Bem-vindo à terceira – e última – parte desta série de blogs, explorando como o desempenho do PostgreSQL evoluiu ao longo dos anos. A primeira parte analisou as cargas de trabalho OLTP, representadas por testes pgbench. A segunda parte olhou para consultas analíticas / BI, usando um subconjunto do benchmark TPC-H tradicional (essencialmente uma parte do teste de poder).
E esta parte final analisa a pesquisa de texto completo, ou seja, a capacidade de indexar e pesquisar em grandes quantidades de dados de texto. A mesma infraestrutura (especialmente os índices) pode ser útil para indexar dados semiestruturados, como documentos JSONB, etc., mas não é nisso que esse benchmark se concentra.
Mas primeiro, vamos ver o histórico da pesquisa de texto completo no PostgreSQL, que pode parecer um recurso estranho para adicionar a um RDBMS, tradicionalmente destinado a armazenar dados estruturados em linhas e colunas.
O histórico da pesquisa de texto completo
Quando o Postgres era de código aberto em 1996, não tinha nada que pudéssemos chamar de pesquisa de texto completo. Mas as pessoas que começaram a usar o Postgres queriam fazer buscas inteligentes em documentos de texto, e as consultas LIKE não eram boas o suficiente. Eles queriam ser capazes de lematizar os termos usando dicionários, ignorar palavras de parada, classificar os documentos correspondentes por relevância, usar índices para executar essas consultas e muitas outras coisas. Coisas que você não pode fazer com os operadores SQL tradicionais.
Felizmente, algumas dessas pessoas também eram desenvolvedores, então começaram a trabalhar nisso – e puderam, graças ao PostgreSQL estar disponível como código aberto em todo o mundo. Houve muitos colaboradores para a pesquisa de texto completo ao longo dos anos, mas inicialmente esse esforço foi liderado por Oleg Bartunov e Teodor Sigaev, mostrados na foto a seguir. Ambos ainda são grandes contribuidores do PostgreSQL, trabalhando em pesquisa de texto completo, indexação, suporte a JSON e muitos outros recursos.

Teodor Sigaev e Oleg Bartunov
Inicialmente, a funcionalidade foi desenvolvida como um módulo externo “contrib” (hoje diríamos que é uma extensão) chamado “tsearch”, lançado em 2002. Mais tarde, isso foi obsoleto pelo tsearch2, melhorando significativamente o recurso em vários aspectos, e no PostgreSQL 8.3 (lançado em 2008) foi totalmente integrado ao núcleo do PostgreSQL (ou seja, sem a necessidade de instalar nenhuma extensão, embora as extensões ainda fossem fornecidas para compatibilidade com versões anteriores).
Houve muitas melhorias desde então (e o trabalho continua, por exemplo, para suportar tipos de dados como JSONB, consulta usando jsonpath etc.). mas esses plugins introduziram a maior parte da funcionalidade de texto completo que temos no PostgreSQL agora – dicionários, indexação de texto completo e recursos de consulta, etc.
A referência
Ao contrário dos benchmarks OLTP / TPC-H, não conheço nenhum benchmark de texto completo que possa ser considerado “padrão da indústria” ou projetado para vários sistemas de banco de dados. A maioria dos benchmarks que conheço devem ser usados com um único banco de dados / produto, e é difícil portá-los de forma significativa, então tive que seguir um caminho diferente e escrever meu próprio benchmark de texto completo.
Anos atrás eu escrevi archie – um par de scripts python que permitem o download de arquivos da lista de discussão PostgreSQL e carregam as mensagens analisadas em um banco de dados PostgreSQL que pode ser indexado e pesquisado. O instantâneo atual de todos os arquivos tem cerca de 1 milhão de linhas e, após carregá-lo em um banco de dados, a tabela tem cerca de 9,5 GB (sem contar os índices).
Quanto às consultas, eu provavelmente poderia gerar algumas aleatórias, mas não tenho certeza de quão realista isso seria. Felizmente, há alguns anos, obtive uma amostra de 33 mil pesquisas reais no site do PostgreSQL (ou seja, coisas que as pessoas realmente pesquisaram nos arquivos da comunidade). É improvável que eu consiga algo mais realista/representativo.
