Este artigo é o segundo de uma série sobre bugs, armadilhas e práticas recomendadas do T-SQL. Desta vez, concentro-me em bugs clássicos envolvendo subconsultas. Particularmente, abordo erros de substituição e problemas de lógica de três valores. Vários dos tópicos que abordo na série foram sugeridos por colegas MVPs em uma discussão que tivemos sobre o assunto. Obrigado a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man e Paul White por suas sugestões!
Erro de substituição
Para demonstrar o erro de substituição clássico, usarei um cenário simples de pedidos de clientes. Execute o seguinte código para criar uma função auxiliar chamada GetNums e para criar e preencher as tabelas Customers e Orders:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Atualmente, a tabela Clientes tem 100 clientes com IDs de clientes consecutivos no intervalo de 1 a 100. 98 desses clientes têm pedidos correspondentes na tabela Pedidos. Os clientes com IDs 17 e 59 ainda não fizeram nenhum pedido e, portanto, não têm presença na tabela Pedidos.
Você está atrás apenas de clientes que fizeram pedidos e tenta fazer isso usando a seguinte consulta (chame-a de Consulta 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Você deveria ter 98 clientes de volta, mas em vez disso você consegue todos os 100 clientes, incluindo aqueles com IDs 17 e 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Você consegue descobrir o que está errado?
Para aumentar a confusão, examine o plano para a Consulta 1, conforme mostrado na Figura 1.
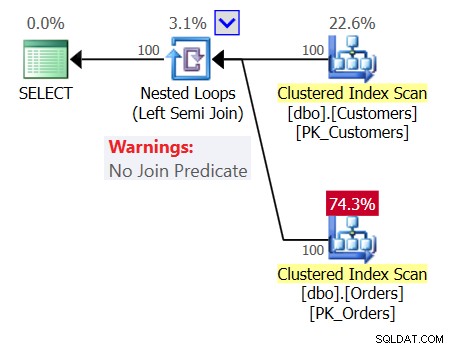 Figura 1:plano para consulta 1
Figura 1:plano para consulta 1 O plano mostra um operador Nested Loops (Left Semi Join) sem predicado de junção, o que significa que a única condição para retornar um cliente é ter uma tabela Orders não vazia, como se a consulta que você escreveu fosse a seguinte:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Você provavelmente esperava um plano semelhante ao mostrado na Figura 2.
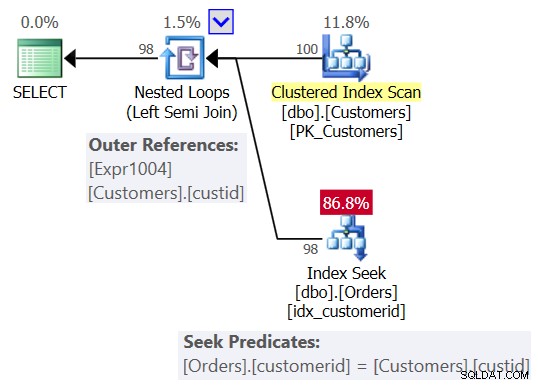 Figura 2:plano esperado para a consulta 1
Figura 2:plano esperado para a consulta 1 Neste plano, você vê um operador Nested Loops (Left Semi Join), com uma varredura do índice clusterizado em Customers como a entrada externa e uma busca no índice na coluna customerid em Orders como a entrada interna. Você também vê uma referência externa (parâmetro correlacionado) com base na coluna custid em Customers e o predicado de busca Orders.customerid =Customers.custid.
Então, por que você está obtendo o plano da Figura 1 e não o da Figura 2? Se você ainda não descobriu, observe atentamente as definições de ambas as tabelas – especificamente os nomes das colunas – e os nomes das colunas usados na consulta. Você notará que a tabela Clientes contém IDs de clientes em uma coluna chamada custid e que a tabela Pedidos contém IDs de clientes em uma coluna chamada customerid. No entanto, o código usa custid nas consultas externas e internas. Como a referência a custid na consulta interna não é qualificada, o SQL Server precisa resolver de qual tabela a coluna está vindo. De acordo com o padrão SQL, o SQL Server deve procurar primeiro a coluna na tabela que é consultada no mesmo escopo, mas como não há uma coluna chamada custid em Orders, ele deve procurá-la na tabela na parte externa escopo, e desta vez há uma correspondência. Então, sem querer, a referência a custid se torna implicitamente uma referência correlacionada, como se você escrevesse a seguinte consulta:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Desde que Orders não esteja vazio e que o valor custid externo não seja NULL (não pode ser no nosso caso, pois a coluna é definida como NOT NULL), você sempre obterá uma correspondência porque compara o valor com ele mesmo . Então a Consulta 1 se torna o equivalente a:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Se a tabela externa suportasse NULLs na coluna custid, a Consulta 1 seria equivalente a:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Agora você entende por que a Consulta 1 foi otimizada com o plano da Figura 1 e por que você conseguiu todos os 100 clientes de volta.
