Em minha postagem anterior sobre estatísticas incrementais, um novo recurso do SQL Server 2014, demonstrei como elas podem ajudar a diminuir a duração da tarefa de manutenção. Isso ocorre porque as estatísticas podem ser atualizadas no nível da partição e as alterações mescladas no histograma principal da tabela. Também observei que o Query Optimizer não usa essas estatísticas em nível de partição ao gerar planos de consulta, o que pode ser algo que as pessoas esperavam. Não existe documentação para declarar que as estatísticas incrementais serão ou não usadas pelo Otimizador de consultas. Então como você sabe? Você tem que testá-lo. :-)
A configuração
A configuração para este teste será semelhante à do último post, mas com menos dados. Observe que os tamanhos padrão são menores para os arquivos de dados e o script carrega apenas alguns milhões de linhas de dados:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Quando criamos o índice clusterizado para dbo.Orders, vamos criá-lo sem o
STATISTICS_INCREMENTAL opção habilitada, então vamos começar com uma tabela particionada tradicional sem estatísticas incrementais:ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Em seguida, carregaremos cerca de 4 milhões de linhas, o que leva pouco menos de um minuto na minha máquina:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Após o carregamento de dados, atualizaremos as estatísticas com um FULLSCAN (para que possamos criar um histograma o mais consistente possível para testes) e verificar quais dados temos em cada partição:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Dados em cada partição após o carregamento de dados
Dados em cada partição após o carregamento de dados A maioria dos dados está na partição de 2015, mas também há dados de 2012, 2013 e 2014. E se verificarmos a saída do DMV não documentado
sys.dm_db_stats_properties_internal , podemos ver que não existem estatísticas de nível de partição:SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];  sys.dm_db_stats_properties_internal output mostrando apenas uma estatística para dbo.Orders
sys.dm_db_stats_properties_internal output mostrando apenas uma estatística para dbo.Orders O Teste
O teste requer uma consulta simples que podemos usar para verificar se a eliminação de partição ocorre e também verificar estimativas com base em estatísticas. A consulta não retorna nenhum dado, mas isso não importa, estamos interessados no que o otimizador pensou ele retornaria, com base nas estatísticas:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
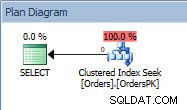 Plano de consulta para a instrução SELECT
Plano de consulta para a instrução SELECT O plano possui um Clustered Index Seek e, se verificarmos as propriedades, veremos que ele estimou 4.000 linhas e acessou a partição 5, que contém dados de 2014.
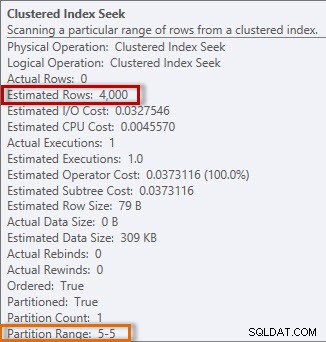 Informações estimadas e reais do Clustered Index Seek
Informações estimadas e reais do Clustered Index Seek Se observarmos o histograma da tabela dbo.Orders, especificamente na área de dados de abril de 2014, veremos que não há etapa para 2014-04-01, portanto, o otimizador estima o número de linhas para essa data usando a etapa para 24/04/2014, onde o
