Introdução
No SQL Server 2012, a agregação agrupada (vetor) podia usar a execução paralela em modo de lote, mas apenas para a agregação parcial (por thread). O agregado global associado sempre foi executado no modo de linha, após um Repartition Streams intercâmbio.
O SQL Server 2014 adicionou a capacidade de realizar agregação agrupada em modo de lote paralelo em um único Hash Match Aggregate operador. Isso eliminou o processamento desnecessário no modo de linha e eliminou a necessidade de uma troca.
O SQL Server 2016 introduziu o processamento em modo de lote serial e pushdown agregado . Quando o pushdown é bem-sucedido, a agregação é realizada dentro do Columnstore Scan próprio operador, possivelmente operando diretamente em dados compactados e aproveitando as instruções da CPU SIMD.
As melhorias de desempenho possíveis com empilhamento agregado podem ser muito substanciais. A documentação lista algumas das condições necessárias para obter o pushdown, mas há casos em que a falta de "linhas agregadas localmente" não pode ser totalmente explicada apenas com esses detalhes.
Este artigo aborda fatores adicionais que afetam o empilhamento agregado para
GROUP BY somente consultas . Empilhamento agregado escalar (agregação sem um GROUP BY cláusula), empilhamento de filtro e empilhamento de expressão podem ser abordados em uma postagem futura. Armazenamento de colunas
A primeira coisa a dizer é que o empilhamento agregado se aplica apenas a dados compactados, portanto, as linhas em um armazenamento delta não são elegíveis. Além disso, o pushdown pode depender do tipo de compactação usado. Para entender isso, é necessário primeiro revisar como o armazenamento columnstore funciona em alto nível:
Um grupo de linhas compactado contém um segmento de coluna para cada coluna. Os valores brutos da coluna são codificados em um inteiro de 4 ou 8 bytes usando valor ou dicionário codificação.
Codificação de valor pode reduzir o número de bits necessários para armazenamento traduzindo valores brutos usando um deslocamento de base e um modificador de magnitude. Por exemplo, os valores {1100, 1200, 1300} podem ser armazenados como (0, 1, 2) primeiro dimensionando por um fator de 0,01 para fornecer {11, 12, 13}, depois rebaseando em 11 para fornecer {0, 1, 2}.
Codificação do dicionário é usado quando há valores duplicados. Pode ser usado com dados não numéricos. Cada valor exclusivo é armazenado em um dicionário e atribuído a um id inteiro. Os dados do segmento fazem referência aos números de identificação no dicionário em vez dos valores originais.
Após a codificação, os dados do segmento podem ser ainda compactados usando codificação de comprimento de execução (RLE) e empacotamento de bits:
RE substitui elementos repetidos pelos dados e o número de repetições, por exemplo, {1, 1, 1, 1, 1, 2, 2, 2} pode ser substituído por {5×1, 3×2}. A economia de espaço RLE aumenta com a duração das execuções repetidas. Corridas curtas podem ser contraproducentes.
Bit-packing armazena a forma binária dos dados em uma janela comum tão estreita quanto possível. Por exemplo, os números {7, 9, 15} são armazenados em inteiros binários (byte único para espaço) como {00000111, 00001001, 00001111}. Empacotar esses bits em uma janela fixa de quatro bits fornece o fluxo {011110011111}. Saber que há um tamanho de janela fixo significa que não há necessidade de um delimitador.
A codificação e a compactação são etapas separadas, portanto, o RLE e o empacotamento de bits são aplicados ao resultado da codificação de valor ou codificação de dicionário dos dados brutos. Além disso, os dados no mesmo segmento de coluna podem ter uma mistura de compressão RLE e bit-packing. Os dados compactados por RLE são chamados de puros , e os dados compactados em pacotes de bits são chamados de impuros . Um segmento de coluna pode conter dados puros e impuros.
A economia de espaço que pode ser obtida por meio da codificação e compactação pode depender do pedido. Todos os segmentos de coluna em um grupo de linhas devem ser classificados implicitamente da mesma maneira para que o SQL Server possa reconstruir com eficiência as linhas completas dos segmentos de coluna. Saber que a linha 123 está armazenada na mesma posição (123) em cada segmento de coluna significa que o número da linha não precisa ser armazenado.
