A remoção e prevenção de fragmentação de índice faz parte das operações normais de manutenção de banco de dados, não apenas no SQL Server, mas em muitas plataformas. A fragmentação de índice afeta o desempenho por vários motivos, e a maioria das pessoas fala sobre os efeitos de pequenos blocos aleatórios de E/S que podem ocorrer fisicamente no armazenamento baseado em disco como algo a ser evitado. A preocupação geral em torno da fragmentação de índice é que ela afeta o desempenho das varreduras por meio da limitação do tamanho das E/Ss de leitura antecipada. É com base nessa compreensão limitada dos problemas que a fragmentação de índice causa que algumas pessoas começaram a circular a ideia de que a fragmentação de índice não importa com dispositivos de armazenamento de estado sólido (SSDs) e que você pode simplesmente ignorar a fragmentação de índice daqui para frente.
No entanto, isso não ocorre por vários motivos. Este artigo explicará e demonstrará um desses motivos:que a fragmentação do índice pode afetar negativamente a escolha do plano de execução para consultas. Isso ocorre porque a fragmentação do índice geralmente leva a um índice com mais páginas (essas páginas extras vêm da divisão de página operações, conforme descrito neste post neste site), e assim o uso desse índice é considerado de maior custo pelo otimizador de consultas do SQL Server.
Vejamos um exemplo.
A primeira coisa que precisamos fazer é construir um banco de dados de teste e um conjunto de dados apropriados a serem usados para examinar como a fragmentação do índice pode afetar a escolha do plano de consulta no SQL Server. O script a seguir criará um banco de dados com duas tabelas com dados idênticos, uma muito fragmentada e outra minimamente fragmentada.