Esta postagem fornece novas informações sobre as pré-condições para carga em massa minimamente registrada ao usar
INSERT...SELECT em tabelas indexadas . O recurso interno que habilita esses casos é chamado de
FastLoadContext . Ele pode ser ativado do SQL Server 2008 a 2014 inclusive usando o sinalizador de rastreamento documentado 610. Do SQL Server 2016 em diante, FastLoadContext está habilitado por padrão; o sinalizador de rastreamento não é necessário. Sem
FastLoadContext , as únicas inserções de índice que podem ser minimamente registradas são aqueles em um vazio índice agrupado sem índices secundários, conforme abordado na segunda parte desta série. O registro mínimo as condições para tabelas de heap não indexadas foram abordadas na primeira parte. Para obter mais informações, consulte o Guia de carregamento de desempenho de dados e a Equipe Tiger notas sobre as alterações de comportamento do SQL Server 2016.
Contexto de carregamento rápido
Como um lembrete rápido, o
RowsetBulk instalação (abordada nas partes 1 e 2) permite registro mínimo carga a granel para:- Heap vazio e não vazio tabelas com:
- Bloqueio de mesa; e
- Nenhum índice secundário.
- Tabelas clusterizadas vazias , com:
- Bloqueio de mesa; e
- Sem índices secundários; e
DMLRequestSort=truena Inserção de índice agrupado operador.
O
FastLoadContext caminho de código adiciona suporte para minimamente registrado e concomitante carga a granel em:- Vazios e não vazios agrupados índices de b-tree.
- Vazios e não vazios não agrupados índices b-tree mantidos por um dedicado Inserção de índice operadora de plano.
O
FastLoadContext também requer DMLRequestSort=true no operador do plano correspondente em todos os casos. Você deve ter notado uma sobreposição entre
RowsetBulk e FastLoadContext para tabelas clusterizadas vazias sem índices secundários. Um TABLOCK dica é não obrigatória com FastLoadContext , mas não é necessário estar ausente ou. Como consequência, uma inserção adequada com TABLOCK ainda pode se qualificar para registro mínimo via FastLoadContext se falhar no RowsetBulk detalhado testes. FastLoadContext pode ser desativado no SQL Server 2016 usando o sinalizador de rastreamento documentado 692. O evento estendido do canal de depuração fastloadcontext_enabled pode ser usado para monitorar FastLoadContext uso por partição de índice (conjunto de linhas). Este evento não é acionado para RowsetBulk cargas. Registro misto
Um único
INSERT...SELECT declaração usando FastLoadContext pode registrar totalmente algumas linhas enquanto registro minimamente outros. As linhas são inseridas uma de cada vez pela Inserção de Índice operador e totalmente registrado nos seguintes casos:
- Todas as linhas adicionadas à primeira página de índice, se o índice estiver vazio no início da operação.
- Linhas adicionadas a existentes páginas de índice.
- Linhas movidas entre as páginas por uma divisão de página.
Caso contrário, as linhas do fluxo de inserção ordenado serão adicionadas a uma página totalmente nova usando um otimizado e minimamente registrado caminho do código. Assim que o maior número possível de linhas for gravado na nova página, ela será vinculada diretamente à estrutura de índice de destino existente.
A página recém-adicionada não necessariamente estar cheio (embora obviamente esse seja o caso ideal) porque o SQL Server precisa ter cuidado para não adicionar linhas à nova página que pertencem logicamente a um existente página de índice. A nova página será 'costurada' no índice como uma unidade, portanto não podemos ter nenhuma linha na nova página que pertença a outro lugar. Isso é principalmente um problema ao adicionar linhas dentro o intervalo de chaves de índice existente, em vez de antes do início ou após o término do intervalo de chaves de índice existente.
Ainda é possível para adicionar novas páginas dentro o intervalo de chaves de índice existente, mas as novas linhas devem ser classificadas acima da chave mais alta no anterior página de índice existente e ordenar abaixo da chave mais baixa no seguinte página de índice existente. Para ter a melhor chance de obter registro mínimo nessas circunstâncias, certifique-se de que as linhas inseridas não se sobreponham às linhas existentes o máximo possível.
Condições de DMLRequestSort
Lembre-se de que
FastLoadContext só pode ser ativado se DMLRequestSort está definido como true para a Inserção de Índice correspondente operador no plano de execução. Existem dois caminhos de código principais que podem definir
DMLRequestSort para verdadeiro para inserções de índice. Qualquer caminho retornando true é suficiente. 1. FOptimizeInserir
O
sqllang!CUpdUtil::FOptimizeInsert código requer:- Mais de 250 linhas estimado ser inserido; e
- Mais de 2 páginas estimado inserir tamanho dos dados; e
- O índice de destino deve ter menos de 3 páginas de folha .