Uma desvantagem desse arranjo é que uma ordem de classificação comum deve ser escolhido para todos os segmentos de coluna em um grupo de linhas. Uma ordenação específica pode se adequar muito bem a uma coluna, mas perder oportunidades significativas em outras colunas. Este é mais claramente o caso da compressão RLE. O SQL Server usa a tecnologia Vertipaq para determinar uma boa maneira de classificar as colunas em cada grupo de linhas para obter um bom resultado geral de compactação.
O SQL Server atualmente usa apenas RLE dentro de um segmento de coluna quando há um mínimo de 64 valores repetidos contíguos. Os valores restantes no segmento são empacotados em bits. Conforme observado, se os valores repetidos aparecem como contíguos em um segmento de coluna depende da ordem escolhida para o grupo de linhas.
O SQL Server oferece suporte a SIMD especializado descompactação de bits para larguras de bits de 1 a 10, inclusive, 12 e 21 bits. O SQL Server também pode usar tamanhos inteiros padrão, por exemplo 16, 32 e 64 bits com empacotamento de bits. Esses números são escolhidos porque se encaixam perfeitamente em uma unidade de 64 bits. Por exemplo, uma unidade pode conter três subunidades de 21 bits ou 5 subunidades de 12 bits. SQL Server não cruzar um limite de 64 bits ao empacotar bits.
SIMD usa registradores de 256 bits quando o processador suporta instruções AVX2 e registradores de 128 bits quando instruções SSE4.2 estão disponíveis. Caso contrário, a descompactação não SIMD pode ser usada.
Condições de empilhamento agregadas agrupadas
A maioria dos planos com um Hash Match Aggregate operador diretamente acima de um Columnstore Scan O operador potencialmente se qualificará para empilhamento agregado agrupado, sujeito às condições gerais indicadas na documentação.
Às vezes, filtros e expressões extras também podem ser adicionados sem impedir o empilhamento de agregados agrupados. A regra geral é que o filtro ou expressão também deve ser capaz de empilhar (embora expressões compatíveis ainda possam aparecer em um Compute Scalar separado ). Conforme observado na introdução, esses aspectos podem ser abordados em detalhes em artigos separados.
Atualmente, não há nada nos planos de execução para indicar se um determinado agregado foi considerado geralmente compatível com pushdown agregado agrupado ou não. Ainda assim, quando o plano geralmente se qualifica para empilhamento agregado agrupado, os caminhos de código de empilhamento (rápido) e sem empilhamento (lento) são disponibilizados.
Cada lote de saída de digitalização (de até 900 linhas) toma uma decisão de tempo de execução entre os caminhos de código rápido e lento. Essa flexibilidade permite que o maior número possível de lotes se beneficie do pushdown. Na pior das hipóteses, nenhum lote usará o caminho rápido em tempo de execução, apesar de um plano “geralmente compatível”.
O plano de execução mostra o resultado do processamento de empilhamento de caminho rápido como 'linhas agregadas localmente' sem saída de linha correspondente da varredura. Os lotes de caminho lento aparecem como linhas de saída da varredura de columnstore como de costume, com a agregação executada por um operador separado em vez de na varredura.
Uma única combinação de agregação e varredura agrupada pode enviar alguns lotes pelo caminho rápido e outros pelo caminho lento, portanto, é perfeitamente possível ver algumas, mas não todas, as linhas agregadas localmente. Quando o empilhamento agregado agrupado é bem-sucedido, cada lote de saída da varredura contém chaves de agrupamento e um agregado parcial que representa as linhas que contribuem.
Verificações detalhadas
Há várias verificações de tempo de execução para determinar se o processamento de empilhamento pode ser usado. Entre as verificações levemente documentadas estão:
- Não deve haver possibilidade de estouro agregado .
- Qualquer impuro (bit-packed) chaves de agrupamento deve ser não maior que 10 bits . Chaves de agrupamento puras (codificadas em RLE) são tratadas como tendo uma largura impura de zero, portanto, geralmente apresentam poucos obstáculos.
- O processamento de pushdown deve continuar sendo considerado valendo , usando uma "medida de benefício" atualizada no final de cada lote de saída.
