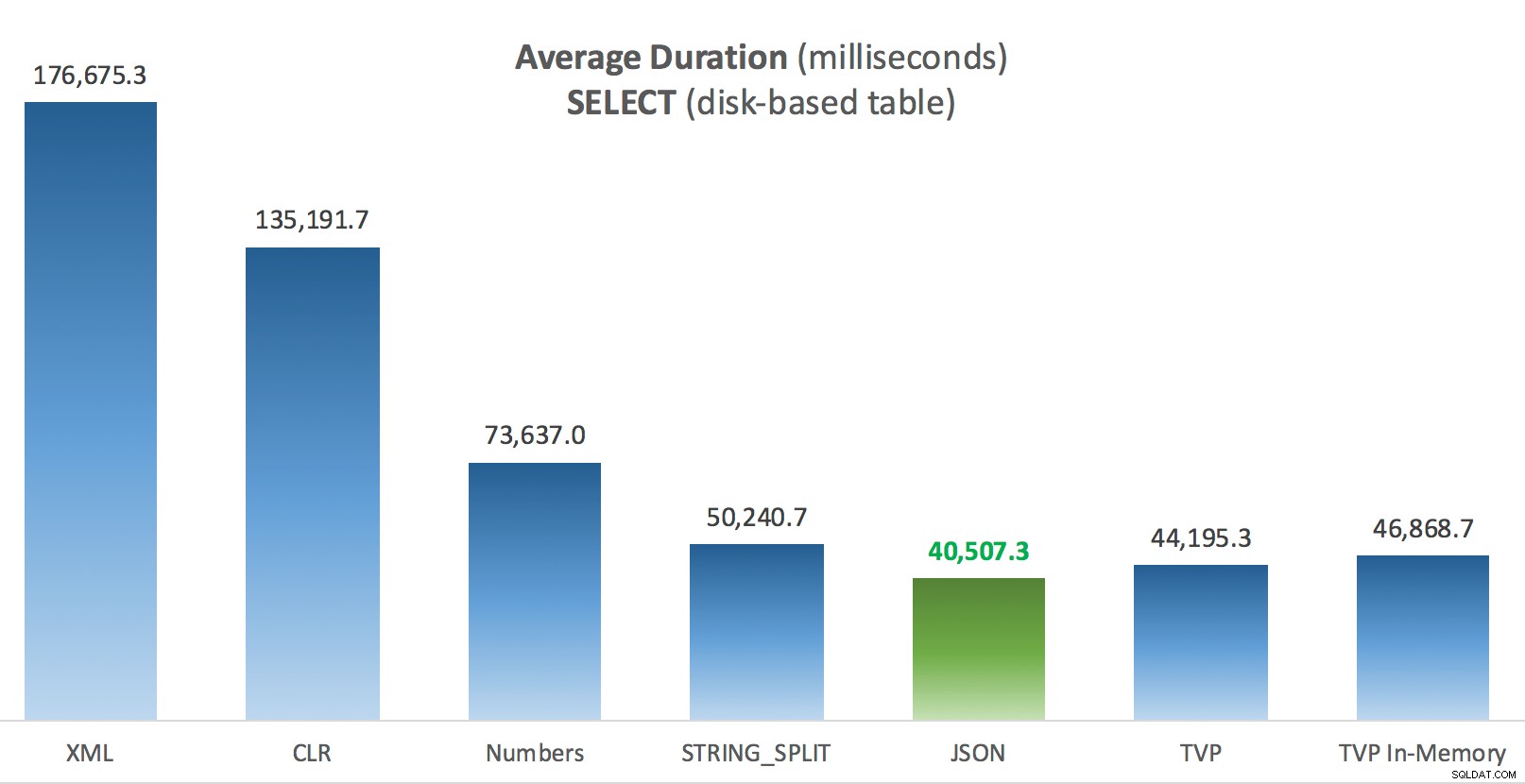 Duração média (milissegundos) para SELECTs em relação à tabela Posts baseada em disco
Duração média (milissegundos) para SELECTs em relação à tabela Posts baseada em disco 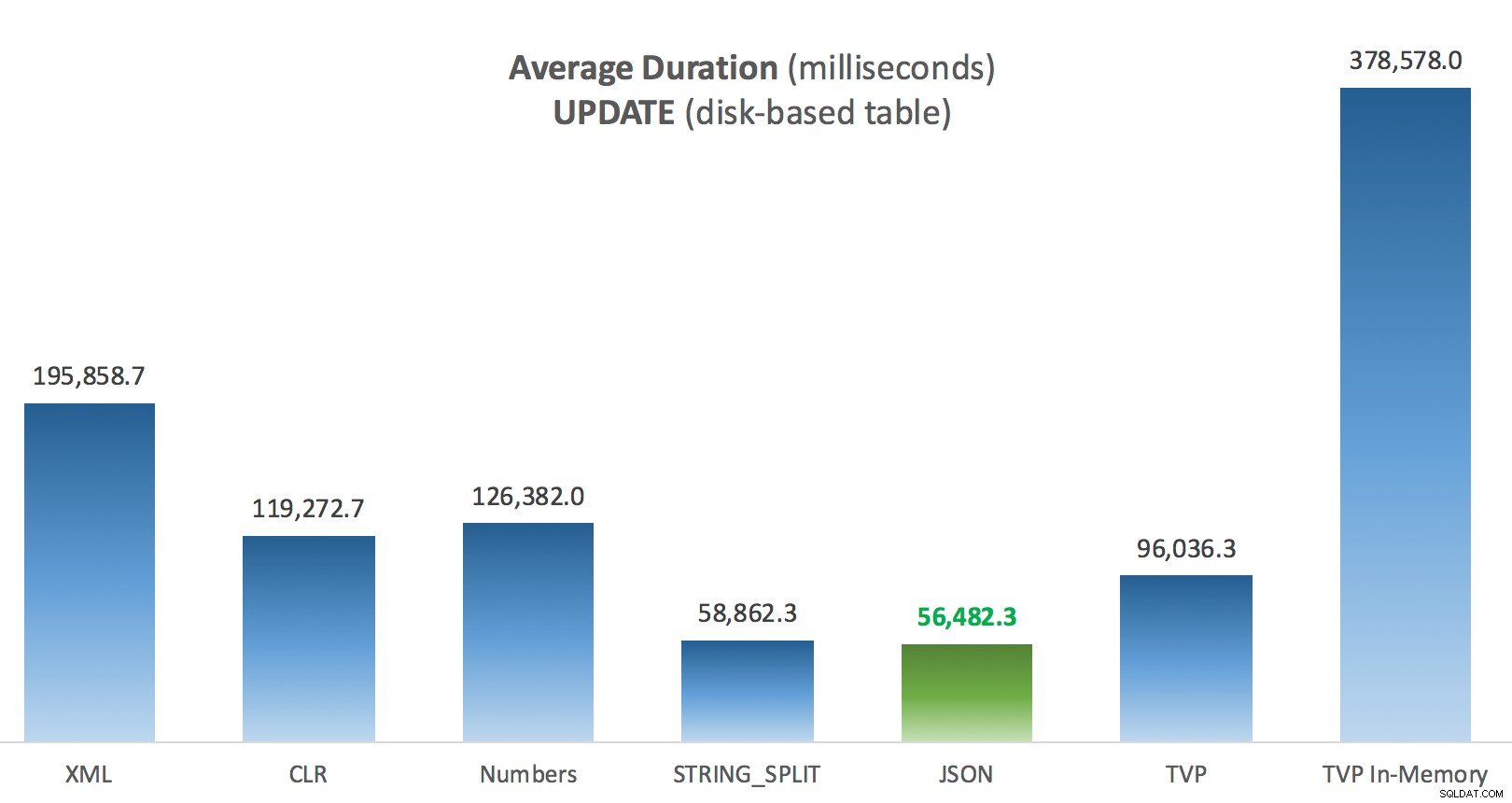 Duração média (milissegundos) para UPDATEs em relação à tabela Posts baseada em disco
Duração média (milissegundos) para UPDATEs em relação à tabela Posts baseada em disco A coisa mais interessante aqui, para mim, é como o TVP com otimização de memória se saiu mal ao ajudar com um
UPDATE . Acontece que as varreduras paralelas são atualmente bloqueadas de forma muito agressiva quando DML está envolvido; A Microsoft reconheceu isso como uma lacuna de recursos e espera resolver isso em breve. Observe que a varredura paralela é atualmente possível com SELECT mas está bloqueado para DML agora. (Isso não será resolvido no SQL Server 2014, pois essas operações de verificação paralela específicas não estão