Essas condições são as mesmas de
RowsetBulk em um índice clusterizado vazio, com um requisito adicional para não mais que duas páginas de nível de folha de índice. Observe cuidadosamente que isso se refere ao tamanho do índice existente antes da inserção, não o tamanho estimado dos dados a serem adicionados. O script abaixo é uma modificação da demonstração usada nas partes anteriores desta série. Ele mostra registro mínimo quando menos de três páginas de índice são preenchidas antes o teste
INSERT...SELECT corre. O esquema da tabela de teste é tal que 130 linhas podem caber em uma única página de 8 KB quando o controle de versão de linha está desativado para o banco de dados. O multiplicador no primeiro TOP cláusula pode ser alterada para determinar o número de páginas de índice existentes antes o teste INSERT...SELECT É executado:IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
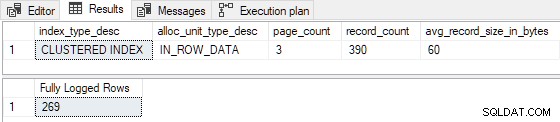
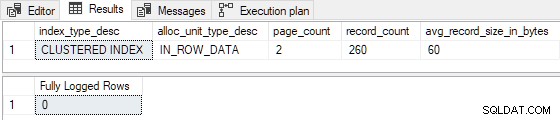
GO Quando o índice clusterizado é pré-carregado com 3 páginas , a inserção de teste é totalmente registrada (registros de detalhes do log de transações omitidos para brevidade):
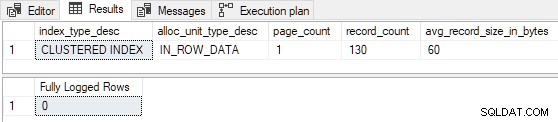
Quando a tabela é pré-carregada com apenas 1 ou 2 páginas , a inserção de teste é minimamente registrada :
Quando a tabela não está pré-carregada com qualquer página, o teste é equivalente a executar a demonstração de tabela em cluster vazia da parte dois, mas sem o
TABLOCK dica: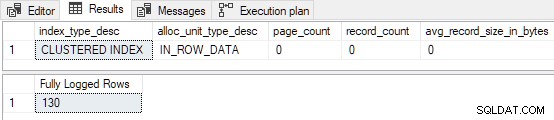
As primeiras 130 linhas são totalmente registradas . Isso ocorre porque o índice estava vazio antes de começarmos e 130 linhas cabem na primeira página. Lembre-se, a primeira página é sempre totalmente registrada quando
FastLoadContext é usado e o índice estava vazio anteriormente. As 139 linhas restantes são inseridas com registro mínimo . Se um
TABLOCK dica é adicionada à inserção, todas as páginas são registrados minimamente (incluindo o primeiro) já que o carregamento de índice clusterizado vazio agora se qualifica para o RowsetBulk mecanismo (ao custo de tomar um Sch-M trancar). 2. FDemandRowsSortedForPerformance
Se o
FOptimizeInsert os testes falham, DMLRequestSort ainda pode ser definido como true por um segundo conjunto de testes no sqllang!CUpdUtil::FDemandRowsSortedForPerformance código. Essas condições são um pouco mais complexas, por isso será útil definir alguns parâmetros:P– número de páginas em nível de folha existentes no índice de destino .I– estimado número de linhas a serem inseridas.R=P/I(páginas de destino por linha inserida).T– número de partições de destino (1 para não particionada).
A lógica para determinar o valor de
DMLRequestSort é então:- Se
P <= 16retornar falso , caso contrário :- Se
R < 8:- Se
P > 524retornar verdadeiro , caso contrário falso .
- Se
- Se
R >= 8:- Se
T > 1eI > 250retornar verdadeiro , caso contrário falso .
- Se
- Se
Os testes acima são avaliados pelo processador de consultas durante a compilação do plano. Há uma condição final avaliado pelo código do mecanismo de armazenamento (
IndexDataSetSession::WakeUpInternal ) em tempo de execução:DMLRequestSorté atualmente verdadeiro; eI >= 100.
Vamos quebrar toda essa lógica em partes gerenciáveis a seguir.
Mais de 16 páginas de destino existentes
O primeiro teste
P <= 16 significa que índices com menos de 17 páginas folha existentes não se qualificarão para FastLoadContext através deste caminho de código. Para ser absolutamente claro neste ponto, P é o número de páginas em nível de folha no índice de destino antes o INSERT...SELECT É executado. Para demonstrar essa parte da lógica, pré-carregaremos a tabela clusterizada de teste com 16 páginas De dados. Isso tem dois efeitos importantes (lembre-se que ambos os caminhos de código devem retornar false terminar com um falso valor para
DMLRequestSort ):- Assegura que o
FOptimizeInsertanterior teste falhou , porque a terceira condição não foi atendida (P < 3). - O
P <= 16condição emFDemandRowsSortedForPerformancetambém não ser atendido.
