Passei uma semana na magnífica cidade de Lisboa participando da Conferência Anual Europeia do PostgeSQL. Isso marcou o 10º aniversário desde a primeira conferência europeia do PostgreSQL e minha sexta participação.
Primeiras impressões
A cidade estava ótima, o ambiente estava ótimo e parecia que seria uma semana muito produtiva e informativa cheia de conversas interessantes com pessoas inteligentes e simpáticas. Então, basicamente, a primeira coisa legal que aprendi em Lisboa é como Lisboa e Portugal são ótimos, mas acho que você veio aqui para o resto da história!


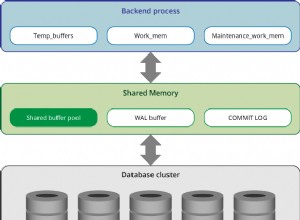
Buffers compartilhados
Participamos da sessão de treinamento “PostgreSQL DBA toolbelt for day-to-day ops”
por Kaarel Moppel (Cybertec) . Uma coisa que notei foi a configuração de shared_buffers. Como shared_buffers realmente compete ou complementa o cache do sistema, não deve ser definido para nenhum valor entre 25% e 75% do total de RAM disponível. Portanto, embora, em geral, a configuração recomendada para cargas de trabalho típicas seja 25% de RAM, ela pode ser definida como>=75% para casos especiais, mas não no meio.
Outras coisas que aprendemos nesta sessão:
- infelizmente, a ativação/ativação on-line (ou off-line) fácil de somas de verificação de dados ainda não está em 11 (initdb/replicação lógica continua sendo a única opção)
- cuidado com vm.overcommit_memory, é melhor desativá-lo configurando-o como 2. Defina vm.overcommit_ratio para cerca de 80.
Replicação lógica avançada

Na conversa de Petr Jelinek (2º Quadrante) , os autores originais da replicação lógica, aprendemos sobre usos mais avançados dessa nova e empolgante tecnologia:
- Coleta de dados centralizada:podemos ter vários editores e, em seguida, um sistema central com um assinante para cada um desses editores, disponibilizando dados de várias fontes em um sistema central. (uso típico:OLAP)
- Dados globais compartilhados ou, em outras palavras, um sistema central para manter dados e parâmetros globais (como moedas, ações, valores de mercado/mercadoria, clima etc.) que são publicados para um ou mais assinantes. Em seguida, esses dados são mantidos apenas em um sistema, mas disponíveis em todos os assinantes.
- A replicação lógica pode ser assíncrona, mas também síncrona (garantida na confirmação)
- Novas possibilidades com decodificação lógica:
- integração com Debezium/Kafka via plugins de decodificação lógica
- plug-in wal2json
- Replicação bidirecional
- Atualizações de tempo de inatividade quase zero:
- configurar a replicação lógica no novo servidor (possivelmente initdb com a ativação de somas de verificação de dados)
- aguarde até que o atraso seja relativamente pequeno
- do pgbouncer pausar o(s) banco(s) de dados
- aguarde até que o atraso seja zero
- altere a configuração do pgbouncer para apontar para o novo servidor, recarregue a configuração do pgbouncer
- do pgbouncer, retome o(s) banco(s) de dados
O que há de novo no PostgreSQL 11

Nesta apresentação emocionante, Magnus Hagander (Redpill Linpro AB) nos apresentou as maravilhas do PostgreSQL 11:
- pg_stat_statements suporta queryid de 64 bits.
- pg_prewarm (um método para aquecer o cache do sistema ou buffers compartilhados):adição de novos parâmetros de configuração
- Novas funções padrão que facilitam o afastamento do postgres (o usuário que quero dizer :) )
- Procedimentos armazenados com controle xação
- Pesquisa de texto completo aprimorada
- Replicação lógica suporta TRUNCATE
- Backups de base (pg_basebackup) validam somas de verificação
- Várias melhorias na paralelização de consultas
- Particionamento ainda mais refinado do que em 10
- partição padrão
- atualizações entre partições (move a linha de uma partição para outra)
- índices de partição local
- chave exclusiva em todas as partições (ainda não pode ser referenciada)
- particionamento de hash
- junções por partição
- agregados por partição
- partições podem ser tabelas externas em diferentes servidores externos. Isso abre grandes possibilidades para fragmentação de granulação mais fina.
- Compilação JIT
zheap:uma resposta aos problemas de inchaço do PostgreSQL
Isso ainda não está no 11, mas parece tão promissor que tive que incluí-lo na lista de coisas legais. A apresentação foi feita por Amit Kapila (EnterpriseDB) um dos principais autores desta nova tecnologia que pretende ser eventualmente integrada no núcleo do PostgreSQL como um tipo alternativo de heap. Isso será integrado com a nova API Pluggable Storage no PostgreSQL, que suportará vários métodos de acesso a tabelas (da mesma forma que os vários métodos de acesso [Index] abordados no meu primeiro blog).
Isso tentará resolver as deficiências crônicas que o PostgreSQL tem com:
- inchaço da mesa
- precisa de (auto)vácuo
- potencialmente um wraparound de ID de transação
Tudo isso não é um problema para as médias e grandes empresas (embora isso seja altamente relativo), conhecemos bancos e outras instituições financeiras que executam o PostgreSQL de dezenas de TBs de dados e várias transações de 1000s/s sem problemas. O inchaço da tabela é tratado por autovacuum e o congelamento de linhas resolve o problema de wraparound de ID de transação, mas ainda assim isso não é isento de manutenção. A comunidade PostgreSQL trabalha para um banco de dados realmente livre de manutenção, portanto a arquitetura zheap é proposta. Isso trará:
- um novo registro de UNDO
- UNDO log tornará os dados visíveis para transações antigas vendo as versões antigas
- UNDO será usado para reverter os efeitos de transações abortadas
- as mudanças acontecem no local. As versões antigas não são mais mantidas nos arquivos de dados.
Objetivos de alto nível:
- melhor controle de inchaço
- menos gravações
- cabeçalhos de tupla menores
Isso colocará o PostgreSQL no mesmo nível do MySql e Oracle nesse sentido.
Consulta Paralela no PostgreSQL:Como não (des)usar?
Nesta apresentação de Amit Kapila e Rafia Sabih (EnterpriseDB), aprendemos os bits internos de paralelização e também dicas para evitar erros comuns, bem como algumas configurações recomendadas do GUC:
- paralelismo suporta apenas índices de árvore B
- max_parallel_workers_per_gather definido como 1→4 (dependendo dos núcleos disponíveis)
- preste atenção às seguintes configurações:
- parallel_tuple_cost:custo de transferência de uma tupla de um processo de trabalho paralelo para outro processo
- parallel_setup_cost:custo de iniciar trabalhadores paralelos e inicializar memória compartilhada dinâmica
- min_parallel_table_scan_size:o tamanho mínimo das relações a serem consideradas para varredura de sequência paralela
- min_parallel_index_scan_size:o tamanho mínimo do índice a ser considerado para uma verificação paralela
- random_page_cost:custo estimado de acesso a uma página aleatória no disco