Introdução
Descobrir que tipo de infraestrutura de banco de dados você precisa para atender aos requisitos de desempenho, confiabilidade e dimensionamento de seus aplicativos pode ser uma tarefa difícil. As escolhas que você faz para sua topologia de banco de dados podem afetar a forma como toda a sua pilha de aplicativos responde a diferentes tipos de uso e quais cenários de falha podem ser considerados. Por isso, é importante entender suas opções e tomar uma decisão informada que esteja alinhada com seus objetivos.
Há muitas maneiras diferentes de ir de um único banco de dados que trata de todas as suas necessidades de infraestrutura para sistemas mais complexos. Junto com isso, há muitos trade-offs a serem considerados.
Neste guia, apresentaremos alguns dos padrões mais comuns para infraestrutura de banco de dados relacional e como eles se alinham a diferentes padrões de uso. Veremos quais vantagens cada configuração oferece, bem como algumas das deficiências que você precisa considerar. Também falaremos sobre o impacto de diferentes decisões na complexidade geral de suas operações. Depois de terminar, você poderá tomar uma decisão melhor sobre quais designs são mais adequados para suas necessidades atuais e quais opções você pode experimentar à medida que suas necessidades mudam.
Escala vertical
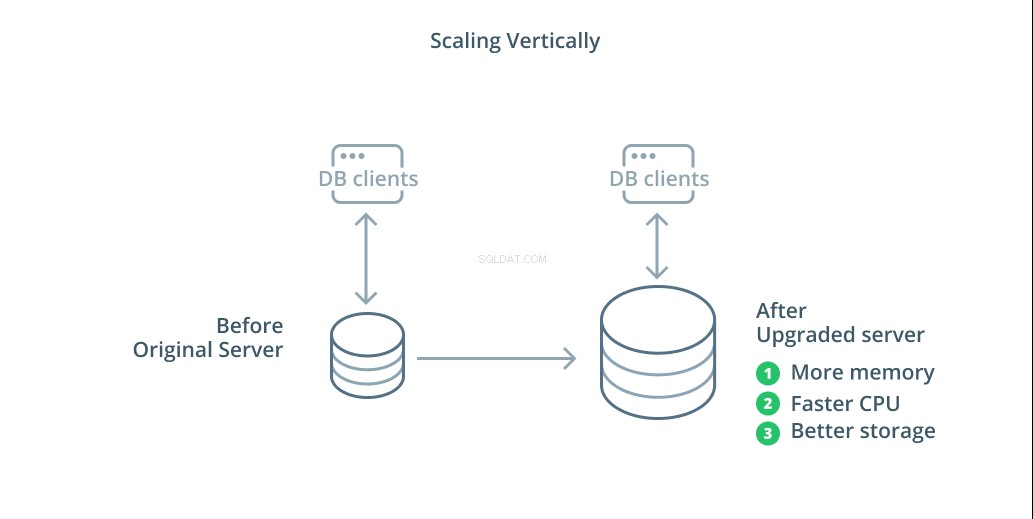
A maneira mais simples de dimensionar um sistema de banco de dados é o dimensionamento vertical. Escala vertical , também chamado de escalonamento , significa adicionar capacidade ao servidor que gerencia seu banco de dados. Ao aumentar o poder de processamento, alocação de memória ou capacidade de armazenamento, você pode aumentar o desempenho e o volume que um sistema de banco de dados pode manipular sem aumentar a complexidade do sistema como um todo.
Como regra geral, dimensionar o banco de dados é um bom primeiro passo, pois aumenta os recursos do banco de dados sem afetar a topologia da infraestrutura. O aumento de escala geralmente também é bastante simples, pois uma máquina de maior capacidade pode ser configurada como seguidora de replicação até que seja sincronizada e, em seguida, um failover possa ser acionado para torná-la o novo servidor primário.
No entanto, o aumento de escala tem suas limitações porque a quantidade de recursos que podem ser razoavelmente alocados para uma máquina é restrita. Ele também representa um único ponto de falha se nenhum seguidor de replicação estiver configurado para assumir o controle quando ocorrerem problemas. Essas preocupações são abordadas por algumas das outras opções de dimensionamento.