A combinação dessas duas partes (conjunto de dados + consultas) parece um bom benchmark. Podemos simplesmente carregar os dados e executar as pesquisas com diferentes tipos de consultas de texto completo com diferentes tipos de índices.
Consultas
Existem várias formas de consultas de texto completo – a consulta pode simplesmente selecionar todas as linhas correspondentes, pode classificar os resultados (classificá-los por relevância), retornar apenas um pequeno número ou os resultados mais relevantes etc. tipos de consultas, mas neste post apresentarei resultados para duas consultas simples que acho que representam muito bem o comportamento geral.
- SELECT id, assunto FROM messages WHERE body_tsvector @@ $1
- SELECT id, assunto FROM messages WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
A primeira consulta simplesmente retorna todas as linhas correspondentes, enquanto a segunda retorna os 100 resultados mais relevantes (isso é algo que você provavelmente usaria para pesquisas de usuários).
Eu experimentei vários outros tipos de consultas, mas todas elas se comportaram de maneira semelhante a um desses dois tipos de consulta.
Índices
Cada mensagem tem duas partes principais que podemos pesquisar – assunto e corpo. Cada um deles tem uma coluna tsvector separada e é indexado separadamente. Os assuntos da mensagem são muito mais curtos que os corpos, então os índices são naturalmente menores.
O PostgreSQL possui dois tipos de índices úteis para pesquisa de texto completo – GIN e GiST. As principais diferenças são explicadas nos documentos, mas resumidamente:
- Os índices GIN são mais rápidos para pesquisas
- Os índices GiST têm perdas, ou seja, exigem uma nova verificação durante as pesquisas (e, portanto, são mais lentos)
Costumávamos afirmar que os índices GiST são mais baratos de atualizar (especialmente com muitas sessões simultâneas), mas isso foi removido da documentação há algum tempo, devido a melhorias no código de indexação.
Esse benchmark não testa o comportamento com atualizações – ele simplesmente carrega a tabela sem os índices de texto completo, cria-os de uma só vez e, em seguida, executa as 33k consultas nos dados. Isso significa que não posso fazer nenhuma declaração sobre como esses tipos de índice lidam com atualizações simultâneas com base nesse benchmark, mas acredito que as alterações na documentação refletem várias melhorias recentes do GIN.
Isso também deve corresponder muito bem ao caso de uso do arquivo da lista de discussão, onde apenas anexamos novos e-mails de vez em quando (poucas atualizações, quase nenhuma simultaneidade de gravação). Mas se o seu aplicativo fizer muitas atualizações simultâneas, você precisará avaliar isso por conta própria.
O hardware
Fiz o benchmark nas mesmas duas máquinas de antes, mas os resultados/conclusões são quase idênticos, então apresentarei apenas os números da menor, ou seja,
- CPU i5-2500K (4 núcleos/threads)
- 8 GB de RAM
- 6 x 100 GB SSD RAID0
- kernel 5.6.15, sistema de arquivos ext4
Eu mencionei anteriormente que o conjunto de dados tem quase 10 GB quando carregado, então é maior que a RAM. Mas os índices ainda são menores que a RAM, que é o que importa para o benchmark.
Resultados
OK, hora de alguns números e gráficos. Apresento resultados para carregamentos de dados e consultas, primeiro com GIN e depois com índices GiST.
GIN / carga de dados
A carga não é particularmente interessante, eu acho. Em primeiro lugar, a maior parte (a parte azul) não tem nada a ver com texto completo, porque acontece antes dos dois índices serem criados. A maior parte desse tempo é gasto analisando as mensagens, reconstruindo os encadeamentos de correio, mantendo a lista de respostas e assim por diante. Alguns desses códigos são implementados em triggers PL/pgSQL, outros são implementados fora do banco de dados. A única parte potencialmente relevante para o texto completo é construir os tsvectors, mas é impossível isolar o tempo gasto nisso.
