Introdução
Atualmente, a alta disponibilidade é um requisito para muitos sistemas, independentemente da tecnologia que você está usando. Isso é especialmente importante para bancos de dados, pois eles armazenam dados dos quais aplicativos e sistemas críticos dependem. A estratégia mais comum para obter alta disponibilidade é a replicação. Existem diferentes maneiras de replicar dados em vários servidores e tráfego de failover quando, por exemplo, um servidor primário para de responder.
Arquitetura de alta disponibilidade para PostgreSQL
Existem várias arquiteturas para implementação de alta disponibilidade no PostgreSQL, mas as básicas são as arquiteturas Primary-Standby e Primary-Primary.
Arquiteturas de espera primária
Primary-Standby pode ser a arquitetura de HA mais básica que você pode configurar e, muitas vezes, a mais fácil de implementar e manter. É baseado em um banco de dados primário com um ou mais servidores Standby. Esses bancos de dados Standby permanecerão sincronizados (ou quase sincronizados) com o nó Primário, dependendo se a replicação for síncrona ou assíncrona. Se o servidor Primário falhar, o servidor Standby contém quase todos os dados do servidor Primário e pode ser rapidamente transformado no novo servidor de banco de dados Primário.
Você pode implementar dois tipos de bancos de dados Standby, com base na natureza da replicação:
- Lógica de espera – A replicação entre Primária e Espera é feita por meio de instruções SQL.
- Standbys Físicos – A replicação entre Primário e Standby é feita por meio de modificações internas na estrutura de dados.
No caso do PostgreSQL, um fluxo de registros de log write-ahead (WAL) é usado para manter os bancos de dados Standby sincronizados. Isso pode ser síncrono ou assíncrono, e todo o servidor de banco de dados é replicado.
A partir da versão 10, o PostgreSQL inclui uma opção embutida para configurar a replicação lógica, que constrói um fluxo de modificações de dados lógicos a partir das informações do log write-ahead. Esse método de replicação permite que as alterações de dados de tabelas individuais sejam replicadas sem a necessidade de designar um servidor Primário. Também permite que os dados fluam em várias direções.
Infelizmente, uma configuração de espera primária não é suficiente para garantir efetivamente a alta disponibilidade, pois você também precisa lidar com falhas. Para lidar com falhas, você precisa ser capaz de detectá-las. Depois de saber que há uma falha, por exemplo, erros no nó Primário ou o nó que não está respondendo, você pode selecionar um nó em espera para substituir o nó com falha com o menor atraso possível. Esse processo deve ser o mais eficiente possível para restaurar a funcionalidade completa dos aplicativos. O próprio PostgreSQL não inclui um mecanismo de failover automático, portanto, isso exigirá algum script personalizado ou ferramentas de terceiros para essa automação.
Após ocorrer um failover, seu aplicativo precisa ser notificado adequadamente para começar a usar o novo Primário. Você também precisa avaliar o estado de sua arquitetura após o failover porque pode se deparar com uma situação em que apenas o novo primário está em execução (por exemplo, você tinha um nó primário e apenas um Standby antes do problema). Nesse caso, você precisará adicionar um nó Standby para recriar a configuração Primary-Standby que você tinha originalmente para alta disponibilidade.
Arquiteturas primárias-primárias
A arquitetura primária-primária fornece uma maneira de minimizar o impacto de um erro em um dos nós, pois os outros nós podem cuidar de todo o tráfego, afetando apenas ligeiramente o desempenho mas nunca perdendo a funcionalidade. A arquitetura primária-primária é frequentemente usada com o duplo propósito de criar um ambiente de alta disponibilidade e dimensionar horizontalmente (em comparação com o conceito de escalabilidade vertical onde você adiciona mais recursos a um servidor).
O PostgreSQL ainda não suporta essa arquitetura "nativamente", então você terá que consultar ferramentas e implementações de terceiros. Ao escolher uma solução, você deve ter em mente que existem muitos projetos/ferramentas, mas alguns deles não são mais suportados, enquanto outros são novos e podem não ser testados em produção.
Balanceamento de carga
Os balanceadores de carga são ferramentas que podem ser usadas para gerenciar o tráfego de seu aplicativo para obter o máximo de sua arquitetura de banco de dados.
Essas ferramentas não são apenas úteis para equilibrar a carga de seus bancos de dados, mas também ajudam os aplicativos a serem redirecionados para os nós disponíveis/saudáveis e até mesmo especificar portas com funções diferentes.
HAProxy é um balanceador de carga que distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para esta tarefa. Se algum dos destinos parar de responder, eles serão marcados como off-line e o tráfego será enviado para o restante dos destinos disponíveis.