Segregação de responsabilidade de consulta de comando (CQRS) e réplicas somente leitura
A outra maneira principal de dimensionar sua infraestrutura de banco de dados é dimensionar horizontalmente. Escalando significa que, em vez de aumentar a capacidade de um único servidor, você aumenta o número de servidores dedicados a atender a uma necessidade específica. Assim, você adiciona capacidade adicionando máquinas adicionais à sua infraestrutura.
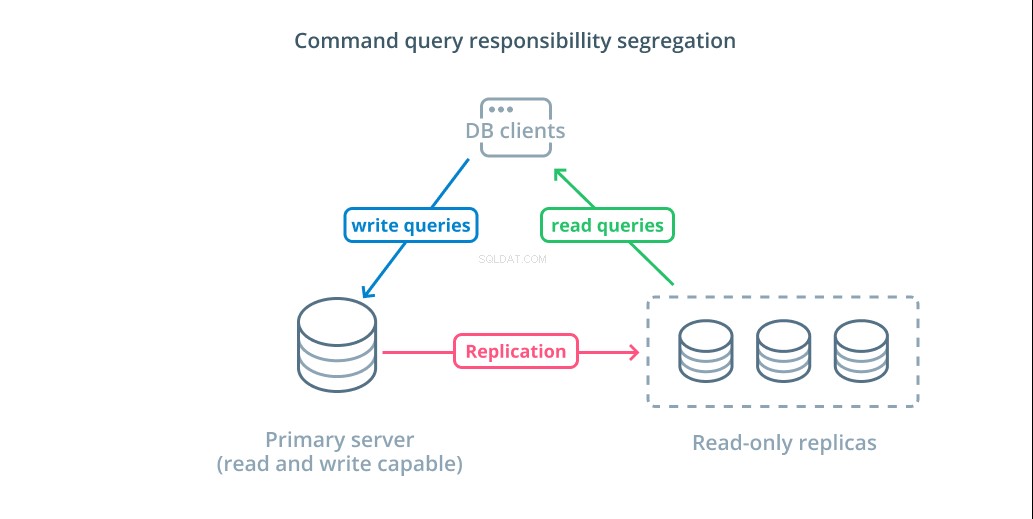
Segregação de responsabilidade de consulta de comando (CQRS) é um termo usado para descrever a adição de lógica para separar as consultas que alteram dados (consultas de gravação) daquelas que não o fazem (consultas de leitura). Isso permite rotear essas diferentes categorias de solicitações para diferentes hosts para ajudar a distribuir a carga.
A infraestrutura mais básica para aproveitar esse design é um servidor primário que pode aceitar consultas de leitura e gravação combinadas com um ou mais servidores de réplica seguindo o servidor primário que pode aceitar consultas de leitura. Esse design é apropriado para padrões de uso de aplicativos que são de leitura intensa, pois as operações de leitura podem ser tratadas por qualquer um dos servidores de banco de dados.
Além disso, este sistema fornece alguma redundância à sua arquitetura, pois o sistema ainda funcionará se algum dos servidores ficar inativo. Se um seguidor ficar inativo, as solicitações de leitura podem ser roteadas para os outros servidores. Se o servidor primário ficar inativo, um dos seguidores de réplica poderá ser promovido para aceitar consultas de gravação.
Replicação multiprimária
Embora o uso do CQRS com réplicas somente leitura ajude a atender a um número maior de solicitações de leitura, isso não afeta significativamente o desempenho de gravação de sua infraestrutura. Para aumentar o número de gravações que sua arquitetura pode suportar, você precisa considerar se pode adotar um design de replicação multiprimária.
