Introdução
Alcançando o registro mínimo usando
INSERT...SELECT em um vazio o destino de índice clusterizado não é tão simples quanto descrito no Guia de carregamento de desempenho de dados . Esta postagem fornece novos detalhes sobre os requisitos para registro mínimo quando o destino de inserção é um índice clusterizado tradicional vazio. (A palavra “tradicional” exclui columnstore e otimizado para memória ('Hekaton') tabelas agrupadas). Para as condições que se aplicam quando a tabela de destino é um heap, consulte o artigo anterior desta série.
Resumo para tabelas agrupadas
O Guia de desempenho de carregamento de dados contém um resumo de alto nível das condições necessárias para registro mínimo em tabelas agrupadas:
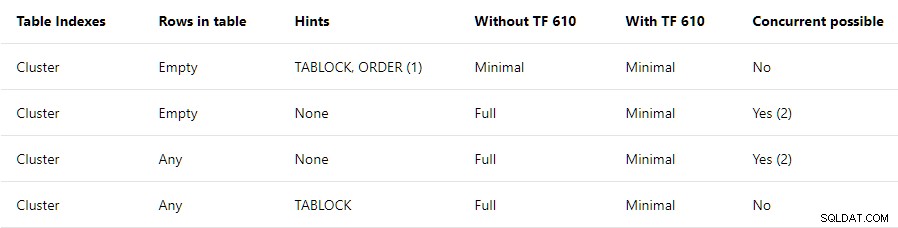
Esta postagem está relacionada à linha superior apenas . Ele afirma que
TABLOCK e ORDER dicas são necessárias, com uma nota que diz:Se você estiver usando o método INSERT … SELECT, a dica ORDER não precisa ser especificada, mas as linhas devem estar na mesma ordem que o índice clusterizado.
Se estiver usando BULK INSERT, a dica de pedido deve ser usada.
Alvo vazio com bloqueio de tabela
A linha superior do resumo sugere que todos inserções em um índice clusterizado vazio serão minimamente registradas contanto que
TABLOCK e ORDER dicas são especificadas. O TABLOCK dica é necessária para habilitar o RowSetBulk facilidade como usado para cargas a granel de mesa heap. Um ORDER dica é necessária para garantir que as linhas cheguem ao Inserção de índice clusterizado operador de plano no índice de destino ordem de chave . Sem essa garantia, o SQL Server pode adicionar linhas de índice que não são classificadas corretamente, o que não seria bom. Ao contrário de outros métodos de carregamento em massa, não é possível para especificar o
ORDER necessário dica em um INSERT...SELECT demonstração. Esta dica não é a mesma como usando um ORDER BY cláusula no INSERT...SELECT demonstração. Um ORDER BY cláusula em um INSERT apenas garante a forma como qualquer identidade os valores são atribuídos, não a ordem de inserção de linha. Para
INSERT...SELECT , o SQL Server faz sua própria determinação se deve garantir que as linhas sejam apresentadas à Inserção de índice clusterizado operador em ordem de chave ou não. O resultado dessa avaliação é visível nos planos de execução por meio do DMLRequestSort propriedade do Inserir operador. O DMLRequestSort propriedade deve ser definido como true para INSERT...SELECT em um índice para ser minimamente registrado . Quando está definido como falso , registro mínimo não pode ocorrer. Tendo
DMLRequestSort definido como true é a única garantia aceitável de ordenação de entrada de inserção para SQL Server. Pode-se inspecionar o plano de execução e prever que as linhas devem/devem chegar em ordem de índice clusterizado, mas sem as garantias internas específicas fornecido por DMLRequestSort , essa avaliação não conta para nada. Quando
DMLRequestSort é verdadeiro , o SQL Server pode introduzir uma Classificação explícita operador no plano de execução. Se puder garantir internamente o pedido de outras maneiras, o Classificar pode ser omitido. Se as alternativas de classificação e não classificação estiverem disponíveis, o otimizador fará uma baseada em custo escolha. A análise de custo não leva em conta o registro mínimo diretamente; é impulsionado pelos benefícios esperados da E/S sequencial e pela prevenção da divisão de páginas. Condições de DMLRequestSort
Ambos os testes a seguir devem passar para o SQL Server escolher definir
DMLRequestSort para verdadeiro ao inserir em um índice clusterizado vazio com bloqueio de tabela especificado:- Uma estimativa de mais de 250 linhas no lado de entrada da Inserção de índice clusterizado operador; e
- Uma estimativa tamanho de dados de mais de 2 páginas . O tamanho estimado dos dados não é um número inteiro, portanto, um resultado de 2.001 páginas atenderia a essa condição.
(Isso pode lembrá-lo das condições para heap registro mínimo , mas a estimativa necessária o tamanho dos dados aqui é de duas páginas em vez de oito.)