Keepalived é um serviço que permite configurar um endereço IP virtual dentro de um grupo ativo/passivo de servidores. Este endereço IP virtual é atribuído a um servidor ativo. Caso este servidor falhe, o endereço IP é migrado automaticamente para o servidor passivo “Secundário”, permitindo que ele continue trabalhando com o mesmo endereço IP de forma transparente para os sistemas.
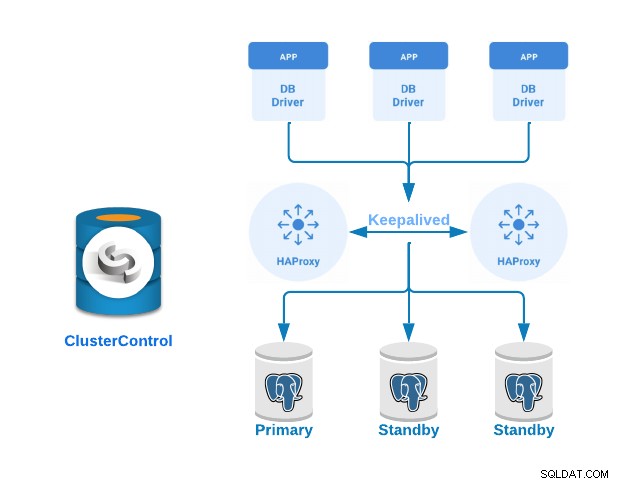
Vamos ver agora como implementar um cluster PostgreSQL Primary-Standby com servidores load balancer e keepalived configurados entre eles. Vamos demonstrar isso usando a interface fácil de usar do ClusterControl.
Para este exemplo, criaremos:
- 3 servidores PostgreSQL (um primário e dois em espera).
- 2 balanceadores de carga HAProxy.
- Mantido configurado entre os servidores do balanceador de carga.
Implantação de banco de dados
Para implantar um banco de dados usando o ClusterControl, basta selecionar a opção “Deploy” e seguir as instruções que aparecem.
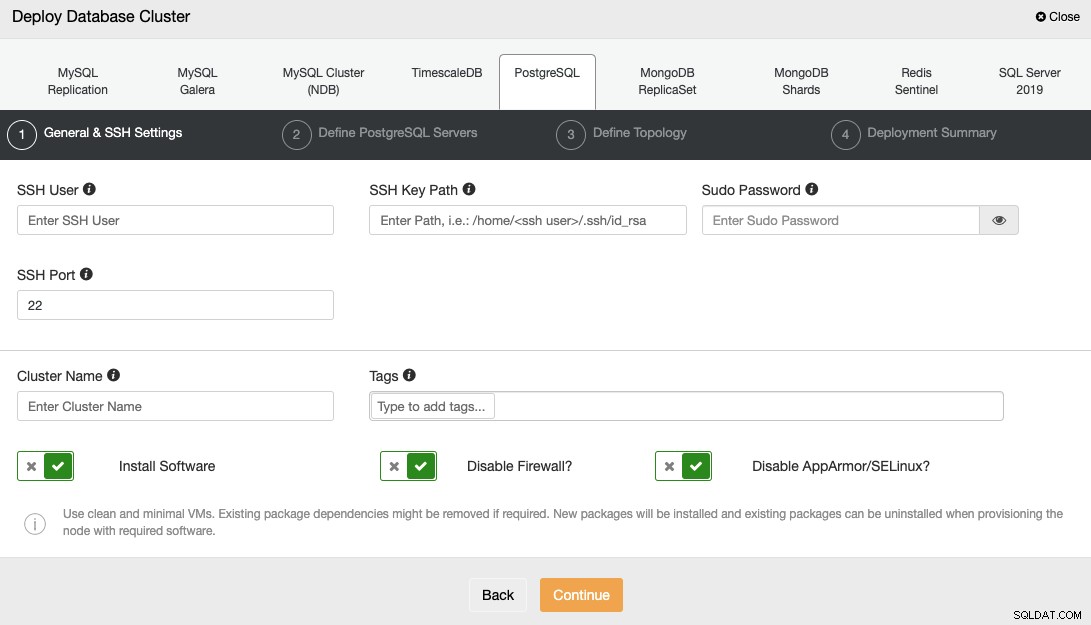
Ao selecionar PostgreSQL, você deve especificar o Usuário, Chave ou Senha e Porta para conectar por SSH aos seus servidores. Você também precisa do nome do seu novo cluster e escolha se deseja que o ClusterControl instale o software e as configurações correspondentes para você.