AVG_RANGE_ROWS for 4000 (para qualquer valor entre 2014-02-14 e 2014-04-23 inclusive, o otimizador estimará que 4000 linhas serão retornadas). DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK'); 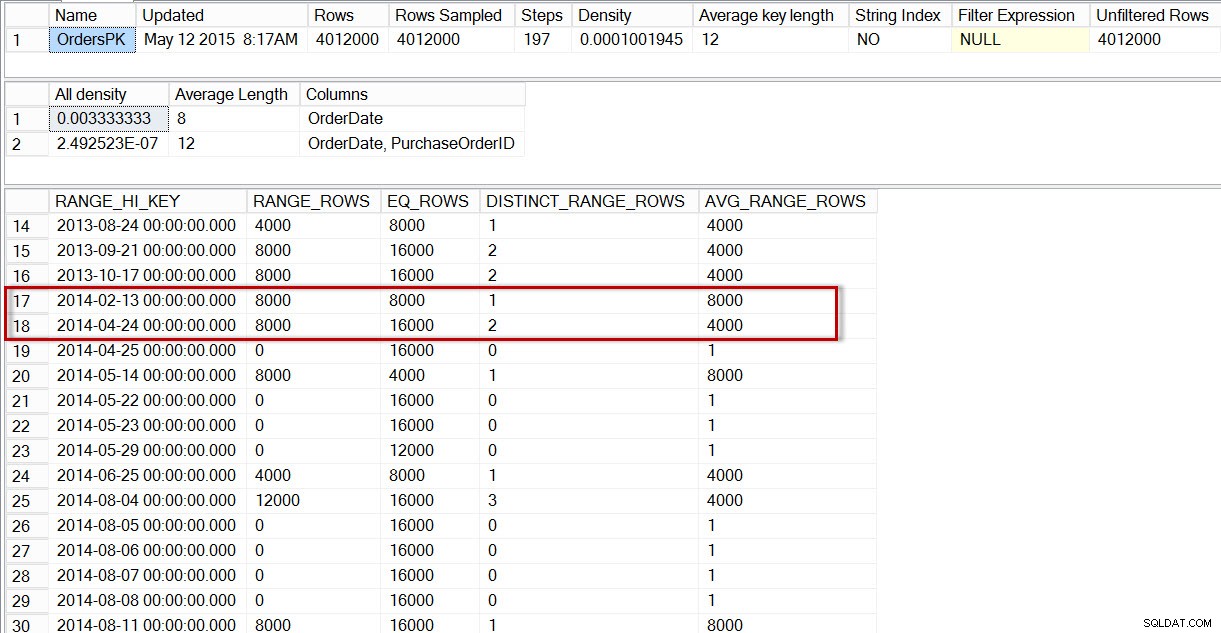 Distribuição no histograma dbo.Orders
Distribuição no histograma dbo.Orders A estimativa e o plano são completamente esperados. Vamos habilitar estatísticas incrementais e ver o que obtemos.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Se executarmos novamente nossa consulta em
sys.dm_db_stats_properties_internal , podemos ver as estatísticas incrementais: sys.dm_db_stats_properties_internal mostrando informações de estatísticas incrementais
sys.dm_db_stats_properties_internal mostrando informações de estatísticas incrementais Agora vamos executar novamente nossa consulta dbo.Orders, e executaremos
DBCC FREEPROCCACHE primeiro para garantir que o plano não seja reutilizado:DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Obtemos o mesmo plano e a mesma estimativa:
Plano de consulta para a instrução SELECT Informações estimadas e reais do Clustered Index Seek Se verificarmos o histograma principal para dbo.Orders, veremos quase o mesmo histograma de antes:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK'); 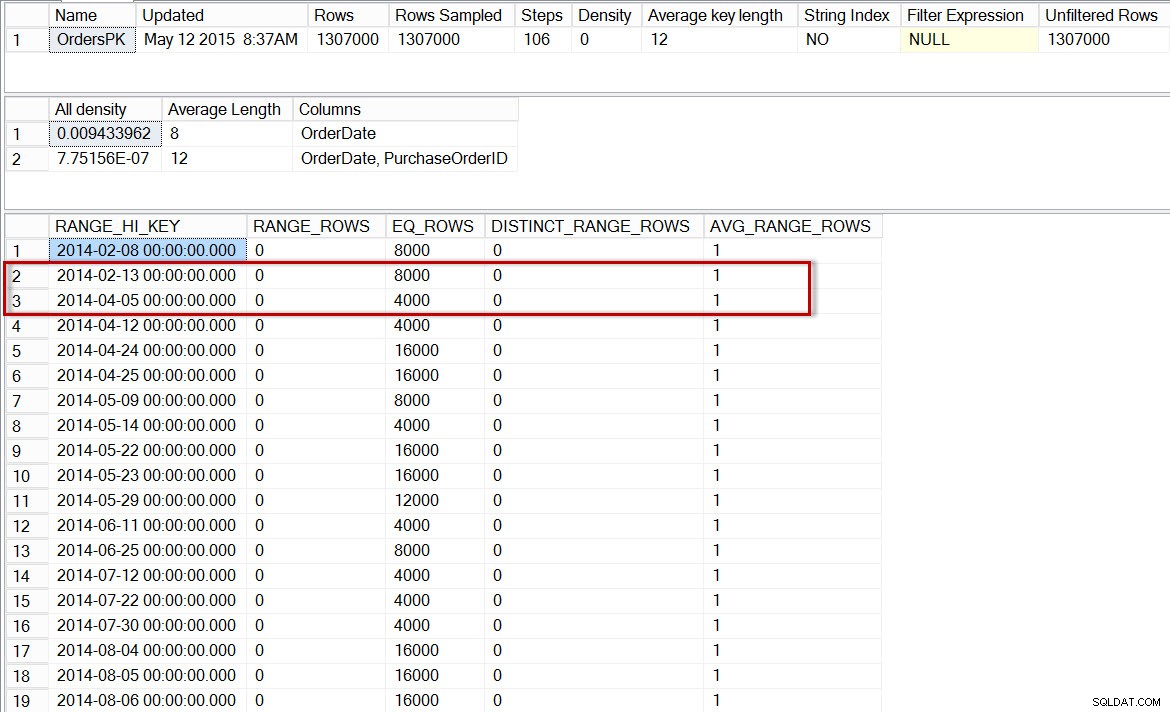 Histograma para dbo.Orders, após habilitar estatísticas incrementais
Histograma para dbo.Orders, após habilitar estatísticas incrementais Agora, vamos verificar o histograma da partição com dados de 2014 (podemos fazer isso usando o sinalizador de rastreamento não documentado 2309, que permite que um número de partição seja especificado como um argumento adicional para
DBCC SHOW_STATISTICS ):DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6); Histograma para a partição 2014 de dbo.Orders, após habilitar estatísticas incrementais Aqui vemos que, novamente, não há etapa para 2014-04-01, mas há 0
RANGE_ROWS entre 13-02-2014 e 05-04-2014, com um AVG_RANGE_ROWS de 1. Se o otimizador estivesse usando o histograma para as estatísticas de nível de partição, a estimativa para o número de linhas para 01-04-2014 seria 1. Observação:a partição identificada como usada no plano de consulta é 5, mas você notará que o
DBCC SHOW_STATISTICS A instrução faz referência à partição 6. A suposição é uma inconsistência nos metadados das estatísticas (um erro comum de um por um, provavelmente devido à contagem baseada em 0 versus 1), que pode ou não ser corrigida no futuro. Entenda que o sinalizador de rastreamento não está documentado no momento e que não é recomendado usá-lo em um ambiente de produção. Resumo
A adição de estatísticas incrementais na versão SQL Server 2014 é um passo na direção certa para estimativas de cardinalidade aprimoradas para tabelas particionadas. No entanto, como demonstramos, o valor atual das estatísticas incrementais é limitado a durações de manutenção reduzidas, pois essas estatísticas incrementais ainda não são usadas pelo Otimizador de consultas.