Você já entrou em contato com a Microsoft ou um parceiro da Microsoft e discutiu com eles quanto custaria migrar para a nuvem? Em caso afirmativo, você pode ter ouvido falar sobre a calculadora de DTU do Banco de Dados SQL do Azure e também pode ter lido sobre como ela foi submetida a engenharia reversa por Andy Mallon. A calculadora DTU é uma ferramenta gratuita que você pode usar para carregar métricas de desempenho de seu servidor e usar os dados para determinar a camada de serviço apropriada se você migrar esse servidor para um Banco de Dados SQL do Azure (ou para um pool elástico do Banco de Dados SQL).
Para fazer isso, você deve agendar ou executar manualmente um script (linha de comando ou Powershell, disponível para download no site da calculadora de DTU) durante um período de uma carga de trabalho de produção típica.
Se você está tentando analisar um ambiente grande ou deseja analisar dados de pontos específicos no tempo, isso pode se tornar uma tarefa árdua. Em muitos casos, muitos DBAs têm algum tipo de ferramenta de monitoramento que já está capturando dados de desempenho para eles. Em muitos casos, provavelmente já está capturando as métricas necessárias ou pode ser facilmente configurado para capturar os dados necessários. Hoje, veremos como tirar proveito do SentryOne para que possamos fornecer os dados apropriados para a calculadora DTU.
Para começar, vejamos as informações obtidas pelo utilitário de linha de comando e pelo script do PowerShell disponíveis no site da calculadora DTU; existem 4 contadores de monitor de desempenho que ele captura:
- Processador – % de tempo do processador
- Disco Lógico – Leituras de Disco/s
- Disco Lógico – Gravações de Disco/s
- Banco de dados – Bytes de log liberados/s
A primeira etapa é determinar se essas métricas já foram capturadas como parte da coleta de dados no SQL Sentry. Para descobrir, sugiro ler esta postagem no blog de Jason Hall, onde ele fala sobre como os dados são dispostos e como você pode consultá-los. Eu não vou passar por cada passo disso aqui, mas encorajo você a ler e marcar toda a série de blogs.
Quando examinei o banco de dados do SentryOne, descobri que 3 dos 4 contadores já estavam sendo capturados por padrão. O único que estava faltando era
[Database – Log Bytes Flushed/sec] , então eu precisava ser capaz de ativar isso. Houve outra postagem no blog de Justin Randall que explica como fazer isso. Resumindo, você pode consultar o
[PerformanceAnalysisCounter] tabela. SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Você notará que, por padrão, o
[PerformanceAnalysisSampleIntervalID] está definido como 0 – isso significa que está desabilitado. Você precisará executar o seguinte comando para habilitar isso. Basta puxar o ID da consulta SELECT que você acabou de executar e usá-lo nesta UPDATE:UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Após executar a atualização, você precisará reiniciar o(s) serviço(s) de monitoramento SentryOne relevantes para este destino, para que os novos dados do contador possam ser coletados.
Observe que defino o
[PerformanceAnalysisSampleIntervalID] para 1 para que os dados sejam capturados a cada 10 segundos, no entanto, você pode capturar esses dados com menos frequência para minimizar o tamanho dos dados coletados ao custo de menor precisão. Consulte o [PerformanceAnalysisSampleInterval] tabela para obter uma lista de valores que você pode usar. Não espere que os dados comecem a fluir para as tabelas imediatamente; isso levará tempo para percorrer o sistema. Você pode verificar a população com a seguinte consulta:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Depois de confirmar que os dados estão aparecendo, você deve ter dados para cada uma das métricas exigidas pela calculadora de DTU, embora talvez queira esperar para extraí-los até ter uma amostra representativa de uma carga de trabalho completa ou ciclo de negócios.
Se você ler a postagem do blog de Jason, verá que os dados são armazenados em várias tabelas de rollup e que cada uma dessas tabelas de rollup tem taxas de retenção variadas. Muitos deles estão abaixo do que eu gostaria se estivesse analisando cargas de trabalho durante um período de tempo. Embora possa ser possível alterá-los, pode não ser o mais sábio. Como o que estou mostrando não tem suporte, convém evitar mexer muito nas configurações do SentryOne, pois isso pode ter um impacto negativo no desempenho, no crescimento ou em ambos.
