O conhecimento de replicação é uma obrigação para qualquer pessoa que gerencia bancos de dados. É um tópico que você provavelmente já viu várias vezes, mas nunca envelhece. Neste blog, revisaremos um pouco da história dos recursos de replicação integrados do PostgreSQL e nos aprofundaremos em como a replicação de streaming funciona.
Ao falar sobre replicação, falaremos muito sobre WALs. Então, vamos revisar rapidamente um pouco sobre os logs de gravação antecipada.
Registro de gravação antecipada (WAL)
Um registro de gravação antecipada é um método padrão para garantir a integridade dos dados e é ativado automaticamente por padrão.
Os WALs são os logs REDO no PostgreSQL. Mas o que exatamente são os logs REDO?
Os logs REDO contêm todas as alterações feitas no banco de dados e são usados para replicação, recuperação, backup online e recuperação pontual (PITR). Quaisquer alterações que não tenham sido aplicadas às páginas de dados podem ser refeitas a partir dos logs REDO.
O uso do WAL resulta em um número significativamente reduzido de gravações em disco porque apenas o arquivo de log precisa ser liberado para o disco para garantir que uma transação seja confirmada, em vez de todos os arquivos de dados alterados pela transação.
Um registro WAL especificará as alterações feitas nos dados, bit a bit. Cada registro WAL será anexado a um arquivo WAL. A posição de inserção é um Log Sequence Number (LSN), um deslocamento de byte nos logs, aumentando a cada novo registro.
Os WALs são armazenados no diretório pg_wal (ou pg_xlog nas versões do PostgreSQL <10) sob o diretório data. Esses arquivos têm um tamanho padrão de 16 MB (você pode alterar o tamanho alterando a opção de configuração --with-wal-segsize ao construir o servidor). Eles têm um nome incremental exclusivo no seguinte formato:"00000001 00000000 00000000".
O número de arquivos WAL contidos em pg_wal dependerá do valor atribuído ao parâmetro checkpoint_segments (ou min_wal_size e max_wal_size, dependendo da versão) no arquivo de configuração postgresql.conf.
Um parâmetro que você precisa configurar ao configurar todas as suas instalações do PostgreSQL é o wal_level. O wal_level determina quanta informação é gravada no WAL. O valor padrão é mínimo, que grava apenas as informações necessárias para se recuperar de uma falha ou desligamento imediato. Arquivo adiciona o registro necessário para o arquivamento do WAL; hot_standby adiciona ainda informações necessárias para executar consultas somente leitura em um servidor em espera; logic adiciona as informações necessárias para suportar a decodificação lógica. Esse parâmetro requer uma reinicialização, portanto, pode ser difícil alterá-lo nos bancos de dados de produção em execução, caso você tenha esquecido isso.
Para mais informações, você pode verificar a documentação oficial aqui ou aqui. Agora que abordamos o WAL, vamos revisar o histórico de replicação no PostgreSQL.
Histórico de replicação no PostgreSQL
O primeiro método de replicação (warm standby) que o PostgreSQL implementou (versão 8.2, em 2006) foi baseado no método de envio de logs.
Isso significa que os registros WAL são movidos diretamente de um servidor de banco de dados para outro para serem aplicados. Podemos dizer que é um PITR contínuo.
O PostgreSQL implementa o envio de log baseado em arquivo, transferindo os registros WAL um arquivo (segmento WAL) por vez.
Esta implementação de replicação tem o lado negativo:se houver uma falha grave nos servidores primários, as transações ainda não enviadas serão perdidas. Portanto, há uma janela para perda de dados (você pode ajustar isso usando o parâmetro archive_timeout, que pode ser definido para alguns segundos. No entanto, uma configuração tão baixa aumentará substancialmente a largura de banda necessária para o envio de arquivos).