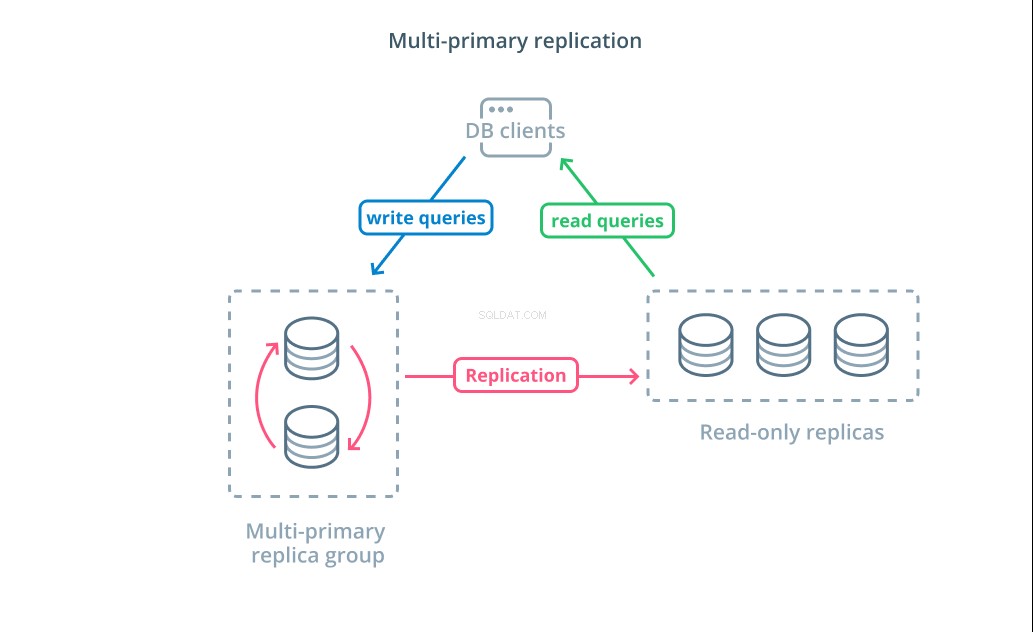
Replicação multiprimária é uma forma de replicação em que vários servidores podem aceitar solicitações de gravação. Alguns sistemas são configurados para que qualquer servidor possa processar solicitações de gravação, enquanto outros são projetados para que um grupo principal de servidores primários lide com gravações com um número maior de seguidores somente leitura. Independentemente da implementação, a replicação multiprimária aumenta o número de servidores responsáveis pelas consultas de gravação.
Embora esse design pareça ideal no início, existem alguns grandes desafios que impedem que esse seja um padrão amplamente adotado. Embora vários servidores possam lidar com solicitações de gravação, eles ainda devem se coordenar para replicar as alterações entre seus servidores e resolver conflitos nas alterações de dados. Isso pode levar a longos tempos de resposta à medida que os conflitos são negociados ou a possibilidade de dados inconsistentes.
Cada sistema escolhe sua própria abordagem para lidar com esses desafios. Esta é uma demonstração do Teorema CAP — uma declaração descrevendo a interação entre consistência, disponibilidade e tolerância de partição em sistemas distribuídos — em ação. Alguns sistemas oferecem garantias de consistência mais fracas para manter a disponibilidade, enquanto outros bancos de dados se recusam a aceitar alterações se seus pares não puderem coordenar a transação no momento da gravação. Escolher a abordagem que melhor se adapta às suas necessidades é um fator importante ao decidir entre várias implementações.
Ler o cache de consulta
Embora o uso de réplicas somente leitura seja uma maneira de aumentar os bancos de dados disponíveis que podem responder a solicitações de leitura, isso não melhora o desempenho de consulta básica de operações de leitura complexas. Espera-se que um dos servidores execute a operação de leitura sempre que uma solicitação for feita, mesmo que os resultados sejam idênticos à pesquisa anterior.
