Digamos que você queira encontrar todos os pacientes que nunca tomaram uma vacina contra a gripe. Ou, em
AdventureWorks2012 , uma pergunta semelhante pode ser "mostre-me todos os clientes que nunca fizeram um pedido". Expresso usando NOT IN , um padrão que vejo com muita frequência, que seria algo assim (estou usando o cabeçalho ampliado e as tabelas de detalhes deste script de Jonathan Kehayias (@SQLPoolBoy)):SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Quando vejo esse padrão, eu me encolho. Mas não por motivos de desempenho – afinal, ele cria um plano decente o suficiente neste caso:
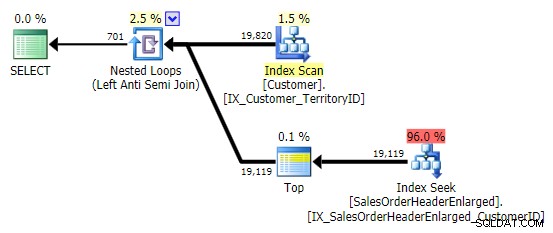
O principal problema é que os resultados podem ser surpreendentes se a coluna de destino for NULLable (o SQL Server processa isso como um anti-semi join esquerdo, mas não pode dizer com segurança se um NULL no lado direito é igual a - ou não igual a – a referência do lado esquerdo). Além disso, a otimização pode se comportar de maneira diferente se a coluna for NULLable, mesmo que ela não contenha nenhum valor NULL (Gail Shaw falou sobre isso em 2010).
Nesse caso, a coluna de destino não é anulável, mas eu queria mencionar esses possíveis problemas com
NOT IN – Posso investigar essas questões mais detalhadamente em um post futuro. TL;versão DR
Em vez de
NOT IN , use um NOT EXISTS correlacionado para este padrão de consulta. Sempre. Outros métodos podem rivalizar em termos de desempenho, quando todas as outras variáveis são as mesmas, mas todos os outros métodos introduzem problemas de desempenho ou outros desafios. Alternativas
Então, de que outras maneiras podemos escrever essa consulta?
APLICAÇÃO EXTERNA
Uma maneira de expressar esse resultado é usando um
OUTER APPLY correlacionado . SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logicamente, este também é um anti-semi join esquerdo, mas o plano resultante não possui o operador anti-semi join esquerdo e parece ser um pouco mais caro do que o
NOT IN equivalente. Isso ocorre porque ele não é mais um anti-semi join à esquerda; na verdade, é processado de uma maneira diferente:uma junção externa traz todas as linhas correspondentes e não correspondentes e *depois* um filtro é aplicado para eliminar as correspondências: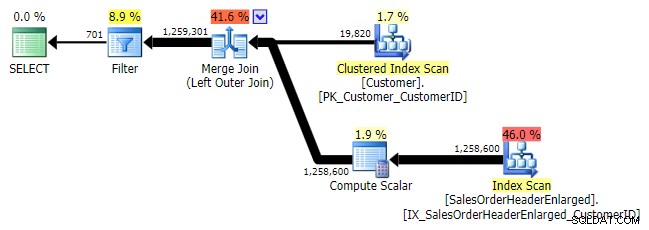
LEFT OUTER JOIN
Uma alternativa mais típica é