Podemos representar este método de envio de log baseado em arquivo com a imagem abaixo:
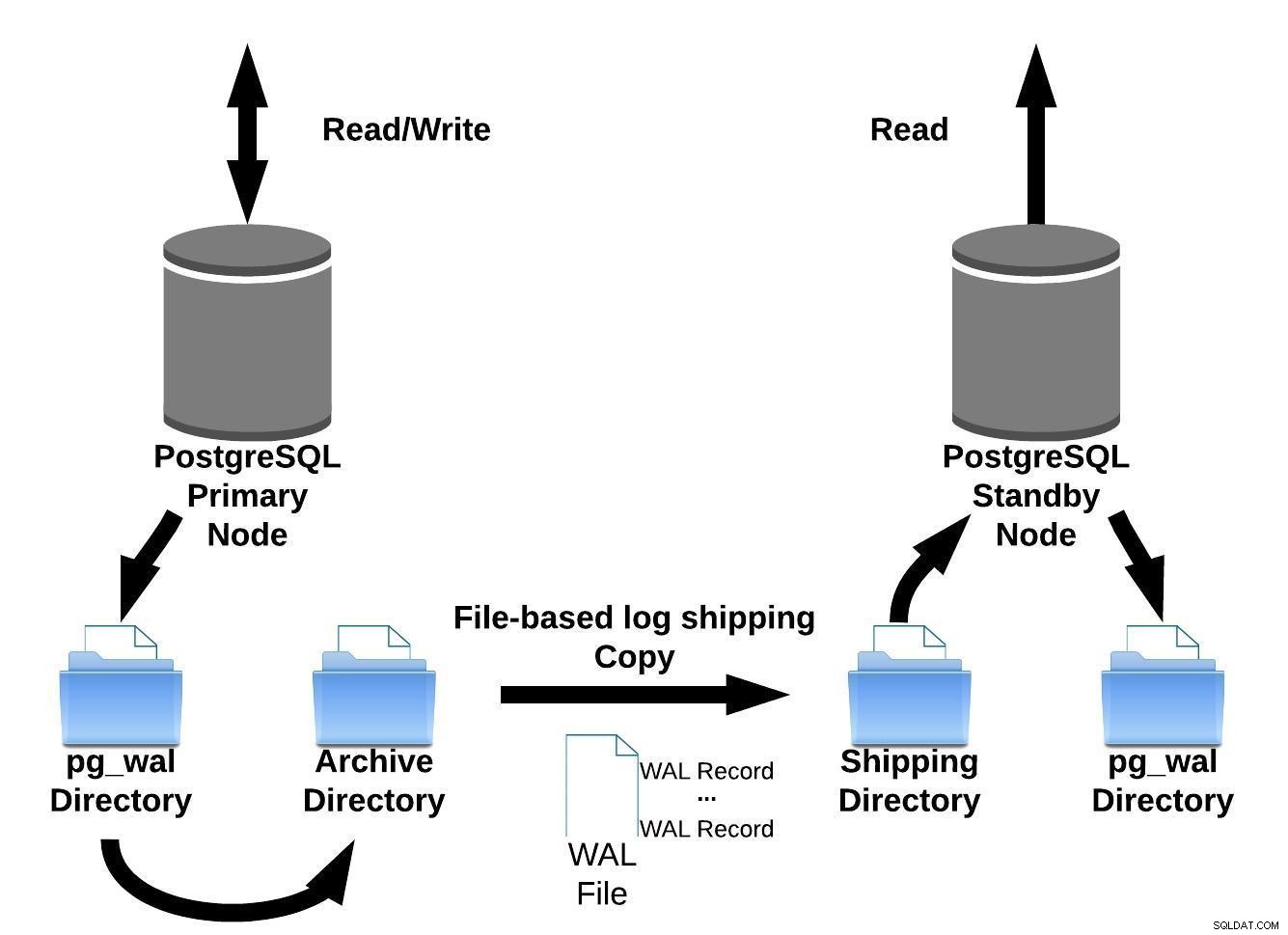 Envio de log baseado em arquivo PostgreSQL
Envio de log baseado em arquivo PostgreSQL
Depois, na versão 9.0 (em 2010 ), a replicação de streaming foi introduzida.
A replicação de streaming permite que você fique mais atualizado do que é possível com o envio de logs baseado em arquivo. Isso funciona transferindo registros WAL (um arquivo WAL é composto de registros WAL) em tempo real (envio de log baseado em registro) entre um servidor primário e um ou vários servidores em espera sem esperar que o arquivo WAL seja preenchido.
Na prática, um processo chamado receptor WAL, executado no servidor em espera, se conectará ao servidor primário usando uma conexão TCP/IP. No servidor primário, existe outro processo, chamado WAL remetente, e é responsável por enviar os registros WAL para o servidor em espera à medida que eles acontecem.