A possibilidade de estouro agregado é avaliado de forma conservadora para cada lote com base no tipo de agregação, tipo de dados de resultado, valores atuais de agregação parcial e informações sobre os dados de entrada. Por exemplo, o SQL Server conhece os valores mínimo e máximo dos metadados do segmento conforme exposto no DMV
sys.column_store_segments . Onde houver risco de estouro, o lote usará o processamento de caminho lento. Isso é principalmente um risco para o SUM agregar. A restrição na largura da chave de agrupamento impura vale a pena enfatizar. Aplica-se apenas a colunas no
GROUP BY cláusula que são realmente utilizadas no plano de execução como base para o agrupamento. Esses conjuntos nem sempre são exatamente os mesmos porque o otimizador tem liberdade para remover colunas de agrupamento redundantes ou para reescrever agregados, desde que os resultados finais da consulta sejam garantidos para corresponder à especificação da consulta original. Onde houver uma disparidade, são as colunas de agrupamento mostradas no plano de execução que importam. A maior dificuldade é saber se alguma das colunas de agrupamento é armazenada usando bit-packing e, em caso afirmativo, qual largura foi usada. Também seria útil saber quantos valores foram codificados usando RLE. Essas informações podem estar em
column_store_segments DMV, mas esse não é o caso hoje. Até onde eu sei, não há nenhuma maneira documentada no momento de obter informações de empacotamento de bits e RLE dos metadados. Isso nos deixa com a procura de alternativas não documentadas. Encontrando informações de RLE e empacotamento de bits
O
DBCC CSINDEX não documentado pode nos dar as informações que precisamos. O sinalizador de rastreamento 3604 precisa estar ativado para que esse comando produza saída na guia de mensagens do SSMS. Dadas as informações sobre o segmento de coluna em que estamos interessados, este comando retorna:- Atributos de segmento (semelhantes a
column_store_segments) - Informações do RLE
- Favoritos em dados RLE
- Informações do pacote de bits
Por não estar documentado, existem algumas peculiaridades (como ter que adicionar um aos ids de coluna para columnstore clusterizado, mas não columnstore não clusterizado) e até mesmo alguns erros menores. Você não deve usá-lo em nada, exceto em um sistema de teste pessoal. Felizmente, um dia, um método compatível para acessar esses dados será fornecido.
Exemplos
A melhor maneira de mostrar
DBCC CSINDEX e demonstrar os pontos levantados até agora neste texto é trabalhar com alguns exemplos. Os scripts a seguir assumem que existe uma tabela chamada dbo.Numbers no banco de dados atual que contém números inteiros de 1 a pelo menos 16.384. Aqui está um script para criar minha versão padrão desta tabela com dez milhões de inteiros:IF OBJECT_ID(N'dbo.Numbers', N'U') NÃO É NULLBEGIN DROP TABLE dbo.Numbers;END;GOWITH Ten(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) SELECT n =IDENTITY(int, 1, 1)INTO dbo.NumbersFROM Ten AS T10CROSS JOIN Ten AS T100CROSS JOIN Ten AS T1000CROSS JOIN Ten AS T10000CROSS JOIN Ten AS T100000CROSS JOIN Ten AS T1000000CROSS JOIN Ten AS T10000000ORDER BY n OFFSET 0 ROWS FETCH FIRST 10 * 1000 * 1000 ROWS ONLYOPÇÃO (PRIMMAXDOP 1); TABELA DE GOALTER] dbo.NumbersADD RESTRING [PK dbo. KEY CLUSTERED (n)WITH( SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
Todos os exemplos usam a mesma tabela de teste básica:A primeira coluna
c1 contém um número exclusivo para cada linha. A segunda coluna c2 é preenchido com um número de duplicatas para cada um de um pequeno número de valores distintos. Um índice columnstore clusterizado é criado após o preenchimento de dados para que todos os dados de teste terminem em um único grupo de linhas compactado (sem armazenamento delta). Ele é construído substituindo um índice clusterizado b-tree na coluna
c2 para incentivar o algoritmo VertiPaq a considerar a utilidade da classificação nessa coluna desde o início. Esta é a configuração básica do teste:USE Sandpit;GODROP TABLE SE EXISTE dbo.Test;GOCREATE TABLE dbo.Test( c1 integer NOT NULL, c2 integer NOT NULL);GODECLAR @values integer =512, @dupes integer =63; INSERT dbo.Test (c1, c2)SELECT N.n, N.n % @valuesFROM dbo.Numbers AS NWHERE N.n BETWEEN 1 AND @values * @dupes;GO-- Incentivar VertiPaqCREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
As duas variáveis são para o número de valores distintos a serem inseridos na coluna
c2 e o número de duplicatas para cada um desses valores. A consulta de teste é um
