Na primeira parte deste blog, mencionamos alguns conceitos importantes relacionados a um bom ambiente de replicação PostgreSQL. Agora, vamos ver como combinar todas essas coisas de uma maneira fácil usando o ClusterControl. Para isso, vamos supor que você tenha o ClusterControl instalado, mas se não tiver, você pode acessar o site oficial ou consultar a documentação oficial para instalá-lo.
Implantando a replicação de streaming do PostgreSQL
Para realizar a implantação de um PostgreSQL Cluster a partir do ClusterControl, selecione a opção Deploy e siga as instruções que aparecem.
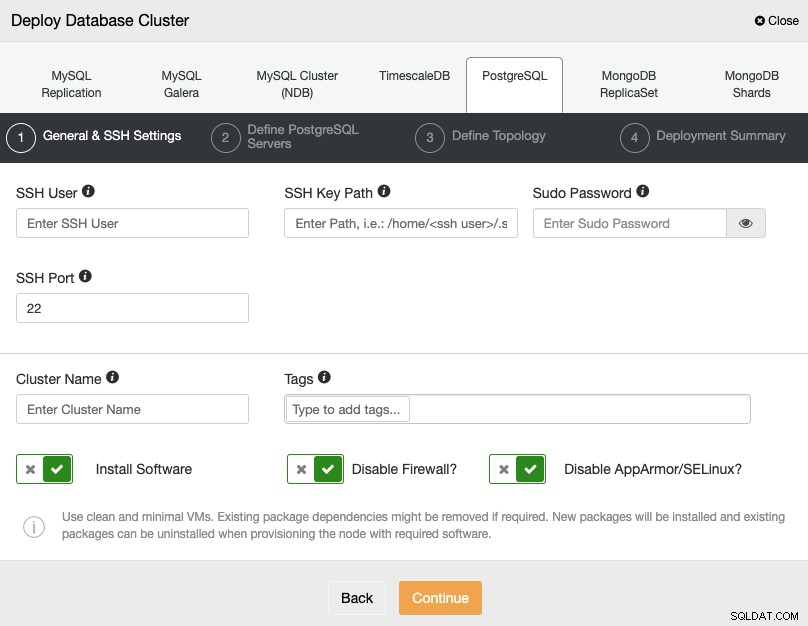
Ao selecionar PostgreSQL, você deve especificar o Usuário, Chave ou Senha e Porta para conectar por SSH aos seus servidores. Você também pode adicionar um nome para seu novo cluster e especificar se deseja que o ClusterControl instale o software e as configurações correspondentes para você.
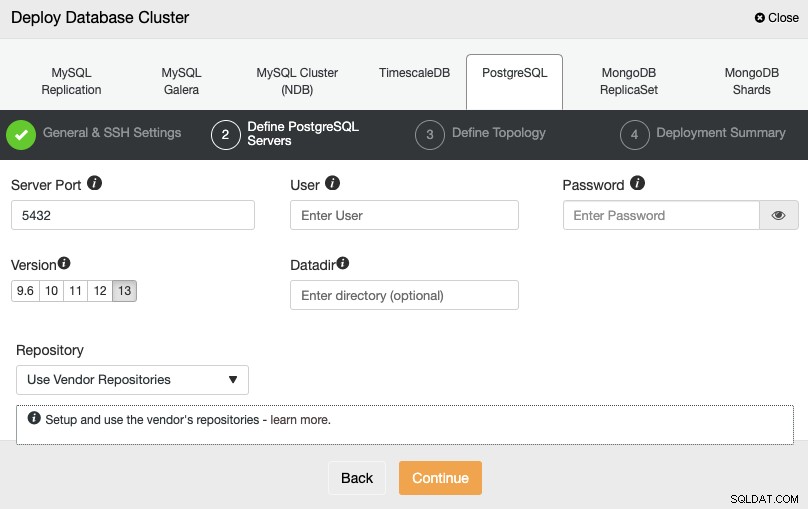
Depois de configurar as informações de acesso SSH, você precisa definir as credenciais do banco de dados , versão e datadir (opcional). Você também pode especificar qual repositório usar.
Na próxima etapa, você precisa adicionar seus servidores ao cluster que você criará usando o endereço IP ou o nome do host.
