Muitas vezes vejo pessoas reclamando sobre como seu log de transações assumiu seu disco rígido. Muitas vezes acontece que eles estavam realizando uma grande operação de exclusão, como limpeza ou arquivamento de dados, em uma grande transação.
Eu queria executar alguns testes para mostrar o impacto, tanto na duração quanto no log de transações, de realizar a mesma operação de dados em partes versus uma única transação. Criei um banco de dados e o preenchi com uma tabela grande
SalesOrderDetailEnlarged ,Depois de preencher a tabela, fiz backup do banco de dados, backup do log e executei um
DBCC SHRINKFILE (não atire em mim) para que o impacto no arquivo de log possa ser estabelecido a partir de uma linha de base (sabendo muito bem que essas operações *farão* fazer com que o log de transações cresça). Eu usei propositadamente um disco mecânico em oposição a um SSD. Embora possamos começar a ver uma tendência mais popular de migrar para SSD, isso ainda não aconteceu em grande escala; em muitos casos, ainda é muito caro fazê-lo em grandes dispositivos de armazenamento.
Os testes
Então, em seguida, tive que determinar o que queria testar para obter o maior impacto. Como eu estava envolvido em uma discussão com um colega de trabalho ontem sobre a exclusão de dados em partes, optei por exclusões. E como o índice clusterizado nesta tabela está em
SalesOrderID , eu não queria usar isso - isso seria muito fácil (e muito raramente corresponderia à maneira como as exclusões são tratadas na vida real). Então decidi ir atrás de uma série de ProductID valores, o que garantiria que eu atingiria um grande número de páginas e exigiria muito registro. Eu determinei quais produtos excluir pela seguinte consulta:SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Isso gerou os seguintes resultados:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Isso excluiria 456.960 linhas (cerca de 10% da tabela), espalhadas por muitos pedidos. Esta não é uma modificação realista neste contexto, uma vez que vai mexer com os totais de pedidos pré-calculados e você não pode realmente remover um produto de um pedido que já foi enviado. Mas usar um banco de dados que todos nós conhecemos e amamos, é análogo a, digamos, deletar um usuário de um site de fórum e também deletar todas as suas mensagens – um cenário real que eu já vi na natureza.
Portanto, um teste seria executar a seguinte exclusão única:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Eu sei que isso vai exigir uma varredura massiva e causar um grande impacto no log de transações. Esse é o ponto. :-)
Enquanto isso estava em execução, montei um script diferente que executará essa exclusão em partes:25.000, 50.000, 75.000 e 100.000 linhas por vez. Cada pedaço será confirmado em sua própria transação (para que se você precisar parar o script, você pode, e todos os pedaços anteriores já serão confirmados, em vez de ter que recomeçar), e dependendo do modelo de recuperação, será seguido por um
CHECKPOINT ou um BACKUP LOG para minimizar o impacto contínuo no log de transações. (Também testarei sem essas operações.) Será algo assim (não vou me preocupar com tratamento de erros e outras sutilezas para este teste, mas você não deve ser tão arrogante):SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END Claro que, após cada teste, eu restauraria o backup original do banco de dados
WITH REPLACE, RECOVERY , defina o modelo de recuperação adequadamente e execute o próximo teste. Os resultados
O resultado do primeiro teste não foi muito surpreendente. Para realizar a exclusão em uma única instrução, foram necessários 42 segundos na íntegra e 43 segundos na simples. Em ambos os casos, isso aumentou o log para 579 MB.