O diagrama a seguir representa a replicação de streaming:
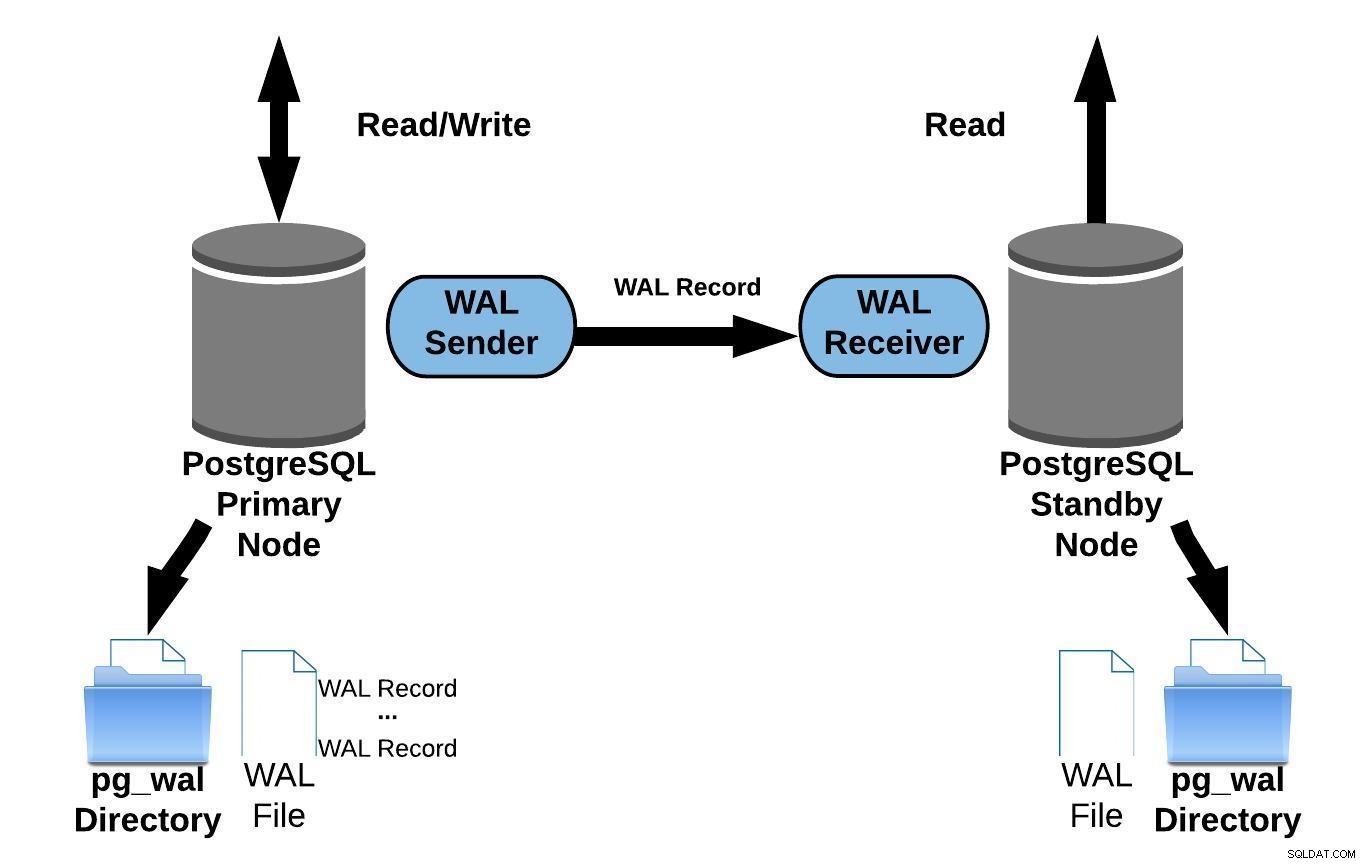 Replicação de streaming do PostgreSQL
Replicação de streaming do PostgreSQL
Olhando para o diagrama acima, você pode se perguntar o que acontece quando a comunicação entre o remetente WAL e o receptor WAL falha?
Ao configurar a replicação de streaming, você tem a opção de habilitar o arquivamento WAL.
Esta etapa não é obrigatória, mas é extremamente importante para uma configuração de replicação robusta. É necessário evitar que o servidor principal recicle arquivos WAL antigos que ainda não foram aplicados ao servidor em espera. Se isso ocorrer, você precisará recriar a réplica do zero.
Ao configurar a replicação com arquivamento contínuo, ela inicia a partir de um backup. Para atingir o estado em sincronia com o primário, ele precisa aplicar todas as alterações hospedadas no WAL que ocorreram após o backup. Durante esse processo, o modo de espera restaurará primeiro todo o WAL disponível no local do arquivo (feito chamando restore_command). O restore_command falhará quando atingir o último registro WAL arquivado, então, depois disso, o standby irá procurar no diretório pg_wal para ver se a alteração existe lá (isso funciona para evitar perda de dados quando os servidores primários travam e algumas alterações que já foram movidos e aplicados à réplica ainda não foram arquivados).
Se isso falhar e o registro solicitado não existir lá, ele começará a se comunicar com o servidor primário por meio de replicação de streaming.