disponíveis para nenhuma operação.) Quando isso for corrigido, ou quando seus TVPs forem menores e/ou o paralelismo não for benéfico, você deverá ver que os TVPs com otimização de memória terão um desempenho melhor (o padrão simplesmente não funciona bem para esse caso de uso específico de TVPs relativamente grandes). Para este caso específico, aqui estão os planos para o
SELECT (que eu poderia forçar a ficar paralelo) e o UPDATE (o que não consegui):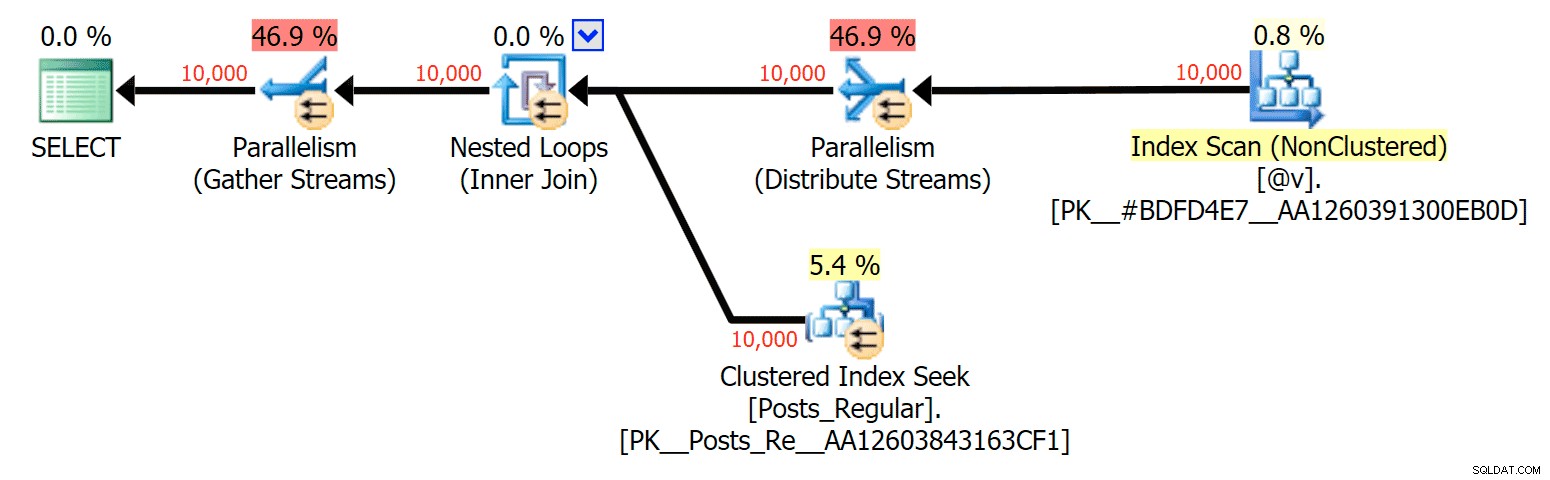 Paralelismo em um plano SELECT unindo uma tabela baseada em disco a um TVP na memória
Paralelismo em um plano SELECT unindo uma tabela baseada em disco a um TVP na memória 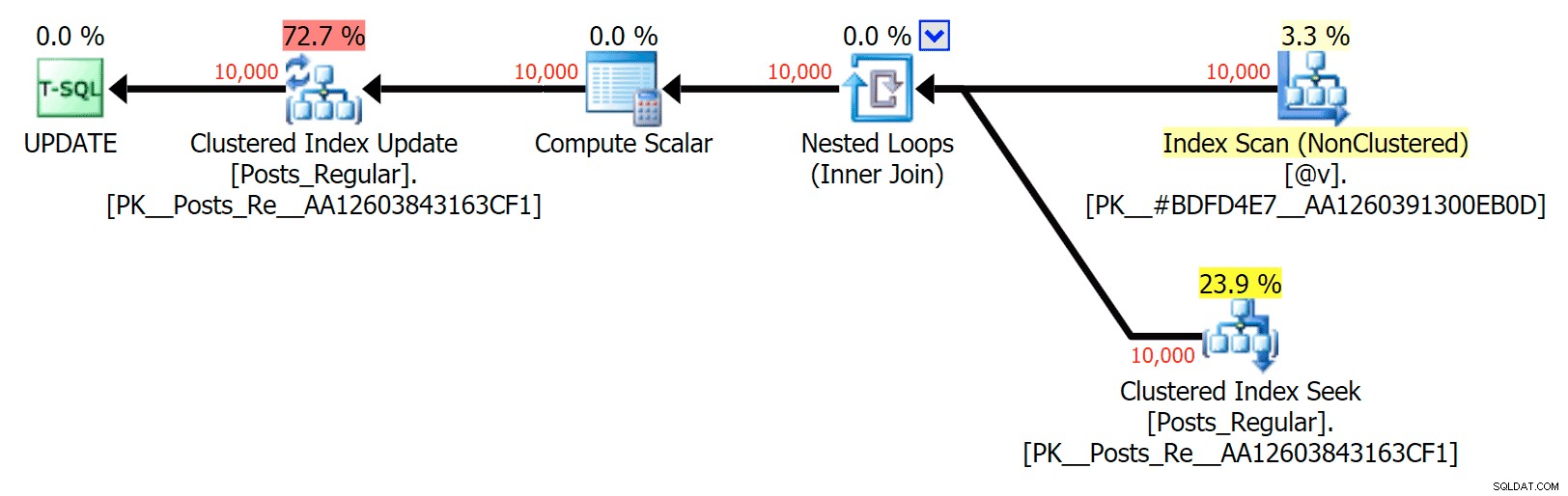 Sem paralelismo em um plano UPDATE unindo uma tabela baseada em disco a uma in-memory TVP
Sem paralelismo em um plano UPDATE unindo uma tabela baseada em disco a uma in-memory TVP Resultados – Tabelas com otimização de memória