O próximo conjunto de testes teve algumas surpresas para mim. Uma é que, embora esses métodos de agrupamento reduzissem significativamente o impacto no arquivo de log, apenas algumas combinações chegaram perto da duração e nenhuma foi realmente mais rápida. Outra é que, em geral, o agrupamento em recuperação completa (sem realizar um backup de log entre as etapas) teve um desempenho melhor do que as operações equivalentes na recuperação simples. Aqui estão os resultados para duração e impacto do log:
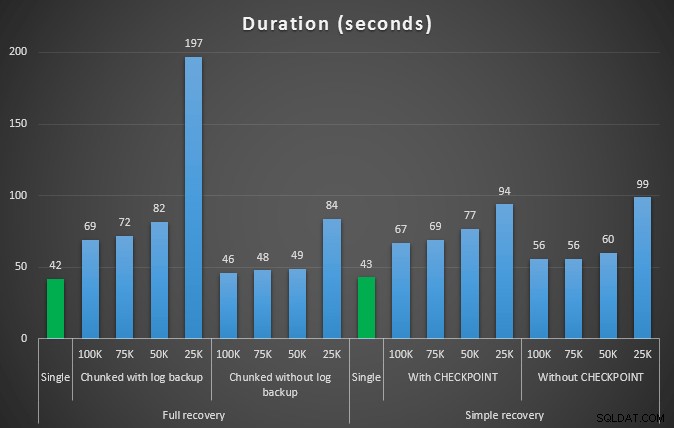
Duração, em segundos, de várias operações de exclusão removendo 457K linhas
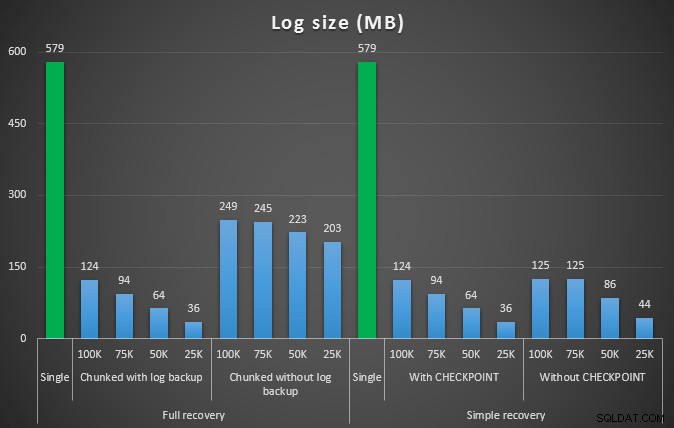
Tamanho do log, em MB, após várias operações de exclusão removendo 457 mil linhas
Novamente, em geral, enquanto o tamanho do log é significativamente reduzido, a duração é aumentada. Você pode usar esse tipo de escala para determinar se é mais importante reduzir o impacto no espaço em disco ou minimizar o tempo gasto. Para um pequeno acerto na duração (e afinal, a maioria desses processos é executada em segundo plano), você pode ter uma economia significativa (até 94%, nesses testes) no uso do espaço de log.
Observe que eu não tentei nenhum desses testes com a compactação ativada (possivelmente um teste futuro!), e deixei as configurações de crescimento automático de log nos terríveis padrões (10%) - em parte por preguiça e em parte porque muitos ambientes por aí mantiveram esta configuração horrível.
Mas e se eu tiver mais dados?
Em seguida, pensei que deveria testar isso em um banco de dados um pouco maior. Então eu fiz outro banco de dados e criei uma nova cópia maior de
dbo.SalesOrderDetailEnlarged . Cerca de dez vezes maior, na verdade. Desta vez, em vez de uma chave primária em SalesOrderID, SalesorderDetailID , acabei de torná-lo um índice clusterizado (para permitir duplicatas) e o preenchi desta maneira:SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Devido a limitações de espaço em disco, tive que sair da VM do meu laptop para este teste (e escolhi uma caixa de 40 núcleos, com 128 GB de RAM, que estava quase ociosa :-)), e ainda não foi um processo rápido de forma alguma. O preenchimento da tabela e a criação dos índices levaram ~24 minutos.
A tabela tem 48,5 milhões de linhas e ocupa 7,9 GB em disco (4,9 GB em dados e 2,9 GB em índice).
Desta vez, minha consulta para determinar um bom conjunto de candidatos
ProductID valores a serem excluídos:SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Obteve os seguintes resultados:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Então vamos deletar 4.455.360 linhas, um pouco menos de 10% da tabela. Seguindo um padrão semelhante ao teste acima, vamos excluir tudo de uma vez, depois em pedaços de 500.000, 250.000 e 100.000 linhas.