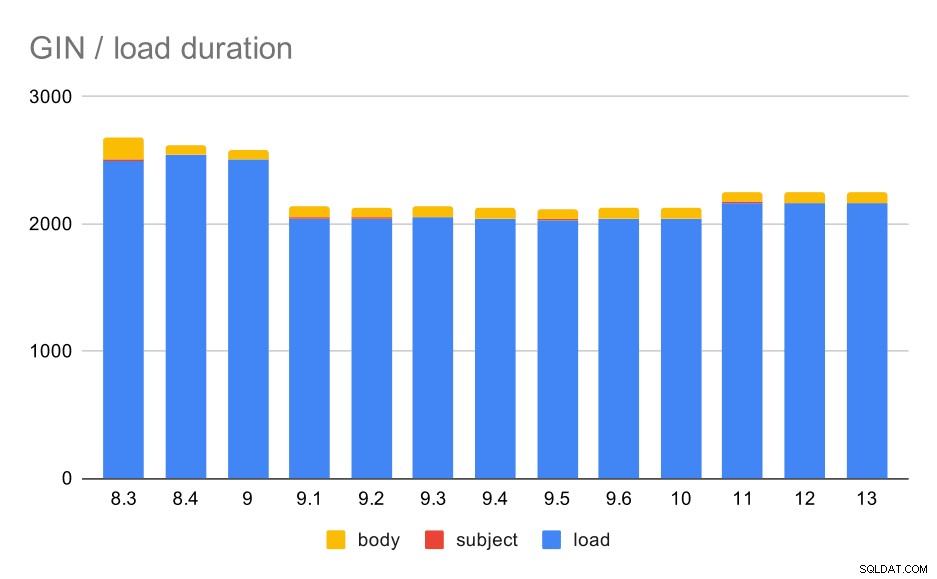
Operações de carregamento de dados com uma tabela e índices GIN.
A tabela a seguir mostra os dados de origem para este gráfico – os valores são a duração em segundos. LOAD inclui análise dos arquivos mbox (de um script Python), inserção em uma tabela e várias tarefas adicionais (reconstrução de threads de e-mail, etc.). O SUBJECT/BODY INDEX refere-se à criação do índice GIN de texto completo nas colunas subject/body depois que os dados são carregados.
| LOAD | ÍNDICE DE ASSUNTO | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8,4 | 2540 | 4 | 78 |
| 9,0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9,2 | 2045 | 3 | 85 |
| 9,3 | 2049 | 4 | 85 |
| 9,4 | 2043 | 4 | 85 |
| 9,5 | 2034 | 4 | 82 |
| 9,6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Claramente, o desempenho é bastante estável - houve uma melhoria bastante significativa (aproximadamente 20%) entre 9.0 e 9.1. Não tenho certeza de qual mudança poderia ser responsável por essa melhoria - nada nas notas de lançamento 9.1 parece claramente relevante. Há também uma clara melhoria na construção dos índices GIN em 8,4, o que reduz o tempo pela metade. O que é legal, claro. Curiosamente, também não vejo nenhum item de notas de lançamento obviamente relacionado a isso.
E quanto aos tamanhos dos índices GIN? Há muito mais variabilidade, pelo menos até 9.4, quando o tamanho dos índices cai de ~ 1 GB para apenas cerca de 670 MB (aproximadamente 30%).
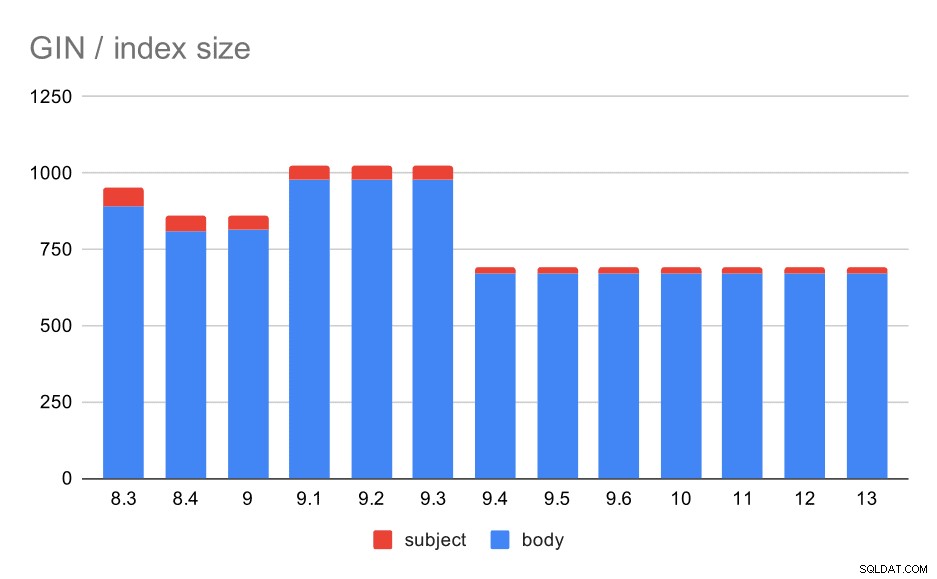
Tamanho dos índices GIN no assunto/corpo da mensagem. Os valores são megabytes.
