
O T-SQL Tuesday #78 está sendo hospedado por Wendy Pastrick, e o desafio deste mês é simplesmente "aprender algo novo e escrever sobre isso no blog". Sua sinopse se inclina para os novos recursos do SQL Server 2016, mas como eu escrevi no blog e apresentei sobre muitos deles, pensei em explorar outra coisa em primeira mão sobre a qual sempre fui genuinamente curioso.
Já vi várias pessoas afirmarem que um heap pode ser melhor do que um índice clusterizado para determinados cenários. Não posso discordar disso. Uma das razões interessantes que eu vi declarado, porém, é que uma pesquisa RID é mais rápida que uma pesquisa de chave. Eu sou um grande fã de índices clusterizados e não um grande fã de heaps, então senti que isso precisava de alguns testes.
Então, vamos testar!
Achei que seria bom criar um banco de dados com duas tabelas, idênticas, exceto que uma tinha uma chave primária clusterizada e a outra uma chave primária não clusterizada. Eu carregava algumas linhas na tabela, atualizando várias linhas em um loop e selecionando a partir de um índice (forçando uma pesquisa de chave ou RID).
Especificações do sistema
Essa pergunta costuma surgir, então, para esclarecer os detalhes importantes sobre esse sistema, estou em uma VM de 8 núcleos com 32 GB de RAM, apoiada por armazenamento PCIe. A versão do SQL Server é 2014 SP1 CU6, sem alterações de configuração especiais ou sinalizadores de rastreamento em execução:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)
13 de abril de 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) no Windows NT 6.3
O banco de dados
Criei um banco de dados com bastante espaço livre nos dados e no arquivo de log para evitar que eventos de crescimento automático interfiram nos testes. Também configurei o banco de dados para recuperação simples para minimizar o impacto no log de transações.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
As Tabelas
Como eu disse, duas tabelas, com a única diferença sendo se a chave primária é clusterizada.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Uma tabela para capturar o tempo de execução
Eu poderia monitorar CPU e tudo isso, mas realmente a curiosidade é quase sempre em torno do tempo de execução. Então criei uma tabela de log para capturar o tempo de execução de cada teste:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
O teste de inserção
Então, quanto tempo leva para inserir 2.000 linhas, 100 vezes? Estou pegando alguns dados bem básicos de
sys.all_objects , e puxando a definição para quaisquer procedimentos, funções, etc.:INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; O teste de atualização
Para o teste de atualização, eu só queria testar a velocidade de gravação em um índice clusterizado versus um heap de maneira muito linha por linha. Então, despejei 200 linhas aleatórias em uma tabela #temp e construí um cursor em torno dela (a tabela #temp apenas garante que as mesmas 200 linhas sejam atualizadas em ambas as versões da tabela, o que provavelmente é um exagero).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; O Teste Seleto
Então, acima você viu que eu criei um índice com
Name como a coluna chave em cada tabela; para avaliar o custo de realizar pesquisas para uma quantidade significativa de linhas, escrevi uma consulta que atribui a saída a uma variável (eliminando a E/S da rede e o tempo de renderização do cliente), mas força o uso do índice:INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Para este eu queria mostrar alguns aspectos interessantes dos planos antes de comparar os resultados dos testes. Executá-los individualmente frente a frente fornece essas métricas comparativas:

A duração é irrelevante para uma única declaração, mas veja essas leituras. Se você estiver em armazenamento lento, essa é uma grande diferença que você não verá em uma escala menor e/ou em seu SSD de desenvolvimento local.
E então os planos mostrando as duas pesquisas diferentes, usando o SQL Sentry Plan Explorer:

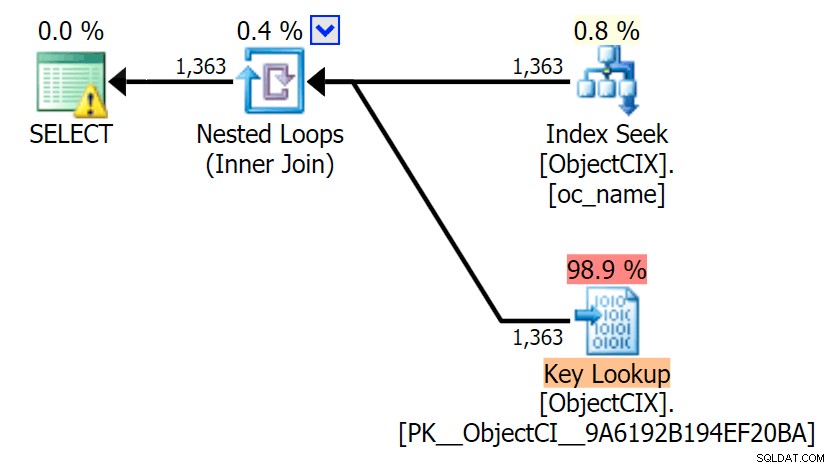
Os planos parecem quase idênticos e você pode não notar a diferença nas leituras no SSMS, a menos que esteja capturando E/S de Estatísticas. Até mesmo os custos estimados de E/S para as duas pesquisas foram semelhantes – 1,69 para a pesquisa de chave e 1,59 para a pesquisa de RID. (O ícone de aviso em ambos os planos é para um índice de cobertura ausente.)
É interessante notar que, se não forçarmos uma pesquisa e permitirmos que o SQL Server decida o que fazer, ele escolherá uma verificação padrão em ambos os casos – sem aviso de índice ausente e observe o quanto as leituras estão mais próximas:

O otimizador sabe que uma varredura será muito mais barata do que buscar + pesquisas neste caso. Eu escolhi uma coluna LOB para atribuição de variável apenas para efeito, mas os resultados foram semelhantes usando uma coluna não LOB também.
Os resultados do teste
Com a tabela Timings em vigor, consegui executar facilmente os testes várias vezes (executei uma dúzia de testes) e, em seguida, obtive médias para os testes com a seguinte consulta:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Um gráfico de barras simples mostra como eles se comparam:
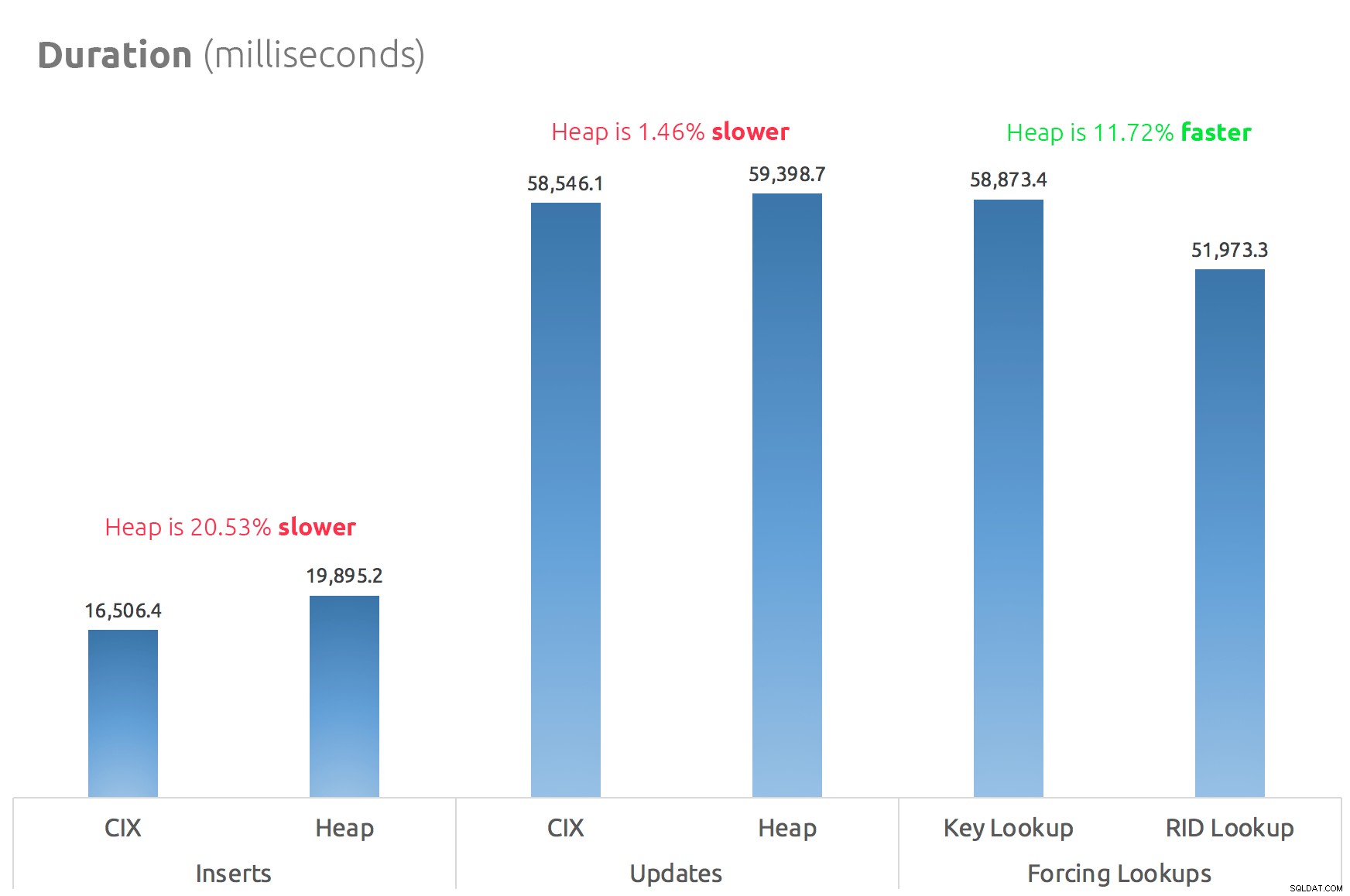
Conclusão
Portanto, os rumores são verdadeiros:neste caso, pelo menos, um RID Lookup é significativamente mais rápido que um Key Lookup. Ir diretamente para file:page:slot é obviamente mais eficiente em termos de E/S do que seguir a b-tree (e se você não estiver em armazenamento moderno, o delta pode ser muito mais perceptível).
Se você deseja tirar proveito disso e trazer todos os outros aspectos do heap, dependerá da sua carga de trabalho – o heap é um pouco mais caro para operações de gravação. Mas isso não definitivo – isso pode variar muito dependendo da estrutura da tabela, índices e padrões de acesso.
Eu testei coisas muito simples aqui, e se você está em dúvida sobre isso, eu recomendo testar sua carga de trabalho real em seu próprio hardware e comparar por si mesmo (e não se esqueça de testar a mesma carga de trabalho onde os índices de cobertura estão presentes; você provavelmente obterá um desempenho geral muito melhor se puder simplesmente eliminar as pesquisas completamente). Certifique-se de medir todas as métricas que são importantes para você; só porque eu foco na duração não significa que é o que você mais precisa se preocupar. :-)