Portanto, esperamos
FastLoadContext não ser habilitado. O script de demonstração modificado é:IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Todas as 269 linhas são totalmente registradas como previsto:
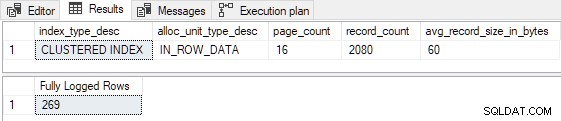
Observe que não importa o quão alto definirmos o número de novas linhas a serem inseridas, o script acima nunca produzir registro mínimo por causa do
P <= 16 teste (e P < 3 teste em FOptimizeInsert ). Se você optar por executar a demonstração por conta própria com um número maior de linhas, comente a seção que mostra os registros de log de transações individuais, caso contrário, você aguardará muito tempo e o SSMS poderá travar. (Para ser justo, ele pode fazer isso de qualquer maneira, mas por que aumentar o risco.)
Proporção de páginas por linha inserida
Se houver 17 ou mais páginas de folha no índice existente, o anterior
P <= 16 teste não falhará. A próxima seção de lógica lida com a proporção de páginas existentes para linhas recém-inseridas . Isso também deve passar para atingir o registro mínimo . Como lembrete, as condições relevantes são:- Proporção
R=P/I. - Se
R < 8:- Se
P > 524retornar verdadeiro , caso contrário falso .
- Se
Também devemos lembrar do teste final do mecanismo de armazenamento para pelo menos 100 linhas:
I >= 100.
Reorganizando um pouco essas condições, todas das seguintes devem ser verdadeiras:
P > 524(páginas de índice existentes)I >= 100(linhas inseridas estimadas)P / I < 8(proporçãoR)
Existem várias maneiras de atender a essas três condições simultaneamente. Vamos escolher os valores mínimos possíveis para
P (525) e I (100) dando um R valor de (525/100) =5,25. Isso satisfaz o (R < 8 test), então esperamos que essa combinação resulte em registro mínimo :IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; O
INSERT...SELECT de 100 linhas é realmente minimamente registrado :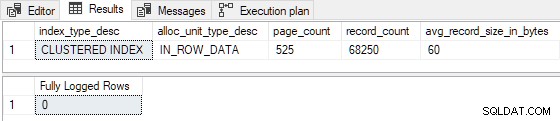
Reduzindo a estimativa linhas inseridas para 99 (quebrando
I >= 100 ) e/ou reduzindo o número de páginas de índice existentes para 524 (quebrando P > 524 ) resulta em registro completo . Também podemos fazer alterações para que R não é inferior a 8 para produzir registro completo . Por exemplo, configurando P = 1000 e I = 125 dá R = 8 , com os seguintes resultados: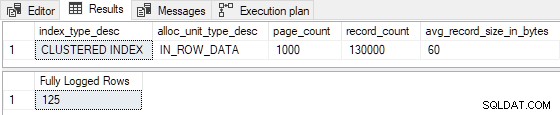
As 125 linhas inseridas foram totalmente registradas como esperado. (Isso não se deve ao registro completo da primeira página, pois o índice não estava vazio anteriormente.)
Proporção de páginas para índices particionados
Se todos os testes anteriores falharem, o teste restante exigirá
R >= 8 e pode somente ser satisfeito quando o número de partições (T ) é maior que 1 e há mais de 250 estimados linhas inseridas (I ). Lembrar:- Se
R >= 8:- Se
T > 1eI > 250retornar verdadeiro , caso contrário falso .
- Se
Uma sutileza:para particionado índices, a regra que diz que todas as linhas da primeira página são totalmente registradas (para um índice inicialmente vazio) se aplica por partição . Para um objeto com 15.000 partições, isso significa 15.000 'primeiras' páginas totalmente registradas.
Resumo e Considerações Finais
As fórmulas e a ordem de avaliação descritas no corpo são baseadas na inspeção de código usando um depurador. Eles foram apresentados em uma forma que representa de perto o tempo e a ordem usados no código real.
É possível reordenar e simplificar um pouco essas condições, para produzir um resumo mais conciso dos requisitos práticos para registro mínimo ao inserir em uma b-tree usando
INSERT...SELECT . As expressões refinadas abaixo usam os três parâmetros a seguir:P=número de existentes indexe páginas em nível de folha.I=estimado número de linhas a serem inseridas.S=estimado insira o tamanho dos dados em páginas de 8 KB.
Carregamento em massa do conjunto de linhas
- Usa
sqlmin!RowsetBulk. - Requer um vazio destino de índice clusterizado com
TABLOCK(ou equivalente). - Requer
DMLRequestSort = truena Inserção de índice agrupado operador. DMLRequestSortestá definido comotrueseI > 250eS > 2.- Todas as linhas inseridas são minimamente registradas .