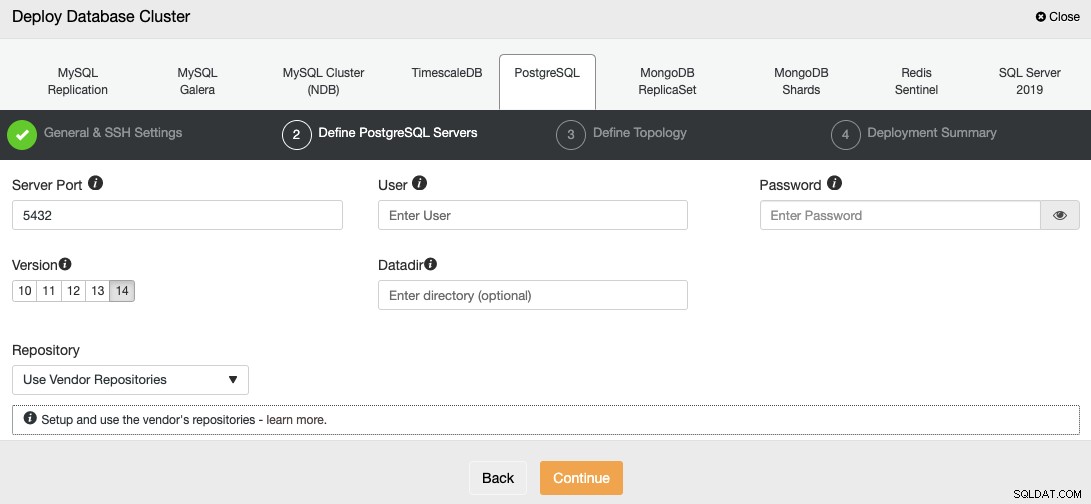
Após configurar as informações de acesso SSH, você deve definir o usuário do banco de dados, versão e datadir (opcional). Você também pode especificar qual repositório usar; o repositório oficial do fornecedor será usado por padrão.
Na próxima etapa, você precisa adicionar seus servidores ao cluster que você criará.
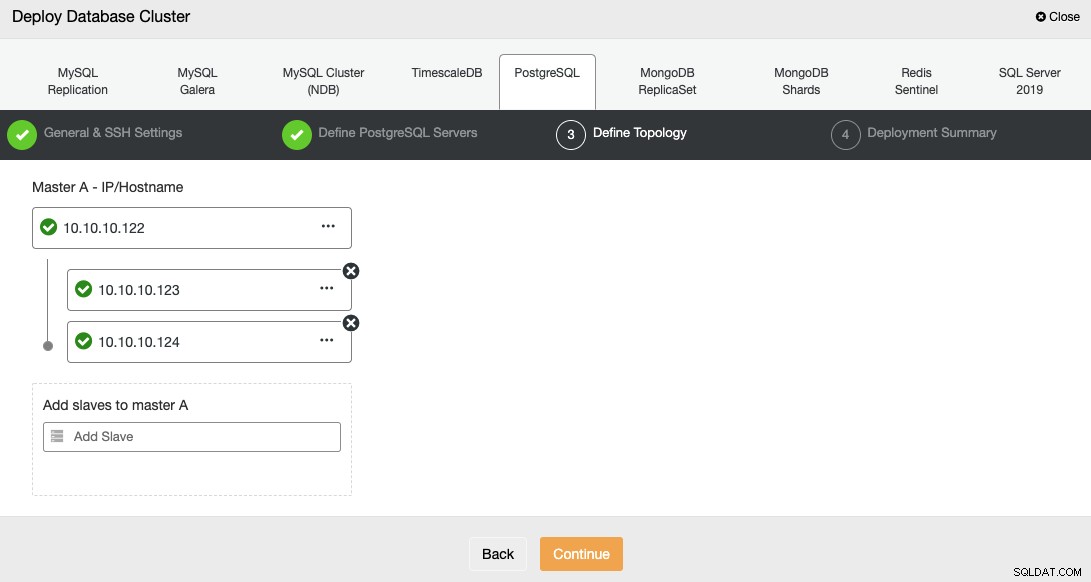
Ao adicionar seus servidores, você pode inserir o IP ou o nome do host.
Na última etapa, você pode escolher se sua replicação será síncrona ou assíncrona.
