O SQL Server nos fornece várias funções de janela que nos ajudam a realizar cálculos em um conjunto de linhas, sem a necessidade de repetir as chamadas ao banco de dados. Ao contrário das funções agregadas padrão, as funções de janela não agruparão as linhas em uma única linha de saída, elas retornarão um único valor agregado para cada linha, mantendo as identidades separadas para essas linhas. O termo Window aqui não está relacionado ao sistema operacional Microsoft Windows, ele descreve o conjunto de linhas que a função processará.
Um dos tipos mais úteis de funções de janela são as Funções de Janela de Classificação que são usadas para classificar valores de campo específicos e categorizá-los de acordo com a classificação de cada linha, resultando em um único valor agregado para cada linha participada. Há quatro funções de janela de classificação com suporte no SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE(). Todas essas funções são usadas para calcular ROWID para a janela de linhas fornecida à sua maneira.
Quatro funções de janela de classificação usam a cláusula OVER() que define um conjunto de linhas especificado pelo usuário em um conjunto de resultados de consulta. Ao definir a cláusula OVER(), você também pode incluir a cláusula PARTITION BY que determina o conjunto de linhas que a função de janela processará, fornecendo colunas ou colunas separadas por vírgula para definir a partição. Além disso, pode ser incluída a cláusula ORDER BY, que define os critérios de ordenação dentro das partições que a função passará pelas linhas durante o processamento.
Neste artigo, discutiremos como usar quatro funções de janela de classificação:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE() praticamente, e a diferença entre elas.
Para servir nossa demonstração, vamos criar uma nova tabela simples e inserir alguns registros na tabela usando o script T-SQL abaixo:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Você pode verificar se os dados foram inseridos com sucesso usando a seguinte instrução SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScoreCom o resultado classificado aplicado, o conjunto de resultados é o seguinte:

ROW_NUMBER()
A função de janela de classificação ROW_NUMBER() retorna um número sequencial exclusivo para cada linha dentro da partição da janela especificada, começando em 1 para a primeira linha em cada partição e sem repetir ou pular números no resultado de classificação de cada partição. Se houver valores duplicados no conjunto de linhas, os números de ID de classificação serão atribuídos arbitrariamente. Se a cláusula PARTITION BY for especificada, o número da linha de classificação será redefinido para cada partição. Na tabela criada anteriormente, a consulta abaixo mostra como utilizar a função da janela de classificação ROW_NUMBER para classificar as linhas da tabela StudentScore de acordo com a pontuação de cada aluno:
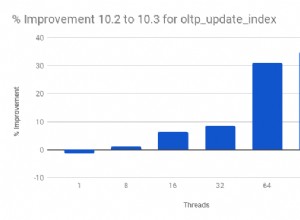
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
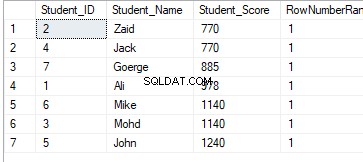
É claro a partir do conjunto de resultados abaixo que a função de janela ROW_NUMBER classifica as linhas da tabela de acordo com os valores da coluna Student_Score para cada linha, gerando um número único de cada linha que reflete sua classificação Student_Score começando do número 1 sem duplicatas ou lacunas e lidar com todas as linhas como uma partição. Você pode ver também que as pontuações duplicadas são atribuídas a diferentes classificações aleatoriamente:
Se modificarmos a consulta anterior incluindo a cláusula PARTITION BY para ter mais de uma partição, conforme mostrado na consulta T-SQL abaixo:
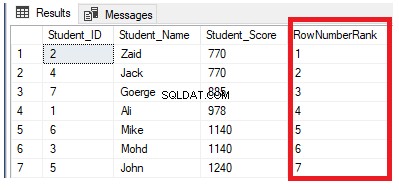
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
O resultado mostrará que a função de janela ROW_NUMBER classificará as linhas da tabela de acordo com os valores da coluna Student_Score para cada linha, mas lidará com as linhas que têm o mesmo valor Student_Score como uma partição. Você verá que um número único será gerado para cada linha refletindo sua classificação Student_Score, começando do número 1 sem duplicatas ou lacunas dentro da mesma partição, redefinindo o número da classificação ao passar para um valor Student_Score diferente.
