Como DBAs do SQL Server, ouvimos dizer que as estruturas de índice podem melhorar drasticamente o desempenho de qualquer consulta (ou conjunto de consultas). Ainda assim, existem certos detalhes que muitos DBAs ignoram, como o seguinte:
- As estruturas de índice podem se tornar fragmentadas, potencialmente levando a problemas de degradação de desempenho.
- Depois que uma estrutura de índice é implantada para uma tabela de banco de dados, o SQL Server a atualiza sempre que ocorrem operações de gravação para essa tabela. Isso acontece se as colunas em conformidade com o índice forem afetadas.
- Existem metadados dentro do SQL Server que podem ser usados para saber quando as estatísticas de uma estrutura de índice específica foram atualizadas (se alguma vez) pela última vez. Estatísticas insuficientes ou desatualizadas podem afetar o desempenho de determinadas consultas.
- Há metadados dentro do SQL Server que podem ser usados para saber o quanto uma estrutura de índice foi consumida por operações de leitura ou atualizada por operações de gravação pelo próprio SQL Server. Essas informações podem ser úteis para saber se existem índices cujo volume de gravação excede amplamente o de leitura. Pode ser potencialmente uma estrutura de índice que não é tão útil para manter.*
*É muito importante ter em mente que a visualização do sistema que contém esses metadados específicos é apagada toda vez que a instância do SQL Server é reiniciada, portanto, não será uma informação desde sua concepção.
Devido à importância desses detalhes, criei um Stored Procedure para acompanhar as informações sobre as estruturas de índice em seu ambiente, para agir da forma mais proativa possível.
Considerações iniciais
- Certifique-se de que a conta que executa este procedimento armazenado tenha privilégios suficientes. Você provavelmente poderia começar com os sysadmin e, em seguida, ir o mais granular possível para garantir que o usuário tenha o mínimo de privilégios necessários para que o SP funcione corretamente.
- Os objetos de banco de dados (tabela de banco de dados e procedimento armazenado) serão criados dentro do banco de dados selecionado no momento em que o script for executado, portanto, escolha com cuidado.
- O script é criado de forma que possa ser executado várias vezes sem gerar um erro. Para o procedimento armazenado, usei a instrução CREATE OR ALTER PROCEDURE, disponível desde o SQL Server 2016 SP1.
- Sinta-se à vontade para alterar o nome dos objetos de banco de dados criados se quiser usar uma convenção de nomenclatura diferente.
- Quando você opta por persistir os dados retornados pelo procedimento armazenado, a tabela de destino será truncada primeiro para que apenas o conjunto de resultados mais recente seja armazenado. Você pode fazer os ajustes necessários se quiser que isso se comporte de maneira diferente, por qualquer motivo (para manter informações históricas, talvez?).
Como usar o procedimento armazenado?
- Copie e cole o código T-SQL (disponível neste artigo).
- O SP espera 2 parâmetros:
- @persistData:'S' se o DBA desejar salvar a saída em uma tabela de destino e 'N' se o DBA quiser apenas ver a saída diretamente.
- @db:'all' para obter as informações de todos os bancos de dados (sistema e usuário), 'user' para direcionar bancos de dados de usuários, 'system' para direcionar apenas bancos de dados do sistema (excluindo tempdb) e, por último, o nome real de um banco de dados específico.
Campos apresentados e seu significado
- dbName: o nome do banco de dados onde o objeto de índice reside.
- nome do esquema: o nome do esquema onde o objeto de índice reside.
- tableName: o nome da tabela onde reside o objeto de índice.
- indexName: o nome da estrutura do índice.
- tipo: o tipo de índice (por exemplo, agrupado, não agrupado).
- allocation_unit_type: especifica o tipo de dado referente (por exemplo, dados em linha, dados lob).
- fragmentação: a quantidade de fragmentação (em %) que a estrutura do índice tem atualmente.
- páginas: o número de páginas de 8 KB que formam a estrutura de índice.
- escreve: o número de gravações que a estrutura de índice sofreu desde que a instância do SQL Server foi reiniciada pela última vez.
- lê: o número de leituras que a estrutura de índice teve desde que a instância do SQL Server foi reiniciada pela última vez.
- desativado: 1 se a estrutura de índice estiver desabilitada no momento ou 0 se a estrutura estiver habilitada.