LEFT OUTER JOIN onde o lado direito é NULL . Nesse caso a consulta seria:SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Isso retorna os mesmos resultados; no entanto, como OUTER APPLY, ele usa a mesma técnica de juntar todas as linhas e só então eliminar as correspondências:
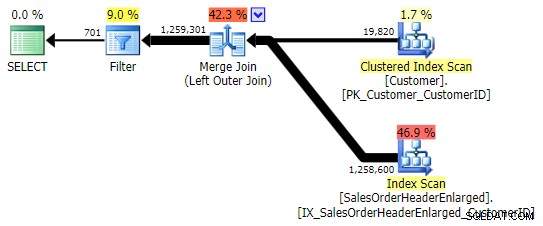
Você precisa ter cuidado, porém, sobre qual coluna você verifica para
NULL . Neste caso CustomerID é a escolha lógica porque é a coluna de junção; também acontece de ser indexado. Eu poderia ter escolhido SalesOrderID , que é a chave de clustering, portanto, também está no índice em CustomerID . Mas eu poderia ter escolhido outra coluna que não está (ou que mais tarde é removida) do índice usado para a junção, levando a um plano diferente. Ou mesmo uma coluna NULLable, levando a resultados incorretos (ou pelo menos inesperados), pois não há como diferenciar entre uma linha que não existe e uma linha que existe, mas onde essa coluna é NULL . E pode não ser óbvio para o leitor/desenvolvedor/solucionador de problemas que este é o caso. Então, também testarei esses três WHERE cláusulas:WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
A primeira variação produz o mesmo plano acima. Os outros dois escolhem uma junção de hash em vez de uma junção de mesclagem e um índice mais restrito no
Customer tabela, mesmo que a consulta acabe lendo exatamente o mesmo número de páginas e quantidade de dados. No entanto, enquanto o h.SubTotal variação produz os resultados corretos: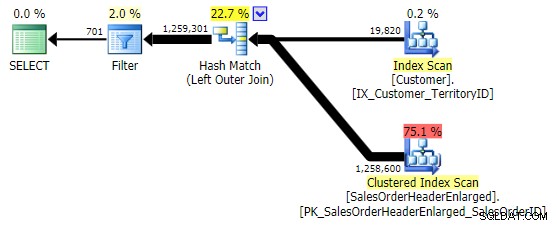
O
h.Comment variação não, pois inclui todas as linhas onde h.Comment IS NULL , bem como todas as linhas que não existiam para nenhum cliente. Destaquei a sutil diferença no número de linhas na saída após a aplicação do filtro: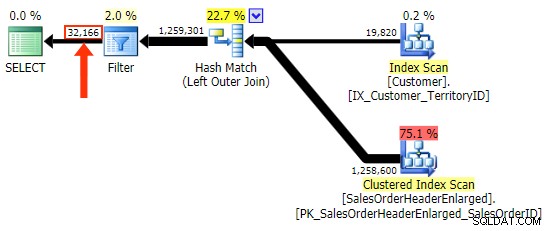
Além de precisar ter cuidado com a seleção de colunas no filtro, o outro problema que tenho com o
LEFT OUTER JOIN form é que não é auto-documentado, da mesma forma que uma junção interna na forma "antiga" de FROM dbo.table_a, dbo.table_b WHERE ... não é auto-documentado. Com isso quero dizer que é fácil esquecer os critérios de junção quando é enviado para o WHERE cláusula, ou para que se misture com outros critérios de filtro. Sei que isso é bastante subjetivo, mas aí está. EXCETO