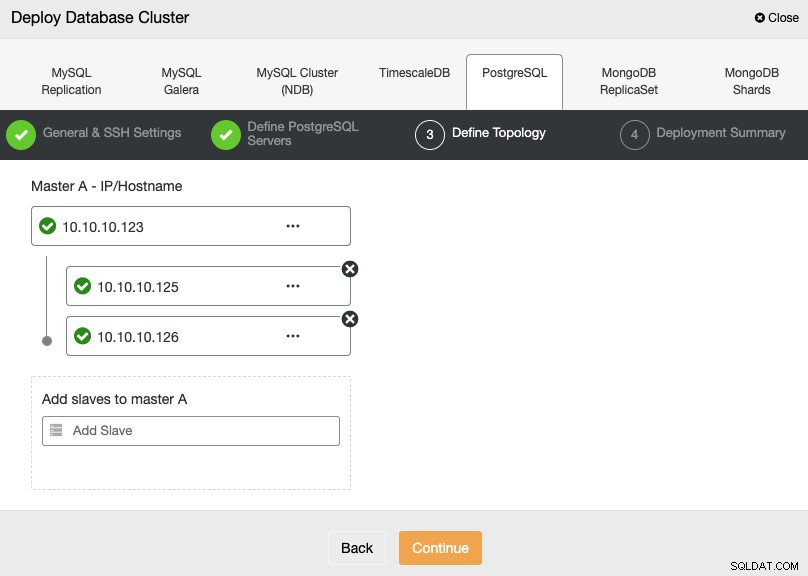
Na última etapa, você pode escolher se sua replicação será síncrona ou Assíncrono e, em seguida, basta pressionar Implantar.
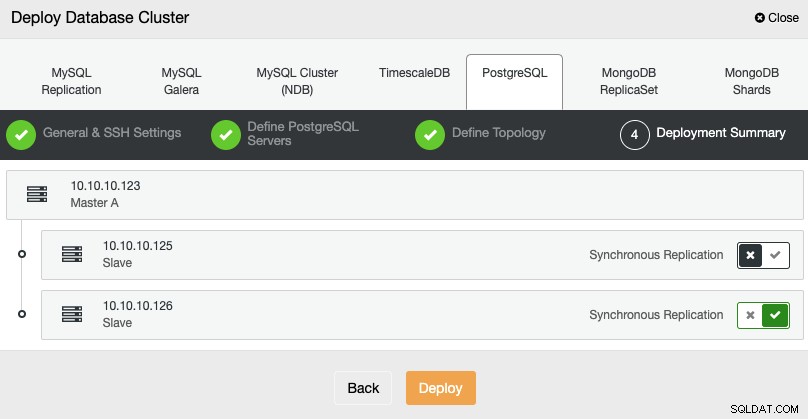
Quando a tarefa for concluída, você poderá ver seu novo PostgreSQL Cluster no tela principal do ClusterControl.

Agora que você criou seu cluster, pode executar várias tarefas nele, como adicionar um balanceador de carga (HAProxy), pool de conexões (PgBouncer) ou um novo escravo de replicação síncrona ou assíncrona.
Adicionando escravos de replicação síncrona e assíncrona
Vá para ClusterControl -> Ações do Cluster -> Adicionar Escravo de Replicação.
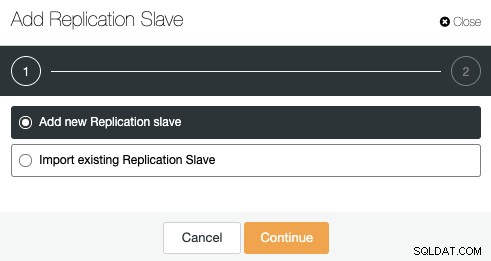
Você pode adicionar um novo slave de replicação ou até mesmo importar um existente. Vamos escolher a primeira opção e continuar.