- stats_timestamp: o valor do carimbo de data/hora de quando as estatísticas para a estrutura de índice específica foram atualizadas pela última vez (NULL se nunca).
- data_collection_timestamp: visível apenas se ‘Y’ for passado para o parâmetro @persistData, e é usado para saber quando o SP foi executado e as informações foram salvas com sucesso na tabela DBA_Indexes.
Testes de execução
Vou demonstrar algumas execuções do Stored Procedure para que você tenha uma ideia do que esperar dele:
*Você pode encontrar o código T-SQL completo do script no final deste artigo, portanto, certifique-se de executá-lo antes de prosseguir com a seção a seguir.
*O conjunto de resultados será muito grande para caber perfeitamente em uma captura de tela, então compartilharei todas as capturas de tela necessárias para apresentar as informações completas.
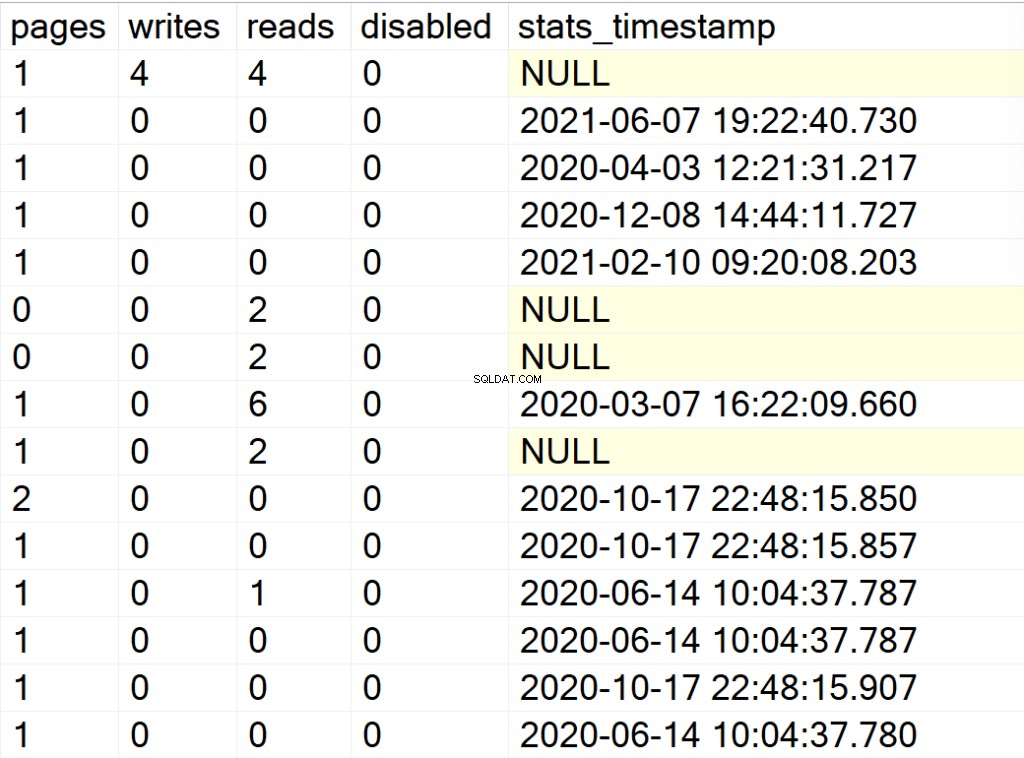
/* Exibe todas as informações de índices para todos os bancos de dados do sistema e do usuário */
EXEC GetIndexData @persistData = 'N',@db = 'all'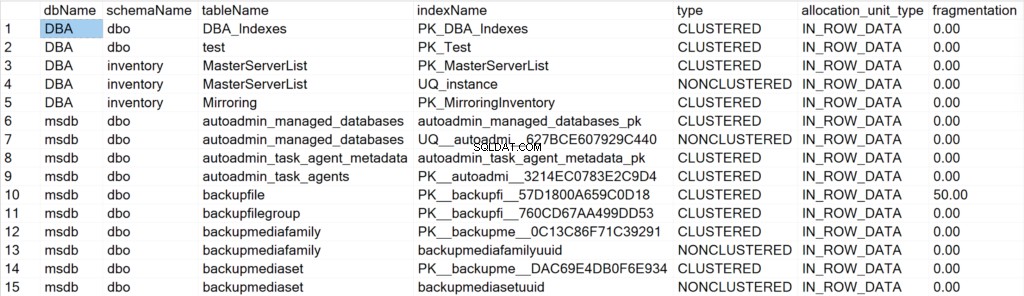
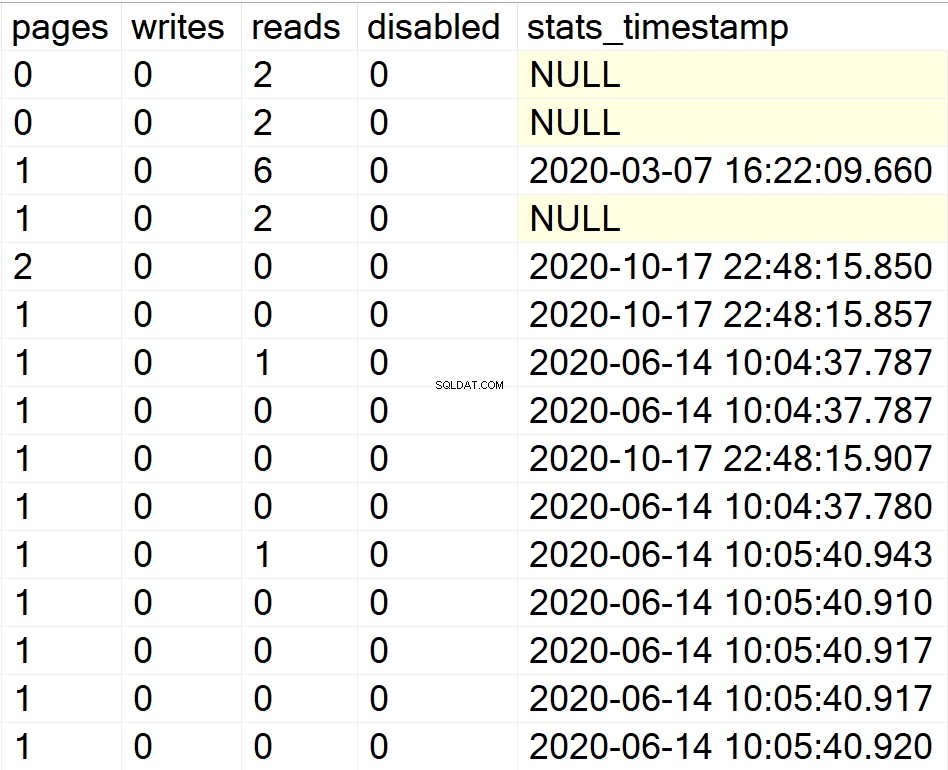