Algum tempo atrás, visitei um cliente que tinha um bug semelhante, mas infelizmente com uma declaração DELETE. Pense por um momento o que isso significa. Todas as linhas da tabela foram apagadas e não apenas aquelas que originalmente pretendiam excluir!
Quanto às melhores práticas que podem ajudá-lo a evitar esses bugs, existem duas principais. Primeiro, por mais que você possa controlá-lo, certifique-se de usar nomes de colunas consistentes nas tabelas para atributos que representam a mesma coisa. Em segundo lugar, certifique-se de que você tabela as referências de coluna qualificadas em subconsultas, inclusive nas autocontidas, onde isso não é uma prática comum. Claro, você pode usar alias de tabela se preferir não usar nomes de tabela completos. Aplicando essa prática à nossa consulta, suponha que sua tentativa inicial tenha usado o seguinte código:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Aqui você não está permitindo a resolução implícita do nome da coluna e, portanto, o SQL Server gera o seguinte erro:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Você verifica os metadados da tabela Orders, percebe que usou o nome de coluna errado e corrige a consulta (chame isso de Consulta 2), assim:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Desta vez, você obtém a saída certa com 98 clientes, excluindo os clientes com IDs 17 e 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Você também obtém o plano esperado mostrado anteriormente na Figura 2.
Além disso, está claro por que Customers.custid é uma referência externa (parâmetro correlacionado) no operador Nested Loops (Left Semi Join) na Figura 2. O que é menos óbvio é por que Expr1004 também aparece no plano como uma referência externa. O colega MVP do SQL Server, Paul White, teoriza que isso pode estar relacionado ao uso de informações da folha de entrada externa para sugerir o mecanismo de armazenamento para evitar esforço duplicado pelos mecanismos de leitura antecipada. Você pode encontrar os detalhes aqui.
Problema de lógica de três valores
Um bug comum envolvendo subconsultas tem a ver com casos em que a consulta externa usa o predicado NOT IN e a subconsulta pode potencialmente retornar NULLs entre seus valores. Por exemplo, suponha que você precise armazenar pedidos em nossa tabela Pedidos com um NULL como o ID do cliente. Tal caso representaria um pedido que não está associado a nenhum cliente; por exemplo, um pedido que compensa inconsistências entre as contagens reais de produtos e as contagens registradas no banco de dados.
Use o código a seguir para recriar a tabela Orders com a coluna custid permitindo NULLs e, por enquanto, preencha-a com os mesmos dados de amostra como antes (com pedidos por IDs de cliente de 1 a 100, excluindo 17 e 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Observe que, enquanto estamos nisso, segui a prática recomendada discutida na seção anterior para usar nomes de coluna consistentes nas tabelas para os mesmos atributos e nomeei a coluna na tabela Orders custid assim como na tabela Customers.
Suponha que você precise escrever uma consulta que retorne clientes que não fizeram pedidos. Você apresenta a seguinte solução simplista usando o predicado NOT IN (chame-o de Consulta 3, primeira execução):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Esta consulta retorna a saída esperada com os clientes 17 e 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
É feito um inventário no almoxarifado da empresa e é constatada uma inconsistência entre a quantidade real de algum produto e a quantidade registrada no banco de dados. Então, você adiciona uma ordem de compensação fictícia para explicar a inconsistência. Como não há um cliente real associado ao pedido, você usa um NULL como o ID do cliente. Execute o seguinte código para adicionar esse cabeçalho de pedido:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Execute a Consulta 3 pela segunda vez:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Desta vez, você obtém um resultado vazio:
custid companyname ------- ------------ (0 rows affected)
Claramente, algo está errado. Você sabe que os clientes 17 e 59 não fizeram nenhum pedido e, de fato, eles aparecem na tabela Clientes, mas não na tabela Pedidos. No entanto, o resultado da consulta afirma que não há cliente que não tenha feito nenhum pedido. Você consegue descobrir onde está o bug e como corrigi-lo?