Para compensar isso, criei um script que me permite extrair os dados de que preciso para as várias tabelas de rollup e armazenar esses dados em seu próprio local, para que eu possa controlar minha própria retenção e não interferir na funcionalidade do SentryOne.
TABELA:dbo.AzureDatabaseDTUData
Criei uma tabela chamada
[AzureDatabaseDTUData] e armazenou-o no banco de dados SentryOne. O procedimento que criei irá gerar automaticamente esta tabela caso ela não exista, então não há necessidade de fazer isso manualmente a menos que você queira customizar onde ela está armazenada. Você pode armazenar isso em um banco de dados separado, se desejar, basta editar o script para fazer isso. A tabela fica assim:CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procedimento:dbo.Custom_CollectDTUDataForDevice
Este é o procedimento armazenado que você pode usar para extrair todos os dados específicos da DTU de uma só vez (desde que tenha coletado o contador de log bytes por um período de tempo suficiente) ou agendá-lo para adicionar periodicamente os dados coletados até você está pronto para enviar a saída para a calculadora DTU. Como na tabela acima, o procedimento é criado no banco de dados SentryOne, mas você pode criá-lo facilmente em outro lugar, basta adicionar nomes de três ou quatro partes às referências de objeto. A interface para o procedimento é a seguinte:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Observação :Todo o procedimento é um pouco longo, então está anexado a este post (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Existem alguns parâmetros que você pode usar. Cada um tem um valor padrão, portanto, você não precisa especificá-los se estiver de acordo com os valores padrão.
- @DeviceID – Isso permite que você especifique se deseja coletar dados para um SQL Server específico ou tudo. O padrão é -1, o que significa copiar todos os SQL Servers monitorados. Se você deseja exportar apenas informações para uma instância específica, localize o
DeviceIDcorrespondente ao host no[dbo].[Device]tabela e passe esse valor. Você só pode passar um@DeviceIDpor vez, portanto, se você quiser passar por um conjunto de servidores, poderá chamar o procedimento várias vezes ou modificá-lo para oferecer suporte a um conjunto de dispositivos. - @DaysToPurge – Isso representa a idade em que você deseja remover os dados. O padrão é 14 dias, o que significa que você só extrairá dados de até 14 dias, e quaisquer dados com mais de 14 dias em sua tabela personalizada serão excluídos.
Os outros quatro parâmetros estão lá para proteção futura, caso as enumerações do SentryOne para IDs de contador sejam alteradas.
Algumas notas sobre o roteiro:
- Quando os dados são extraídos, ele pega o valor máximo do minuto truncado e o exporta. Isso significa que há um valor por métrica por minuto, mas é o valor máximo capturado. Isso é importante devido à forma como os dados precisam ser apresentados à calculadora DTU.
- A primeira vez que você executar a exportação, pode demorar um pouco mais. Isso ocorre porque ele extrai todos os dados possíveis com base em seus valores de parâmetro. A cada execução adicional, os únicos dados extraídos são os novos desde a última execução, portanto, deve ser muito mais rápido.
- Você precisará agendar este procedimento para ser executado em um cronograma que fique à frente do processo de limpeza do SentryOne. O que eu fiz foi apenas criar um SQL Agent Job para ser executado todas as noites que coleta todos os novos dados desde a noite anterior.
- Como o processo de limpeza no SentryOne pode variar de acordo com a métrica, você pode acabar com linhas em sua cópia que não contêm todos os 4 contadores por um período de tempo. Você pode querer começar a analisar seus dados apenas a partir do momento em que iniciar o processo de extração.
- Usei um bloco de código de procedimentos SentryOne existentes para determinar a tabela de rollup para cada contador. Eu poderia ter codificado os nomes atuais das tabelas, no entanto, usando o método SentryOne, ele deve ser compatível com qualquer alteração nos processos de rollup internos.
Depois que seus dados estiverem sendo movidos para uma tabela independente, você poderá usar uma consulta PIVOT para transformá-los no formato que a calculadora DTU espera.
Procedimento:dbo.Custom_ExportDataForDTUcalculator
Criei outro procedimento para extrair os dados no formato CSV. O código para este procedimento também está anexado (dbo.Custom_ExportDataForDTUcalculator.sql_.zip).