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Após reconstruir o índice, podemos observar os níveis de fragmentação com a seguinte consulta:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Resultados:

Aqui podemos ver que nosso GuidHighFragmentation A tabela é 99% fragmentada e usa 31% mais espaço de página do que o GuidLowFragmentation tabela no banco de dados, apesar de terem os mesmos 7.000.000 de linhas de dados. Se realizarmos uma consulta de agregação básica em cada uma das tabelas e compararmos os planos de execução em uma instalação padrão (com opções e valores de configuração padrão) do SQL Server usando o SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


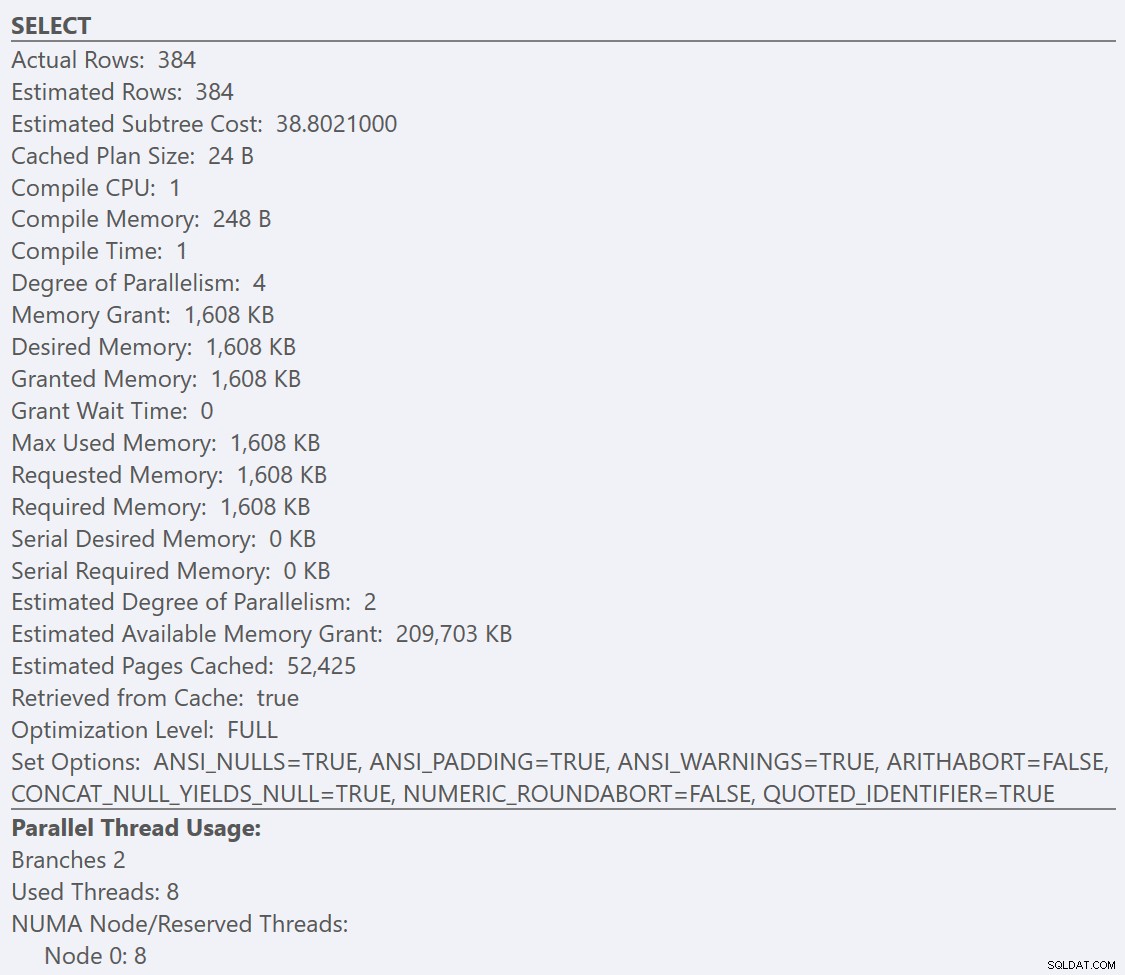

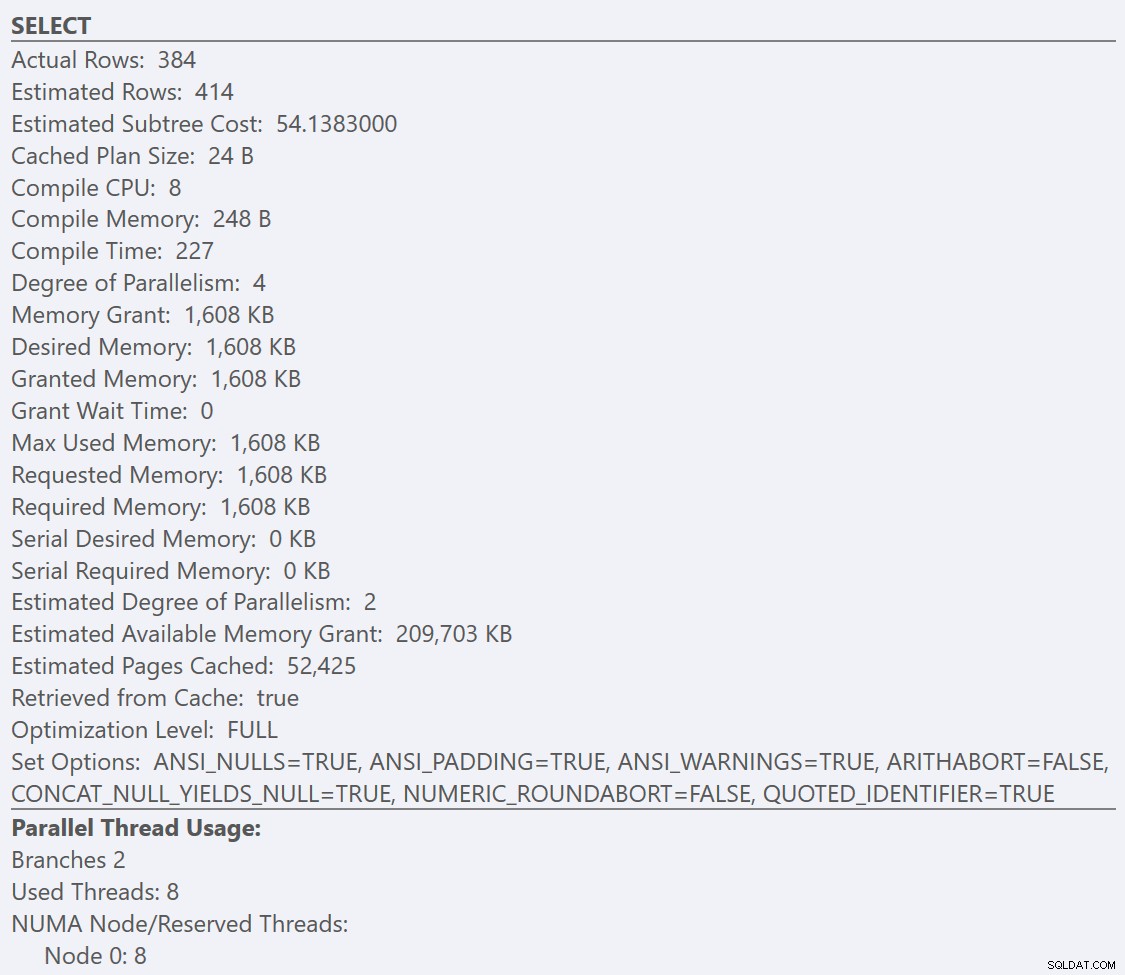
Se olharmos para as dicas de ferramentas do SELECT operador para cada plano, o plano para o GuidLowFragmentation table tem um custo de consulta de 38,80 (a terceira linha abaixo da parte superior da dica de ferramenta) versus um custo de consulta de 54,14 para o plano GuidHighFragmentation.
Em uma configuração padrão para o SQL Server, ambas as consultas acabam gerando um plano de execução paralela, pois o custo estimado da consulta é maior que o padrão da opção 'limite de custo para paralelismo' sp_configure de 5. Isso ocorre porque o otimizador de consulta primeiro produz um serial plan (que só pode ser executado por um único thread) ao compilar o plano para uma consulta. Se o custo estimado desse plano serial exceder o valor configurado de "limite de custo para paralelismo", um plano paralelo será gerado e armazenado em cache.