O bug tem a ver com o NULL na tabela Orders, é claro. Para SQL, um NULL é um marcador para um valor ausente que pode representar um cliente aplicável. O SQL não sabe que para nós o NULL representa um cliente ausente e inaplicável (irrelevante). Para todos os clientes na tabela Customers que estão presentes na tabela Orders, o predicado IN encontra uma correspondência que resulta em TRUE e a parte NOT IN a torna FALSE, portanto, a linha do cliente é descartada. Até agora tudo bem. Mas para os clientes 17 e 59, o predicado IN gera UNKNOWN, pois todas as comparações com valores não NULL geram FALSE, e a comparação com o NULL gera UNKNOWN. Lembre-se, o SQL pressupõe que o NULL pode representar qualquer cliente aplicável, portanto, o valor lógico UNKNOWN indica que não se sabe se o ID do cliente externo é igual ao ID do cliente NULL interno. FALSO OU FALSO… OU DESCONHECIDO é DESCONHECIDO. Então a parte NOT IN aplicada a UNKNOWN ainda produz UNKNOWN.
Em termos mais simples em inglês, você pediu para retornar clientes que não fizeram pedidos. Então, naturalmente, a consulta descarta todos os clientes da tabela Clientes que estão presentes na tabela Pedidos porque é conhecido com certeza que eles fizeram pedidos. Quanto ao resto (17 e 59 no nosso caso) a consulta os descarta desde o SQL, assim como não se sabe se fizeram pedidos, não se sabe se não fizeram pedidos, e o filtro precisa de certeza (TRUE) em ordem para retornar uma linha. Que picanha!
Portanto, assim que o primeiro NULL entrar na tabela Orders, a partir desse momento você sempre obterá um resultado vazio da consulta NOT IN. E os casos em que você realmente não tem NULLs nos dados, mas a coluna permite NULLs? Como você viu na primeira execução da Consulta 3, nesse caso você obtém o resultado correto. Talvez você esteja pensando que o aplicativo nunca introduzirá NULLs nos dados, então não há nada para você se preocupar. Essa é uma prática ruim por alguns motivos. Por um lado, se uma coluna é definida como permitindo NULLs, é praticamente certo que os NULLs eventualmente chegarão lá, mesmo que não devam; É só uma questão de tempo. Pode ser o resultado da importação de dados incorretos, um bug no aplicativo e outros motivos. Por outro lado, mesmo que os dados não contenham NULLs, se a coluna permitir, o otimizador deve considerar a possibilidade de NULLs estarem presentes ao criar o plano de consulta e, em nossa consulta NOT IN, isso incorre em uma penalidade de desempenho . Para demonstrar isso, considere o plano para a primeira execução da Consulta 3 antes de adicionar a linha com o NULL, conforme mostrado na Figura 3.
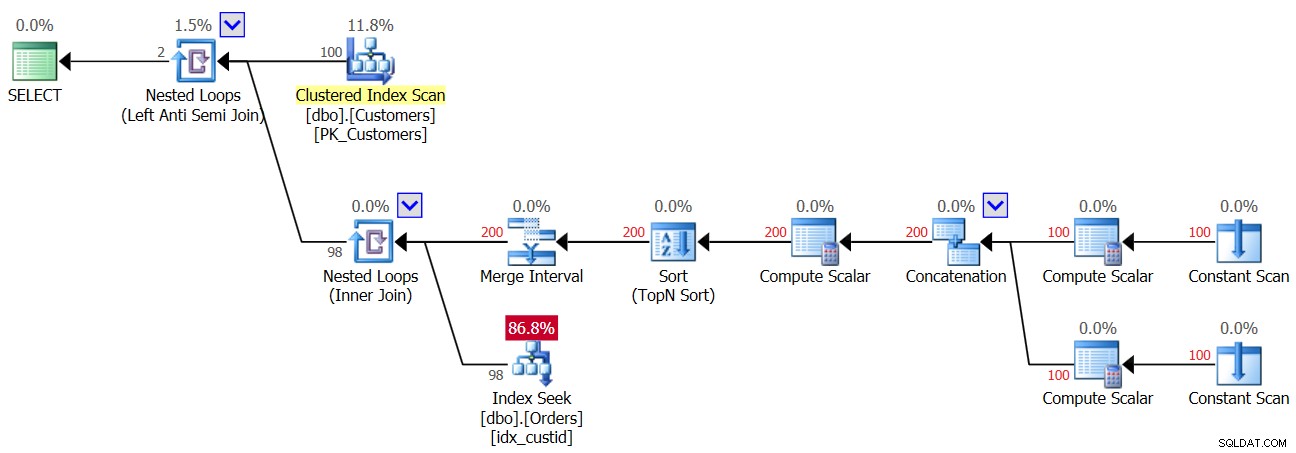 Figura 3:planejar a primeira execução da consulta 3
Figura 3:planejar a primeira execução da consulta 3 O operador de loops aninhados superior lida com a lógica Left Anti Semi Join. Trata-se essencialmente de identificar não correspondências e curto-circuitar a atividade interna assim que uma correspondência for encontrada. A parte externa do loop puxa todos os 100 clientes da tabela Customers, portanto, a parte interna do loop é executada 100 vezes.