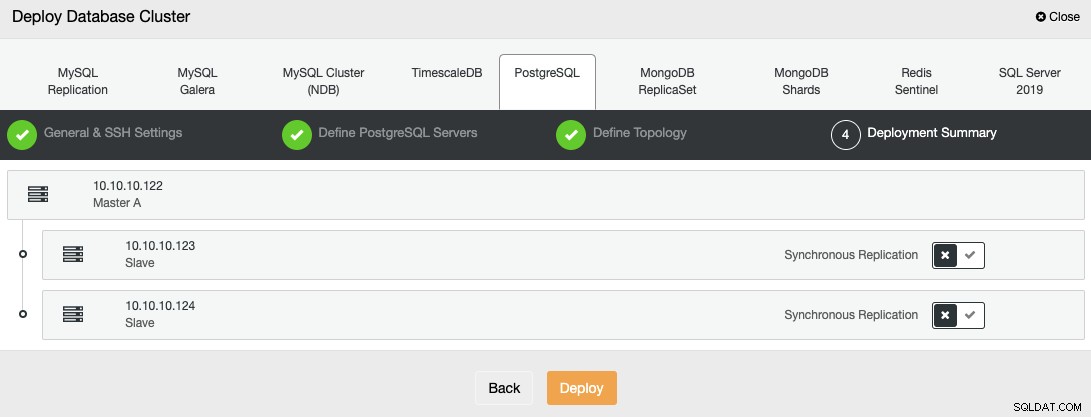
Você pode monitorar o status da criação de seu novo cluster no ClusterControl monitor de atividade.
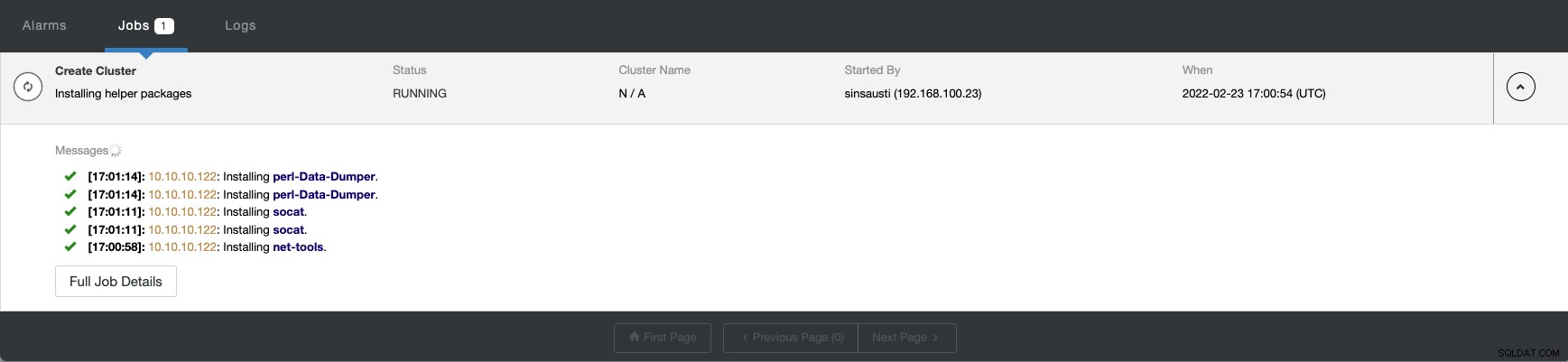
Quando a tarefa for concluída, você poderá ver seu cluster no ClusterControl principal tela.
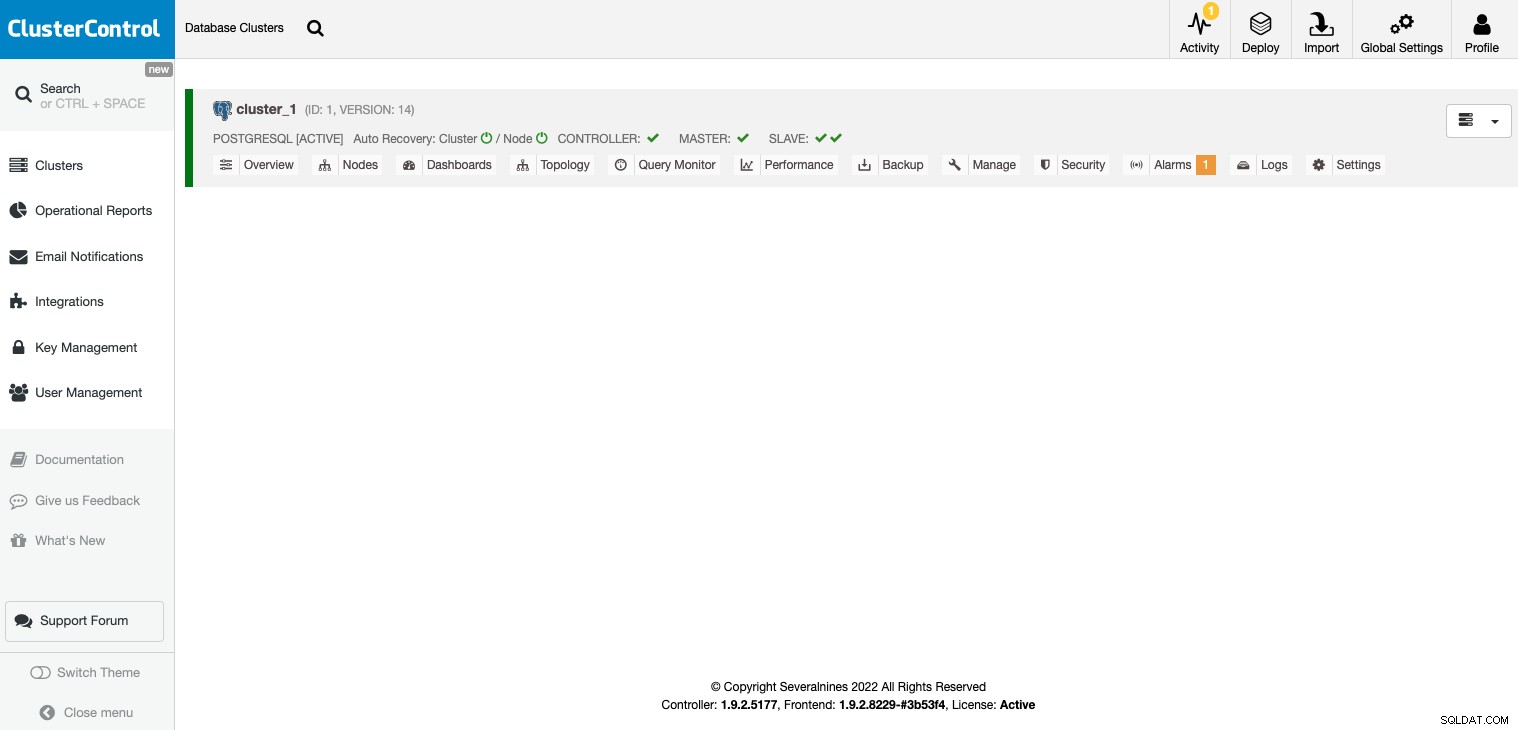
Depois que seu cluster for criado, você poderá executar várias tarefas, como adicionar um balanceador de carga (HAProxy) ou uma nova réplica.
