Um dos muitos novos recursos introduzidos no SQL Server 2008 foi a compactação de dados. A compactação no nível da linha ou da página oferece uma oportunidade de economizar espaço em disco, com a compensação de exigir um pouco mais de CPU para compactar e descompactar os dados. Argumenta-se frequentemente que a maioria dos sistemas é vinculada a E/S, não vinculada à CPU, portanto, a troca vale a pena. A pegada? Você precisava estar no Enterprise Edition para usar a compactação de dados. Com o lançamento do SQL Server 2016 SP1, isso mudou! Se você estiver executando o Standard Edition do SQL Server 2016 SP1 e superior, agora poderá usar a compactação de dados. Há também uma nova função interna para compactação, COMPRESS (e sua contraparte DECOMPRESS). A compactação de dados não funciona em dados fora da linha, portanto, se você tiver uma coluna como NVARCHAR(MAX) em sua tabela com valores normalmente com mais de 8.000 bytes de tamanho, esses dados não serão compactados (obrigado Adam Machanic por esse lembrete) . A função COMPRESS resolve esse problema e comprime dados de até 2 GB de tamanho. Além disso, embora eu argumentasse que a função deveria ser usada apenas para dados grandes e fora de linha, pensei que compará-la diretamente com a compactação de linha e página era um experimento que valeria a pena.
CONFIGURAÇÃO
Para dados de teste, estou trabalhando a partir de um script que Aaron Bertrand usou anteriormente, mas fiz alguns ajustes. Criei um banco de dados separado para teste, mas você pode usar tempdb ou outro banco de dados de exemplo e, em seguida, comecei com uma tabela Customers que possui três colunas NVARCHAR. Considerei criar colunas maiores e preenchê-las com sequências de letras repetidas, mas usar texto legível fornece uma amostra mais realista e, portanto, oferece maior precisão.
Observação: Se você estiver interessado em implementar a compactação e quiser saber como ela afetará o armazenamento e o desempenho em seu ambiente, RECOMENDO ALTAMENTE QUE VOCÊ A TESTE. Estou dando a você a metodologia com dados de amostra; implementar isso em seu ambiente não deve envolver trabalho adicional.
Você observará abaixo que, após criar o banco de dados, estamos habilitando o Query Store. Por que criar uma tabela separada para tentar acompanhar nossas métricas de desempenho quando podemos apenas usar a funcionalidade integrada ao SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Agora vamos configurar algumas coisas dentro do banco de dados:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Com a tabela criada, adicionaremos alguns dados, mas estamos adicionando 5 milhões de linhas em vez de 1 milhão. Isso leva cerca de oito minutos para ser executado no meu laptop.