Existem três parâmetros:
- @DeviceID – Smallint correspondente a um dos dispositivos que você está coletando e que deseja enviar para a calculadora.
- @BeginTime – Datetime representando a hora de início, em hora local; por exemplo,
'2018-12-04 05:47:00.000'. O procedimento será traduzido para UTC. Se omitido, ele será coletado do valor mais antigo na tabela. - @EndTime – Datetime representando o horário de término, novamente em horário local; por exemplo,
'2018-12-06 12:54:00.000'. Se omitido, ele coletará até o valor mais recente da tabela.
Um exemplo de execução, para obter todos os dados coletados para
SQLInstanceA entre 4 de dezembro às 5h47 e 6 de dezembro às 12h54. EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Os dados precisarão ser exportados para um arquivo CSV. Não se preocupe com os dados em si; Certifiquei-me de produzir resultados para que não haja informações de identificação sobre seu servidor no arquivo csv, apenas datas e métricas.
Se você executar a consulta no SSMS, poderá clicar com o botão direito do mouse e exportar os resultados; no entanto, você tem opções limitadas aqui e terá que manipular a saída para obter o formato esperado pela calculadora DTU. (Sinta-se à vontade para tentar e me avise se você encontrar uma maneira de fazer isso.)
Eu recomendo apenas usar o assistente de exportação integrado ao SSMS. Clique com o botão direito do mouse no banco de dados e vá para Tarefas -> Exportar dados. Para sua fonte de dados, use “SQL Server Native Client” e aponte-o para seu banco de dados SentryOne (ou onde quer que você tenha sua cópia dos dados armazenados). Para o seu destino, você desejará selecionar “Flat File Destination”. Navegue até um local, dê um nome ao arquivo e salve o arquivo como CSV.
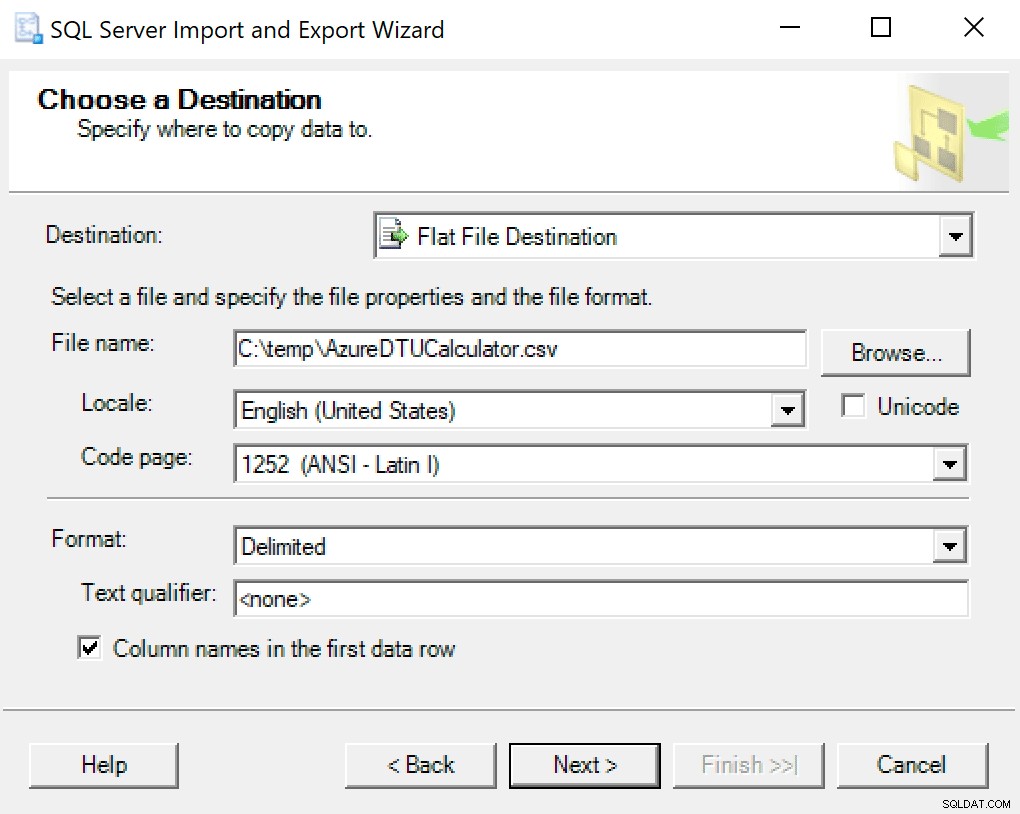
Tome cuidado para deixar a página de código em paz; alguns podem retornar erros. Eu sei que 1252 funciona bem. Os demais valores ficam como padrão.