Um pouco mais de consistência aqui – os quatro métodos à direita são relativamente uniformes, enquanto os três à esquerda parecem muito indesejáveis em contraste. Preste também atenção especial à escala absoluta em comparação com as tabelas baseadas em disco – na maioria das vezes, usando os mesmos métodos, e mesmo sem paralelismo, você acaba com operações muito mais rápidas em relação às tabelas com otimização de memória, levando a um menor uso geral da CPU.
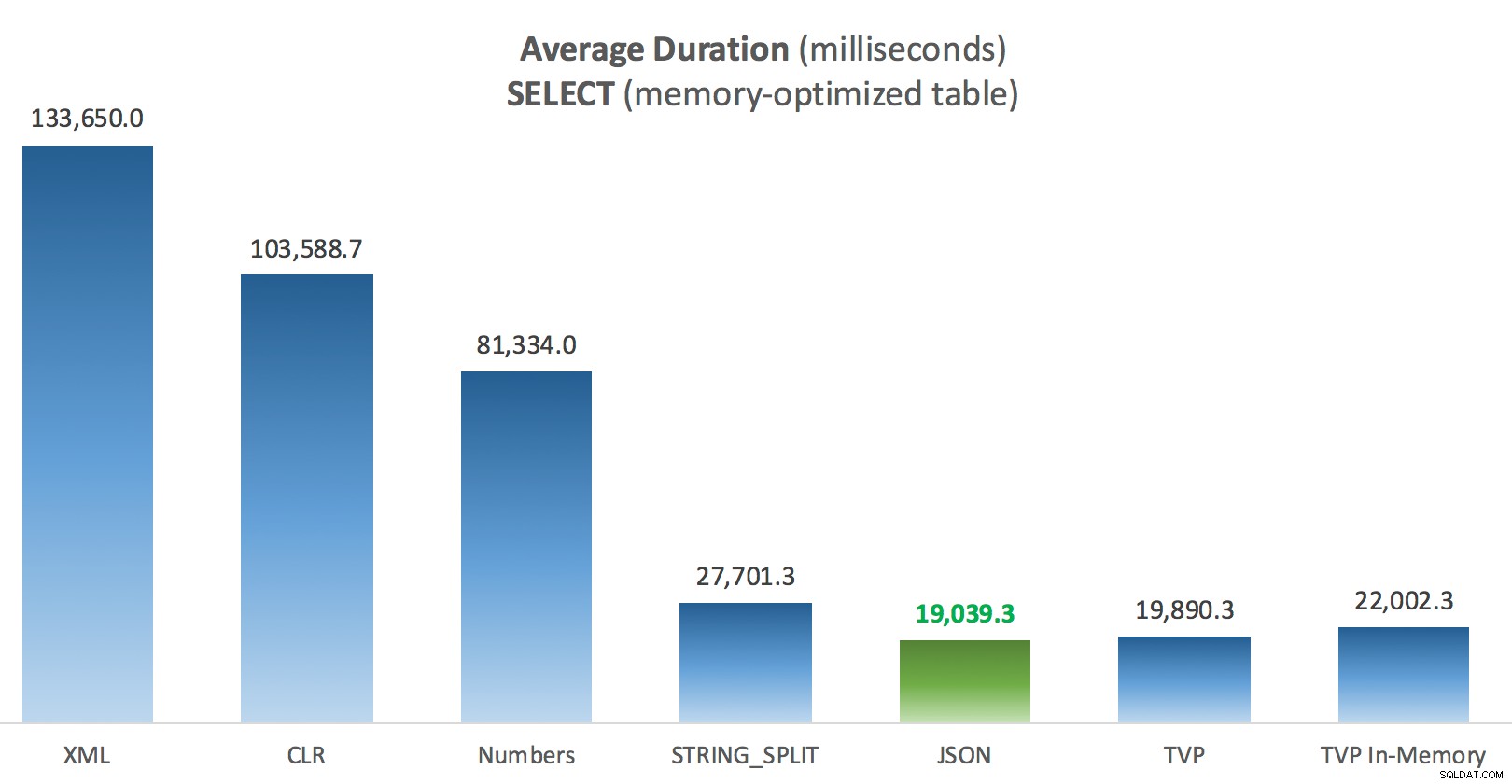 Duração média (milissegundos) para SELECTs em relação à tabela Posts com otimização de memória
Duração média (milissegundos) para SELECTs em relação à tabela Posts com otimização de memória 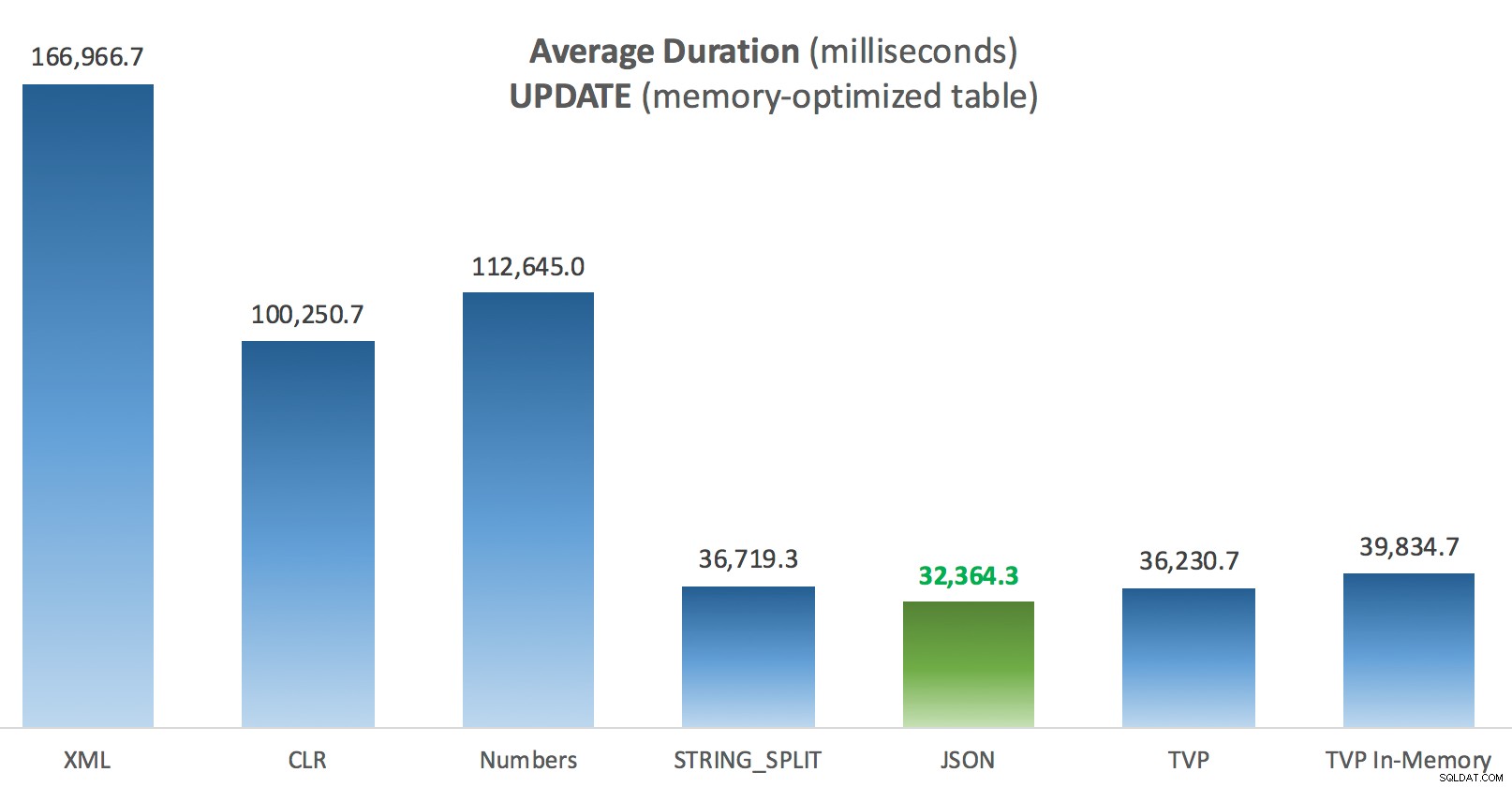 Duração média (milissegundos) para UPDATEs em relação à tabela de postagens com otimização de memória
Duração média (milissegundos) para UPDATEs em relação à tabela de postagens com otimização de memória Conclusão