Sempre que a replicação de streaming falhar, ela retornará à etapa 1 e restaurará os registros do arquivo novamente. Esse loop de tentativas do arquivo, pg_wal e via replicação de streaming continua até que o servidor pare ou o failover seja acionado por um arquivo de gatilho.
O diagrama a seguir representa uma configuração de replicação de streaming com arquivamento contínuo:
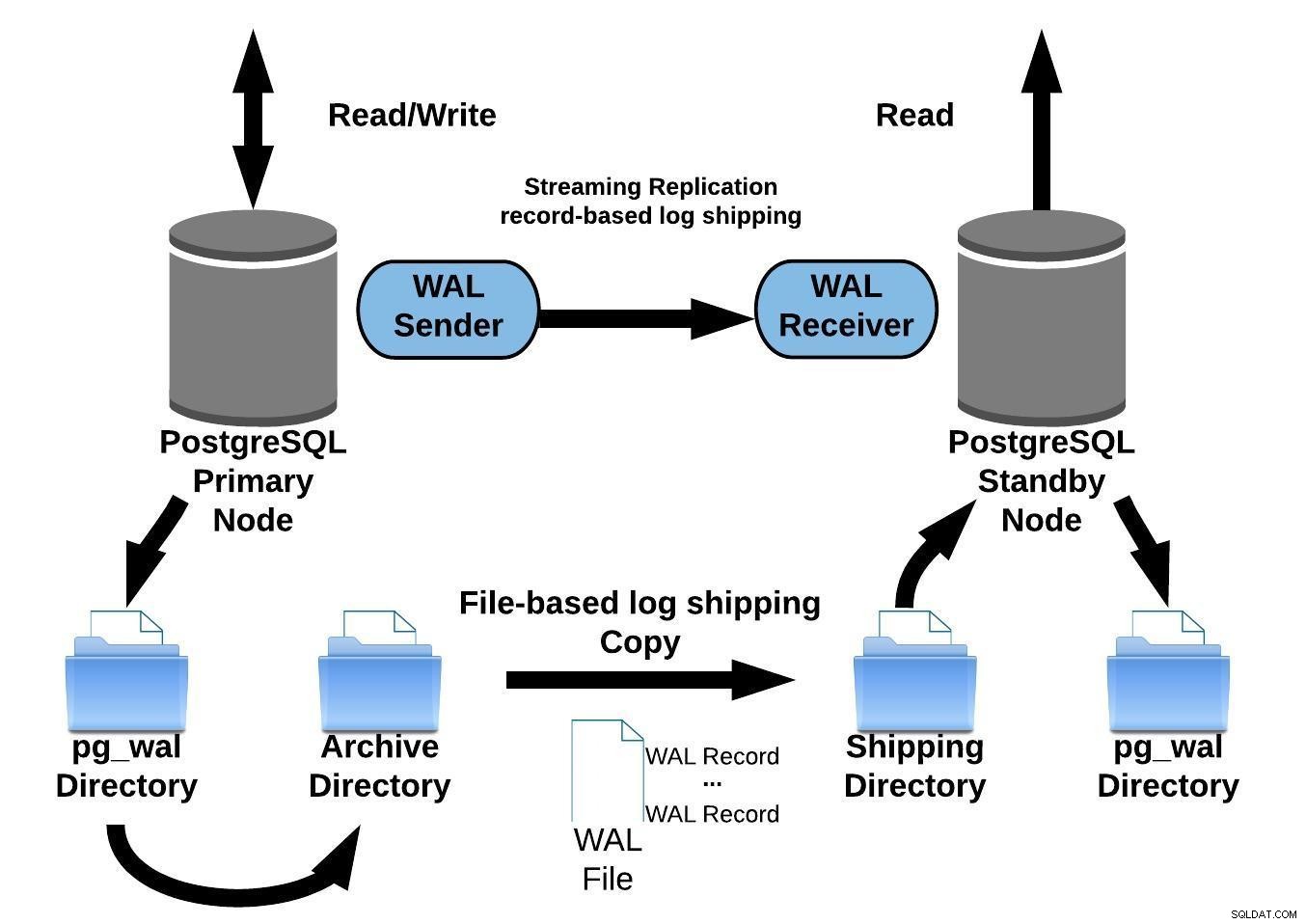 Replicação de streaming PostgreSQL com arquivamento contínuo
Replicação de streaming PostgreSQL com arquivamento contínuo
A replicação de streaming é assíncrona por padrão, portanto, em a qualquer momento, você pode ter algumas transações que podem ser confirmadas no servidor primário e ainda não replicadas no servidor em espera. Isso implica em alguma perda potencial de dados.