COUNT_BIG agrupado muito simples agregação usando a coluna c2 como chave:-- O teste querySELECT T.c2, numrows =COUNT_BIG(*)FROM dbo.Test AS TGROUP BY T.c2;
As informações do índice Columnstore serão exibidas usando
DBCC CSINDEX após cada execução de consulta de teste:DECLARE @dbname sysname =DB_NAME(), @objectid integer =OBJECT_ID(N'dbo.Test', N'U'); DECLARE @rowsetid bigint =( SELECT P.hobt_id FROM sys.partitions AS P WHERE P.[object_id] =@objectid AND P.index_id =1 AND P.partition_number =1 ), @rowgroupid integer =0, @columnid integer =COLUMNPROPERTY (@objectid, N'c2', 'ColumnId') + 1; DBCC CSINDEX( @dbname, @rowsetid, @columnid, @rowgroupid, 1, -- mostra os dados do segmento 2, -- print option 0, -- start bitpack unit (inclusive) 2 -- end bitpack unit (exclusive));
Os testes foram executados na versão mais recente do SQL Server disponível no momento da redação:Microsoft SQL Server 2017 RTM-CU13-OD compilação 14.0.3049 Developer Edition (64 bits) no Windows 10 Pro. As coisas também devem funcionar bem na versão mais recente do SQL Server 2016.
Teste 1:Pushdown, chaves impuras de 9 bits
Este teste usa o script de preenchimento de dados de teste exatamente como escrito acima, produzindo uma tabela com 32.256 linhas. Colunac1contém números de 1 a 32.256.
Colunac2contém 512 valores distintos de 0 a 511 inclusive. Cada valor emc2é duplicado 63 vezes , mas eles não aparecem como blocos contíguos quando visualizados emc1pedido; eles circulam 63 vezes pelos valores de 0 a 511.
Dada a discussão anterior, esperamos que o SQL Server armazene oc2dados da coluna usando:
- Codificação do dicionário pois há um número significativo de valores duplicados.
- Sem RLE . O número de duplicatas (63) por valor não atinge o limite de 64 exigido para RLE.
- Bit-packing tamanho 9 . As 512 entradas distintas do dicionário caberão exatamente em 9 bits (2^9 =512). Cada unidade de 64 bits conterá até sete subunidades de 9 bits.
Tudo isso é confirmado como correto usando o
DBCC CSINDEX inquerir:Os Atributos do Segmento seção da saída mostra a codificação do dicionário (tipo 2; os valores para
encodingType estão documentados em sys.column_store_segments ). Atributos do segmento:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Contagem de Linhas =32256
A seção RLE mostra nenhum dado RLE , apenas um ponteiro para a região compactada de bits e uma entrada vazia para o valor zero:
Cabeçalho RLE:
Tipo de Lob =3 Contagem de Array RLE (Em termos de Unidades Nativas) =2
Tamanho de Entrada de Array RLE =8
Dados RLE:
Índice =0 Bitpack Array Índice =0 Contagem =32256
Índice =1 Valor =0 Contagem =0
O Cabeçalho de Dados do Bitpack seção mostra tamanho do pacote de bits 9 e 4.608 unidades bitpack usadas:
Cabeçalho de dados do pacote de bits:
Tamanho da entrada do pacote de bits =9 Contagem de unidades do pacote de bits =4608 Bitpack MinId =3
Tamanho de dados do pacote de bits =36864
Os Dados do Bitpack seção mostra os valores armazenados nas duas primeiras unidades de bitpack conforme solicitado pelos dois últimos parâmetros para o
DBCC CSINDEX comando. Lembre-se de que cada unidade de 64 bits pode conter 7 subunidades (numeradas de 0 a 6) de 9 bits cada (7 x 9 =63 bits). As 4.608 unidades em geral contêm 4.608 * 7 =32.256 linhas:Dados do pacote de bits:
Unidade 0 Subunidade 0 =383
Unidade 0 Subunidade 1 =255
Unidade 0 Subunidade 2 =127
Unidade 0 Subunidade 3 =510
Unidade 0 Subunidade 4 =381
Unidade 0 Subunidade 5 =253
Unidade 0 Subunidade 6 =125
Unidade 1 Subunidade 0 =508
Unidade 1 Subunidade 1 =379
Unidade 1 Subunidade 2 =251
Unidade 1 Subunidade 3 =123
Unidade 1 Subunidade 4 =506
Unidade 1 Subunidade 5 =377
Unidade 1 Subunidade 6 =249
Como as chaves de agrupamento usam empacotamento de bits com um tamanho menor ou igual a 10 , esperamos empilhamento agregado agrupado para trabalhar aqui. De fato, o plano de execução mostra que todas as linhas foram agregadas localmente no Columnstore Index Scan operador:

O xml do plano contém
ActualLocallyAggregatedRows="32256" nas informações de tempo de execução para a varredura de índice. Teste 2:sem empilhamento, chaves impuras de 12 bits
Este teste altera os
@values parâmetro para 1025, mantendo @dupes em 63. Isso dá uma tabela de 64.575 linhas, com 1.025 valores distintos na coluna c2 funcionando de 0 a 1024 inclusive. Cada valor em c2 é duplicado 63 vezes . SQL Server armazena o
c2 dados da coluna usando:- Codificação do dicionário pois há um número significativo de valores duplicados.
