É bom, mas às vezes pode ser ruim.
O sniffing de parâmetro é sobre o otimizador de consulta usando o valor do parâmetro fornecido para descobrir o melhor plano de consulta possível. Uma das muitas opções e que é bem fácil de entender é se a tabela inteira deve ser escaneada para obter os valores ou se será mais rápido usando buscas de índice. Se o valor em seu parâmetro for altamente seletivo o otimizador provavelmente construirá um plano de consulta com buscas e se não for a consulta fará uma varredura em sua tabela.
O plano de consulta é então armazenado em cache e reutilizado para consultas consecutivas que possuem valores diferentes. A parte ruim da detecção de parâmetros é quando o plano em cache não é a melhor escolha para um desses valores.
Dados de amostra:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T é uma tabela com alguns milhares de linhas com um índice não clusterizado em Valor. Há uma linha em que o valor é 1 e o resto tem o valor 2 . Exemplo de consulta:
select *
from T
where Value = @Value;
As opções que o otimizador de consultas tem aqui é fazer um Clustered Index Scan e verificar a cláusula where em cada linha ou usar um Index Seek para encontrar as linhas que correspondem e então fazer uma Key Lookup para obter os valores das colunas solicitadas em a lista de colunas.
Quando o valor farejado é
1 o plano de consulta ficará assim:
E quando o valor farejado é
2 Isso parecerá assim: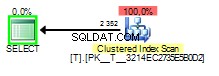
A parte ruim do sniffing de parâmetros neste caso acontece quando o plano de consulta é construído sniffing um
1 mas executado posteriormente com o valor de 2 . 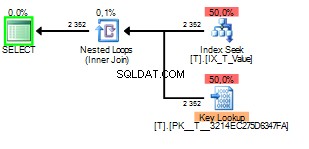
Você pode ver que o Key Lookup foi executado 2352 vezes. Uma varredura seria claramente a melhor escolha.
Para resumir, eu diria que o sniffing de parâmetros é uma coisa boa que você deve tentar fazer acontecer o máximo possível usando parâmetros para suas consultas. Às vezes, pode dar errado e, nesses casos, é mais provável que seja devido a dados distorcidos que estão mexendo com suas estatísticas.
Atualização:
Aqui está uma consulta a alguns dmvs que você pode usar para descobrir quais consultas são mais caras em seu sistema. Mude para ordem por cláusula para usar critérios diferentes sobre o que você está procurando. Acho que
TotalDuration é um bom lugar para começar. set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;