No entanto, e se a opção sp_configure 'limite de custo para paralelismo' não estiver definida para o padrão de 5 e estiver definida como mais alta? É uma prática recomendada (e correta) aumentar essa opção do baixo padrão de 5 para qualquer lugar de 25 a 50 (ou até muito mais alto) para evitar que pequenas consultas incorram na sobrecarga adicional de serem paralelas.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Depois de seguir as diretrizes de práticas recomendadas e aumentar o "limite de custo para paralelismo" para 50, a reexecução das consultas resulta no mesmo plano de execução para o GuidHighFragmentation tabela, mas o GuidLowFragmentation o custo serial da consulta, 44,68, agora está abaixo do valor 'limite de custo para paralelismo' (lembre-se que seu custo paralelo estimado era 38,80), então obtemos um plano de execução serial:
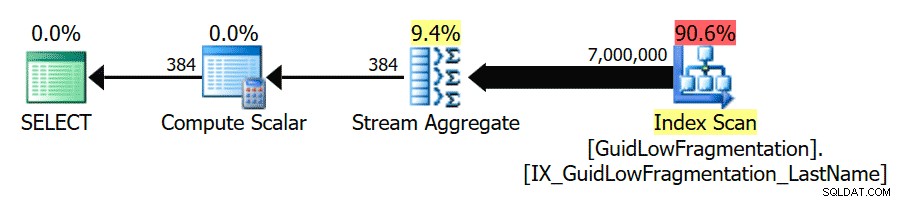
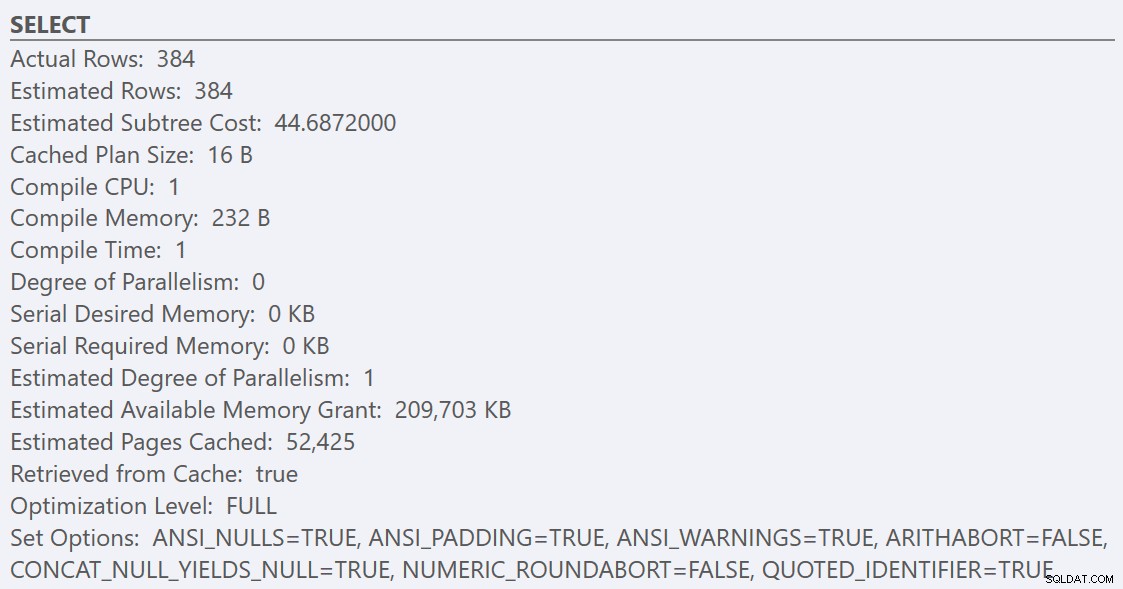
O espaço de página adicional no GuidHighFragmentation índice clusterizado manteve o custo acima da configuração de melhores práticas para "limite de custo para paralelismo" e resultou em um plano paralelo.
Agora imagine que este era um sistema em que você seguiu a orientação de melhores práticas e inicialmente configurou o 'limite de custo para paralelismo' em um valor de 50. Depois, mais tarde, você seguiu o conselho equivocado de simplesmente ignorar completamente a fragmentação do índice.