Implantação do balanceador de carga
Para realizar uma implantação do balanceador de carga, selecione a opção “Adicionar balanceador de carga” nas ações do cluster e preencha as informações solicitadas.
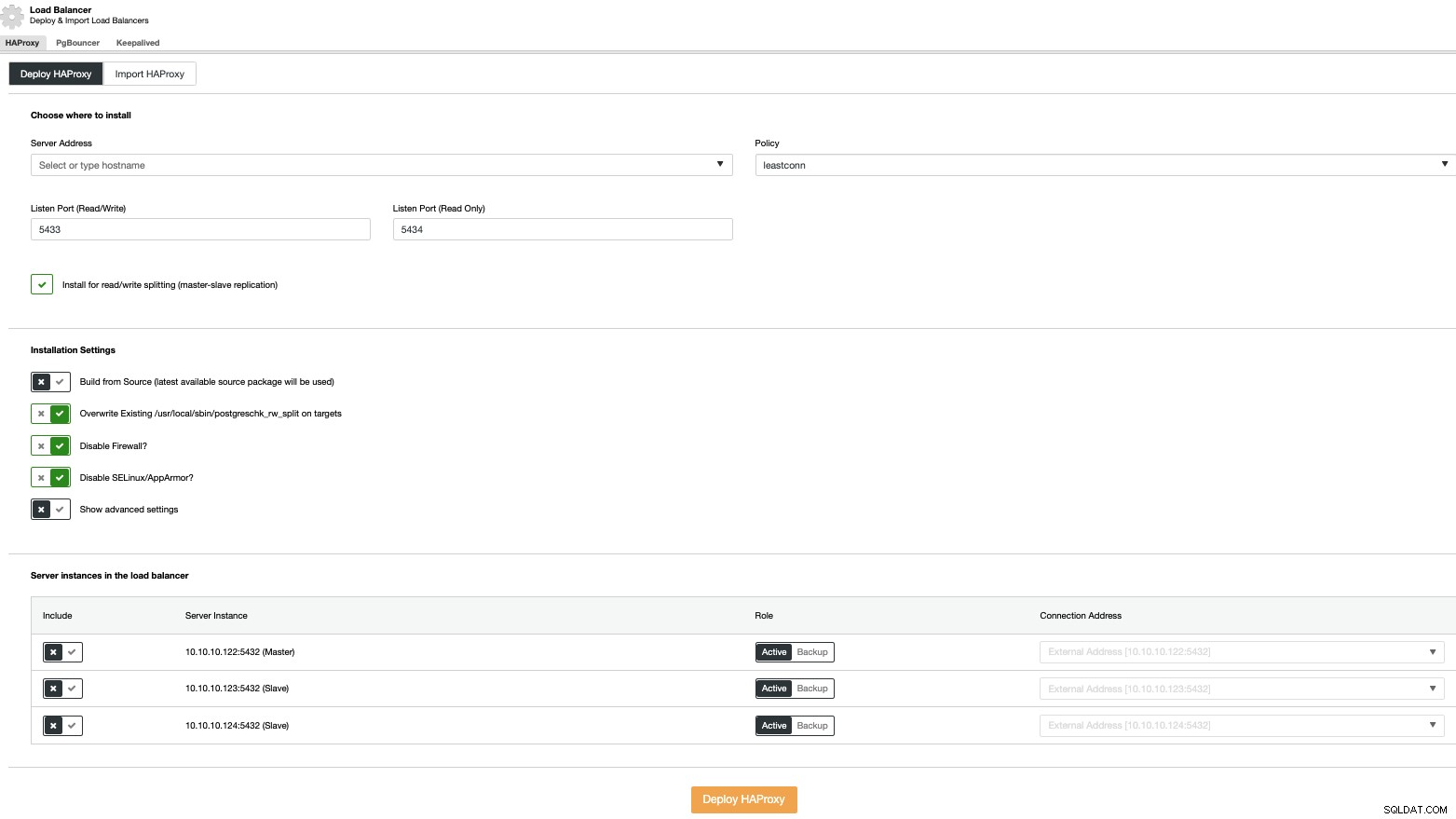
Você só precisa adicionar o endereço IP ou nome de host, porta, política, e os nós que você configurará em seus balanceadores de carga.
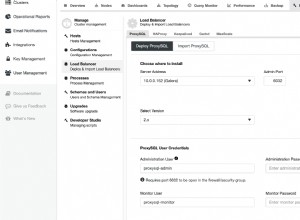
Implantação mantida