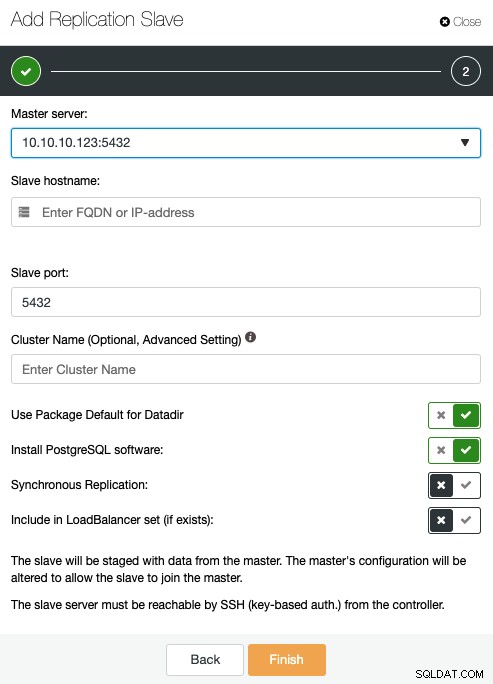
Aqui, você precisa especificar o servidor mestre, endereço IP ou nome de host do o novo slave de replicação, porta e se você deseja que o ClusterControl instale o software ou inclua este nó em um balanceador de carga existente. Você também pode configurar a replicação para ser síncrona ou assíncrona.
Agora que você tem seu cluster PostgreSQL com as réplicas correspondentes, vamos ver como melhorar o desempenho adicionando um pool de conexões.
Implantação do PgBouncer
Vá para ClusterControl -> Selecione PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer -> PgBouncer. Aqui, você pode implantar um novo nó PgBouncer que será implantado no nó de banco de dados selecionado ou até mesmo importar um PgBouncer existente.
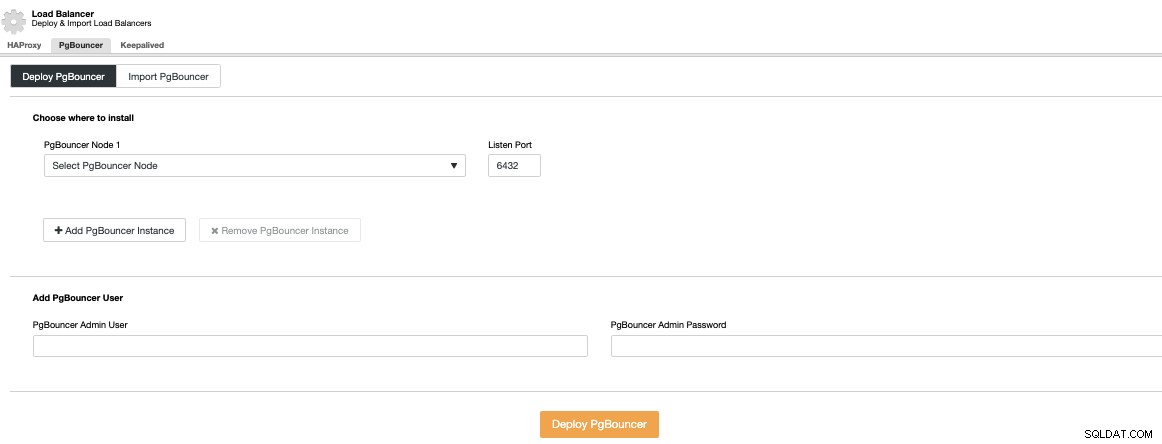
Você precisará especificar um endereço IP ou nome de host, a porta de escuta e Credenciais do PgBouncer. Ao pressionar Deploy PgBouncer, o ClusterControl acessará o nó, instalará e configurará tudo sem nenhuma intervenção manual.
Você pode monitorar o progresso na Seção de Atividade do ClusterControl. Quando terminar, você precisa criar o novo Pool. Para isso, vá para ClusterControl -> Selecione o PostgreSQL Cluster -> Nós -> nó PgBouncer.