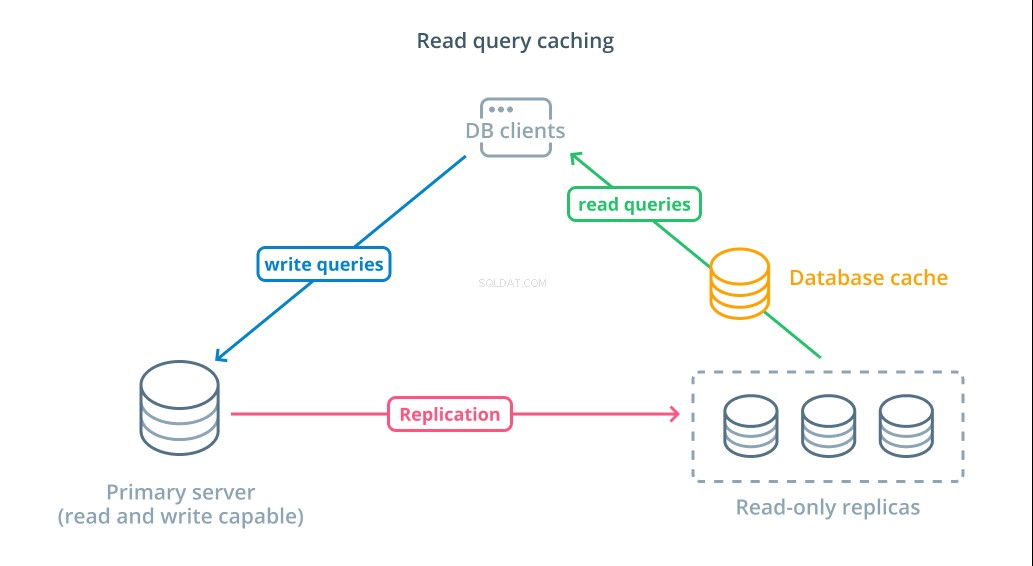
Para diminuir os tempos de resposta, um caching de consulta de leitura camada pode ser introduzida. Adicionar um cache entre seus clientes de banco de dados e os próprios bancos de dados pode reduzir significativamente o tempo de consulta para solicitações comuns. O aplicativo pode solicitar resultados de leitura do cache e recebê-los quase imediatamente, se disponíveis. Para casos em que os resultados não são encontrados no cache, eles são buscados no próprio banco de dados e adicionados ao cache para a próxima vez.
Configurar o cache dessa maneira é incrivelmente eficiente para cenários em que os dados provavelmente não serão alterados toda vez que a solicitação for feita. É especialmente útil para consultas de leitura caras que consultam várias tabelas e incluem operações de junção complexas. Esses resultados podem ser executados uma vez e salvos para consultas futuras.
Nos casos em que os dados estão mudando mais rapidamente, um cache de leitura pode não ajudar tanto. Dependendo do comportamento configurado, os caches correm o risco de retornar dados obsoletos nessas situações e estratégias de invalidação de cache devem ser implementadas para remover dados obsoletos do cache quando alterados.
Fragmentação de dados
Até agora, os designs que discutimos segmentaram os componentes do banco de dados com base no fato de responderem ou não a solicitações de gravação. No entanto, outra maneira de dividir a responsabilidade é dividir o conjunto de dados real em várias partes.
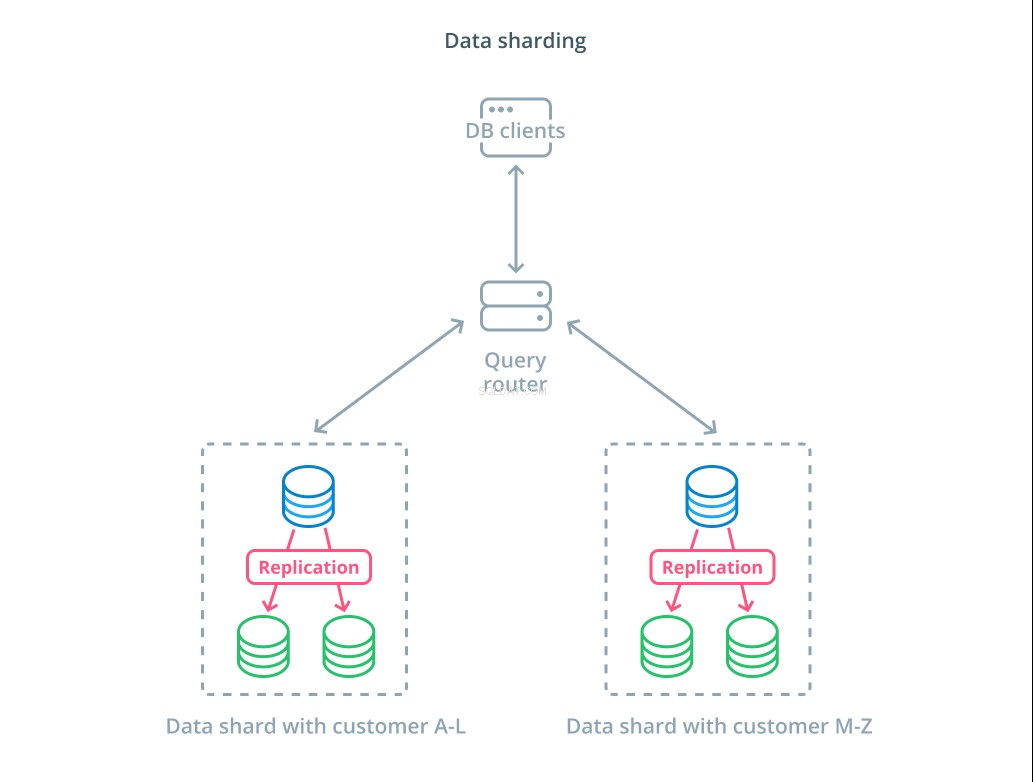