Se tudo o que nos interessa é a coluna de junção (que por definição está em ambas as tabelas), podemos usar
EXCEPT – uma alternativa que parece não aparecer muito nessas conversas (provavelmente porque – geralmente – você precisa estender a consulta para incluir colunas que você não está comparando):SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Isso vem com exatamente o mesmo plano que o
NOT IN variação acima: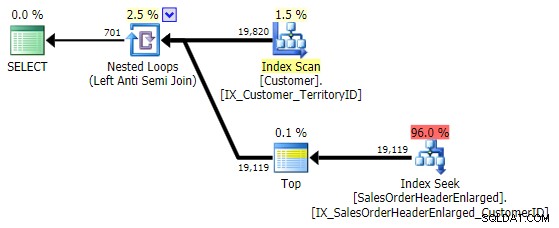
Uma coisa a ter em mente é que
EXCEPT inclui um DISTINCT implícito – portanto, se você tiver casos em que deseja que várias linhas tenham o mesmo valor na tabela "esquerda", este formulário eliminará essas duplicatas. Não é um problema neste caso específico, apenas algo para se ter em mente – assim como UNION versus UNION ALL . NÃO EXISTE
Minha preferência por este padrão é definitivamente
NOT EXISTS :SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
); (E sim, eu uso
SELECT 1 em vez de SELECT * … não por motivos de desempenho, pois o SQL Server não se importa com quais colunas você usa dentro de EXISTS e os otimiza, mas simplesmente para esclarecer a intenção:isso me lembra que essa "subconsulta" não retorna nenhum dado.) Seu desempenho é semelhante ao
NOT IN e EXCEPT , e produz um plano idêntico, mas não é propenso a possíveis problemas causados por NULLs ou duplicatas: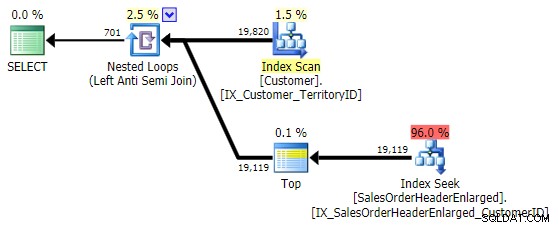
Testes de desempenho
Fiz vários testes, com cache frio e quente, para validar minha percepção de longa data sobre
NOT EXISTS sendo a escolha certa permaneceu verdadeiro. A saída típica ficou assim: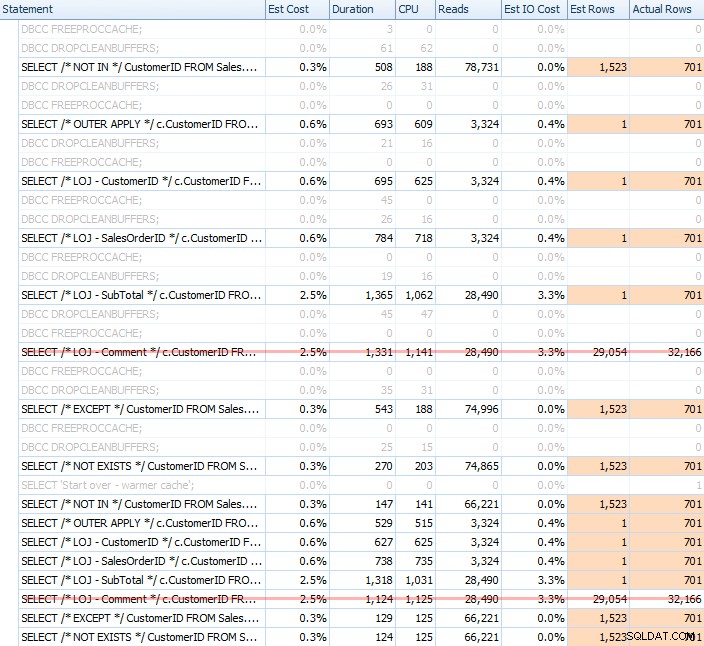
Tirarei o resultado incorreto da mistura ao mostrar o desempenho médio de 20 execuções em um gráfico (só o incluí para demonstrar o quão errados são os resultados) e executei as consultas em ordem diferente nos testes para garantir que uma consulta não estava se beneficiando consistentemente do trabalho de uma consulta anterior. Com foco na duração, aqui estão os resultados:
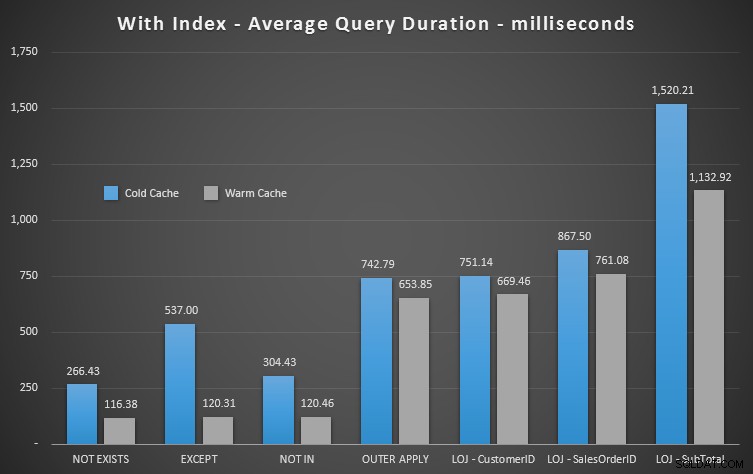
Se olharmos para a duração e ignorarmos as leituras, NOT EXISTS é o seu vencedor, mas não muito. EXCEPT e NOT IN não ficam muito atrás, mas, novamente, você precisa analisar mais do que o desempenho para determinar se essas opções são válidas e testar em seu cenário.
E se não houver índice compatível?