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Agora vamos criar mais três tabelas:uma para compactação de linha, uma para compactação de página e uma para a função COMPRESS. Observe que com a função COMPRESS, você deve criar as colunas como tipos de dados VARBINARY. Como resultado, não há índices não clusterizados na tabela (já que você não pode criar uma chave de índice em uma coluna varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Em seguida, copiaremos os dados de [dbo].[Clientes] para as outras três tabelas. Este é um INSERT direto para nossas tabelas de páginas e linhas e leva cerca de dois a três minutos para cada INSERT, mas há um problema de escalabilidade com a função COMPRESS:tentar inserir 5 milhões de linhas de uma só vez não é razoável. O script abaixo insere linhas em lotes de 50.000 e insere apenas 1 milhão de linhas em vez de 5 milhões. Eu sei, isso significa que não somos realmente maçãs com maçãs aqui para comparação, mas estou bem com isso. Inserir 1 milhão de linhas leva 10 minutos na minha máquina; sinta-se à vontade para ajustar o script e inserir 5 milhões de linhas para seus próprios testes.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Com todas as nossas tabelas preenchidas, podemos fazer uma verificação de tamanho. Neste ponto, não implementamos a compactação ROW ou PAGE, mas a função COMPRESS foi usada:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
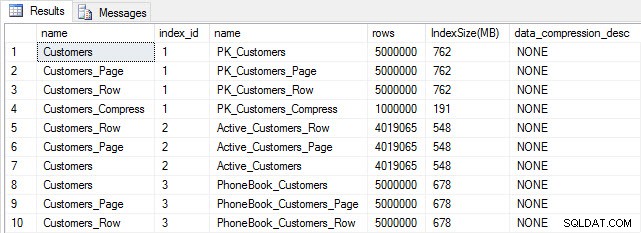 Tamanho da tabela e do índice após a inserção
Tamanho da tabela e do índice após a inserção Como esperado, todas as tabelas, exceto Customers_Compress, têm aproximadamente o mesmo tamanho. Agora vamos reconstruir os índices em todas as tabelas, implementando a compactação de linha e página em Customers_Row e Customers_Page, respectivamente.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Se verificarmos o tamanho da tabela após a compactação, agora podemos ver nossa economia de espaço em disco:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
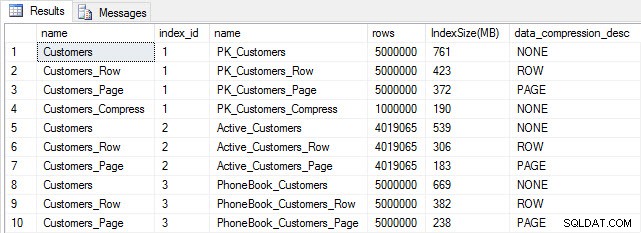
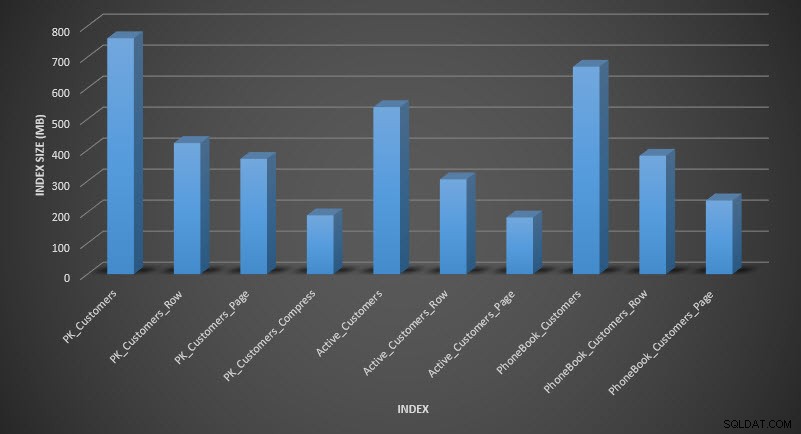 Tamanho do índice após compactação
Tamanho do índice após compactação Conforme esperado, a compactação de linha e página diminui significativamente o tamanho da tabela e seus índices. A função COMPRESS nos economizou mais espaço – o índice clusterizado é um quarto do tamanho da tabela original.
EXAME DO DESEMPENHO DA CONSULTA
Antes de testar o desempenho da consulta, observe que podemos usar o Repositório de Consultas para analisar o desempenho de INSERT e REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
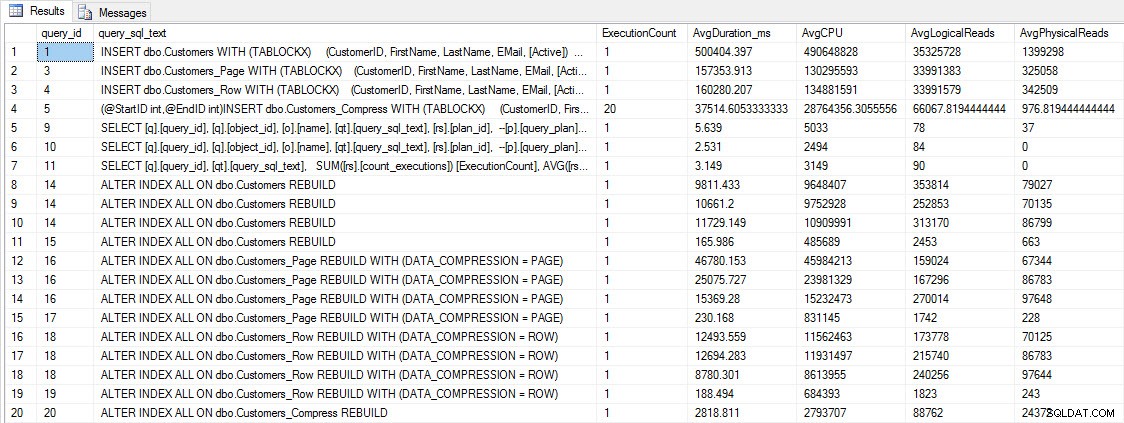 INSERIR e RECONSTRUIR métricas de desempenho
INSERIR e RECONSTRUIR métricas de desempenho Embora esses dados sejam interessantes, estou mais curioso sobre como a compactação afeta minhas consultas SELECT diárias. Eu tenho um conjunto de três procedimentos armazenados, cada um com uma consulta SELECT, para que cada índice seja usado. Criei esses procedimentos para cada tabela e, em seguida, escrevi um script para extrair valores para nomes e sobrenomes a serem usados para teste. Aqui está o script para criar os procedimentos.