- Um
Sch-Mlock impede o acesso simultâneo à tabela.
Contexto de carregamento rápido
- Usa
sqlmin!FastLoadContext. - Ativa registrado minimamente inserções em índices b-tree:
- Em cluster ou não em cluster.
- Com ou sem bloqueio de mesa.
- Índice de destino vazio ou não.
- Requer
DMLRequestSort = truena Inserção de Índice associada operadora de plano. - Somente linhas gravadas em páginas novas são carregados em massa e minimamente registrados .
- A primeira página de um índice vazio anteriormente partição é sempre totalmente registrada .
- Mínimo absoluto de
I >= 100. - Requer o sinalizador de rastreamento 610 antes do SQL Server 2016.
- Disponível por padrão no SQL Server 2016 (o sinalizador de rastreamento 692 desativa).
DMLRequestSort está definido como true por:- Qualquer índice (particionado ou não) se:
I > 250eP < 3eS > 2; ouI >= 100eP > 524eP < I * 8
Para índices particionados apenas (com> 1 partição),
DMLRequestSort também é definido como true E se:I > 250eP > 16eP >= I * 8
Existem alguns casos interessantes decorrentes desses
FastLoadContext condições:- Todos inserções para um não particionado índice com entre 3 e 524 (inclusive) as páginas folha existentes serão totalmente registradas independentemente do número e tamanho total das linhas adicionadas. Isso afetará mais notavelmente as inserções grandes em tabelas pequenas (mas não vazias).
- Todos inserções para um particionado índice entre 3 e 16 as páginas existentes serão totalmente registradas .
- Inserções grandes para grande não particionado índices podem não ser minimamente registrados devido à desigualdade
P < I * 8. QuandoPé grande, uma estimativa correspondentemente grande número de linhas inseridas (I) É necessário. Por exemplo, um índice com 8 milhões de páginas não suporta registro mínimo ao inserir 1 milhão de linhas ou menos.
Índices não clusterizados
As mesmas considerações e cálculos aplicados a índices clusterizados nas demonstrações se aplicam a não clusterizados índices b-tree também, desde que o índice seja mantido por um operador de plano dedicado (uma largura , ou por índice plano). Índices não clusterizados mantidos por um operador de tabela base (por exemplo, Inserção de índice clusterizado ) não são qualificados para
FastLoadContext . Observe que os parâmetros da fórmula precisam ser avaliados novamente para cada não clusterizado operador de índice — tamanho de linha calculado, número de páginas de índice existentes e estimativa de cardinalidade.
Observações gerais
Fique atento às estimativas de baixa cardinalidade na Inserção de índice operador, pois isso afetará o
I e S parâmetros. Se um limite não for atingido devido a um erro de estimativa de cardinalidade, a inserção será totalmente registrada . Lembre-se de que
DMLRequestSort é armazenado em cache com o plano — não é avaliado a cada execução de um plano reutilizado. Isso pode introduzir uma forma do conhecido Problema de Sensibilidade de Parâmetro (também conhecido como “sniffing de parâmetro”). O valor de
P (páginas de folha de índice) não é atualizada no início de cada declaração. A implementação atual armazena em cache o valor de todo o lote . Isso pode ter efeitos colaterais inesperados. Por exemplo, um TRUNCATE TABLE no mesmo lote como INSERT...SELECT não irá redefinir P para zero para os cálculos descritos neste artigo — eles continuarão a usar o valor pré-truncado e uma recompilação não ajudará. Uma solução alternativa é enviar grandes alterações em lotes separados. Sinalizadores de rastreamento
É possível forçar
FDemandRowsSortedForPerformance para retornar true definindo não documentado e não suportado sinalizador de rastreamento 2332, como escrevi em Otimizando consultas T-SQL que alteram dados. Quando o TF 2332 está ativo, o número de linhas estimadas a serem inseridas ainda precisa ser pelo menos 100 . O TF 2332 afeta o registro mínimo decisão para FastLoadContext somente (é eficaz para heaps particionados até DMLRequestSort está preocupado, mas não tem efeito no heap em si, pois FastLoadContext só se aplica a índices). Uma ampla/por índice A forma do plano para manutenção de índice não clusterizado pode ser forçada para tabelas rowstore usando o sinalizador de rastreamento 8790 (não documentado oficialmente, mas mencionado em um artigo da Base de Conhecimento, bem como em meu artigo vinculado ao TF2332 logo acima).
Leitura Relacionada
Tudo por Sunil Agarwal da equipe do SQL Server:
- O que são as otimizações de importação em massa?
- Otimizações de importação em massa (registro mínimo)
- Mudanças mínimas de log no SQL Server 2008
- Mudanças mínimas de log no SQL Server 2008 (parte 2)
- Mudanças mínimas de log no SQL Server 2008 (parte 3)