Resultados:
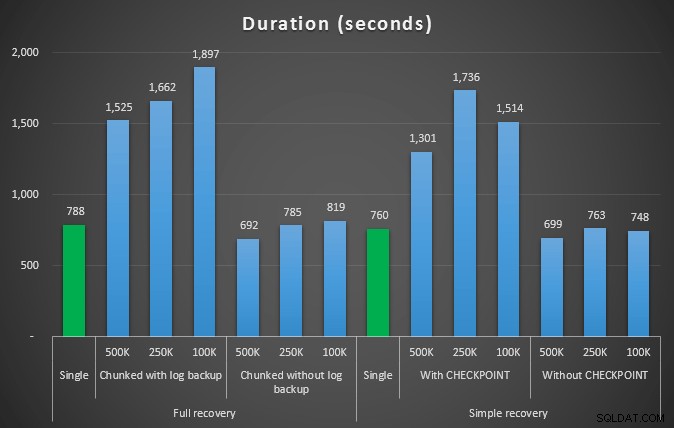 Duração, em segundos, de várias operações de exclusão removendo 4,5 milhões de linhas
Duração, em segundos, de várias operações de exclusão removendo 4,5 milhões de linhas 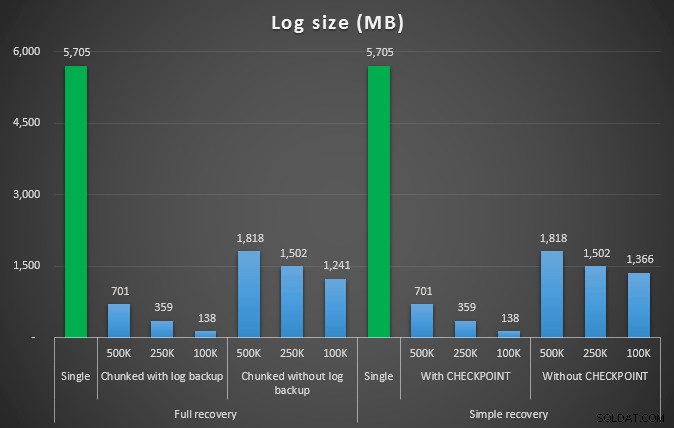 Tamanho do log, em MB, após várias operações de exclusão removendo 4,5 milhões de linhas
Tamanho do log, em MB, após várias operações de exclusão removendo 4,5 milhões de linhas Então, novamente, vemos uma redução significativa no tamanho do arquivo de log (mais de 97% nos casos com o menor tamanho de bloco de 100K); porém, nessa escala, vemos alguns casos em que também realizamos a exclusão em menos tempo, mesmo com todos os eventos de crescimento automático que devem ter ocorrido. Isso soa muito como ganha-ganha para mim!