Por exemplo, os alunos com pontuação 770 serão classificados dentro dessa pontuação, atribuindo-lhe um número de classificação. No entanto, quando for movido para o aluno com pontuação 885, o número inicial da classificação será redefinido para iniciar novamente em 1, conforme mostrado abaixo:
RANK()
A função de janela de classificação RANK() retorna um número de classificação exclusivo para cada linha distinta dentro da partição de acordo com um valor de coluna especificado, começando em 1 para a primeira linha em cada partição, com a mesma classificação para valores duplicados e deixando lacunas entre as classificações; essa lacuna aparece na sequência após os valores duplicados. Em outras palavras, a função de janela de classificação RANK() se comporta como a função ROW_NUMBER(), exceto para as linhas com valores iguais, onde ela será classificada com o mesmo ID de classificação e gerará uma lacuna após ela. Se modificarmos a consulta de classificação anterior para usar a função de classificação RANK():
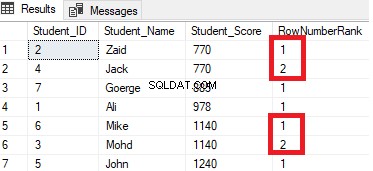
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreVocê verá a partir do resultado que a função da janela RANK classificará as linhas da tabela de acordo com os valores da coluna Student_Score para cada linha, com um valor de classificação refletindo sua Student_Score começando no número 1 e classificando as linhas que têm a mesma Student_Score com o mesmo valor de classificação. Você também pode ver que duas linhas com Student_Score igual a 770 são classificadas com o mesmo valor, deixando uma lacuna, que é o número 2 perdido, após a segunda linha classificada. O mesmo acontece com as linhas em que Student_Score é igual a 1140 que são classificadas com o mesmo valor, deixando uma lacuna, que é o número 6 ausente, após a segunda linha, conforme mostrado abaixo:
Modificando a consulta anterior incluindo a cláusula PARTITION BY para ter mais de uma partição, conforme mostrado na consulta T-SQL abaixo:
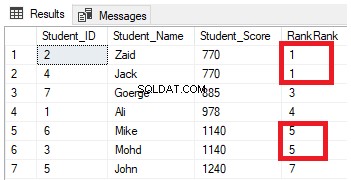
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreO resultado da classificação não terá significado, pois a classificação será feita de acordo com os valores Student_Score por cada partição, e os dados serão particionados de acordo com os valores Student_Score. E devido ao fato de que cada partição terá linhas com os mesmos valores Student_Score, as linhas com os mesmos valores Student_Score na mesma partição serão classificadas com um valor igual a 1. Assim, ao passar para a segunda partição, a classificação será ser zerado, começando novamente com o número 1, tendo todos os valores de classificação iguais a 1 conforme mostrado abaixo:
DENSE_RANK()
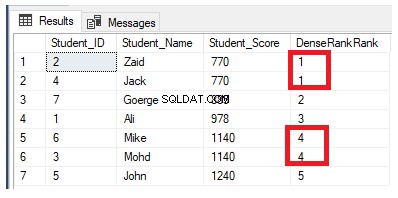
A função de janela de classificação DENSE_RANK() é semelhante à função RANK() gerando um número de classificação exclusivo para cada linha distinta dentro da partição de acordo com um valor de coluna especificado, começando em 1 para a primeira linha em cada partição, classificando as linhas com valores iguais com o mesmo número de rank, exceto que não salta nenhum rank, não deixando espaços entre os ranks.
Se reescrevermos a consulta de classificação anterior para usar a função de classificação DENSE_RANK():
Novamente, modifique a consulta anterior incluindo a cláusula PARTITION BY para ter mais de uma partição, conforme mostrado na consulta T-SQL abaixo:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
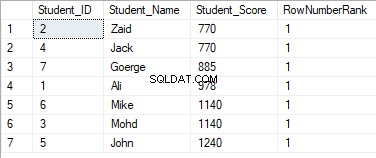
Os valores de classificação não terão significado, onde todas as linhas serão classificadas com o valor 1, devido à atribuição dos valores duplicados ao mesmo valor de classificação e redefinição do id inicial da classificação ao processar uma nova partição, conforme mostrado abaixo:
NTILE(N)
A função da janela de classificação NTILE(N) é usada para distribuir as linhas nas linhas definidas em um número especificado de grupos, fornecendo a cada linha no conjunto de linhas um número de grupo exclusivo, começando com o número 1 que mostra o grupo a que esta linha pertence para, onde N é um número positivo, que define o número de grupos que você precisa para distribuir as linhas definidas.
Em outras palavras, se você precisar dividir linhas de dados específicas da tabela em 3 grupos, com base em valores de coluna específicos, a função da janela de classificação NTILE(3) ajudará você a conseguir isso facilmente.