- Sem RLE . O número de duplicatas (63) por valor não atinge o limite de 64 exigido para RLE.
- Bit-packed com tamanho 12 . As 1.025 entradas distintas do dicionário não cabem em 10 bits (2^10 =1.024). Eles caberiam em 11 bits, mas o SQL Server não oferece suporte a esse tamanho de empacotamento de bits, conforme mencionado anteriormente. O próximo tamanho menor é 12 bits. Usando unidades de 64 bits com bordas rígidas para empacotamento de bits, não caberiam mais subunidades de 11 bits em 64 bits do que as subunidades de 12 bits. De qualquer forma, 5 subunidades caberão em uma unidade de 64 bits.
O
DBCC CSINDEX saída confirma a análise acima:Atributos do segmento:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Contagem de Linhas =64575
Cabeçalho RLE:
Tipo de Lob =3 Contagem de Array RLE (Em termos de Unidades Nativas) =2
Tamanho de Entrada de Array RLE =8
Dados RLE:
Índice =0 Bitpack Array Índice =0 Contagem =64575
Índice =1 Valor =0 Contagem =0
Cabeçalho de dados do pacote de bits:
Bitpack Entry Size =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Bitpack Data:
Unidade 0 Subunidade 0 =767
Unidade 0 Subunidade 1 =510
Unidade 0 Subunidade 2 =254
Unidade 0 Subunidade 3 =1021
Unidade 0 Subunidade 4 =765
Unidade 1 Subunidade 0 =507
Unidade 1 Subunidade 1 =250
Unidade 1 Subunidade 2 =1019
Unidade 1 Subunidade 3 =761
Unidade 1 Subunidade 4 =505
Uma vez que o impuro chaves de agrupamento têm um tamanho maior que 10 , esperamos empilhamento agregado agrupado não trabalhar aqui. Isso é confirmado pelo plano de execução mostrando zero linhas agregadas localmente na Varredura de índice de armazenamento de colunas operador:
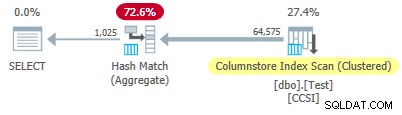
Todas as 64.575 linhas são emitidas (em lotes) pela Varredura de índice de armazenamento de colunas e agregados em modo de lote pelo Hash Match Aggregate operador. As
ActualLocallyAggregatedRows atributo está ausente nas informações de tempo de execução do plano xml para a varredura de índice. Teste 3:pushdown, chaves puras
Este teste altera o
@dupes parâmetro de 63 a 64 para permitir RLE. Os @values O parâmetro é alterado para 16.384 (o máximo para o número total de linhas ainda caber em um único grupo de linhas). O número exato escolhido para @values não é importante — o objetivo é gerar 64 duplicatas de cada valor exclusivo para que o RLE possa ser usado. SQL Server armazena o
c2 dados da coluna usando:- Codificação do dicionário devido aos valores duplicados.
- RLE. Usado para cada valor distinto, pois cada um atende ao limite de 64.
- Nenhum dado compactado em bits . Se houvesse algum, usaria o tamanho 16. O tamanho 12 não é grande o suficiente (2^12 =4.096 valores distintos) e o tamanho 21 seria um desperdício. Os 16.384 valores distintos caberiam em 14 bits, mas, como antes, não cabem mais em uma unidade de 64 bits do que em subunidades de 16 bits.