A tabela a seguir mostra os tamanhos dos índices GIN no corpo e no assunto da mensagem. Os valores estão em megabytes.
| BODY | ASSUNTO | |
| 8,3 | 890 | 62 |
| 8,4 | 811 | 47 |
| 9,0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9,2 | 978 | 47 |
| 9,3 | 977 | 47 |
| 9,4 | 671 | 20 |
| 9,5 | 671 | 20 |
| 9,6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
Nesse caso, acho que podemos assumir com segurança que essa aceleração está relacionada a este item nas notas da versão 9.4:
- Reduzir o tamanho do índice GIN (Alexander Korotkov, Heikki Linnakangas)
A variabilidade de tamanho entre 8,3 e 9,1 parece ser devido a mudanças na lematização (como as palavras são transformadas para a forma “básica”). Além das diferenças de tamanho, as consultas nessas versões retornam números de resultados ligeiramente diferentes, por exemplo.
GIN / consultas
Agora, a parte principal deste benchmark – desempenho de consulta. Todos os números apresentados aqui são para um único cliente – já discutimos a escalabilidade do cliente na parte relacionada ao desempenho do OLTP, as descobertas também se aplicam a essas consultas. (Além disso, esta máquina em particular tem apenas 4 núcleos, então não iríamos muito longe em termos de testes de escalabilidade de qualquer maneira.)
SELECT id, subject FROM messages WHERE tsvector @@ $1
Primeiro, a consulta procura todos os documentos correspondentes. Para pesquisas na coluna “assunto”, podemos fazer cerca de 800 consultas por segundo (e na verdade cai um pouco em 9,1), mas em 9,4 de repente dispara até 3000 consultas por segundo. Para a coluna "corpo", é basicamente a mesma história - 160 consultas inicialmente, uma queda para ~ 90 consultas em 9.1 e, em seguida, um aumento para 300 em 9.4.
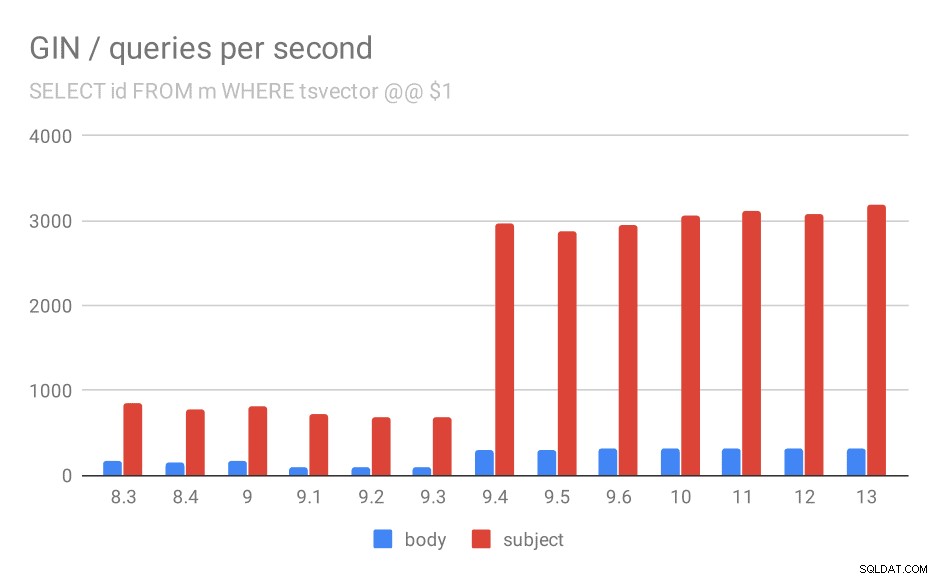
Número de consultas por segundo para a primeira consulta (buscando todas as linhas correspondentes).