Depois de criar os procedimentos armazenados, podemos executar o script abaixo para chamá-los. Dê o pontapé inicial e espere alguns minutos…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Após alguns minutos, dê uma olhada no que há no Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Você verá que a maioria dos procedimentos armazenados foi executada apenas 20 vezes porque dois procedimentos contra [dbo].[Customers_Compress] são realmente lento. Isso não é uma surpresa; nem [FirstName] nem [LastName] são indexados, portanto, qualquer consulta terá que varrer a tabela. Não quero que essas duas consultas retardem meus testes, então vou modificar a carga de trabalho e comentar EXEC [dbo].[usp_FindActiveCustomer_CS] e EXEC [dbo].[usp_FindAnyCustomer_CS] e depois iniciá-lo novamente. Desta vez, vou deixá-lo funcionar por cerca de 10 minutos, e quando eu olhar para a saída do Repositório de Consultas novamente, agora tenho alguns dados bons. Os números brutos estão abaixo, com os gráficos favoritos dos gerentes abaixo.
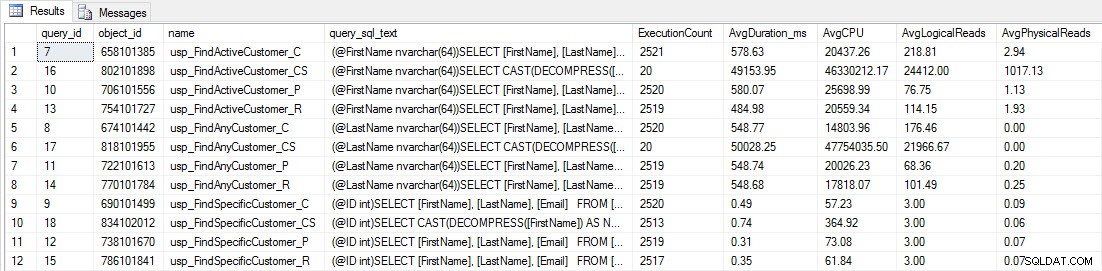 Dados de desempenho do Query Store
Dados de desempenho do Query Store 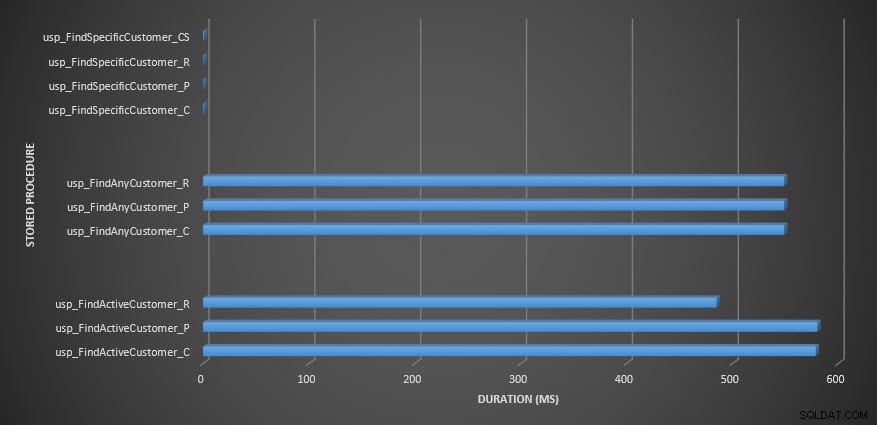 Duração do procedimento armazenado
Duração do procedimento armazenado 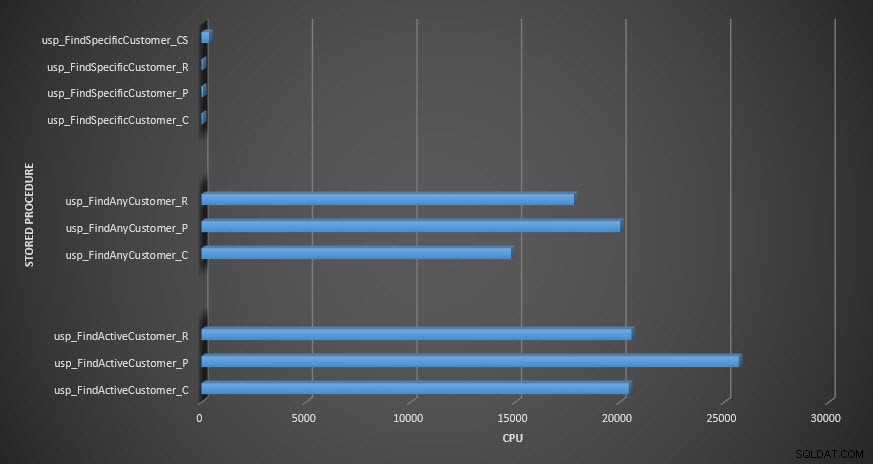 CPU de procedimento armazenado
CPU de procedimento armazenado Lembrete:Todos os procedimentos armazenados que terminam com _C são da tabela não compactada. Os procedimentos que terminam com _R são a tabela compactada por linha, aqueles que terminam com _P são compactados por página, e aquele com _CS usa a função COMPRESS (removi os resultados da referida tabela para usp_FindAnyCustomer_CS e usp_FindActiveCustomer_CS, pois distorceram tanto o gráfico que perdemos o diferenças no resto dos dados). Os procedimentos usp_FindAnyCustomer_* e usp_FindActiveCustomer_* usaram índices não clusterizados e retornaram milhares de linhas para cada execução.