A parte interna do loop superior executa um operador Nested Loops (Inner Join). A parte externa do loop inferior cria duas linhas por cliente - uma para um caso NULL e outra para o ID do cliente atual, nesta ordem. Não deixe que o operador Merge Interval o confunda. É normalmente usado para mesclar intervalos sobrepostos, por exemplo, um predicado como col1 BETWEEN 20 AND 30 OR col1 BETWEEN 25 AND 35 é convertido em col1 BETWEEN 20 AND 35. Essa ideia pode ser generalizada para remover duplicatas em um predicado IN. No nosso caso, não pode haver duplicatas. Em termos simplificados, conforme mencionado, pense na parte externa do loop como criando duas linhas por cliente – a primeira para um caso NULL e a segunda para o ID do cliente atual. Em seguida, a parte interna do loop primeiro faz uma busca no índice idx_custid em Orders para procurar um NULL. Se um NULL for encontrado, ele não ativará a segunda busca pelo ID do cliente atual (lembre-se do curto-circuito tratado pelo loop Anti Semi Join superior). Nesse caso, o cliente externo é descartado. Mas se um NULL não for encontrado, o loop inferior ativa uma segunda busca para procurar o ID do cliente atual em Pedidos. Se for encontrado, o cliente externo é descartado. Se não for encontrado, o cliente externo é devolvido. O que isso significa é que quando NULLs não estão presentes nos Pedidos, este plano realiza duas buscas por cliente! Isso pode ser observado no plano como o número de linhas 200 na entrada externa do loop inferior. Consequentemente, aqui estão as estatísticas de E/S relatadas para a primeira execução:
Table 'Orders'. Scan count 200, logical reads 603
O plano para a segunda execução da Consulta 3, após a adição de uma linha com NULL à tabela Orders, é mostrado na Figura 4.
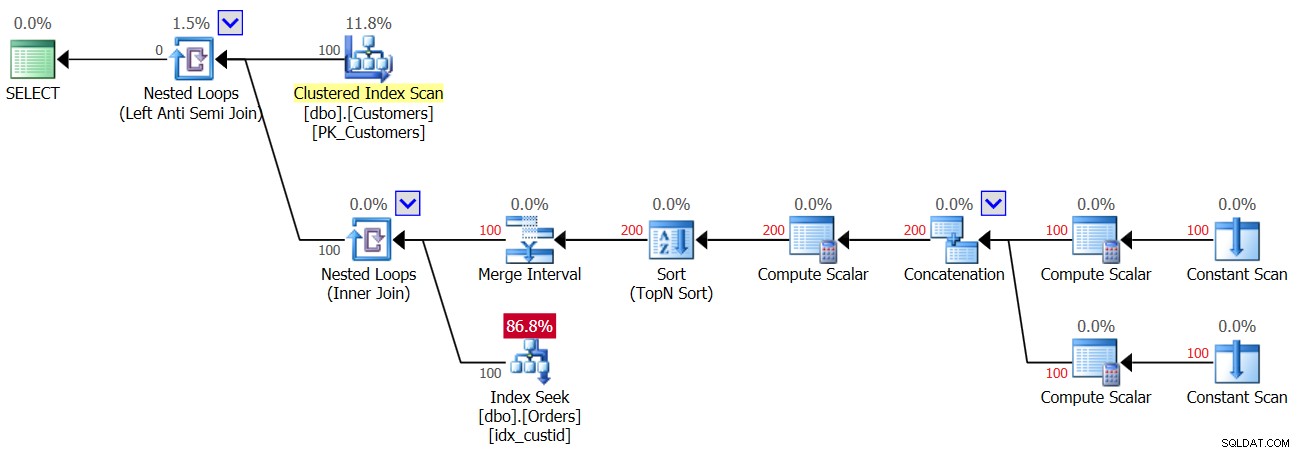 Figura 4:planejar a segunda execução da consulta 3
Figura 4:planejar a segunda execução da consulta 3 Como um NULL está presente na tabela, para todos os clientes, a primeira execução do operador Index Seek encontra uma correspondência e, portanto, todos os clientes são descartados. Então yay, fazemos apenas uma busca por cliente e não duas, então desta vez você recebe 100 buscas e não 200; no entanto, ao mesmo tempo, isso significa que você está recebendo um resultado vazio!