Fragmentação é o processo de quebrar um conjunto de dados lógicos em subconjuntos menores para distribuir seu gerenciamento para diferentes máquinas. Cada servidor de banco de dados lida apenas com uma parte dos dados e é introduzida uma mecânica de roteamento que entende quais máquinas são responsáveis por quais partes dos dados.
Normalmente, a fragmentação é executada em cenários em que a operação em todo o conjunto de dados de uma só vez é desnecessária ou incomum. O conjunto de dados é segmentado com base no valor de cada registro para uma chave específica, conhecida como chave de fragmentação . Por exemplo, você pode fragmentar dados manualmente com base na localização dos clientes. Você também pode fragmentar automaticamente usando um algoritmo de hash para determinar quais nós devem manipular quais chaves. Isso pode ajudar seu sistema a evitar a distribuição desequilibrada nos casos em que o espaço de chave do estilhaço é distribuído de forma desigual.
O sharding introduz um pouco de complexidade nos sistemas de dados e não é apropriado para todos os cenários. As operações que interagem com vários shards sofrerão penalidades de desempenho significativas à medida que recuperam os resultados de cada membro. Isso pode acontecer para consultas agregadas ou se a chave de fragmentação específica não for conhecida antecipadamente. Além disso, a alocação desigual de estilhaços também pode causar ineficiências e gargalos que precisam ser corrigidos reequilibrando a distribuição de todo o conjunto de dados.
Gerenciamento de dados funcionais descentralizado
Em vez de dividir os valores de um conjunto de dados em vários segmentos, em muitos casos, faz mais sentido usar bancos de dados diferentes para fins funcionais diferentes. Por exemplo, se você tiver um serviço de contas e um serviço de produtos, ter bancos de dados dedicados que coincidam com cada preocupação pode ajudá-lo a dimensionar diferentes componentes de forma independente.