E, novamente, os dados de origem – os números são de taxa de transferência (consultas por segundo).
| BODY | ASSUNTO | |
| 8,3 | 168 | 848 |
| 8,4 | 155 | 774 |
| 9,0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9,2 | 93 | 675 |
| 9,3 | 95 | 692 |
| 9,4 | 303 | 2966 |
| 9,5 | 303 | 2871 |
| 9,6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Acho que podemos assumir com segurança que a melhoria na versão 9.4 está relacionada a este item nas notas de lançamento:
- Melhore a velocidade de pesquisas de GIN com várias chaves (Alexander Korotkov, Heikki Linnakangas)
Então, outra melhoria 9.4 no GIN dos mesmos dois desenvolvedores – claramente, Alexander e Heikki fizeram um bom trabalho nos índices GIN na versão 9.4 😉
SELECT id, assunto FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
Para a consulta classificando os resultados por relevância usando ts_rank e LIMIT, o comportamento geral é quase exatamente o mesmo, não há necessidade de descrever o gráfico em detalhes, eu acho.
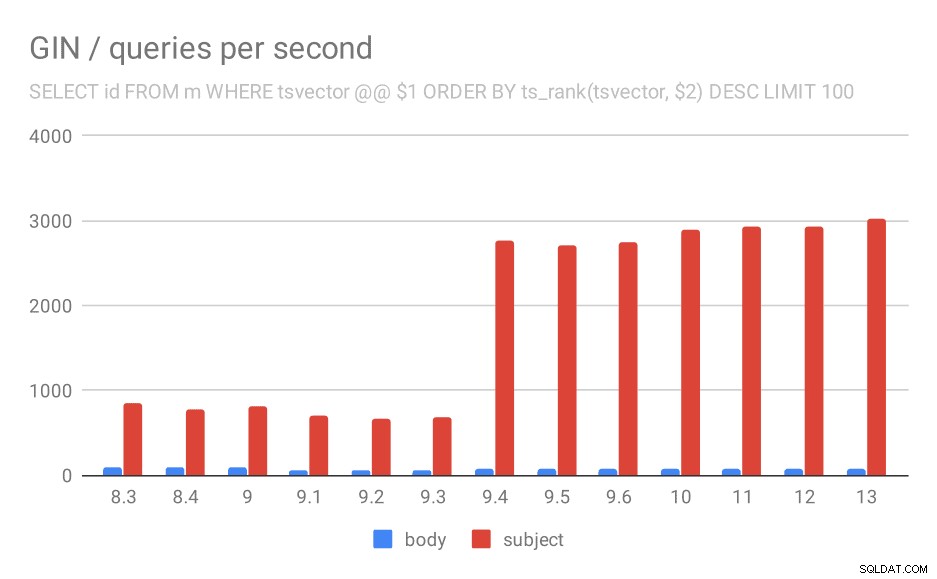
Número de consultas por segundo para a segunda consulta (buscando as linhas mais relevantes).
| BODY | ASSUNTO | |
| 8,3 | 94 | 840 |
| 8,4 | 98 | 775 |
| 9,0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9,2 | 51 | 666 |
| 9,3 | 51 | 678 |
| 9,4 | 80 | 2766 |
| 9,5 | 81 | 2704 |
| 9,6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Mas há uma pergunta:por que o desempenho caiu entre 9,0 e 9,1? Parece haver uma queda bastante significativa na taxa de transferência – cerca de 50% para as pesquisas corporais e 20% para pesquisas nos assuntos das mensagens. Não tenho uma explicação clara do que aconteceu, mas tenho duas observações…
Em primeiro lugar, o tamanho do índice mudou – se você observar o primeiro gráfico “GIN / tamanho do índice” e a tabela, verá que o índice nos corpos das mensagens cresceu de 813 MB para cerca de 977 MB. Esse é um aumento significativo e pode explicar parte da desaceleração. O problema, porém, é que o índice de assuntos não cresceu nada, mas as consultas também ficaram mais lentas.