/* Exibe todas as informações de índices para todos os bancos de dados do sistema */
EXEC GetIndexData @persistData = 'N',@db = 'system'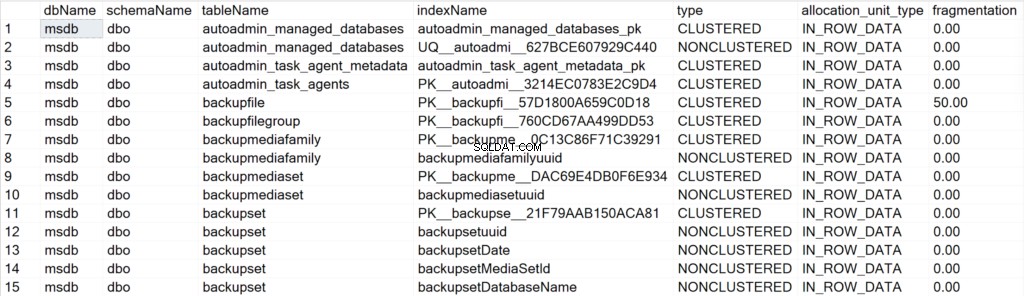
/* Exibe todas as informações de índices para todos os bancos de dados de usuários */
EXEC GetIndexData @persistData = 'N',@db = 'user'
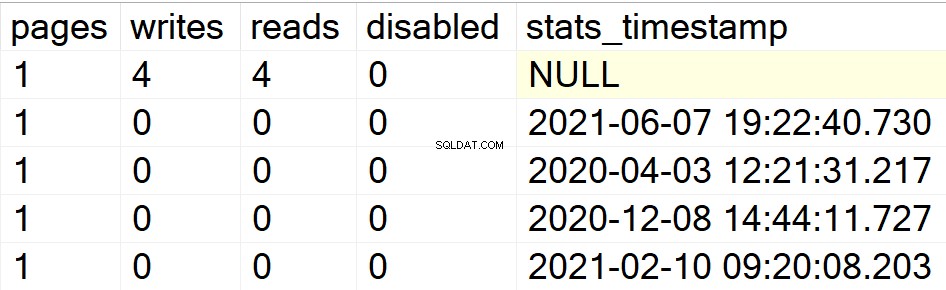
/* Exibe todas as informações de índices para bancos de dados de usuários específicos */
Em meus exemplos anteriores, apenas o banco de dados DBA apareceu como meu único banco de dados de usuário com índices nele. Portanto, deixe-me criar uma estrutura de índice em outro banco de dados que tenho na mesma instância para que você possa ver se o SP faz o que quer ou não.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Todos os exemplos apresentados até agora demonstram a saída que você obtém quando não deseja persistir os dados, para as diferentes combinações de opções para o parâmetro @db. A saída está vazia quando você especifica uma opção que não é válida ou o banco de dados de destino não existe. Mas e quando o DBA deseja persistir dados em uma tabela de banco de dados? Vamos descobrir.
