O tipo e o número de bloqueios adquiridos e liberados durante a execução da consulta podem ter um efeito surpreendente no desempenho (ao usar um nível de isolamento de bloqueio como a leitura padrão confirmada) mesmo quando não ocorre espera ou bloqueio. Não há informações nos planos de execução para indicar a quantidade de atividade de bloqueio durante a execução, o que torna mais difícil identificar quando o bloqueio excessivo está causando um problema de desempenho.
Para explorar alguns comportamentos de bloqueio menos conhecidos no SQL Server, reutilizarei as consultas e os dados de exemplo do meu último post sobre cálculo de medianas. Nesse post, mencionei que o
OFFSET solução mediana agrupada precisava de um PAGLOCK explícito dica de bloqueio para evitar perder muito para o cursor aninhado solução, então vamos começar analisando as razões para isso em detalhes. A solução mediana agrupada OFFSET
O teste de mediana agrupado reutilizou os dados de amostra do artigo anterior de Aaron Bertrand. O script abaixo recria essa configuração de um milhão de linhas, consistindo em dez mil registros para cada uma das cem pessoas de vendas imaginárias:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); O SQL Server 2012 (e posterior)
OFFSET solução criada por Peter Larsson é a seguinte (sem dicas de bloqueio):DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); As partes importantes do plano pós-execução são mostradas abaixo:

Com todos os dados necessários na memória, esta consulta é executada em 580 ms em média no meu laptop (executando o SQL Server 2014 Service Pack 1). O desempenho desta consulta pode ser melhorado para 320 ms simplesmente adicionando uma dica de bloqueio de granularidade de página à tabela Sales na subconsulta apply:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); O plano de execução permanece inalterado (bem, além do texto da dica de bloqueio no XML do showplan, é claro):
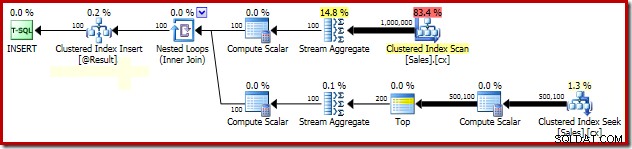
Análise de bloqueio de mediana agrupada
A explicação para a melhoria dramática no desempenho devido ao
PAGLOCK dica é bastante simples, pelo menos inicialmente. Se monitorarmos manualmente a atividade de bloqueio durante a execução dessa consulta, veremos que, sem a dica de granularidade de bloqueio de página, o SQL Server adquire e libera mais de meio milhão de bloqueios em nível de linha enquanto procura o índice clusterizado. Não há nenhum bloqueio para culpar; simplesmente adquirir e liberar tantos bloqueios adiciona uma sobrecarga substancial à execução dessa consulta. A solicitação de bloqueios no nível da página reduz bastante a atividade de bloqueio, resultando em um desempenho muito melhor.
O problema de desempenho de bloqueio desse plano específico está confinado à busca de índice clusterizado no plano acima. A varredura completa do índice clusterizado (usado para calcular o número de linhas presentes para cada vendedor) usa bloqueios de nível de página automaticamente. Este é um ponto interessante. O comportamento de bloqueio detalhado do mecanismo do SQL Server não está documentado em grande parte nos Manuais Online, mas vários membros da equipe do SQL Server fizeram algumas observações gerais ao longo dos anos, incluindo o fato de que as verificações irrestritas tendem a começar bloqueios, enquanto as operações menores tendem a começar com bloqueios de linha.
O otimizador de consulta disponibiliza algumas informações para o mecanismo de armazenamento, incluindo estimativas de cardinalidade, dicas internas para nível de isolamento e granularidade de bloqueio, quais otimizações internas podem ser aplicadas com segurança e assim por diante. Novamente, esses detalhes não estão documentados nos Manuais Online. No final, o mecanismo de armazenamento usa uma variedade de informações para decidir quais bloqueios são necessários em tempo de execução e em qual granularidade eles devem ser executados.
Como uma observação lateral, e lembrando que estamos falando de uma consulta em execução no nível de isolamento de transação confirmada de leitura de bloqueio padrão, observe que os bloqueios de linha obtidos sem a dica de granularidade não serão escalados para um bloqueio de tabela nesse caso. Isso ocorre porque o comportamento normal sob leitura confirmada é liberar o bloqueio anterior antes de adquirir o próximo bloqueio, o que significa que apenas um único bloqueio de linha compartilhado (com seus bloqueios compartilhados de intenção de nível superior associados) será mantido em um determinado momento. Como o número de bloqueios de linha mantidos simultaneamente nunca atinge o limite, nenhuma escalação de bloqueio é tentada.
A Solução Mediana Única OFFSET
O teste de desempenho para um único cálculo de mediana usa um conjunto diferente de dados de amostra, novamente reproduzidos do artigo anterior de Aaron. O script abaixo cria uma tabela com dez milhões de linhas de dados pseudo-aleatórios:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); O
OFFSET solução é:DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O plano pós-execução é:

Esta consulta é executada em 910 ms em média na minha máquina de teste. O desempenho permanece inalterado se um
PAGLOCK dica é adicionada, mas a razão para isso não é o que você pode estar pensando… Análise de bloqueio de mediana única
Você pode estar esperando que o mecanismo de armazenamento escolha bloqueios compartilhados em nível de página de qualquer maneira, devido à varredura de índice clusterizado, explicando por que um
PAGLOCK dica não tem efeito. Na verdade, monitorar os bloqueios obtidos durante a execução dessa consulta revela que nenhum bloqueio compartilhado (S) é obtido, em qualquer granularidade . Os únicos bloqueios são compartilhados por intenção (IS) no nível do objeto e da página. A explicação para esse comportamento vem em duas partes. A primeira coisa a notar é que o Clustered Index Scan está abaixo de um operador Top no plano de execução. Isso tem um efeito importante nas estimativas de cardinalidade, conforme mostrado no plano de pré-execução (estimado):

O
OFFSET e FETCH cláusulas na consulta fazem referência a uma expressão e uma variável, de modo que o otimizador de consulta adivinha o número de linhas que serão necessárias em tempo de execução. A estimativa padrão para Top é de cem linhas. Claro que isso é um palpite terrível, mas é suficiente para convencer o mecanismo de armazenamento a travar na granularidade de linha em vez de no nível da página. Se desabilitarmos o efeito "objetivo de linha" do operador Top usando o sinalizador de rastreamento documentado 4138, o número estimado de linhas na varredura será alterado para dez milhões (o que ainda está errado, mas na outra direção). Isso é suficiente para alterar a decisão de granularidade de bloqueio do mecanismo de armazenamento, de modo que os bloqueios compartilhados no nível da página (observação, não bloqueios compartilhados por intenção) sejam usados:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O plano de execução estimado produzido sob o sinalizador de rastreamento 4138 é:

Voltando ao exemplo principal, a estimativa de cem linhas devido à meta de linha adivinhada significa que o mecanismo de armazenamento opta por travar no nível da linha. No entanto, só observamos bloqueios compartilhados por intenção (IS) no nível da tabela e da página. Esses bloqueios de nível superior seriam bastante normais se víssemos bloqueios compartilhados (S) em nível de linha, então para onde eles foram?
A resposta é que o mecanismo de armazenamento contém outra otimização que pode ignorar os bloqueios compartilhados em nível de linha em determinadas circunstâncias. Quando essa otimização é aplicada, os bloqueios compartilhados por intenção de nível superior ainda são adquiridos.
Para resumir, para a consulta de mediana única:
- O uso de uma variável e expressão no
OFFSETcláusula significa que o otimizador adivinha a cardinalidade. - A estimativa baixa significa que o mecanismo de armazenamento decide sobre uma estratégia de bloqueio em nível de linha.
- Uma otimização interna significa que os bloqueios S no nível da linha são ignorados no tempo de execução, deixando apenas os bloqueios IS no nível da página e do objeto.
A consulta mediana única teria o mesmo problema de desempenho de bloqueio de linha que a mediana agrupada (devido à estimativa imprecisa do otimizador de consulta), mas foi salva por uma otimização de mecanismo de armazenamento separada que resultou em apenas bloqueios de página e tabela compartilhados por intenção. em tempo de execução.
O teste da mediana agrupada revisitado
Você pode estar se perguntando por que o Clustered Index Seek no teste de mediana agrupada não aproveitou a mesma otimização do mecanismo de armazenamento para ignorar bloqueios compartilhados em nível de linha. Por que tantos bloqueios de linha compartilhados foram usados, tornando o
PAGLOCK dica necessária? A resposta curta é que esta otimização não está disponível para
INSERT...SELECT consultas. Se executarmos o SELECT por conta própria (ou seja, sem gravar os resultados em uma tabela) e sem um PAGLOCK dica, a otimização de salto de bloqueio de linha é aplicado:DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Somente bloqueios de compartilhamento de intenção (IS) no nível da tabela e da página são usados, e o desempenho aumenta para o mesmo nível de quando usamos o
PAGLOCK dica. Você não encontrará esse comportamento na documentação, é claro, e ele pode mudar a qualquer momento. Ainda assim, é bom estar atento. Além disso, caso você esteja se perguntando, o sinalizador de rastreamento 4138 não tem efeito sobre a escolha de granularidade de bloqueio do mecanismo de armazenamento neste caso porque o número estimado de linhas na busca é muito baixo (por iteração de aplicação) mesmo com a meta de linha desabilitada.
Antes de tirar conclusões sobre o desempenho de uma consulta, certifique-se de verificar o número e o tipo de bloqueios que ela está realizando durante a execução. Embora o SQL Server geralmente escolha a granularidade 'correta', há momentos em que pode dar errado, às vezes com efeitos dramáticos no desempenho.