Para realizar uma implantação keepalived, selecione o cluster, acesse o menu "Gerenciar" e a seção "Load Balancer" e selecione a opção "Keepalived".
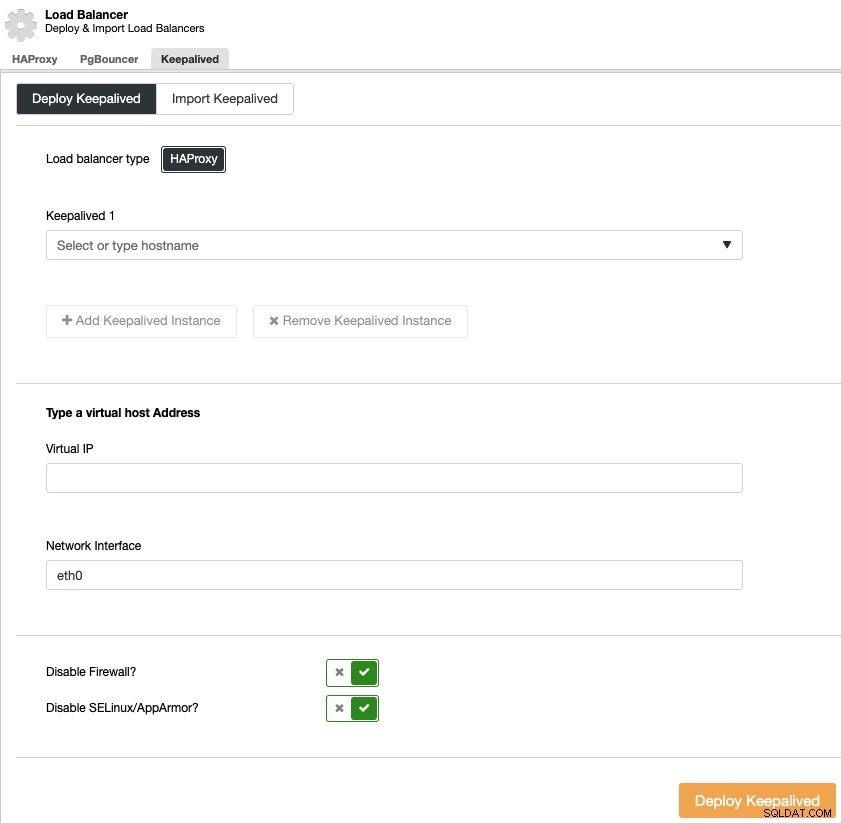
Você deve selecionar os servidores do balanceador de carga e o endereço IP virtual para seu alto ambiente de disponibilidade.
O Keepalived usa o endereço IP virtual e o migra de um balanceador de carga para outro em caso de falha, para que seus sistemas possam continuar funcionando normalmente.