*Vou executar o SP para um caso apenas porque o restante das opções para o parâmetro @db foi exibido acima e o resultado é o mesmo, mas persistiu em uma tabela de banco de dados.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
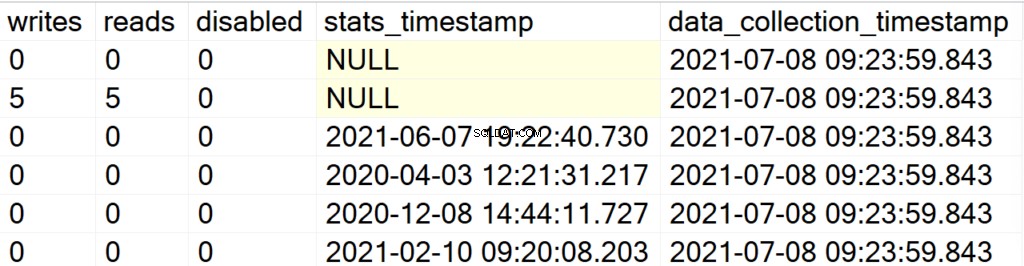
Agora, depois de executar o procedimento armazenado, você não obterá nenhuma saída. Para consultar o conjunto de resultados, você deve emitir uma instrução SELECT na tabela DBA_Indexes. A principal atração aqui é que você pode consultar o conjunto de resultados obtido, para pós-análise, e a adição do campo data_collection_timestamp que informará quão recentes/antigos são os dados que você está analisando.
Consultas secundárias
Agora, para entregar mais valor ao DBA, preparei algumas consultas que podem ajudá-lo a obter informações úteis a partir dos dados persistidos na tabela.
*Consulta para encontrar índices muito fragmentados em geral.
*Escolha o número de % que você considera adequado.
*As 1500 páginas são baseadas em um artigo que li, com base na recomendação da Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Consulta para encontrar índices desabilitados em seu ambiente.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Consulta para localizar índices (principalmente não clusterizados) que não são muito usados por consultas, pelo menos não desde a última vez que a instância do SQL Server foi reiniciada.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Consulte para encontrar estatísticas que nunca foram atualizadas ou são antigas.
*Você determina o que é antigo em seu ambiente, portanto, certifique-se de ajustar o número de dias de acordo.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Aqui está o código completo do procedimento armazenado:
*No início do script, você verá o valor padrão que o procedimento armazenado assume se nenhum valor for passado para cada parâmetro.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusão
- Você pode implantar este SP em todas as instâncias do SQL Server sob seu suporte e implementar um mecanismo de alerta em toda a sua pilha de instâncias com suporte.
- Se você implementar um trabalho de agente que está consultando essas informações com relativa frequência, poderá ficar no topo do jogo para cuidar das estruturas de índice em seus ambientes suportados.
- Certifique-se de testar esse mecanismo corretamente em um ambiente de sandbox e, ao planejar uma implantação de produção, certifique-se de escolher períodos de baixa atividade.
Os problemas de fragmentação do índice podem ser complicados e estressantes. Para encontrá-los e corrigi-los, você pode usar diferentes ferramentas, como o dbForge Index Manager, que pode ser baixado aqui.