O
DBCC CSINDEX a saída confirma o acima (apenas algumas entradas RLE e marcadores mostrados por motivos de espaço):Atributos do segmento:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Contagem de Linhas =1048576
Cabeçalho RLE:
Tipo de Lob =3 Contagem de Array RLE (Em termos de Unidades Nativas) =16385
Tamanho de Entrada de Array RLE =8
Dados RLE:
Índice =0 Valor =3 Contagem =64
Índice =1 Valor =1538 Contagem =64
Índice =2 Valor =3072 Contagem =64
Índice =3 Valor =4608 Contagem =64
Índice =4 Valor =6142 Contagem =64
…
Índice =16381 Valor =8954 Contagem =64
Índice =16382 Valor =10489 Contagem =64
Índice =16383 Valor =12025 Contagem =64
Índice =16384 Valor =0 Contagem =0
Cabeçalho do marcador:
Contagem de Favoritos =65 Distância do Favorito =16384 Tamanho do Favorito =520
Dados do marcador:
Posição =0 Índice =64
Posição =512 Índice =16448
Posição =1024 Índice =32832
…
Posição =31744 Índice =1015872
Posição =32256 Índice =1032256
Posição =32768 Índice =1048577
Cabeçalho de dados do pacote de bits:
Tamanho da entrada do pacote de bits =16 Contagem de unidades do pacote de bits =0 Bitpack MinId =3
Bitpack DataSize =0
Como as chaves de agrupamento são puras (RLE é usado), empilhamento agregado agrupado é esperado aqui. O plano de execução confirma isso mostrando todas as linhas agregadas localmente na Varredura de índice de armazenamento de colunas operador:
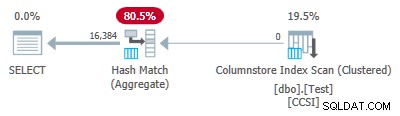
O xml do plano contém
ActualLocallyAggregatedRows="1048576" nas informações de tempo de execução para a varredura de índice. Teste 4:chaves impuras de 10 bits
Este teste define
@values para 1024 e @dupes para 63, resultando em uma tabela de 64.512 linhas, com 1.024 valores distintos na coluna c2 com valores de 0 a 1.023 inclusive. Cada valor em c2 é duplicado 63 vezes . O mais importante , o índice clusterizado b-tree agora é criado na coluna
c1 em vez da coluna c2 . O columnstore clusterizado ainda substitui o índice clusterizado de b-tree. Esta é a parte alterada do script:-- Observe a coluna c1 agora!CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
SQL Server armazena o
c2 dados da coluna usando:- Codificação do dicionário devido às duplicatas.
- Sem RLE . O número de duplicatas (63) por valor não atinge o limite de 64 exigido para RLE.
- Bit-packing com tamanho 10 . As 1.024 entradas distintas do dicionário cabem exatamente em 10 bits (2^10 =1.024). Seis subunidades de 10 bits cada podem ser armazenadas em cada unidade de 64 bits.
O
DBCC CSINDEX saída é:Atributos do segmento:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Contagem de Linhas =64512
Cabeçalho RLE:
Tipo de Lob =3 Contagem de Array RLE (Em termos de Unidades Nativas) =2
Tamanho de Entrada de Array RLE =8
Dados RLE:
Índice =0 Bitpack Array Índice =0 Contagem =64512
Índice =1 Valor =0 Contagem =0
Cabeçalho de dados do pacote de bits:
Bitpack Entry Size =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Unidade 0 Subunidade 0 =766
Unidade 0 Subunidade 1 =509
Unidade 0 Subunidade 2 =254
Unidade 0 Subunidade 3 =1020
Unidade 0 Subunidade 4 =764
Unidade 0 Subunidade 5 =506
Unidade 1 Subunidade 0 =250
Unidade 1 Subunidade 1 =1018
Unidade 1 Subunidade 2 =760
Unidade 1 Subunidade 3 =504
Unidade 1 Subunidade 4 =247
Unidade 1 Subunidade 5 =1014
Uma vez que o impuro chaves de agrupamento usam um tamanho menor ou igual a 10, esperamos empilhamento agregado agrupado para trabalhar aqui. Mas isso não é o que acontece . O plano de execução mostra que 54.612 das 64.512 linhas foram agregadas no Hash Match Aggregate operador:
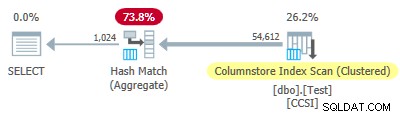
O xml do plano contém
ActualLocallyAggregatedRows="9900" nas informações de tempo de execução para a varredura de índice. Isso significa empilhamento agregado agrupado foi usado para 9.900 linhas, mas não para as outras 54.612! O mecanismo de feedback
O SQL Server começou usando empilhamento agregado agrupado para essa execução porque as chaves de agrupamento impuras atenderam aos critérios de 10 bits ou menos. Isso durou um total de 11 lotes (de 900 linhas cada =9.900 linhas no total). Nesse ponto, um mecanismo de feedback que mede a eficácia do empilhamento agregado agrupado decidiu que não estava funcionando e desligou . Os lotes restantes foram todos processados com o empilhamento desativado.