No entanto, esse atraso entre o commit e o impacto das alterações na réplica deve ser muito pequeno (alguns milissegundos), supondo, é claro, que o servidor de réplica seja poderoso o suficiente para acompanhar A carga.
Para os casos em que mesmo o risco de uma leve perda de dados não é aceitável, a versão 9.1 introduziu o recurso de replicação síncrona.
Na replicação síncrona, cada confirmação de uma transação de gravação aguarda até que seja recebida a confirmação de que a confirmação foi gravada no log de gravação antecipada no disco do servidor primário e de espera.
Este método minimiza a possibilidade de perda de dados; para que isso aconteça, você precisará que o primário e o standby falhem simultaneamente.
A desvantagem óbvia dessa configuração é que o tempo de resposta para cada transação de gravação aumenta, pois ela precisa esperar até que todas as partes tenham respondido. Portanto, o tempo para uma confirmação é, no mínimo, a viagem de ida e volta entre o primário e a réplica. As transações somente leitura não serão afetadas por isso.
Para configurar a replicação síncrona, você precisa especificar um application_name no primary_conninfo da recuperação para cada arquivo server.conf em espera:primary_conninfo ='...aplication_name=standbyX' .
Você também precisa especificar a lista dos servidores em espera que farão parte da replicação síncrona:synchronous_standby_name ='standbyX,standbyY'.
Você pode configurar um ou vários servidores síncronos, e esse parâmetro também especifica qual método (FIRST e ANY) escolher os standbys síncronos dentre os listados. Para obter mais informações sobre como configurar o modo de replicação síncrona, confira este blog. Também é possível configurar a replicação síncrona ao implantar via ClusterControl.
Depois de configurar sua replicação e ela estiver funcionando, você precisará implementar o monitoramento
Monitorando a replicação do PostgreSQL
A visualização pg_stat_replication no servidor mestre tem muitas informações relevantes:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Vamos ver isso em detalhes:
-
pid:ID do processo walsender.
-
usesysid:OID do usuário que é usado para replicação de streaming.
-
usename:Nome do usuário que é usado para replicação de streaming.
-
application_name:Nome do aplicativo conectado ao mestre.
-
client_addr:Endereço de replicação em espera/streaming.
-
client_hostname:Nome do host de espera.
-
client_port:número da porta TCP na qual espera se comunicar com o remetente WAL.
-
backend_start:Hora de início quando o SR se conectou ao Primário.
-
estado:estado atual do remetente WAL, ou seja, streaming.
-
sent_lsn:Último local de transação enviado para espera.
-
write_lsn:Última transação gravada no disco em espera.
-
flush_lsn:Última transação liberada no disco em espera.
-
replay_lsn:Última transação liberada no disco em espera.
-
sync_priority:Prioridade do servidor standby escolhido como standby síncrono.
-
sync_state:Sync Estado de espera (é assíncrono ou síncrono).
Você também pode ver os processos do remetente/receptor WAL em execução nos servidores.
Remetente (nó primário):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Receptor (nó de espera):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Uma forma de verificar se sua replicação está atualizada é verificando a quantidade de registros WAL gerados no servidor primário, mas ainda não aplicados no servidor em espera.
Primário:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Espera:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Você pode usar a seguinte consulta no nó de espera para obter o atraso em segundos:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)E você também pode ver a última mensagem recebida:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Monitorando a replicação do PostgreSQL com ClusterControl
Para monitorar seu cluster PostgreSQL, você pode usar o ClusterControl, que permite monitorar e executar várias tarefas de gerenciamento adicionais, como implantação, backups, expansão e muito mais.