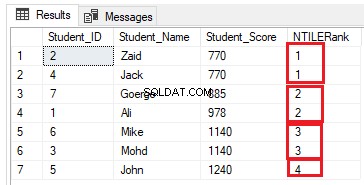
O número de linhas em cada grupo pode ser calculado dividindo o número de linhas pelo número necessário de grupos. Se modificarmos a consulta de classificação anterior para usar a função de janela de classificação NTILE(4) para classificar sete linhas da tabela em quatro grupos como a consulta T-SQL abaixo:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
O número de linhas deve ser (7/4=1,75) linhas em cada grupo. Usando a função NTILE(), o SQL Server Engine atribuirá 2 linhas aos três primeiros grupos e uma linha ao último grupo, para que todas as linhas sejam incluídas nos grupos, conforme mostrado no conjunto de resultados abaixo:
Modificando a consulta anterior incluindo a cláusula PARTITION BY para ter mais de uma partição, conforme mostrado na consulta T-SQL abaixo:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
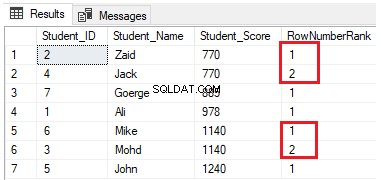
FROM StudentScoreAs linhas serão distribuídas em quatro grupos em cada partição. Por exemplo, as duas primeiras linhas com Student_Score igual a 770 estarão na mesma partição e serão distribuídas dentro dos grupos classificando cada uma com um número único, conforme mostrado no conjunto de resultados abaixo:
Juntando tudo
Para ter um cenário de comparação mais claro, vamos truncar a tabela anterior, adicionar outro critério de classificação, que é a turma dos alunos, e por fim inserir novas sete linhas utilizando o script T-SQL abaixo:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Depois disso, classificaremos sete linhas de acordo com a pontuação de cada aluno, dividindo os alunos de acordo com sua classe. Em outras palavras, cada partição incluirá uma turma, e cada turma de alunos será classificada de acordo com suas pontuações dentro da mesma turma, usando quatro funções de janela de classificação descritas anteriormente, conforme mostrado no script T-SQL abaixo:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
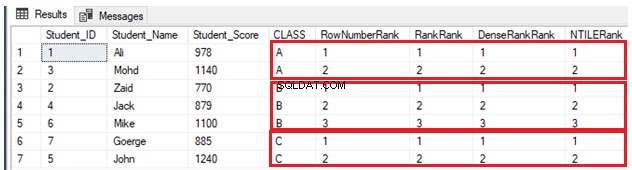
GODevido ao fato de não haver valores duplicados, quatro funções da janela de classificação funcionarão da mesma forma, retornando o mesmo resultado, conforme mostrado no conjunto de resultados abaixo:
Se outro aluno for incluído na turma A com nota, que outro aluno da mesma turma já tenha, usando a instrução INSERT abaixo:
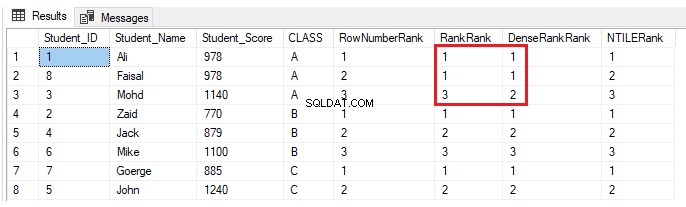
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Nada mudará para as funções da janela de classificação ROW_NUMBER() e NTILE(). As funções RANK e DENSE_RANK() atribuirão a mesma classificação para os alunos com a mesma pontuação, com uma lacuna nas classificações após as classificações duplicadas ao usar a função RANK e nenhuma lacuna nas classificações após as classificações duplicadas ao usar a função DENSE_RANK( ), como mostra o resultado abaixo:
Cenário Prático
As funções da janela de classificação são amplamente utilizadas pelos desenvolvedores do SQL Server. Um dos cenários comuns para o uso das funções de classificação, quando você deseja buscar linhas específicas e pular outras, usando a função de janela de classificação ROW_NUMBER(,) dentro de um CTE, como no script T-SQL abaixo que retorna os alunos com classificações entre 2 e 5 e pule os outros:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
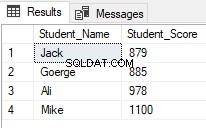
O resultado mostrará que apenas os alunos com classificações entre 2 e 5 serão devolvidos:
A partir do SQL Server 2012, um novo comando útil, OFFSET FETCH foi introduzido que pode ser usado para realizar a mesma tarefa anterior buscando registros específicos e pulando os demais, utilizando o script T-SQL abaixo:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
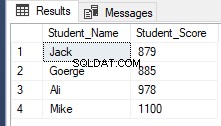
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Recuperando o mesmo resultado anterior, conforme mostrado abaixo:
Conclusão
O SQL Server nos fornece quatro funções de janela de classificação que nos ajudam a classificar as linhas fornecidas definidas de acordo com valores de coluna específicos. Estas funções são:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE(). Todas essas funções de classificação executam a tarefa de classificação à sua maneira, retornando o mesmo resultado quando não há valores duplicados nas linhas. Se houver um valor duplicado no conjunto de linhas, a função RANK atribuirá o mesmo ID de classificação para todas as linhas com o mesmo valor, deixando lacunas entre as classificações após as duplicatas. A função DENSE_RANK também atribuirá o mesmo ID de classificação para todas as linhas com o mesmo valor, mas não deixará nenhuma lacuna entre as classificações após as duplicatas. Passamos por diferentes cenários neste artigo para cobrir todos os casos possíveis que ajudam você a entender praticamente as funções da janela de classificação.
Referências:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- Cláusula OFFSET FETCH (SQL Server Compact)