Em segundo lugar, podemos ver quantos resultados as consultas retornaram. O conjunto de dados indexado é exatamente o mesmo, então parece razoável esperar o mesmo número de resultados em todas as versões do PostgreSQL, certo? Bom, na prática fica assim:
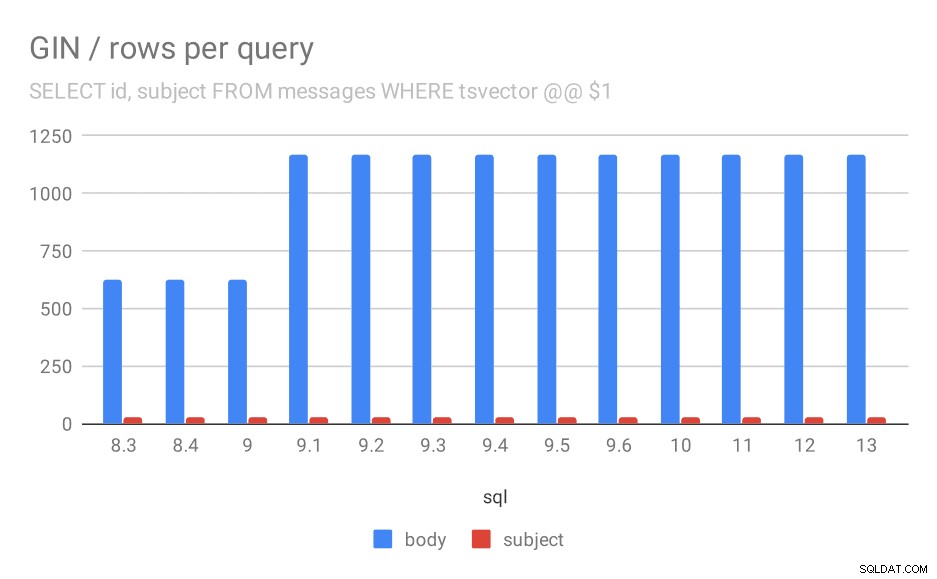
Número médio de linhas retornadas para uma consulta.
| BODY | ASSUNTO | |
| 8,3 | 624 | 26 |
| 8,4 | 624 | 26 |
| 9,0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9,2 | 1165 | 26 |
| 9,3 | 1165 | 26 |
| 9,4 | 1165 | 26 |
| 9,5 | 1165 | 26 |
| 9,6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Claramente, em 9.1, o número médio de resultados para pesquisas em corpos de mensagens dobra de repente, o que é quase perfeitamente proporcional à desaceleração. No entanto, o número de resultados para pesquisas por assunto permanece o mesmo. Não tenho uma explicação muito boa para isso, exceto que a indexação mudou de uma maneira que permite combinar mais mensagens, mas tornando-a um pouco mais lenta. Se você tiver explicações melhores, eu gostaria de ouvi-las!
GiST / carga de dados
Agora, o outro tipo de índices de texto completo – GiST. Esses índices são com perdas, ou seja, exigem uma nova verificação dos resultados usando os valores da tabela. Portanto, podemos esperar uma taxa de transferência menor em comparação com os índices GIN, mas, fora isso, é razoável esperar aproximadamente o mesmo padrão.
Os tempos de carregamento realmente correspondem ao GIN quase perfeitamente – os tempos de criação do índice são diferentes, mas o padrão geral é o mesmo. Aceleração em 9.1, pequena desaceleração em 11.