Aqui estão as estatísticas de E/S relatadas para a segunda execução:
Table 'Orders'. Scan count 100, logical reads 300
Uma solução para essa tarefa quando NULLs são possíveis entre os valores retornados na subconsulta é simplesmente filtrá-los, assim (chame de Solução 1/Consulta 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Este código gera a saída esperada:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
A desvantagem desta solução é que você precisa se lembrar de adicionar o filtro. Eu prefiro uma solução usando o predicado NOT EXISTS, onde a subconsulta tem uma correlação explícita comparando o ID do cliente do pedido com o ID do cliente do cliente, assim (chame de Solução 2/Consulta 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Lembre-se de que uma comparação baseada em igualdade entre um NULL e qualquer coisa produz UNKNOWN, e UNKNOWN é descartado por um filtro WHERE. Portanto, se NULLs existirem em Orders, eles serão eliminados pelo filtro da consulta interna sem que você precise adicionar um tratamento NULL explícito e, portanto, você não precisa se preocupar se os NULLs existem ou não nos dados.
Esta consulta gera a saída esperada:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Os planos para ambas as soluções são mostrados na Figura 5.
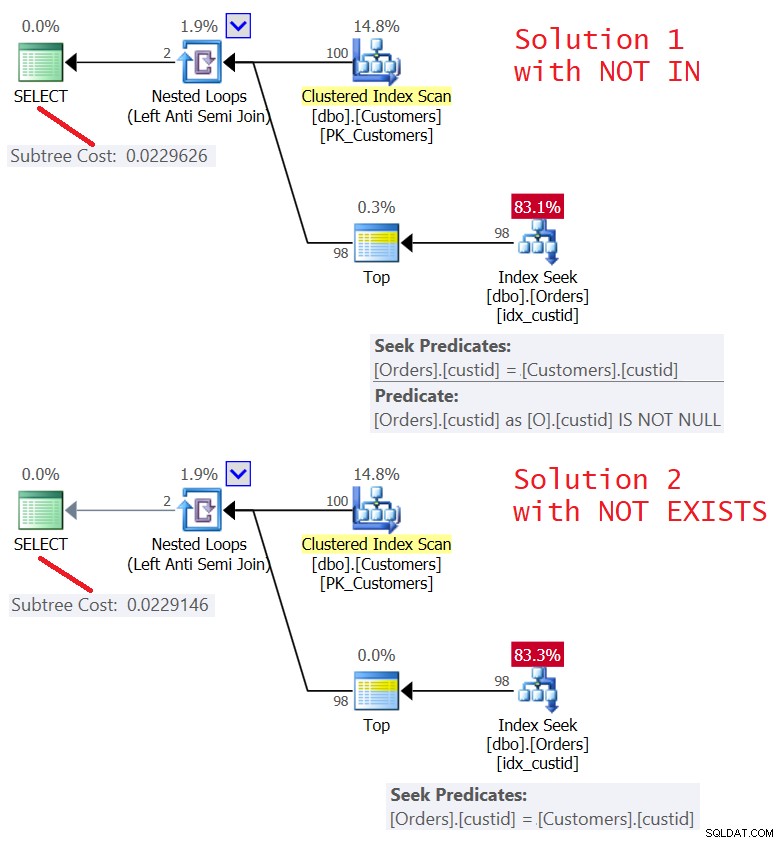 Figura 5:Planos para Consulta 4 (Solução 1) e Consulta 5 (Solução 2) )
Figura 5:Planos para Consulta 4 (Solução 1) e Consulta 5 (Solução 2) ) Como você pode ver, os planos são quase idênticos. Eles também são bastante eficientes, usando uma otimização Left Semi Join com um curto-circuito. Ambos realizam apenas 100 buscas no índice idx_custid em Orders, e com o operador Top, aplicam um curto-circuito após uma linha ser tocada na folha.