As consultas acima se beneficiam, é claro, do índice em
Sales.SalesOrderHeaderEnlarged.CustomerID . Como esses resultados mudam se abandonarmos esse índice? Executei o mesmo conjunto de testes novamente, depois de descartar o índice:DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Desta vez houve muito menos desvio em termos de desempenho entre os diferentes métodos. Primeiro, mostrarei os planos para cada método (a maioria dos quais, não surpreendentemente, indica a utilidade do índice ausente que acabamos de descartar). Em seguida, mostrarei um novo gráfico representando o perfil de desempenho tanto com um cache frio quanto com um cache quente.
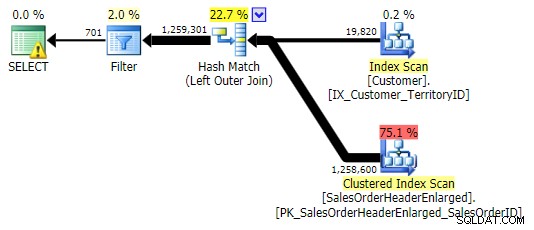
NOT IN, EXCEPT, NOT EXISTS (todos os três eram idênticos)
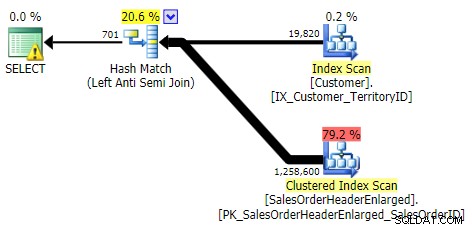
APLICAÇÃO EXTERNA
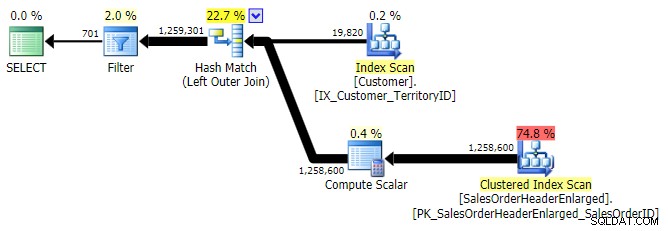
LEFT OUTER JOIN (todos os três eram idênticos, exceto pelo número de linhas)
Resultados de desempenho
Podemos ver imediatamente o quão útil é o índice quando analisamos esses novos resultados. Em todos os casos, exceto em um (a junção externa esquerda que sai do índice de qualquer maneira), os resultados são claramente piores quando descartamos o índice:
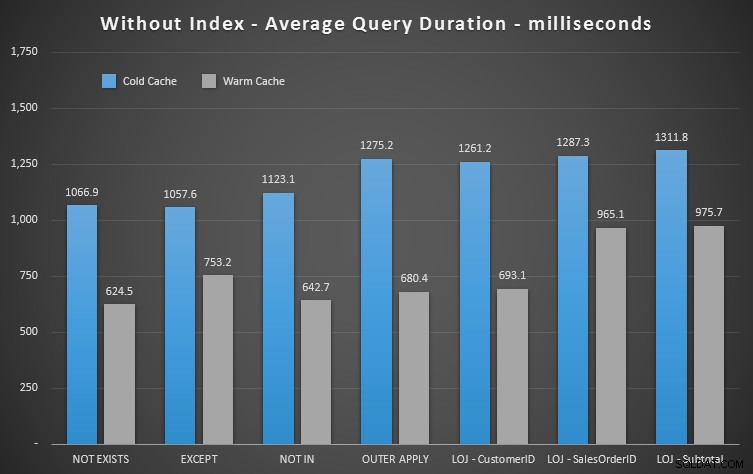
Assim, podemos ver que, embora haja um impacto menos perceptível,
NOT EXISTS ainda é o seu vencedor marginal em termos de duração. E em situações em que as outras abordagens são suscetíveis à volatilidade do esquema, também é sua escolha mais segura. Conclusão
Esta foi apenas uma maneira muito prolixa de dizer a você que, para o padrão de encontrar todas as linhas na tabela A onde alguma condição não existe na tabela B,
NOT EXISTS normalmente vai ser sua melhor escolha. Mas, como sempre, você precisa testar esses padrões em seu próprio ambiente, usando seu esquema, dados e hardware e misturados com suas próprias cargas de trabalho.