Se você seguiu as etapas anteriores, deve ter a seguinte topologia:
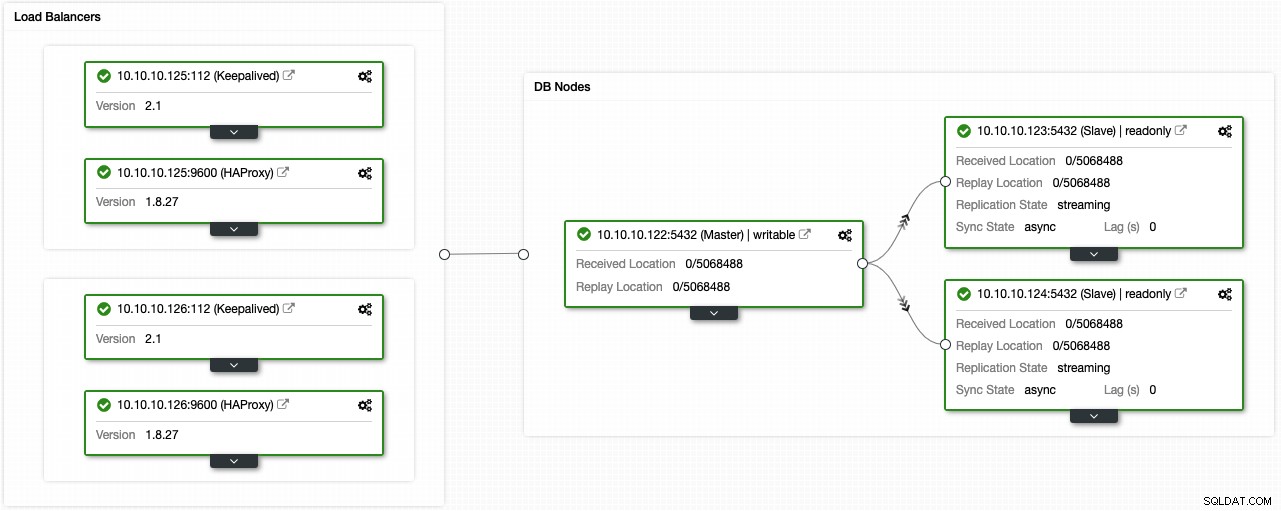
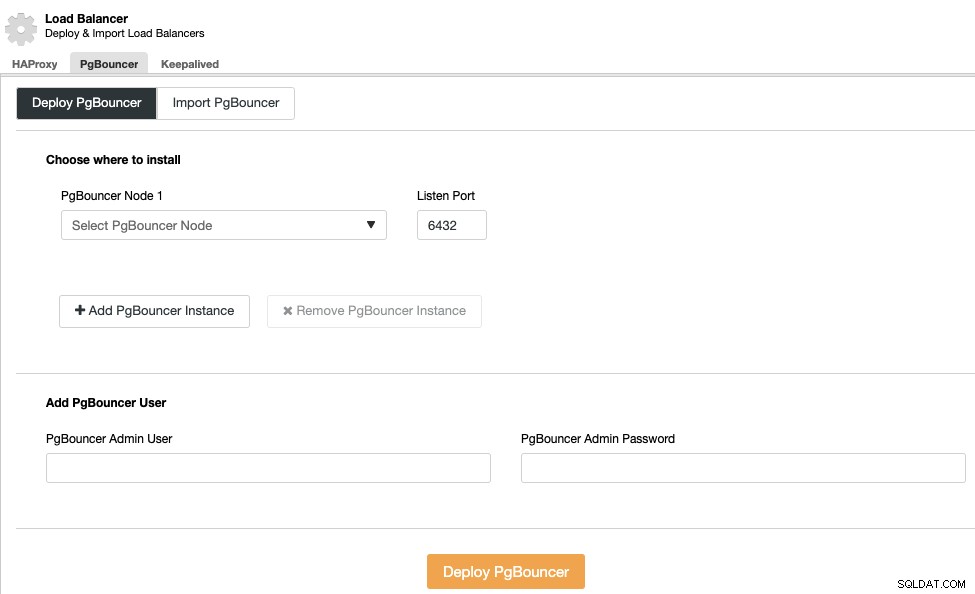
Você pode melhorar esse ambiente de alta disponibilidade adicionando um pool de conexões como o PgBouncer. Não é obrigatório, mas pode ser útil para melhorar o desempenho e lidar com conexões ativas em caso de falha, e o melhor é que você também pode implantá-lo usando o ClusterControl.
Failover de controle de cluster
Suponha que a opção “Autorecovery” esteja ATIVADA em seu servidor ClusterControl. Em caso de falha do Primário, o ClusterControl promoverá o Standby mais avançado (se não estiver na lista negra) para o Primário, além de notificá-lo sobre o problema. Ele também fará o failover do restante dos nós Standby para replicar do novo Primary.
O HAProxy é configurado por padrão com duas portas diferentes; portas de leitura-gravação e somente leitura.