Na próxima tela, selecione a opção Escreva uma consulta para especificar os dados a serem transferidos .
Na próxima janela, copie a chamada de procedimento com seus parâmetros definidos nela. Acerte em seguida.
Quando você chega em Configurar Destino de Arquivo Simples, deixo as opções como padrão. Aqui está uma captura de tela caso a sua seja diferente:
Acerte em seguida e corra imediatamente. Será criado um arquivo que você usará na última etapa.
OBSERVAÇÃO :você pode criar um pacote SSIS para usar para isso e, em seguida, passar seus valores de parâmetro para o pacote SSIS se for fazer muito isso. Isso evitaria que você tivesse que passar pelo assistente todas as vezes.
Navegue até o local onde você salvou o arquivo e verifique se ele está lá. Ao abri-lo, deve ser algo assim:
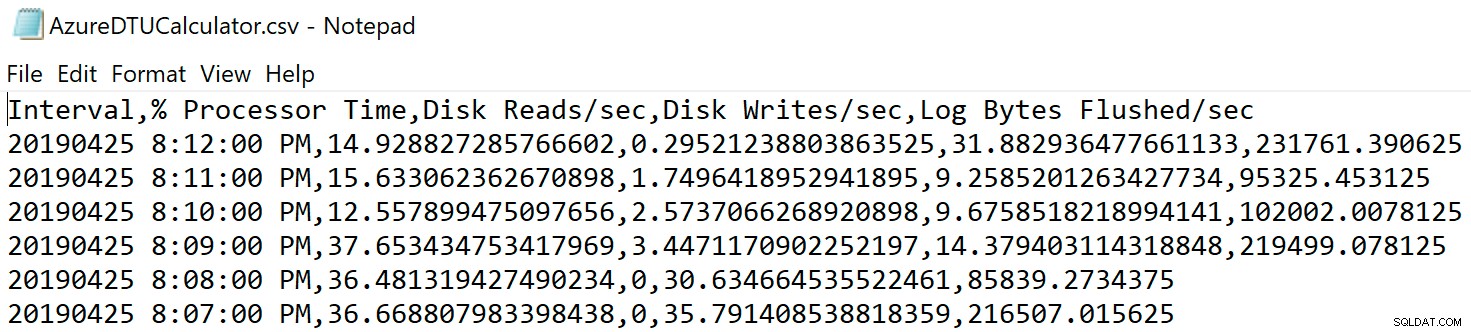