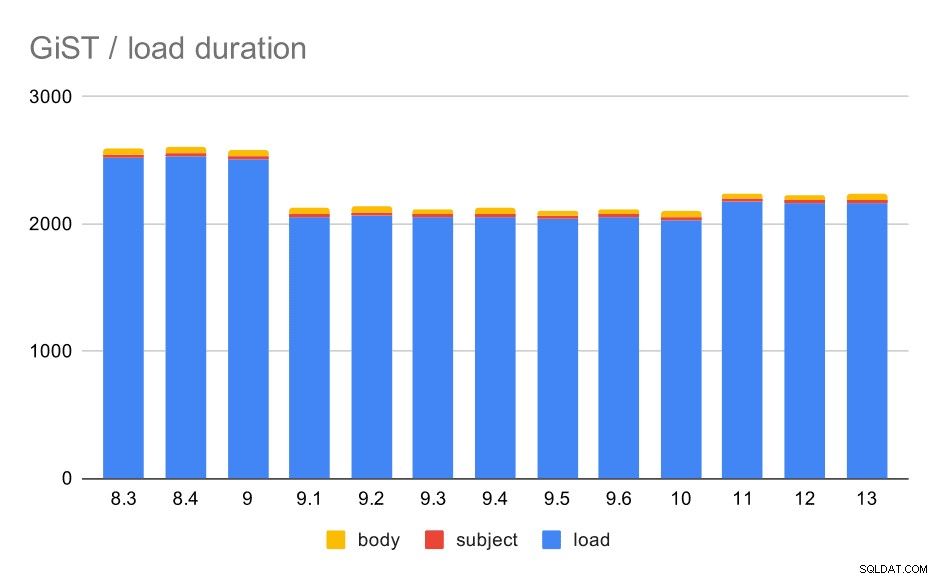
Operações de carregamento de dados com uma tabela e índices GiST.
| LOAD | ASSUNTO | BODY | |
| 8,3 | 2522 | 23 | 47 |
| 8,4 | 2527 | 23 | 49 |
| 9,0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9,2 | 2067 | 22 | 47 |
| 9,3 | 2049 | 23 | 46 |
| 9,4 | 2055 | 23 | 47 |
| 9,5 | 2038 | 22 | 45 |
| 9,6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
O tamanho do índice, no entanto, permaneceu quase constante - não houve melhorias no GiST semelhantes ao GIN em 9.4, o que reduziu o tamanho em ~30%. Há um aumento na 9.1, que é outro sinal de que a indexação de texto completo mudou nessa versão para indexar mais palavras.
Isso é ainda apoiado pelo número médio de resultados com GiST sendo exatamente o mesmo que para GIN (com um aumento de 9,1).
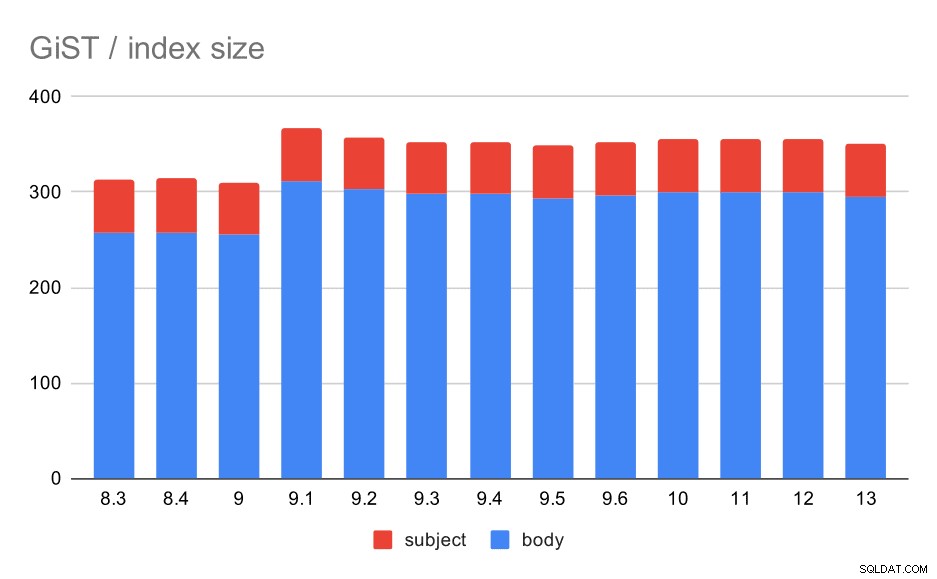
Tamanho dos índices GiST no assunto/corpo da mensagem. Os valores são megabytes.