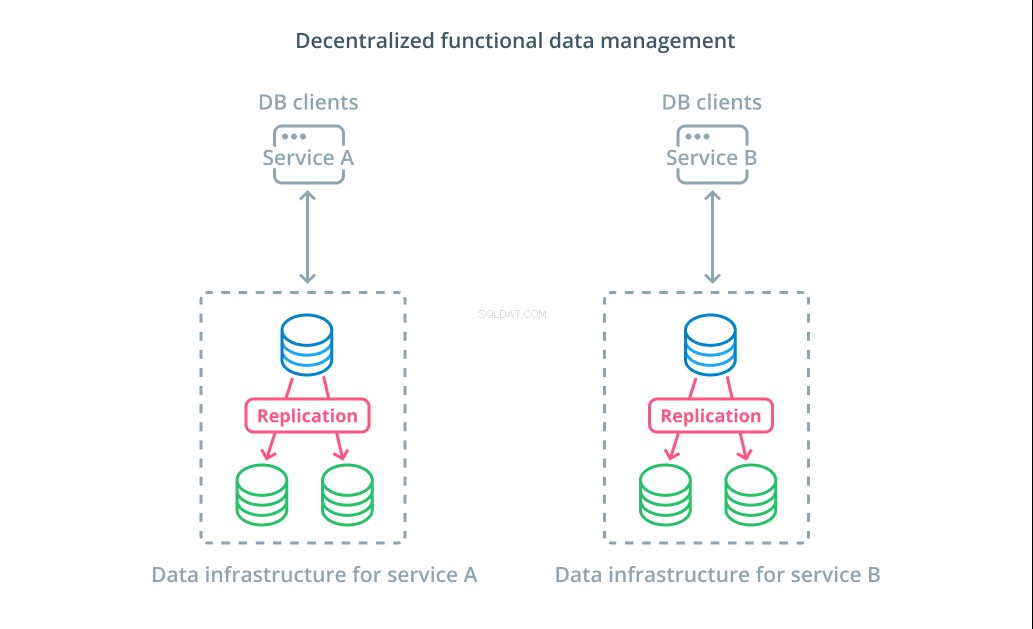
O gerenciamento de dados funcional permite dividir sua infraestrutura de banco de dados e gerenciar cada parte de acordo com as necessidades de seus clientes. Cada parte funcional pode ser dimensionada usando qualquer estratégia que faça mais sentido. Ele permite projetar o esquema do banco de dados e implantá-lo em um local que melhor corresponda aos padrões de um caso de uso específico, em vez de exigir que ele atenda a toda a organização.
Para muitas organizações, essa estratégia tem vantagens importantes que vão além das propriedades dos sistemas reais. A descentralização do gerenciamento de dados pode permitir que equipes menores possuam seus próprios dados sem coordenar as alterações com outras partes. Ele se alinha bem com a separação focada de preocupações promovida por arquiteturas de aplicativos orientadas a microsserviços.
Bancos de dados sem servidor
As diferentes compensações que você deve avaliar e a quantidade de infraestrutura que você deve gerenciar para o dimensionamento adequado podem ser esmagadoras para muitas pessoas. Uma opção para descarregar essa complexidade é aproveitar os serviços de banco de dados que gerenciam a infraestrutura e dimensionam para você.
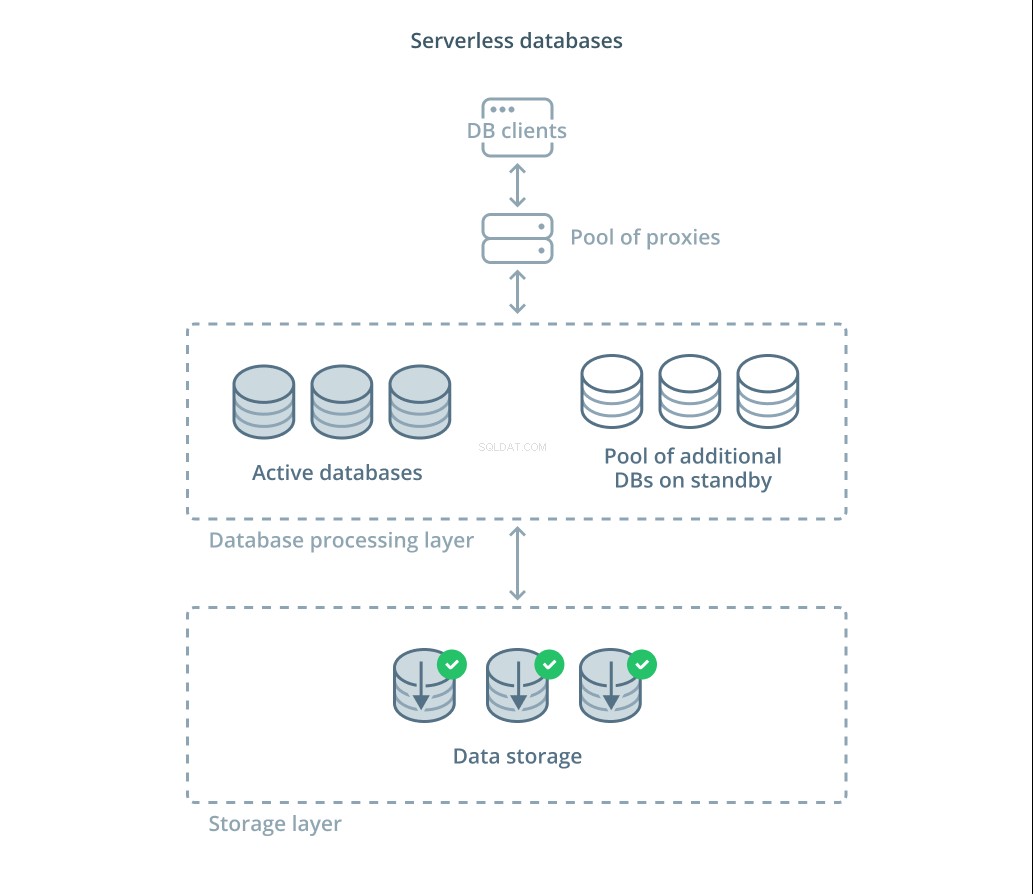
Bancos de dados sem servidor são uma categoria de serviços que desacoplam o armazenamento de dados do processamento de dados para dimensionar facilmente os recursos em resposta às mudanças na demanda.