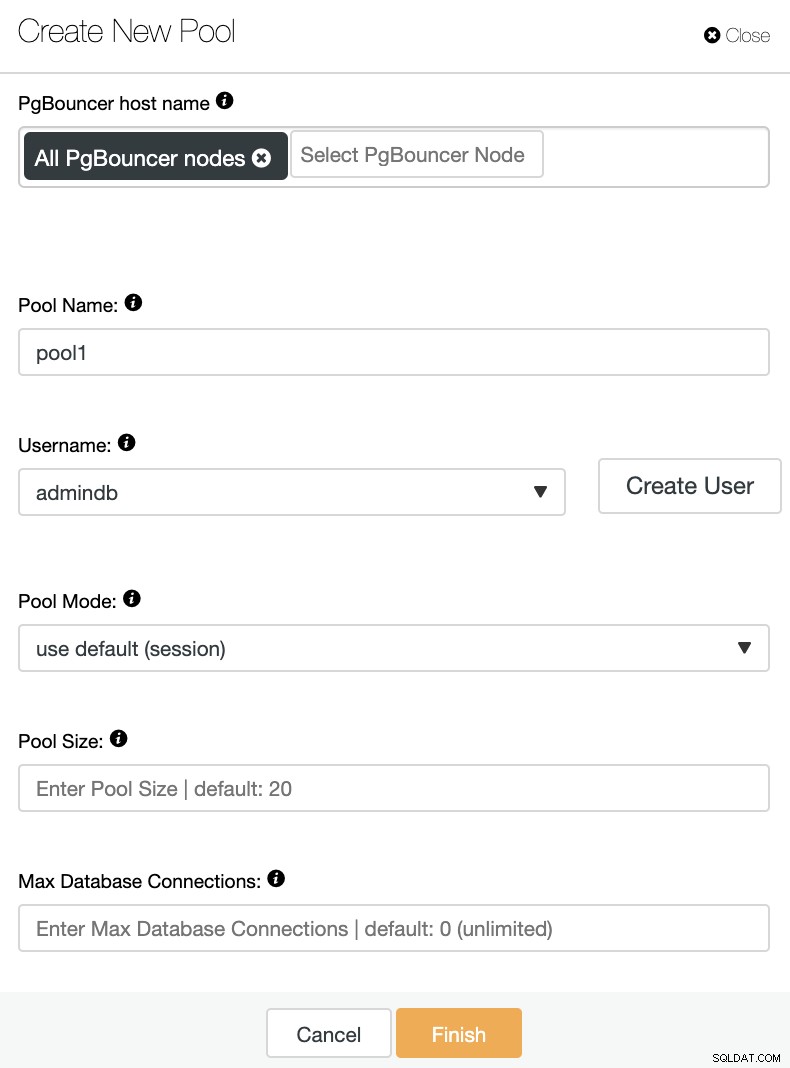
Você precisará adicionar as seguintes informações:
-
Nome do host do PgBouncer:Selecione os hosts do nó para criar o pool de conexões.
-
Nome do pool:os nomes do pool e do banco de dados devem ser os mesmos.
-
Nome de usuário: Selecione um usuário do nó principal do PostgreSQL ou crie um novo.
-
Modo Pool:Pode ser:sessão (padrão), transação ou pool de instruções.
-
Tamanho do Pool:Tamanho máximo dos pools para este banco de dados. O valor padrão é 20.
-
Máximo de conexões de banco de dados:Configure um máximo de todo o banco de dados. O valor padrão é 0, o que significa ilimitado.
Agora, você poderá ver o Pool na seção Node.
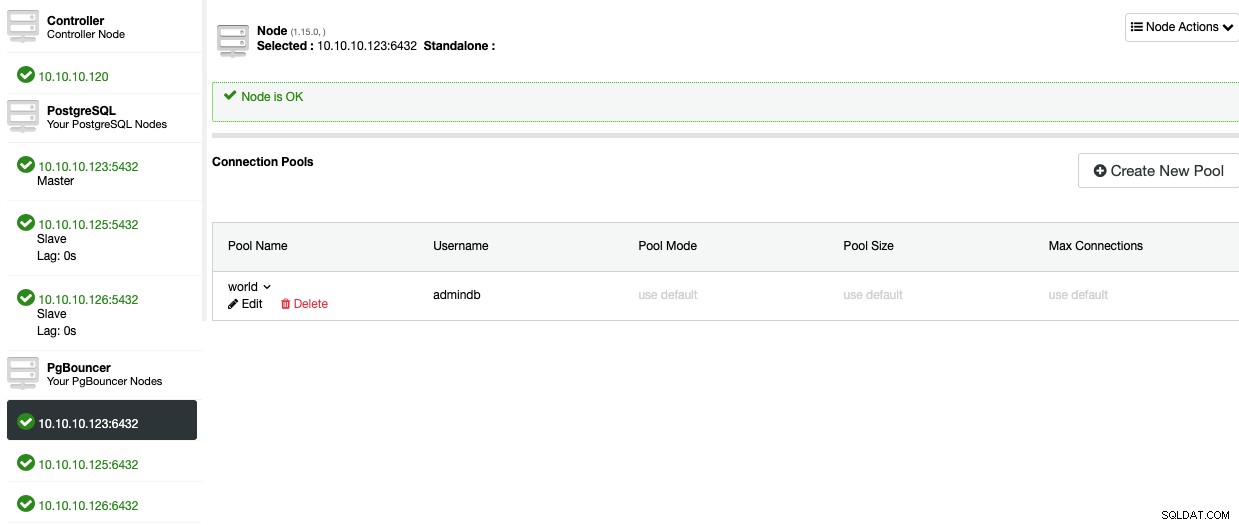
Para adicionar alta disponibilidade ao seu banco de dados PostgreSQL, vamos ver como implantar um balanceador de carga.