Para este teste específico, com um tamanho de dados específico, distribuição e número de parâmetros, e no meu hardware específico, o JSON foi um vencedor consistente (embora marginalmente). Para alguns dos outros testes em posts anteriores, porém, outras abordagens se saíram melhor. Apenas um exemplo de como o que você está fazendo e onde você está fazendo pode ter um impacto dramático na eficiência relativa de várias técnicas, aqui estão as coisas que eu testei nesta breve série, com meu resumo de qual técnica usar nesse caso e qual usar como 2ª ou 3ª opção (por exemplo, se você não puder implementar o CLR devido à política corporativa ou porque está usando o Banco de Dados SQL do Azure, ou não pode usar JSON ou
STRING_SPLIT() porque você ainda não está no SQL Server 2016). Observe que eu não voltei e testei novamente a atribuição de variável e SELECT INTO scripts usando TVPs – esses testes foram configurados assumindo que você já tinha dados existentes no formato CSV que teriam que ser divididos primeiro de qualquer maneira. Geralmente, se você puder evitá-lo, não coloque seus conjuntos em strings separadas por vírgulas em primeiro lugar, IMHO. | Meta | 1ª escolha | 2ª escolha (e 3ª, quando apropriado) |
|---|---|---|
| Atribuição de variável simples | STRING_SPLIT() | CLR se <2016 XML se não houver CLR e <2016 |
| SELECIONAR EM | CLR | XML se não houver CLR |
| SELECT INTO (sem carretel) | CLR | Tabela de números se não houver CLR |
| SELECT INTO (sem carretel + MAXDOP 1) | STRING_SPLIT() | CLR se <2016 Tabela de números se não houver CLR e <2016 |
| SELECT juntando lista grande (com base em disco) | JSON (int) | TVP se <2016 |
| SELECT ingressando em lista grande (otimizado para memória) | JSON (int) | TVP se <2016 |
| ATUALIZAR ingressando em lista grande (com base em disco) | JSON (int) | TVP se <2016 |
| ATUALIZAR ingressando em lista grande (otimizado para memória) | JSON (int) | TVP se <2016 |
Para a pergunta específica de Doug:JSON,
STRING_SPLIT() , e os TVPs tiveram um desempenho bastante semelhante nesses testes em média – próximos o suficiente para que os TVPs sejam a escolha óbvia se você não estiver no SQL Server 2016. Se você tiver diferentes casos de uso, esses resultados podem ser diferentes. Muito . O que nos leva à moral de isto história:eu e outros podemos realizar testes de desempenho muito específicos, girando em torno de qualquer recurso ou abordagem, e chegar a alguma conclusão sobre qual abordagem é mais rápida. Mas há tantas variáveis que nunca terei confiança para dizer "essa abordagem é sempre o mais rápido." Nesse cenário, tentei muito controlar a maioria dos fatores contribuintes e, embora o JSON tenha vencido em todos os quatro casos, você pode ver como esses diferentes fatores afetaram os tempos de execução (e drasticamente para algumas abordagens). sempre vale a pena construir seus próprios testes, e espero ter ajudado a ilustrar como faço esse tipo de coisa.