Em vez de ser uma consulta básica, é mais complexa, mas se também for executada com muita frequência em seu sistema e, como resultado da fragmentação do índice, a contagem de páginas transfere o custo para um plano paralelo, ele usará mais CPU e impactar o desempenho geral da carga de trabalho como resultado.
O que você faz? Você aumenta o 'limite de custo para paralelismo' para que a consulta mantenha um plano de execução serial? Você sugere a consulta com OPTION(MAXDOP 1) e apenas a força para um plano de execução serial?
Tenha em mente que a fragmentação de índice provavelmente não afeta apenas uma tabela em seu banco de dados, agora que você a está ignorando completamente; é provável que muitos índices clusterizados e não clusterizados sejam fragmentados e tenham uma contagem de páginas maior do que o necessário, portanto, os custos de muitas operações de E/S estão aumentando como resultado da fragmentação generalizada do índice, levando a muitas consultas potencialmente ineficientes planos.
Resumo
Você não pode simplesmente ignorar a fragmentação do índice inteiramente, como alguns podem querer que você acredite. Entre outras desvantagens de fazer isso, os custos acumulados de execução de consulta irão alcançá-lo, com mudanças de plano de consulta porque o otimizador de consulta é um otimizador baseado em custo e, portanto, corretamente considera esses índices fragmentados como mais caros de utilizar.
As consultas e o cenário aqui são obviamente artificiais, mas vimos mudanças no plano de execução causadas pela fragmentação na vida real nos sistemas clientes.
Você precisa ter certeza de que está abordando a fragmentação de índice para aqueles índices em que a fragmentação causa problemas de desempenho da carga de trabalho, independentemente do hardware que você está usando.