Cálculo do tamanho dos dados
O tamanho estimado dos dados cálculo aqui está sujeito às mesmas peculiaridades descritas no artigo anterior para heaps, exceto que o RID de 8 bytes não está presente.
Para SQL Server 2012 e anteriores, isso significa 5 bytes extras por linha são incluídos no cálculo do tamanho dos dados:Um byte para um bit interno sinalizador e quatro bytes para o uniquifier (usado no cálculo mesmo para índices únicos, que não armazenam um uniquifier ).
Para SQL Server 2014 e posterior, o uniquifier é omitido corretamente para único índices, mas o um byte extra para o bit interno bandeira é mantida.
Demonstração
O script a seguir deve ser executado em uma instância de desenvolvimento do SQL Server em um novo banco de dados de teste definido para usar o
SIMPLE ou BULK_LOGGED modelo de recuperação. A demonstração carrega 268 linhas em uma nova tabela clusterizada usando
INSERT...SELECT com TABLOCK , e relatórios sobre os registros de log de transações gerados. IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; (Se você executar o script no SQL Server 2012 ou anterior, altere o
TOP cláusula no script de 268 a 252, por motivos que serão explicados em breve.) A saída mostra que todas as linhas inseridas foram totalmente registradas apesar do vazio tabela clusterizada de destino e o
TABLOCK dica: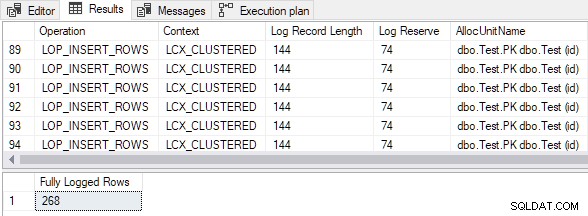
Tamanho calculado dos dados de inserção
As propriedades do plano de execução da Inserção de índice clusterizado operador mostra que
DMLRequestSort está definido como falso . Isso ocorre porque, embora o número estimado de linhas a serem inseridas seja superior a 250 (atendendo ao primeiro requisito), o valor calculado tamanho dos dados não exceder duas páginas de 8 KB. Os detalhes do cálculo (para SQL Server 2014 em diante) são os seguintes:
- Total de comprimento fixo tamanho da coluna =54 bytes :
- ID do tipo 104
bit=1 byte (interno). - ID do tipo 56
integer=4 bytes (idcoluna). - ID do tipo 56
integer=4 bytes (c1coluna). - ID do tipo 175
char(45)=45 bytes (paddingcoluna).
- ID do tipo 104
- Bitmap nulo =3 bytes .
- Cabeçalho da linha sobrecarga =4 bytes .
- Tamanho da linha calculada =54 + 3 + 4 =61 bytes .
- Tamanho dos dados calculados =61 bytes * 268 linhas =16.348 bytes .
- Páginas de dados calculados =16.384 / 8192 =1,99560546875 .
O tamanho de linha calculado (61 bytes) difere do tamanho de armazenamento de linha real (60 bytes) por um byte extra de metadados internos presentes no fluxo de inserção. O cálculo também não leva em conta os 96 bytes usados em cada página pelo cabeçalho da página ou outras coisas como sobrecarga de versão de linha. A mesma computação no SQL Server 2012 adiciona mais 4 bytes por linha para o uniquifier (que não está presente em índices únicos como mencionado anteriormente). Os bytes extras significam que menos linhas devem caber em cada página:
- Tamanho da linha calculada =61 + 4 =65 bytes .
- Tamanho dos dados calculados =65 bytes * 252 linhas =16.380 bytes
- Páginas de dados calculados =16.380 / 8192 =1,99951171875 .
Alterando o
TOP cláusula de 268 linhas a 269 (ou de 252 a 253 para 2012) torna o cálculo do tamanho de dados esperado apenas ultrapassar o limite mínimo de 2 páginas:- SQL Server 2014
- 61 bytes * 269 linhas =16.409 bytes.
- 16.409 / 8192 =2,0030517578125 páginas.
- SQL Server 2012
- 65 bytes * 253 linhas =16.445 bytes.
- 16.445 / 8192 =2,0074462890625 páginas.
Com a segunda condição agora também satisfeita,
DMLRequestSort está definido como true , e registro mínimo é alcançado, conforme mostrado na saída abaixo: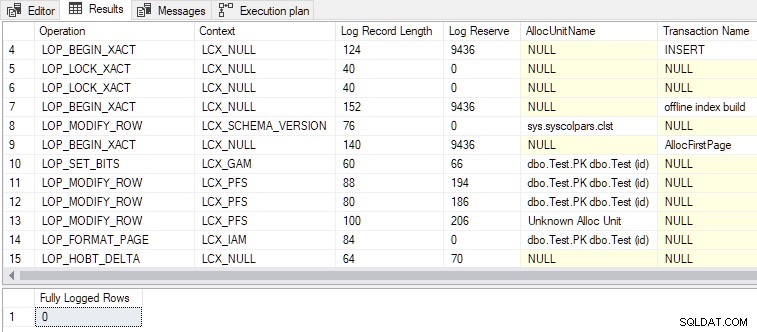
Alguns outros pontos de interesse:
- Um total de 79 registros de log são gerados, em comparação com 328 para a versão totalmente logada. Menos registros de log são o resultado esperado do log mínimo.