Na porta de leitura e gravação, você tem o servidor Primário como online e o restante de seus nós como offline, e na porta somente leitura, você tem o Primário e os Standbys online.
Quando o HAProxy detecta que um de seus nós, primário ou em espera, não está acessível, ele o marca automaticamente como offline. Ele não leva em consideração para enviar tráfego para ele. A detecção é realizada por scripts de verificação de integridade que o ClusterControl configura no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Quando o ClusterControl promove um Standby para Primary, seu HAProxy marca o antigo Primary como offline para ambas as portas e coloca o nó promovido online na porta de leitura/gravação.
Se seu HAProxy ativo, que atribuiu o endereço IP virtual ao qual seus sistemas se conectam, falhar, o Keepalived migra esse endereço IP para seu HAProxy passivo automaticamente. Isso significa que seus sistemas podem continuar a funcionar normalmente.
Dessa forma, seus sistemas continuam operando conforme o esperado e sem sua intervenção manual.
Considerações
Se você conseguir recuperar seu antigo nó Primário com falha, ele NÃO será reintroduzido automaticamente no cluster por padrão. Você precisa fazer isso manualmente. Uma razão para isso é que, se sua réplica estivesse atrasada no momento da falha e o ClusterControl adicionasse o Primário antigo ao cluster, isso significaria perda de informações ou inconsistência de dados nos nós. Você também pode querer analisar o problema em detalhes. Se o ClusterControl apenas reintroduzir o nó com falha no cluster, você possivelmente perderá as informações de diagnóstico.
Além disso, se o failover falhar, nenhuma outra tentativa será feita. A intervenção manual é necessária para analisar o problema e realizar as ações correspondentes. Isso é para evitar a situação em que o ClusterControl, como o gerenciador de alta disponibilidade, tenta promover o próximo Standby e o próximo. Pode haver um problema, e você precisará verificar isso.
Segurança
Uma coisa importante que você não pode esquecer antes de entrar em produção com seu ambiente de alta disponibilidade é garantir sua segurança.
Vários aspectos de segurança a serem considerados incluem criptografia, gerenciamento de funções e restrição de acesso por endereço IP, que abordamos detalhadamente em um blog anterior.
Em seu banco de dados PostgreSQL, você tem o arquivo pg_hba.conf, que trata da autenticação do cliente. Você pode limitar o tipo de conexão, o endereço IP de origem ou a rede, a qual banco de dados você pode se conectar e com quais usuários. Portanto, este arquivo é uma peça crítica para a segurança do PostgreSQL.
Você pode configurar seu banco de dados PostgreSQL a partir do arquivo postgresql.conf, para que ele escute apenas em uma interface de rede específica e em uma porta diferente da padrão (5432), evitando assim tentativas básicas de conexão de fontes indesejadas .
O gerenciamento adequado de usuários, seja usando senhas seguras ou limitando acesso e privilégios, é outra parte vital de suas configurações de segurança. É recomendável atribuir o mínimo de privilégios possível a todos os usuários e especificar, se possível, a origem da conexão.
Você também pode habilitar a criptografia de dados, seja em trânsito ou em repouso, evitando o acesso às informações a pessoas não autorizadas.
Um log de auditoria é útil para entender o que está acontecendo ou aconteceu em seu banco de dados. O PostgreSQL permite configurar diversos parâmetros para logging ou até mesmo utilizar a extensão pgAudit para esta tarefa.
Por último, mas não menos importante, é recomendável manter seu banco de dados e servidores atualizados com os patches mais recentes para evitar riscos de segurança. Para isso, o ClusterControl permite gerar relatórios operacionais para verificar se você tem atualizações disponíveis e até mesmo ajudá-lo a atualizar seus servidores de banco de dados.
Conclusão
As implantações de alta disponibilidade podem parecer difíceis de alcançar, principalmente quando se trata de entender as diferentes arquiteturas e os componentes necessários para configurá-los corretamente.
Se você estiver gerenciando HA manualmente, não deixe de conferir Performing Replication Topology Changes for PostgreSQL. Muitos procurarão ferramentas como o ClusterControl para ajudar a gerenciar a implantação, balanceadores de carga, failover, segurança e muito mais para obter um ambiente completo de alta disponibilidade. Você pode baixar o ClusterControl gratuitamente por 30 dias para ver como ele pode aliviar a carga de gerenciamento de uma infraestrutura de banco de dados de alta disponibilidade.
No entanto, você escolhe gerenciar seus bancos de dados PostgreSQL de alta disponibilidade, siga-nos no Twitter ou LinkedIn ou assine nosso boletim informativo para obter as atualizações mais recentes e as melhores práticas para gerenciar suas configurações de banco de dados.