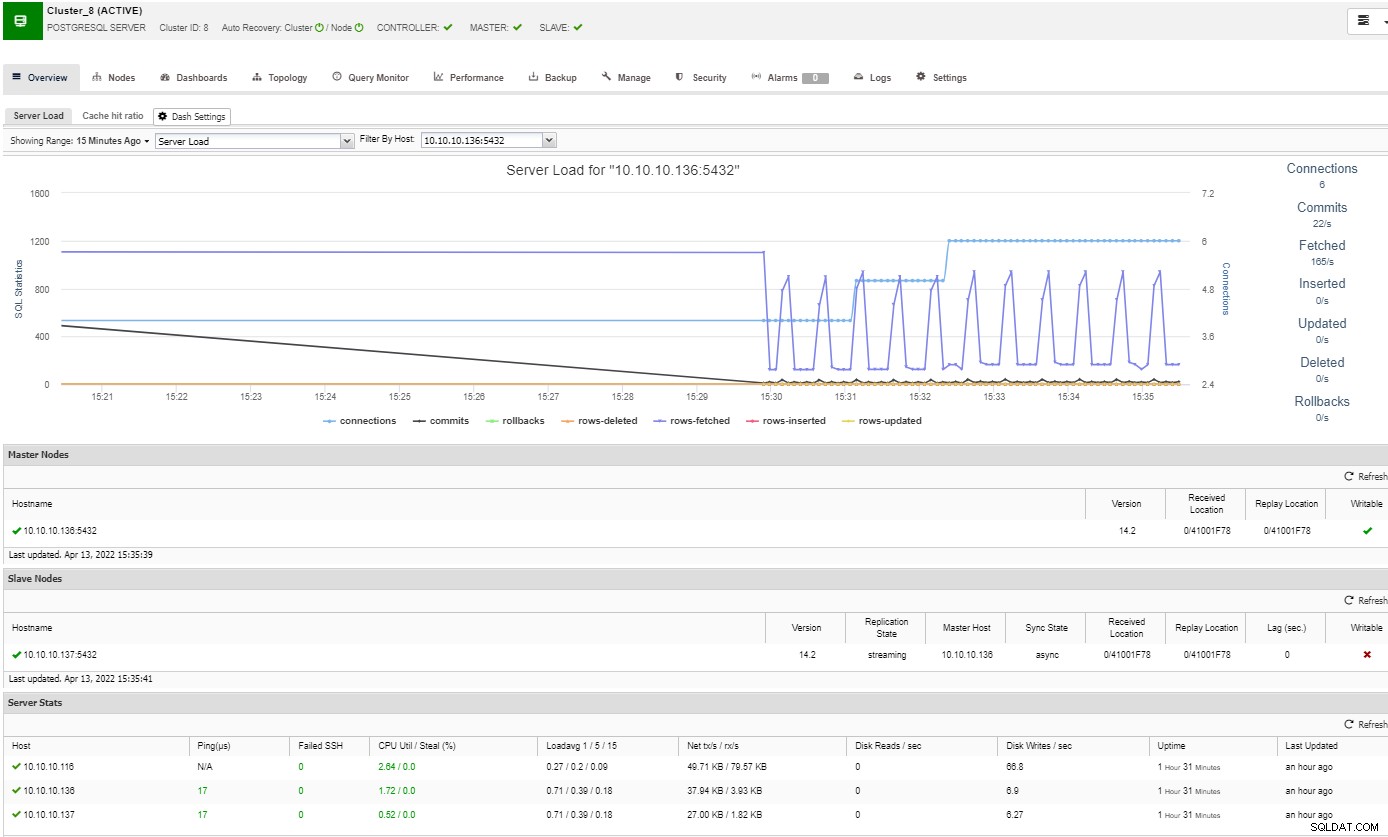
Na seção de visão geral, você terá uma visão completa do cluster de banco de dados status atual. Para ver mais detalhes, você pode acessar a seção do painel, onde você verá muitas informações úteis separadas em diferentes gráficos.
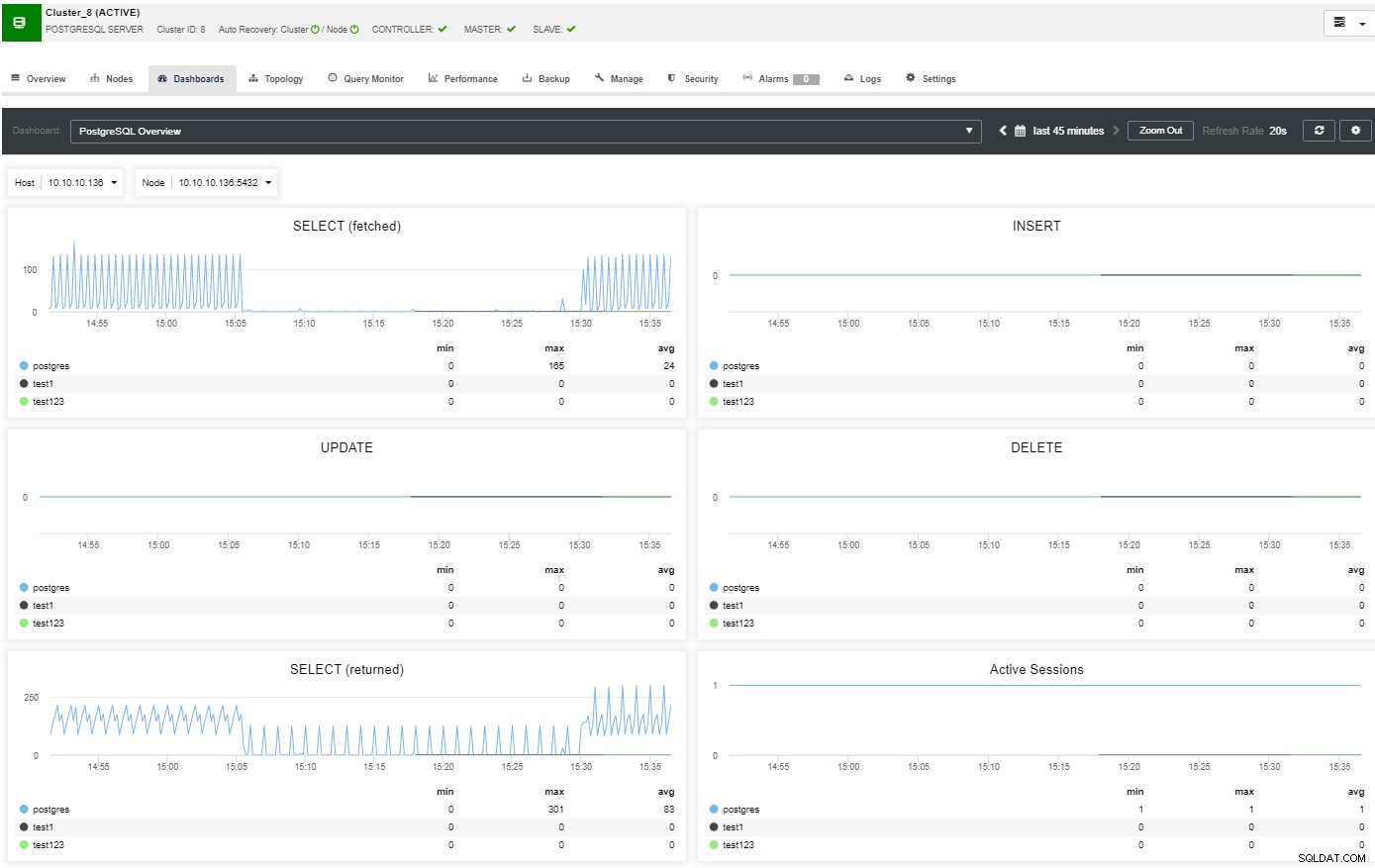
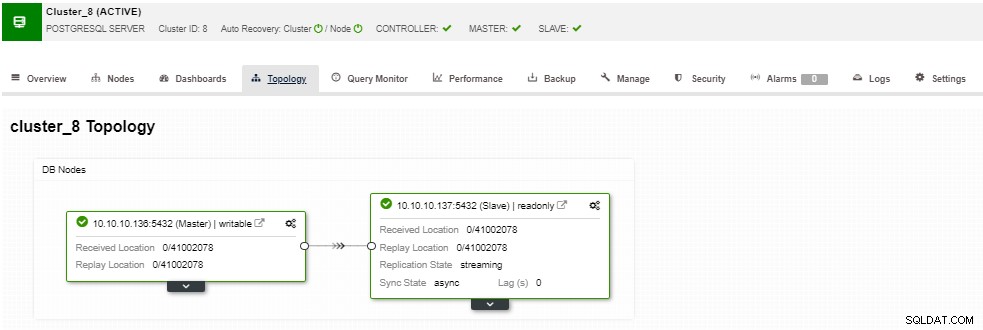
Na seção de topologia, você pode ver sua topologia atual em um arquivo user- maneira amigável, e você também pode executar tarefas diferentes nos nós usando o botão Ação do nó.
A replicação de streaming é baseada em enviar os registros WAL e aplicá-los ao modo de espera servidor, ele dita quais bytes adicionar ou alterar em qual arquivo. Como resultado, o servidor em espera é, na verdade, uma cópia bit a bit do servidor primário. Existem, no entanto, algumas limitações bem conhecidas aqui:
-
Você não pode replicar em uma versão ou arquitetura diferente.
-
Você não pode alterar nada no servidor em espera.
-
Você não tem muita granularidade no que replica.
Então, para superar essas limitações, o PostgreSQL 10 adicionou suporte para replicação lógica
Replicação lógica
A replicação lógica também usará as informações do arquivo WAL, mas as decodificará em alterações lógicas. Em vez de saber qual byte foi alterado, ele saberá precisamente quais dados foram inseridos em qual tabela.