- O
LOP_BEGIN_XACTregistros no minimamente registrado registros reservam uma quantidade comparativamente grande de espaço de log (9436 bytes cada). - Um dos nomes de transação listados nos registros de log é “criação de índice offline” . Embora não tenhamos solicitado a criação de um índice como tal, o carregamento em massa de linhas em um índice vazio é essencialmente a mesma operação.
- O totalmente registrado insert recebe um bloqueio exclusivo ao nível da tabela (
Tab-X), enquanto o minimamente registrado insert aceita modificação de esquema (Sch-M) assim como uma compilação de índice offline "real". - Carregamento em massa de uma tabela clusterizada vazia usando
INSERT...SELECTcomTABLOCKeDMRequestSortdefinido como true usa oRowsetBulkmecanismo, assim como o minimamente registrado cargas de heap fizeram no artigo anterior.
Estimativas de cardinalidade
Fique atento às estimativas de baixa cardinalidade na Inserção de índice agrupado operador. Se um dos limites necessários para definir
DMLRequestSort para verdadeiro não for alcançado devido à estimativa imprecisa de cardinalidade, a inserção será totalmente registrada , independentemente do número real de linhas e do tamanho total dos dados encontrados no tempo de execução. Por exemplo, alterando o
TOP cláusula no script de demonstração para usar uma variável resulta em uma cardinalidade fixa suposição de 100 linhas, que está abaixo do mínimo de 251 linhas:-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Planejar o cache
O
DMLRequestSort A propriedade é salva como parte do plano armazenado em cache. Quando um plano armazenado em cache é reutilizado , o valor de DMLRequestSort é não recalculado em tempo de execução, a menos que ocorra uma recompilação. Observe que as recompilações não ocorrem para TRIVIAL planos baseados em mudanças nas estatísticas ou cardinalidade da tabela. Uma maneira de evitar comportamentos inesperados devido ao armazenamento em cache é usar uma
OPTION (RECOMPILE) dica. Isso garantirá a configuração apropriada para DMLRequestSort é recalculado, ao custo de uma compilação em cada execução. Sinalizador de rastreamento
É possível forçar
DMLRequestSort a ser definido como true definindo não documentado e não suportado sinalizador de rastreamento 2332, como escrevi em Otimizando consultas T-SQL que alteram dados. Infelizmente, isso não afetar o registro mínimo elegibilidade para tabelas em cluster vazias — a inserção ainda deve ser estimada em mais de 250 linhas e 2 páginas. Este sinalizador de rastreamento afeta outros registros mínimos cenários, que são abordados na parte final desta série. Resumo
Carregamento em massa de um vazio índice clusterizado usando
INSERT...SELECT reutiliza o RowsetBulk mecanismo usado para carregar tabelas de heap em massa. Isso requer bloqueio de tabela (normalmente obtido com um TABLOCK dica) e um ORDER dica. Não há como adicionar um ORDER dica para um INSERT...SELECT demonstração. Como consequência, alcançar registro mínimo em uma tabela em cluster vazia requer que o DMLRequestSort propriedade da Inserção de índice clusterizado operador está definido como true . Isso garantia ao SQL Server que as linhas apresentadas ao Inserir operador chegará na ordem de chave de índice de destino. O efeito é o mesmo ao usar o ORDER dica disponível para outros métodos de inserção em massa, como BULK INSERT e bcp . Para
DMLRequestSort a ser definido como true , deve haver:- Mais de 250 linhas estimado ser inserido; e
- Uma estimativa inserir tamanho de dados de mais de duas páginas .
A estimativa inserir cálculo de tamanho de dados não corresponder ao resultado da multiplicação do plano de execução número estimado de linhas e tamanho de linha estimado propriedades na entrada para Inserir operador. O cálculo interno (incorretamente) inclui uma ou mais colunas internas no fluxo de inserção, que não persistem no índice final. O cálculo interno também não leva em conta cabeçalhos de página ou outras despesas gerais, como controle de versão de linha.
Ao testar ou depurar o registro mínimo problemas, cuidado com estimativas de baixa cardinalidade e lembre-se de que a configuração de
DMLRequestSort é armazenado em cache como parte do plano de execução. A parte final desta série detalha as condições necessárias para alcançar o registro mínimo sem usar o
RowsetBulk mecanismo. Eles correspondem diretamente aos novos recursos adicionados no sinalizador de rastreamento 610 ao SQL Server 2008 e, em seguida, alterados para serem ativados por padrão do SQL Server 2016 em diante.