| BODY | ASSUNTO | |
| 8,3 | 257 | 56 |
| 8,4 | 258 | 56 |
| 9,0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9,2 | 303 | 55 |
| 9,3 | 298 | 55 |
| 9,4 | 298 | 55 |
| 9,5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
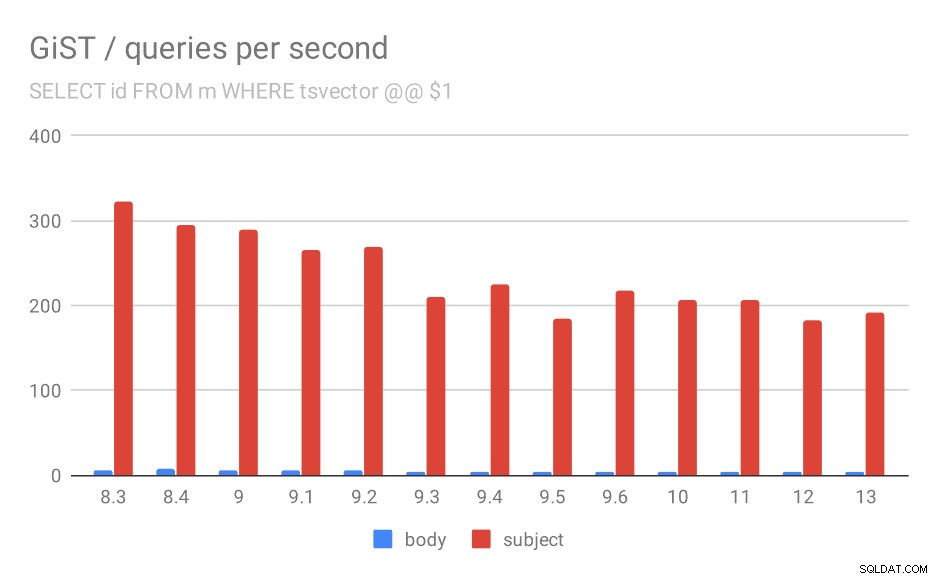
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
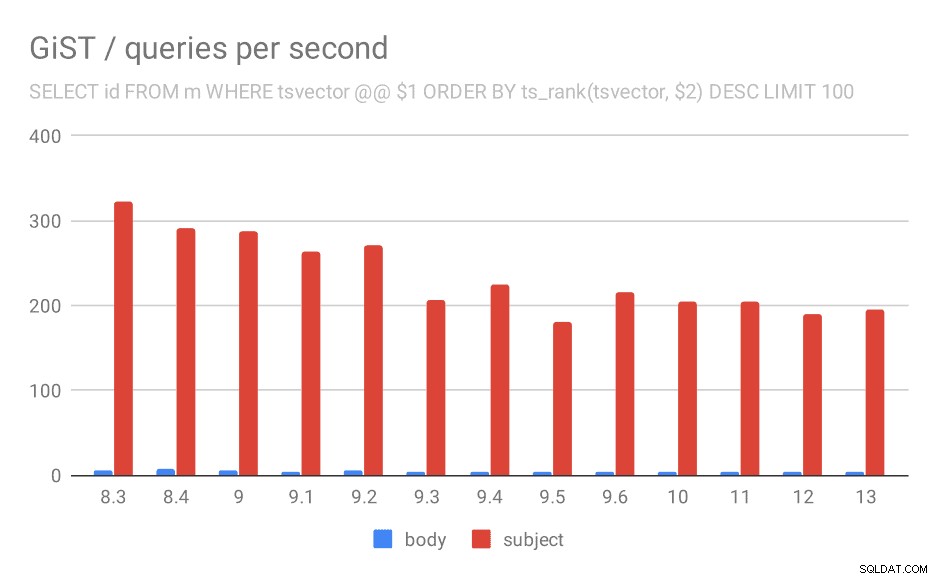
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).