É baseado em um modelo "publicar" e "assinar" com um ou mais assinantes assinando uma ou mais publicações em um nó de editor que se parece com isso:
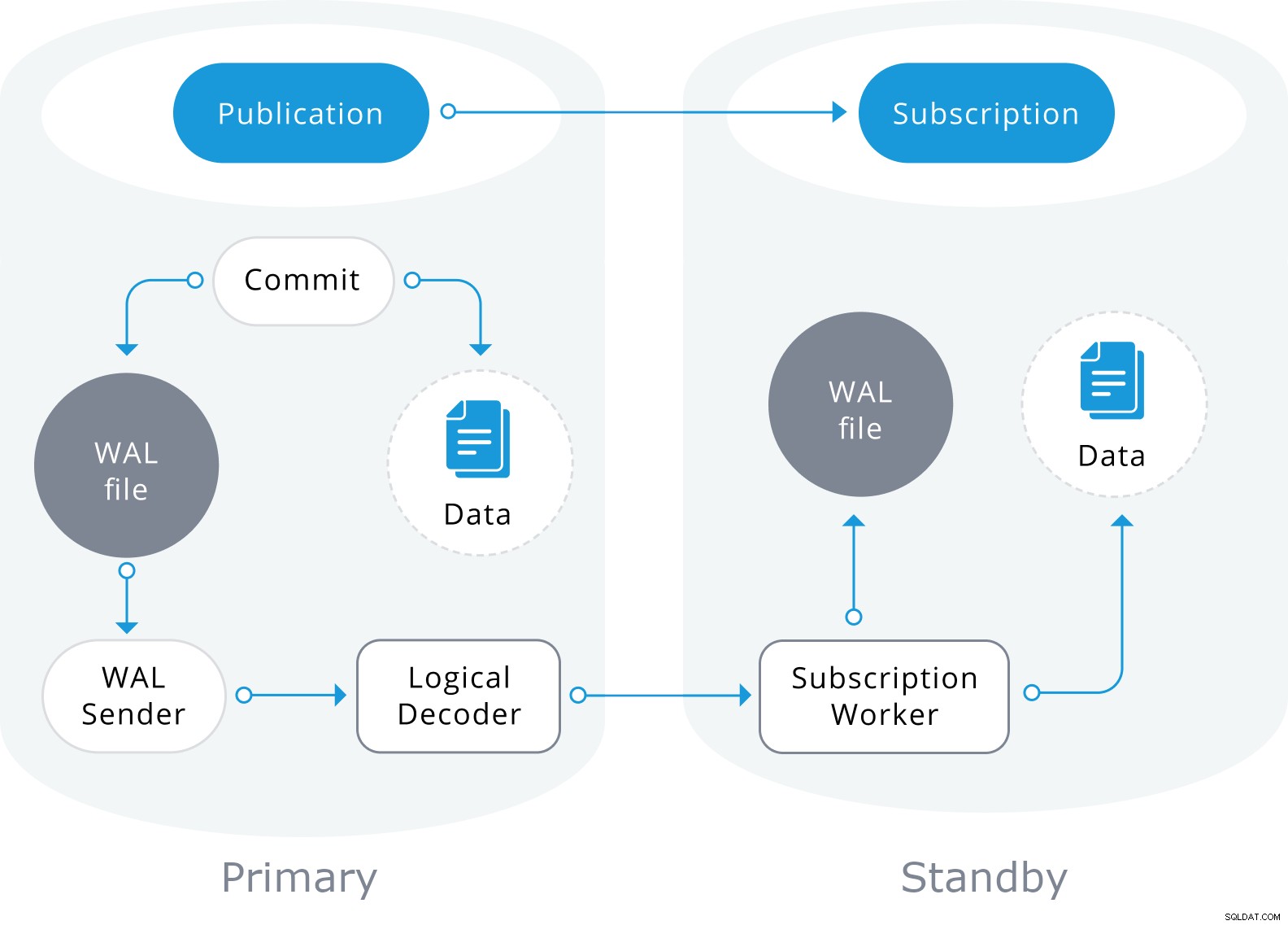
Replicação lógica do PostgreSQL
Encerrando
Com a replicação de streaming, você pode enviar e aplicar continuamente registros WAL aos seus servidores em espera, garantindo que as informações atualizadas no servidor primário sejam transferidas para o servidor em espera em tempo real, permitindo que ambos permaneçam sincronizados .
O ClusterControl simplifica a configuração da replicação de streaming e você pode avaliá-la gratuitamente por 30 dias.
Se você quiser saber mais sobre replicação lógica no PostgreSQL, não deixe de conferir esta visão geral da replicação lógica e este post sobre as melhores práticas de replicação do PostgreSQL.
Para obter mais dicas e práticas recomendadas para gerenciar seu banco de dados baseado em código aberto, siga-nos no Twitter e LinkedIn e assine nosso boletim informativo para atualizações regulares.