Abra o site da calculadora DTU e role para baixo até a parte que diz "Faça upload do arquivo CSV e calcule". Insira o número de Núcleos que o servidor possui, carregue o arquivo CSV e clique em Calcular. Você obterá um conjunto de resultados como este (clique em qualquer imagem para ampliar):
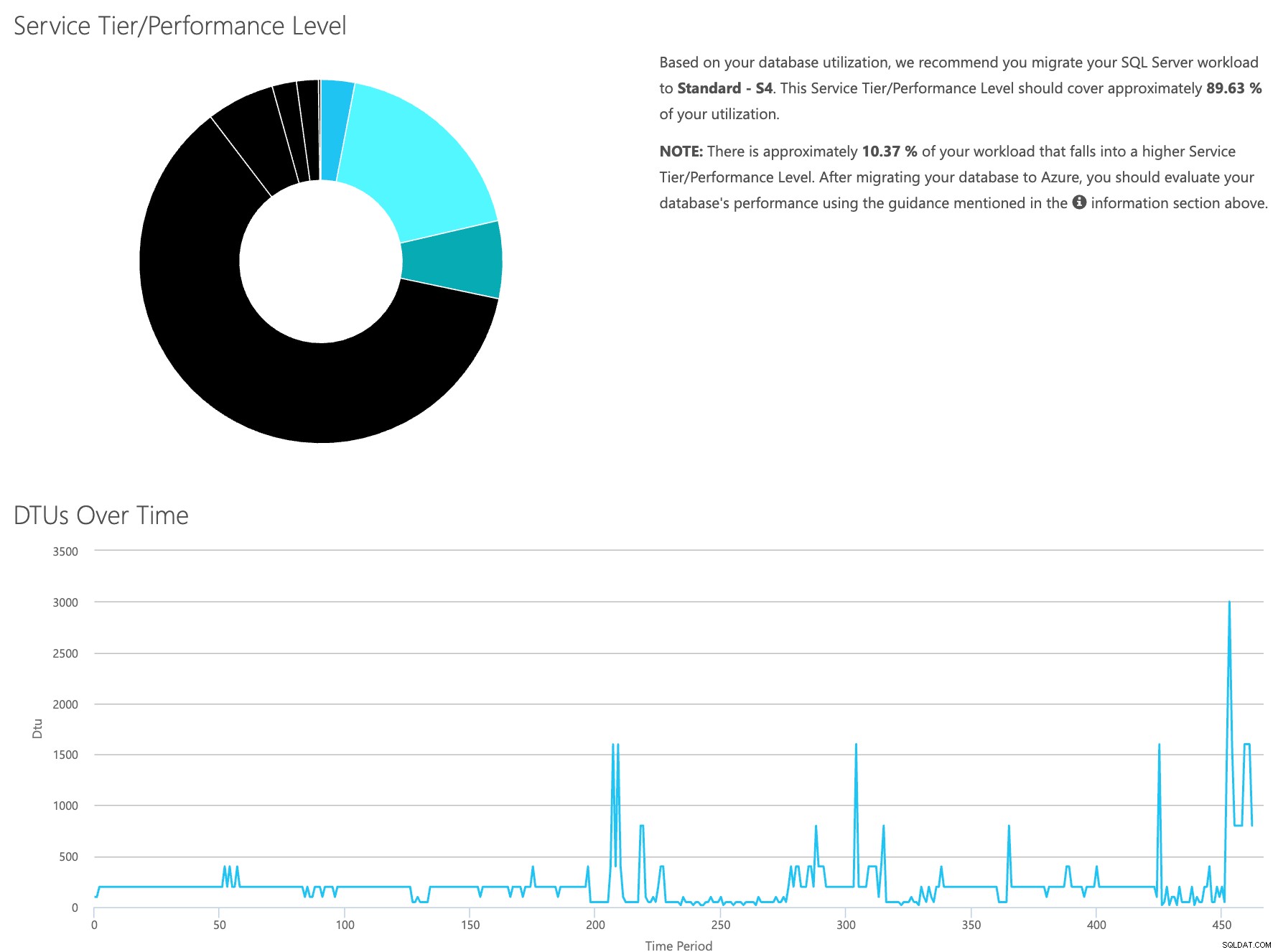
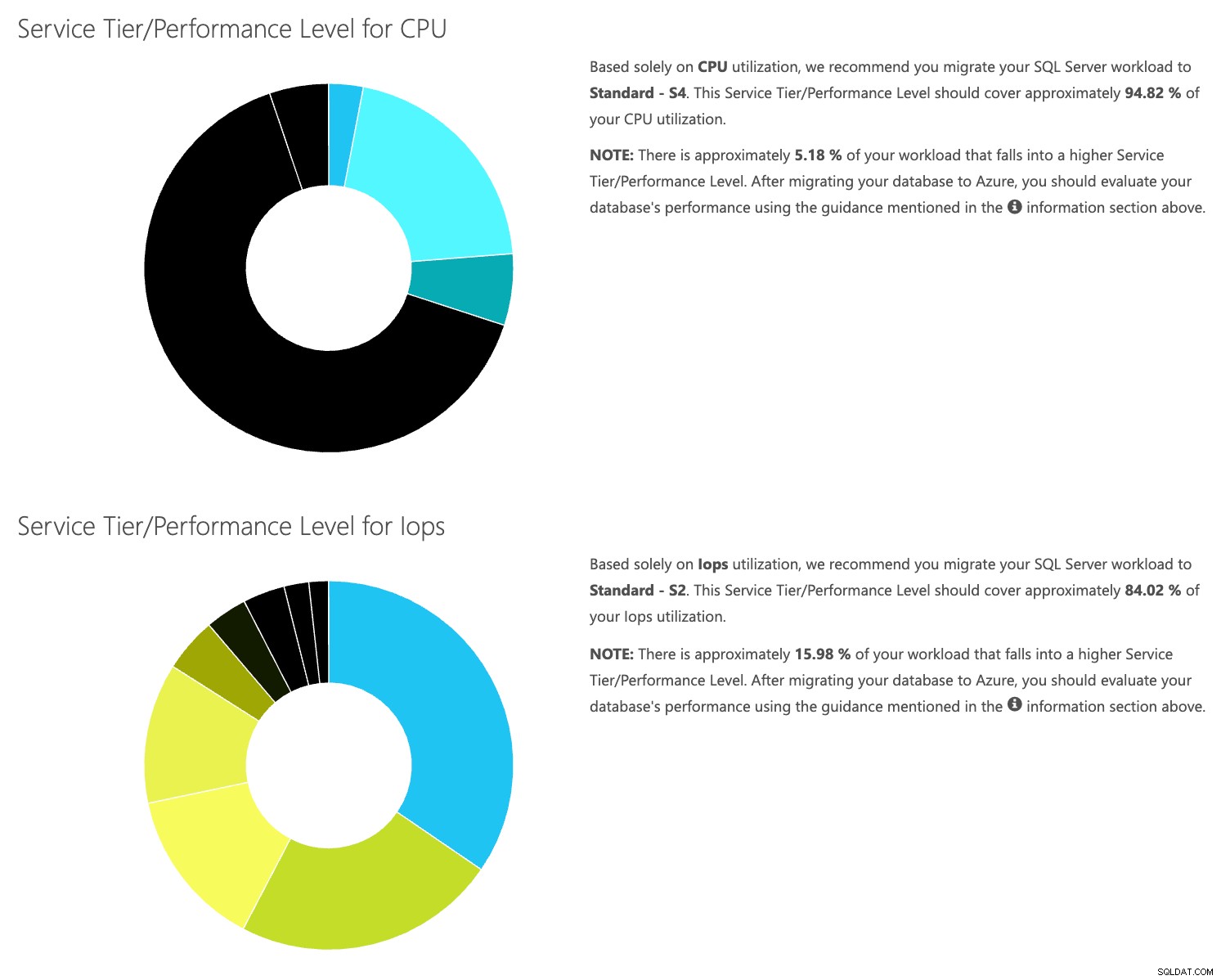
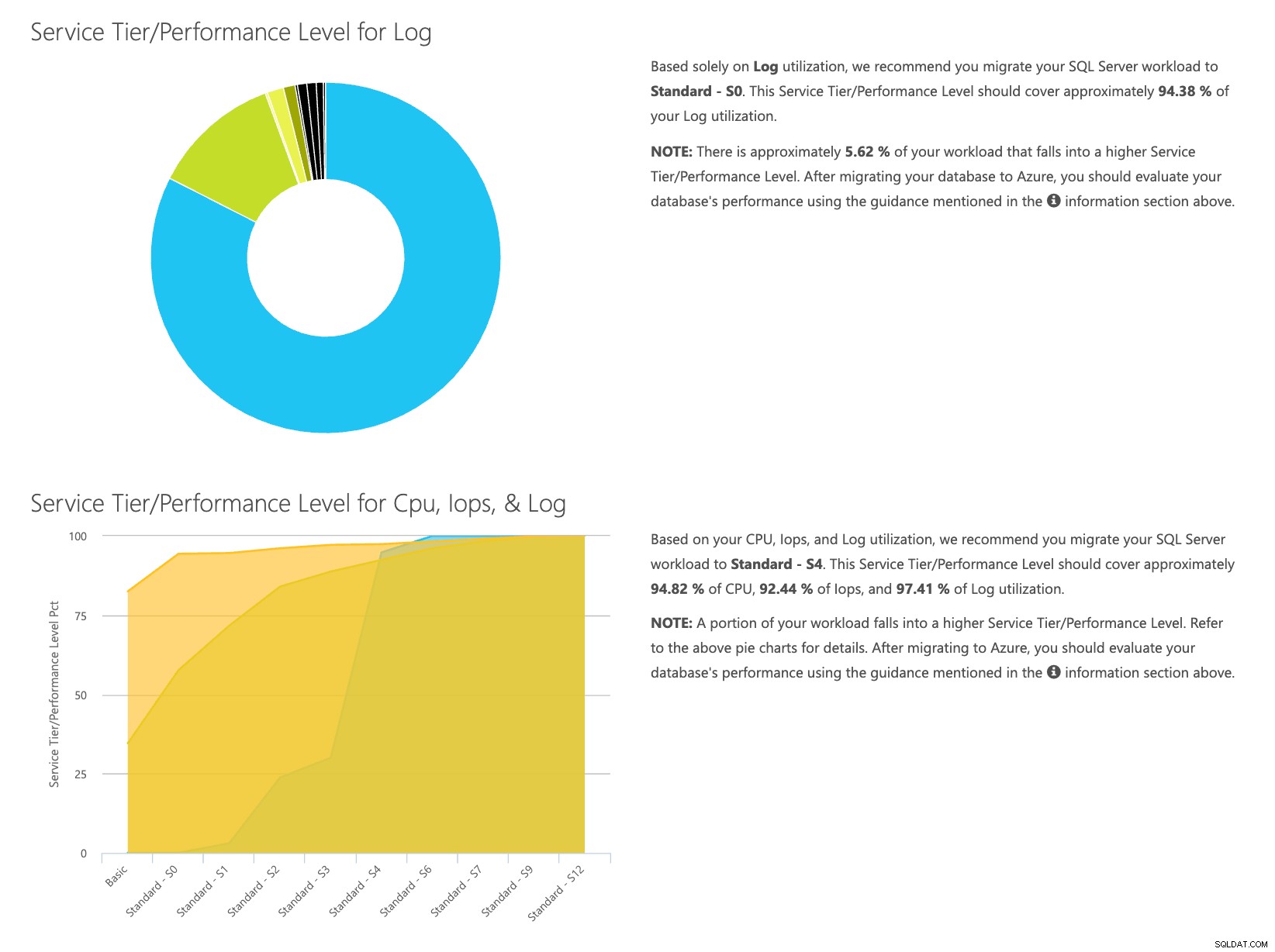
Como você tem os dados armazenados separadamente, você pode analisar cargas de trabalho de tempos variados e pode fazer isso sem precisar executar\agendar manualmente o utilitário de comando\script do powershell para qualquer servidor que já esteja usando o SentryOne para monitorar.
Para recapitular brevemente as etapas, veja o que precisa ser feito:
- Ative o contador [Banco de dados – Log Bytes liberados/s] e verifique se os dados estão sendo coletados
