[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Na parte 3 desta série, mostrei duas soluções alternativas para evitar ampliar uma
IDENTITY coluna – uma que simplesmente ganha tempo e outra que abandona IDENTITY completamente. O primeiro evita que você tenha que lidar com dependências externas, como chaves estrangeiras, mas o último ainda não resolve esse problema. Neste post, eu queria detalhar a abordagem que eu usaria se eu realmente precisasse migrar para bigint , precisava minimizar o tempo de inatividade e tinha muito tempo para planejar. Por causa de todos os bloqueadores em potencial e da necessidade de interrupção mínima, a abordagem pode ser vista como um pouco complexa, e só se torna mais complexa se recursos exóticos adicionais estiverem sendo usados (por exemplo, particionamento, OLTP na memória ou replicação) .
Em um nível muito alto, a abordagem é criar um conjunto de tabelas sombra, onde todas as inserções são direcionadas para uma nova cópia da tabela (com o tipo de dados maior), e a existência dos dois conjuntos de tabelas é tão transparente possível para o aplicativo e seus usuários.
Em um nível mais granular, o conjunto de etapas seria o seguinte:
- Crie cópias de sombra das tabelas com os tipos de dados corretos.
- Altere os procedimentos armazenados (ou código ad hoc) para usar bigint para parâmetros. (Isso pode exigir modificações além da lista de parâmetros, como variáveis locais, tabelas temporárias, etc., mas não é o caso aqui.)
- Renomeie as tabelas antigas e crie visualizações com os nomes que unem as tabelas antigas e novas.
- Essas visualizações terão em vez de acionadores para direcionar adequadamente as operações DML para as tabelas apropriadas, para que os dados ainda possam ser modificados durante a migração.
- Isso também exige que SCHEMABINDING seja removido de todas as visualizações indexadas, visualizações existentes que tenham uniões entre tabelas novas e antigas e que os procedimentos que dependem de SCOPE_IDENTITY() sejam modificados.
- Migre os dados antigos para as novas tabelas em partes.
- Limpeza, composta por:
- Eliminar as visualizações temporárias (que eliminarão os gatilhos INSTEAD OF).
- Renomeando as novas tabelas de volta para os nomes originais.
- Corrigindo os procedimentos armazenados para reverter para SCOPE_IDENTITY().
- Eliminar as tabelas antigas e agora vazias.
- Colocando SCHEMABINDING de volta em visualizações indexadas e recriando índices clusterizados.
Você provavelmente pode evitar muitas visualizações e gatilhos se puder controlar todo o acesso a dados por meio de procedimentos armazenados, mas como esse cenário é raro (e impossível confiar 100%), vou mostrar a rota mais difícil.
Esquema inicial
Em um esforço para manter essa abordagem o mais simples possível, enquanto ainda aborda muitos dos bloqueadores que mencionei anteriormente na série, vamos supor que temos este esquema:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Portanto, uma tabela de pessoal simples, com uma coluna IDENTITY clusterizada, um índice não clusterizado, uma coluna computada com base na coluna IDENTITY, uma exibição indexada e uma tabela HR/dirt separada que possui uma chave estrangeira de volta à tabela pessoal (I não estou necessariamente incentivando esse design, apenas usando-o para este exemplo). Essas são todas as coisas que tornam esse problema mais complicado do que seria se tivéssemos uma tabela independente e independente.
Com esse esquema, provavelmente temos alguns procedimentos armazenados que fazem coisas como CRUD. Estes são mais por causa da documentação do que qualquer outra coisa; Vou fazer alterações no esquema subjacente de modo que a alteração desses procedimentos seja mínima. Isso é para simular o fato de que alterar o SQL ad hoc de seus aplicativos pode não ser possível e pode não ser necessário (bem, desde que você não esteja usando um ORM que possa detectar tabela versus exibição).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Agora, vamos adicionar 5 linhas de dados às tabelas originais:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Passo 1 – novas tabelas
Aqui, criaremos um novo par de tabelas, espelhando as originais, exceto o tipo de dados das colunas EmployeeID, a semente inicial da coluna IDENTITY e um sufixo temporário nos nomes:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Etapa 2 – corrigir os parâmetros do procedimento
Os procedimentos aqui (e potencialmente seu código ad hoc, a menos que já esteja usando o tipo inteiro maior) precisarão de uma alteração muito pequena para que no futuro possam aceitar valores EmployeeID além dos limites superiores de um inteiro. Embora você possa argumentar que, se for alterar esses procedimentos, poderá simplesmente apontá-los para as novas tabelas, estou tentando argumentar que você pode atingir o objetivo final com uma intrusão *mínima* no existente e permanente código.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Etapa 3 – visualizações e acionadores
Infelizmente, isso não pode *tudo* ser feito silenciosamente. Podemos fazer a maioria das operações em paralelo e sem afetar o uso simultâneo, mas por causa do SCHEMABINDING, a visão indexada precisa ser alterada e o índice posteriormente recriado.