Desta vez com um log maior
Agora, eu estava curioso para saber como essas diferentes exclusões seriam comparadas a um arquivo de log pré-dimensionado para acomodar operações tão grandes. Mantendo nosso banco de dados maior, pré-expandi o arquivo de log para 6 GB, fiz backup e executei os testes novamente:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Resultados, comparando a duração com um arquivo de log fixo para o caso em que o arquivo teve que crescer automaticamente continuamente:
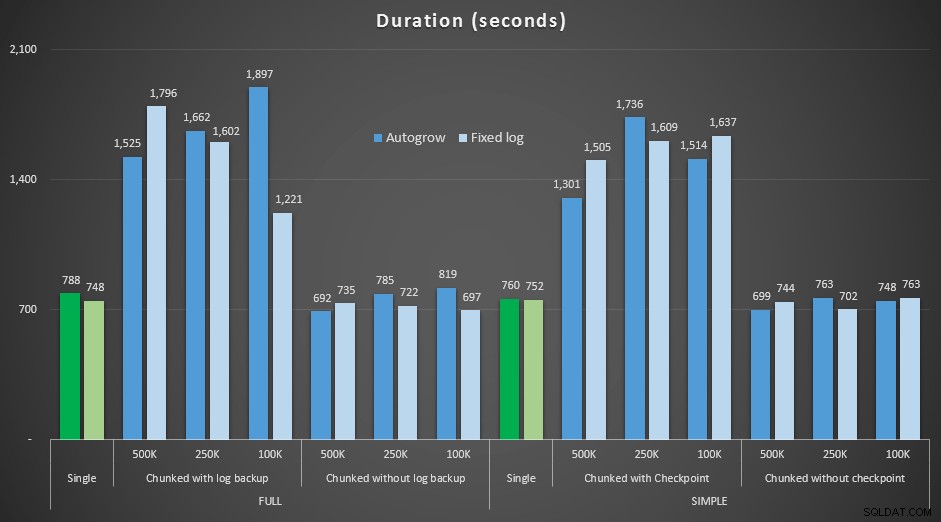
Duração, em segundos, de várias operações de exclusão removendo 4,5 milhões de linhas , comparando o tamanho fixo do log e o crescimento automático
Mais uma vez, vemos que os métodos que excluem pedaços em lotes e *não* executam um backup de log ou um ponto de verificação após cada etapa, rivalizam com a operação única equivalente em termos de duração. Na verdade, veja que a maioria realmente funciona em menos tempo geral, com o bônus adicional de que outras transações poderão entrar e sair entre as etapas. O que é bom, a menos que você queira que essa operação de exclusão bloqueie todas as transações não relacionadas.
Conclusão
É claro que não há uma resposta única e correta para esse problema – há muitas variáveis inerentes do tipo "depende". Pode levar alguns experimentos para encontrar seu número mágico, pois haverá um equilíbrio entre a sobrecarga necessária para fazer backup do log e quanto trabalho e tempo você economiza em diferentes tamanhos de blocos. Mas se você planeja excluir ou arquivar um grande número de linhas, é bem provável que seja melhor, no geral, realizar as alterações em partes, em vez de em uma transação massiva - mesmo que os números de duração pareçam fazer que uma operação menos atraente. Não é tudo sobre a duração - se você não tiver um arquivo de log suficientemente pré-alocado e não tiver espaço para acomodar uma transação tão grande, provavelmente é muito melhor minimizar o crescimento do arquivo de log ao custo da duração, nesse caso, ignore os gráficos de duração acima e preste atenção aos gráficos de tamanho de log.
Se você puder pagar pelo espaço, ainda poderá ou não querer pré-dimensionar seu log de transações de acordo. Dependendo do cenário, às vezes, usar as configurações padrão de crescimento automático acabou um pouco mais rápido em meus testes do que usar um arquivo de log fixo com muito espaço. Além disso, pode ser difícil adivinhar exatamente quanto você precisará para acomodar uma grande transação que você ainda não executou. Se você não puder testar um cenário realista, tente ao máximo imaginar seu pior cenário – então, por segurança, dobre-o. Kimberly Tripp (blog | @KimberlyLTripp) tem ótimos conselhos neste post:8 etapas para melhorar a taxa de transferência do log de transações – neste contexto, especificamente, veja o ponto 6. Independentemente de como você decida calcular seus requisitos de espaço de log, se você acabar precisando do espaço de qualquer maneira, é melhor levá-lo de maneira controlada com bastante antecedência do que interromper seus processos de negócios enquanto eles aguardam um crescimento automático ( não importa vários!).
Outra faceta muito importante disso que não medi explicitamente é o impacto na simultaneidade – um monte de transações mais curtas, em teoria, terão menos impacto nas operações simultâneas. Embora uma única exclusão levasse um pouco menos de tempo do que as operações em lote mais longas, ela mantinha todos os seus bloqueios por toda a duração, enquanto as operações em partes permitiriam que outras transações enfileiradas se infiltrassem entre cada transação. Em um post futuro, tentarei dar uma olhada mais de perto nesse impacto (e também tenho planos para outras análises mais profundas).