Eu esperava que a duração fosse maior para os procedimentos usp_FindAnyCustomer_* e usp_FindActiveCustomer_* em relação às tabelas compactadas de linha e página, em comparação com a tabela não compactada, devido à sobrecarga de descompactar os dados. Os dados do Query Store não dão suporte à minha expectativa – a duração desses dois procedimentos armazenados é aproximadamente a mesma (ou menos em um caso!) nessas três tabelas. O IO lógico para as consultas era quase o mesmo nas tabelas não compactadas e compactadas de página e linha.
Em termos de CPU, nos procedimentos armazenados usp_FindActiveCustomer e usp_FindAnyCustomer sempre foi maior para as tabelas compactadas. A CPU era comparável para o procedimento usp_FindSpecificCustomer, que sempre era uma pesquisa singleton em relação ao índice clusterizado. Observe a CPU alta (mas duração relativamente baixa) para o procedimento usp_FindSpecificCustomer na tabela [dbo].[Customer_Compress], que exigia a função DECOMPRESS para exibir dados em formato legível.
RESUMO
A CPU adicional necessária para recuperar dados compactados existe e pode ser medida usando o Repositório de Consultas ou métodos tradicionais de linha de base. Com base neste teste inicial, a CPU é comparável para pesquisas singleton, mas aumenta com mais dados. Eu queria forçar o SQL Server a descompactar mais do que apenas 10 páginas – eu queria pelo menos 100. Executei variações deste script, onde dezenas de milhares de linhas foram retornadas e as descobertas foram consistentes com o que você vê aqui. Minha expectativa é que, para ver diferenças significativas na duração devido ao tempo para descompactar os dados, as consultas precisariam retornar centenas de milhares ou milhões de linhas. Se você estiver em um sistema OLTP, não deseja retornar tantas linhas, portanto, os testes aqui devem dar uma ideia de como a compactação pode afetar o desempenho. Se você estiver em um data warehouse, provavelmente verá uma duração mais alta junto com a CPU mais alta ao retornar grandes conjuntos de dados. Embora a função COMPRESS proporcione uma economia de espaço significativa em comparação com a compactação de páginas e linhas, a queda de desempenho em termos de CPU e a incapacidade de indexar as colunas compactadas devido ao seu tipo de dados a tornam viável apenas para grandes volumes de dados que não serão pesquisado.