Isso vale para qualquer outro objeto que use SCHEMABINDING e faça referência a qualquer uma de nossas tabelas. Eu recomendo alterá-lo para ser uma exibição não indexada no início da operação e apenas reconstruir o índice uma vez depois que todos os dados forem migrados, em vez de várias vezes no processo (já que as tabelas serão renomeadas várias vezes). Na verdade o que vou fazer é mudar a visão para unir as versões nova e antiga da tabela Employees durante o processo.
Outra coisa que precisamos fazer é alterar o procedimento armazenado Employee_Add para usar @@IDENTITY em vez de SCOPE_IDENTITY(), temporariamente. Isso ocorre porque o gatilho INSTEAD OF que manipulará novas atualizações para "Employees" não terá visibilidade do valor SCOPE_IDENTITY(). Isso, é claro, pressupõe que as tabelas não tenham gatilhos posteriores que afetarão @@IDENTITY. Espero que você possa alterar essas consultas dentro de um procedimento armazenado (onde você pode simplesmente apontar o INSERT para a nova tabela), ou o código do seu aplicativo não precisa depender de SCOPE_IDENTITY() em primeiro lugar.
Faremos isso em SERIALIZABLE para que nenhuma transação tente se infiltrar enquanto os objetos estiverem em fluxo. Este é um conjunto de operações em grande parte somente de metadados, portanto, deve ser rápido.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Etapa 4 – Migrar dados antigos para uma nova tabela
Vamos migrar dados em partes para minimizar o impacto na simultaneidade e no log de transações, pegando emprestado a técnica básica de um post antigo meu, "Quebrar grandes operações de exclusão em partes". Vamos executar esses lotes em SERIALIZABLE também, o que significa que você deve ter cuidado com o tamanho do lote, e deixei de lado o tratamento de erros por brevidade.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Resultados:
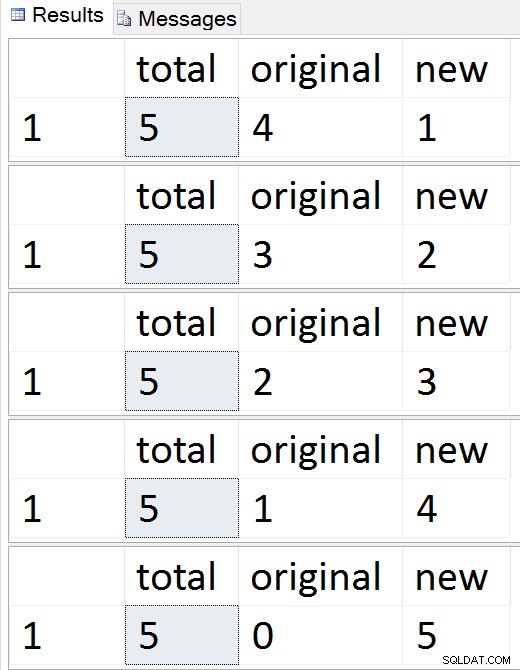 Veja as linhas migrarem uma a uma
Veja as linhas migrarem uma a uma A qualquer momento durante essa sequência, você pode testar inserções, atualizações e exclusões, e elas devem ser tratadas adequadamente. Quando a migração estiver concluída, você poderá prosseguir para o restante do processo.
Etapa 5 - Limpeza
Uma série de etapas é necessária para limpar os objetos que foram criados temporariamente e para restaurar Employees / EmployeeFile como cidadãos de primeira classe adequados. Muitos desses comandos são simplesmente operações de metadados – com exceção da criação do índice clusterizado na exibição indexada, todos eles devem ser instantâneos.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO Nesse ponto, tudo deve estar de volta à operação normal, embora você possa querer considerar as atividades típicas de manutenção após grandes alterações de esquema, como atualização de estatísticas, reconstrução de índices ou remoção de planos do cache.
Conclusão
Esta é uma solução bastante complexa para o que deveria ser um problema simples. Espero que em algum momento o SQL Server torne possível fazer coisas como adicionar/remover a propriedade IDENTITY, reconstruir índices com novos tipos de dados de destino e alterar colunas em ambos os lados de um relacionamento sem sacrificar o relacionamento. Enquanto isso, gostaria de saber se essa solução ajuda você ou se você tem uma abordagem diferente.
Um grande salve para James Lupolt (@jlupoltsql) por ajudar a verificar a sanidade da minha abordagem e colocá-la no teste final em uma de suas próprias tabelas reais. (Correu bem. Obrigado James!)
—
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]