Quando o SQL Server 2012 ainda estava em beta, eu escrevi sobre o novo
FORMAT() função:SQL Server v.Next (Denali):CTP3 T-SQL Aprimoramentos:FORMAT(). Naquela época, eu estava tão empolgado com a nova funcionalidade que nem pensei em fazer nenhum teste de desempenho. Eu abordei isso em uma postagem de blog mais recente, mas apenas no contexto de tirar o tempo de um datetime:Trimming time from datetime – a follow-up.
Na semana passada, meu bom amigo Jason Horner (blog | @jasonhorner) me trollou com esses tweets:
| |
Meu problema com isso é apenas que
FORMAT() parece conveniente, mas é extremamente ineficiente em comparação com outras abordagens (oh e isso AS VARCHAR coisa é ruim também). Se você estiver fazendo este one-twosy e para pequenos conjuntos de resultados, eu não me preocuparia muito com isso; mas em escala, pode ficar muito caro. Deixe-me ilustrar com um exemplo. Primeiro, vamos criar uma pequena tabela com 1000 datas pseudo-aleatórias:SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Agora, vamos preparar o cache com os dados desta tabela e ilustrar três das maneiras comuns pelas quais as pessoas tendem a apresentar apenas o momento:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Agora, vamos realizar consultas individuais que usam essas diferentes técnicas. Vamos executá-los a cada 5 vezes e executaremos as seguintes variações:
- Selecionando todas as 1.000 linhas
- Selecionar TOP (1) ordenado pela chave de índice clusterizado
- Atribuir a uma variável (o que força uma verificação completa, mas impede que a renderização do SSMS interfira no desempenho)
Aqui está o roteiro:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Agora, podemos medir o desempenho com a seguinte consulta (meu sistema é bastante silencioso; no seu, pode ser necessário realizar uma filtragem mais avançada do que apenas
execution_count ):SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Os resultados no meu caso foram bastante consistentes:
| Consulta (truncada) | Duração (microssegundos) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| SELECIONE 1.000 linhas | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time saída (clique para ampliar):
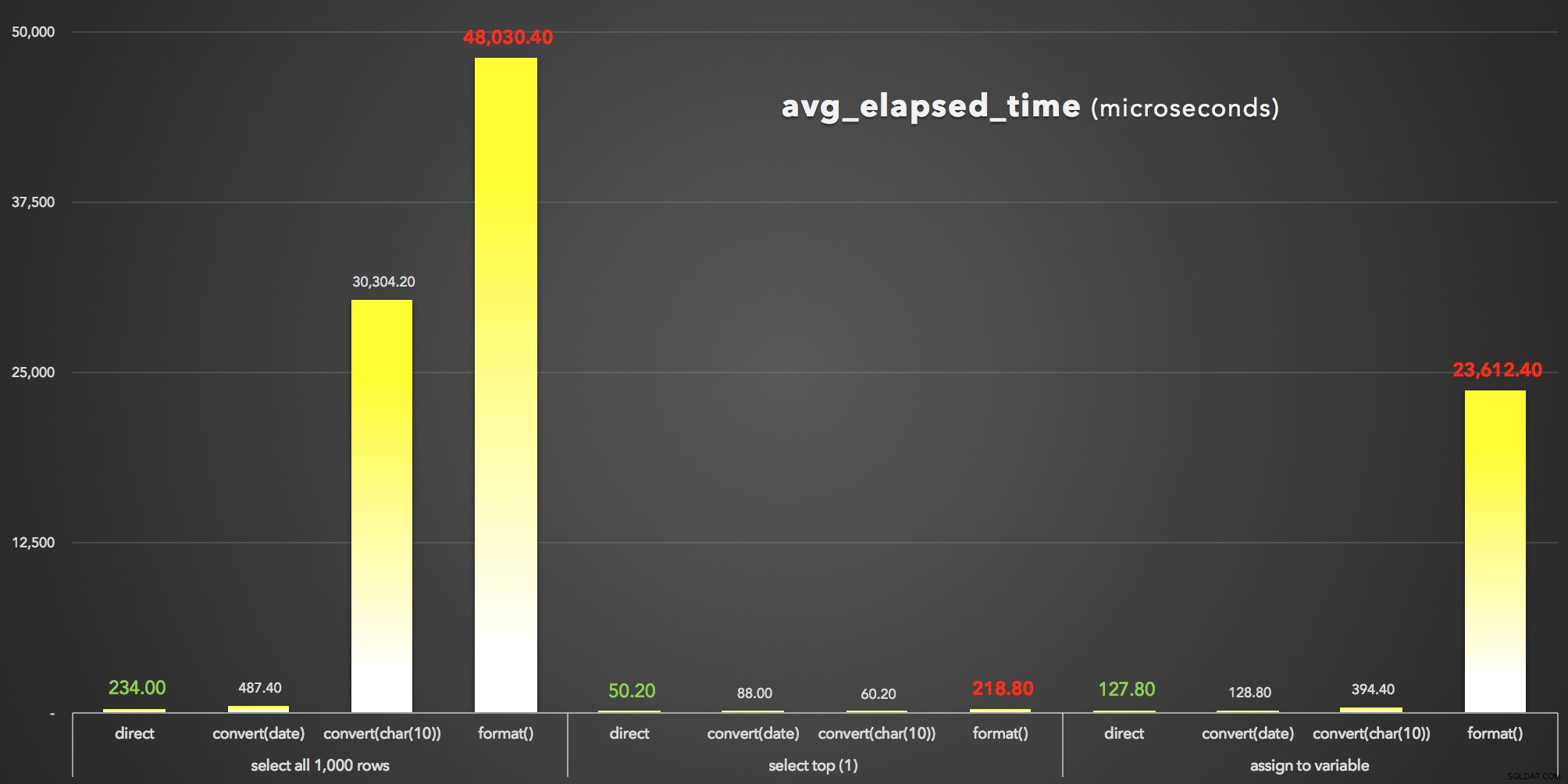 FORMAT() é claramente o perdedor:resultados avg_elapsed_time (microssegundos)
FORMAT() é claramente o perdedor:resultados avg_elapsed_time (microssegundos)
O que podemos aprender com esses resultados (novamente):
- Em primeiro lugar,
FORMAT()é caro . FORMAT()pode, reconhecidamente, fornecer mais flexibilidade e fornecer métodos mais intuitivos que são consistentes com aqueles em outras linguagens como C#. No entanto, além de sua sobrecarga, e enquantoCONVERT()os números de estilo são enigmáticos e menos exaustivos, você pode ter que usar a abordagem mais antiga de qualquer maneira, já queFORMAT()é válido apenas no SQL Server 2012 e mais recente.- Até o
CONVERT()de espera pode ser drasticamente caro (embora apenas severamente no caso em que o SSMS teve que renderizar os resultados - ele claramente lida com strings de maneira diferente dos valores de data). - Apenas extrair o valor datetime diretamente do banco de dados sempre foi mais eficiente. Você deve traçar o perfil de quanto tempo adicional leva para seu aplicativo formatar a data conforme desejado na camada de apresentação - é altamente provável que você não queira que o SQL Server se envolva com o formato bonito (e, de fato, muitos argumentariam que este é o lugar onde essa lógica sempre pertence).
Estamos falando apenas de microssegundos aqui, mas também estamos falando de apenas 1.000 linhas. Dimensione isso para seus tamanhos reais de tabela, e o impacto de escolher a abordagem de formatação errada pode ser devastador.
Se você quiser experimentar este experimento em sua própria máquina, enviei um script de exemplo:FormatIsNiceAndAllBut.sql_.zip