Apêndice A:Código do aplicativo do console
Por favor, sem picuinhas sobre esse código; foi literalmente jogado junto como uma maneira muito simples de executar esses procedimentos armazenados 1.000 vezes com listas verdadeiras e DataTables montadas em C# e registrar o tempo que cada loop levou para uma tabela (para ter certeza de incluir qualquer sobrecarga relacionada ao aplicativo com manipulação uma string grande ou uma coleção). Eu poderia adicionar tratamento de erros, fazer um loop diferente (por exemplo, construir as listas dentro do loop em vez de reutilizar uma única unidade de trabalho) e assim por diante.
usando System;usando System.Text;usando System.Configuration;usando System.Data;usando System.Data.SqlClient; namespace SplitTesting{ class Program { static void Main(string[] args) { string operation ="Update"; if (args[0].ToString() =="-Selecionar") { operação ="Selecionar"; } var csv =new StringBuilder(); Elementos DataTable =new DataTable(); elements.Columns.Add("valor", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elements.Rows.Add(i*300); } string[] métodos ={ "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" }; using (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primary"].ToString(); con.Abrir(); SqlParameter p; foreach (método string em métodos) { SqlCommand cmd =new SqlCommand("dbo." + operação + "Posts_" + método, con); cmd.CommandType =CommandType.StoredProcedure; if (método =="TVP" || método =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =elements; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operação =="Atualizar") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Fechar(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // tempo de registro - o procedimento de registro adiciona o tempo do relógio e // grava baseado em memória/disco (determinado via sinônimo) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value =operação; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =method; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(método + ":" + this_time.ToString()); } } } }} Exemplo de uso:
SplitTesting.exe -Selecione
SplitTesting.exe -Atualizar
Apêndice B:Funções, Procedimentos e Tabela de Registro
Aqui estavam as funções editadas para suportar
varchar(max) (a função CLR já aceita nvarchar(max) e eu ainda estava relutante em tentar mudá-lo):CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [valor] FROM STRING_SPLIT(@List, @Delimiter));GO CREATE FUNCTION dbo.SplitStrings_XML ( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [valor] =y.i.value('(./text())[1]', 'varchar(max)') FROM (SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [valor] =SUBSTRING (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) FROM dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCH EMABINDINGAS RETURN (SELECT [valor] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (valor int '$'));GO E os procedimentos armazenados ficaram assim:
CRIAR PROCEDIMENTO dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [valor];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s.[value];ENDGO-- repita para os outros 4 métodos baseados em varchar(max) CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- alterne _Regular para _InMemoryASBEGIN SET NOCOUNT ON; UPDATE p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- alternar _Regular para _InMemory ASBEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- repita para na memória
E, finalmente, a tabela de log e o procedimento:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory ou Posts_Regular Operation varchar(32) NOT NULL DEFAULT 'Atualizar', -- ou selecione Método varchar(32) NOT NULL DEFAULT 'Native', -- ou TVP, JSON, etc. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN SET NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- e a consulta para gerar os gráficos:;WITH x AS( SELECT OperatingTable,Operation,Method,Time, Recency =ROW_NUMBER() OVER (PARTITION BY OperatingTable,Operation,Method ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable,Operation,Method,AverageDuration =AVG(1.0*Time) FROM x WHERE Recência <=3GROUP BY OperatingTable,Operation,Method;