Uma camada de armazenamento de dados é responsável por manter os dados reais gerenciados pelo sistema. Na frente dessa camada, uma camada de unidades de processamento de banco de dados escaláveis é implantada para lidar com o processamento de consulta real nos conjuntos de dados. O número de unidades ativas em um determinado momento está vinculado diretamente ao uso atual, portanto, mais recursos são alocados conforme os picos de demanda e as unidades de processamento são devolvidas ao modo de espera se as coisas se acalmarem.
As consultas são encaminhadas aos processadores de banco de dados por meio de um proxy de roteamento que sabe como encaminhar solicitações para os nós ativos e quando solicitar recursos adicionais.
Os bancos de dados sem servidor têm muitas das mesmas propriedades dos serviços de banco de dados tradicionais que implementam recursos de dimensionamento automático. Ambos podem alocar capacidade com base na demanda. No entanto, os bancos de dados sem servidor permitem separar os custos de armazenamento dos custos de processamento e podem reduzir o processamento a zero quando não for necessário. Além disso, as soluções sem servidor tendem a ser dimensionadas muito mais rapidamente para atender à demanda em comparação com o dimensionamento automático oferecido pelas ofertas tradicionais.
Embora os bancos de dados sem servidor possam ser uma boa opção para alguns, eles não são uma bala de prata. Nos casos em que os processadores de banco de dados foram reduzida a zero, pode haver atrasos no processamento novamente devido a partidas a frio. Além disso, a rotatividade das conexões entre os vários componentes em uma pilha de banco de dados sem servidor pode levar a latência adicional.
Plataformas de banco de dados sem servidor também podem ser difíceis do ponto de vista das operações. As implantações e as alterações no banco de dados podem ser mais difíceis de raciocinar e monitorar. O ambiente de desenvolvimento local também pode diferir significativamente do ambiente de produção devido ao estado dinâmico do sistema de banco de dados. E, finalmente, como em qualquer outro serviço de nuvem, o uso de bancos de dados sem servidor pode colocar você em risco de ficar preso ao fornecedor. É importante lembrar dessas compensações ao projetar em torno de uma plataforma sem servidor.
Conclusão
Há muitas maneiras de projetar, implantar e gerenciar sua infraestrutura de banco de dados à medida que os requisitos de seu aplicativo se tornam mais sérios. Cada solução tem seus pontos fortes e limitações que são importantes para entender ao tentar encontrar um ajuste para seu ambiente.
Aprender sobre como a infraestrutura de banco de dados afeta a disponibilidade, o desempenho e a integridade de seus dados permite evitar erros dispendiosos e implementações que não fornecem as garantias necessárias. Se um dos designs acima não atender às suas necessidades, você poderá combinar alguns dos elementos de diferentes abordagens para obter vantagens adicionais.
Se você quiser saber mais sobre os padrões gerais abordados acima, aqui estão alguns recursos adicionais que você pode conferir:
- Ampliação versus ampliação
- Segregação de responsabilidade de consulta de comando
- Replicação multiprimária
- Como armazenar consultas de leitura em cache
- Fragmentação de dados
- Gerenciamento de dados descentralizado
- Bancos de dados sem servidor