- Copie os dados das tabelas do SentryOne em sua própria tabela (e programe-os quando apropriado).
- Exporte os dados da nova tabela no formato correto para a calculadora DTU
- Faça upload do CSV para a Calculadora de DTU
Para qualquer servidor/instância que você esteja pensando em migrar para a nuvem e que esteja monitorando no momento com o SQL Sentry, essa é uma maneira relativamente simples de estimar que tipo de camada de serviço você precisará e quanto isso custará. Você ainda precisará monitorá-lo quando estiver lá em cima; para isso, confira SentryOne DB Sentry.
Sobre o autor
 Dustin Dorsey é atualmente o Managing Database Engineer da LifePoint Health, na qual lidera uma equipe responsável pelo gerenciamento e engenharia de soluções em tecnologias de banco de dados para 90 hospitais. Ele vem trabalhando e dando suporte ao SQL Server predominantemente na área de saúde desde 2008 em administração, arquitetura, desenvolvimento e capacidade de BI. Ele é apaixonado por encontrar maneiras de resolver problemas que afligem o DBA cotidiano e adora compartilhar isso com os outros. Ele pode ser encontrado falando em eventos da comunidade SQL, bem como blogando em DustinDorsey.com.
Dustin Dorsey é atualmente o Managing Database Engineer da LifePoint Health, na qual lidera uma equipe responsável pelo gerenciamento e engenharia de soluções em tecnologias de banco de dados para 90 hospitais. Ele vem trabalhando e dando suporte ao SQL Server predominantemente na área de saúde desde 2008 em administração, arquitetura, desenvolvimento e capacidade de BI. Ele é apaixonado por encontrar maneiras de resolver problemas que afligem o DBA cotidiano e adora compartilhar isso com os outros. Ele pode ser encontrado falando em eventos da comunidade SQL, bem como blogando em DustinDorsey.com.