O feedback essencialmente compara o número de linhas agregadas com o número de grupos produzidos. Ele começa com um valor de 100 e é ajustado no final de cada lote de saída de empilhamento. Se o valor cair para 10 ou abaixo, o pushdown é desabilitado para a operação de agrupamento atual.
A 'medida de benefício pushdown' é reduzida mais ou menos dependendo de quão ruim o esforço de agregação empurrado está indo. Se houver menos de 8 linhas por chave de agrupamento em média no lote de saída, o valor do benefício atual será reduzido em 22%. Se houver mais de 8, mas menos de 16, a métrica será reduzida em 11%.
Por outro lado, se as coisas melhorarem e 16 ou mais linhas por chave de agrupamento forem encontradas posteriormente para um lote de saída, a métrica será redefinida para 100 e continuará a ser ajustada à medida que os lotes agregados parciais forem produzidos pela varredura.
Os dados neste teste foram apresentados em uma ordem particularmente inútil para empilhamento devido ao índice agrupado de árvore b original na coluna
c1 . Quando apresentados desta forma, os valores na coluna c2 começam em 0 e incrementam em 1 até atingirem 1.023, então iniciam o ciclo novamente. Os 1.023 valores distintos são mais do que suficientes para garantir que cada lote de saída de 900 linhas contenha apenas uma linha parcialmente agregada para cada chave. Este não é um estado feliz. Se houvesse 64 duplicatas por valor em vez de 63, o SQL Server teria considerado a classificação por
c2 ao construir o índice columnstore e, assim, produziu a compactação RLE. Como está, a penalidade de 22% entra em ação após cada lote. Começando em 100 e usando a mesma aritmética inteira de arredondamento, a sequência de valores de métrica é:-- @metric :=FLOOR(@metric * 0,78 + 0,5);-- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
O décimo primeiro lote reduz a métrica para 10 ou menos e o empilhamento é desabilitado. Os 11 lotes de 900 linhas representam as 9.900 linhas agregadas localmente mostradas no plano de execução.
Variação com 900 valores distintos
O mesmo comportamento pode ser visto no teste 4 com apenas 901 valores distintos, supondo que as linhas sejam apresentadas na mesma ordem inútil.
Alterando os
@values parâmetro para 900, mantendo todo o resto igual, tem um efeito dramático no plano de execução: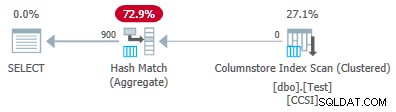
Agora todos os 900 grupos são agregados na varredura! As propriedades do plano xml mostram
ActualLocallyAggregatedRows="56700" . Isso porque o empilhamento agregado agrupado mantém 900 chaves de agrupamento e agregações parciais em um único lote. Ele nunca encontra um novo valor de chave fora do lote, portanto, não há motivo para iniciar um novo lote de saída. A produção de apenas um lote significa que o mecanismo de feedback nunca tem chance de reduzir a “medida de benefício de pushdown” até o ponto em que o pushdown agregado agrupado é desabilitado. De qualquer forma, nunca aconteceria, já que o pushdown é muito bem-sucedido — 56.700 linhas para 900 chaves de agrupamento são 63 por chave, bem acima do limite para redução da medida de benefício.
Evento Estendido
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named
query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel. It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Observação: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.