As estatísticas de E/S para ambas as consultas são as mesmas:
Table 'Orders'. Scan count 100, logical reads 348
Uma coisa a considerar é se há alguma chance de a tabela externa ter NULLs na coluna correlacionada (custid em nosso caso). Muito improvável que seja relevante em um cenário como pedidos de clientes, mas pode ser relevante em outros cenários. Se for esse o caso, ambas as soluções tratam um NULL externo incorretamente.
Para demonstrar isso, descarte e recrie a tabela Customers com um NULL como um dos IDs do cliente executando o seguinte código:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); A solução 1 não retornará um NULL externo, independentemente de um NULL interno estar presente ou não.
A solução 2 retornará um NULL externo, independentemente de um NULL interno estar presente ou não.
Se você deseja lidar com NULLs como lida com valores não NULL, ou seja, retornar o NULL se estiver presente em Customers, mas não em Orders, e não devolvê-lo se estiver presente em ambos, será necessário alterar a lógica da solução para usar uma distinção comparação baseada em igualdade em vez de uma comparação baseada em igualdade. Isso pode ser obtido combinando o predicado EXISTS e o operador EXCEPT set, assim (chame esta Solução 3/Consulta 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Como atualmente existem NULLs em Customers e Orders, essa consulta corretamente não retorna o NULL. Aqui está a saída da consulta:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Execute o seguinte código para remover a linha com o NULL da tabela Orders e execute novamente a Solução 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Desta vez, como um NULL está presente em Clientes, mas não em Pedidos, o resultado inclui o NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
O plano para esta solução é mostrado na Figura 6:
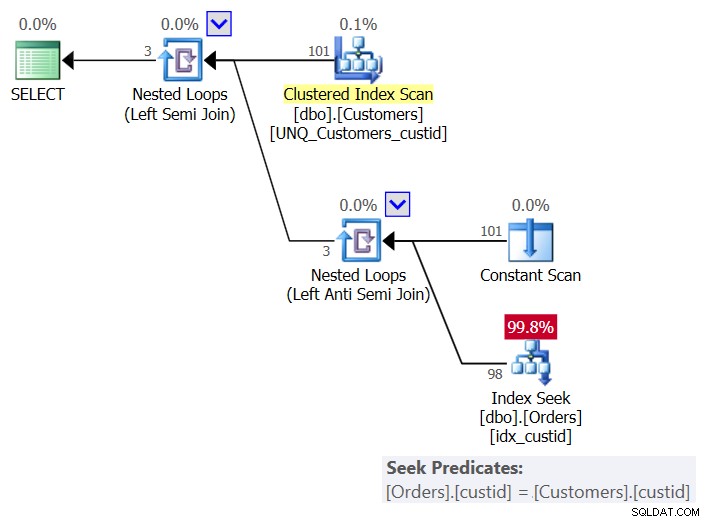 Figura 6:plano para a consulta 6 (solução 3)
Figura 6:plano para a consulta 6 (solução 3) Por cliente, o plano usa um operador Constant Scan para criar uma linha com o cliente atual e aplica uma única busca no índice idx_custid em Orders para verificar se o cliente existe em Orders. Você acaba com uma busca por cliente. Como atualmente temos 101 clientes na tabela, recebemos 101 buscas.
Aqui estão as estatísticas de E/S para esta consulta:
Table 'Orders'. Scan count 101, logical reads 415
Conclusão
Este mês, abordei bugs, armadilhas e práticas recomendadas relacionados a subconsultas. Cobri erros de substituição e problemas de lógica de três valores. Lembre-se de usar nomes de coluna consistentes nas tabelas e sempre qualificar colunas de tabela em subconsultas, mesmo quando elas são autocontidas. Lembre-se também de aplicar uma restrição NOT NULL quando a coluna não deve permitir NULLs e sempre levar NULLs em consideração quando forem possíveis em seus dados. Certifique-se de incluir NULLs em seus dados de amostra quando eles forem permitidos para que você possa detectar bugs mais facilmente em seu código ao testá-lo. Tenha cuidado com o predicado NOT IN quando combinado com subconsultas. Se NULLs forem possíveis no resultado da consulta interna, o predicado NOT EXISTS geralmente é a alternativa preferida.