Implantação do balanceador de carga
Para realizar uma implantação de balanceador de carga, selecione a opção Adicionar balanceador de carga no menu Ações de cluster e preencha as informações solicitadas.
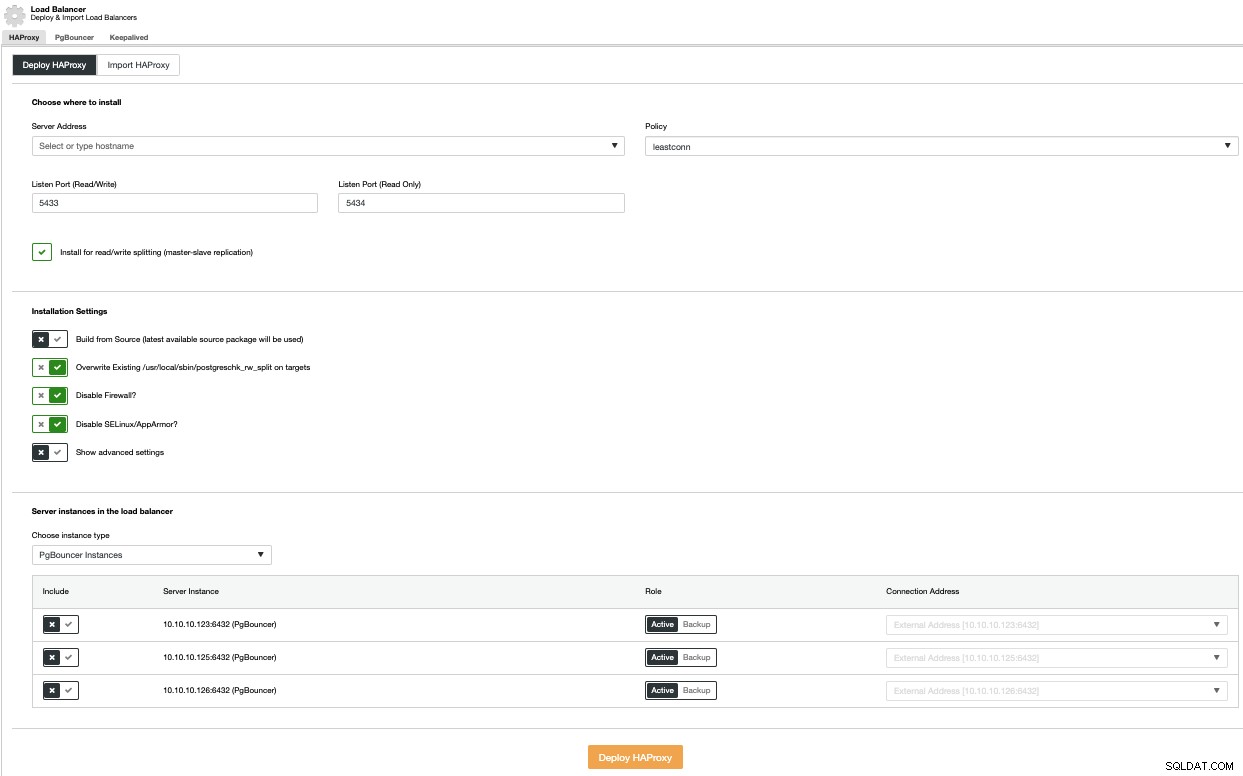
Você precisa adicionar IP ou nome de host, porta, política e os nós você vai usar. Se você estiver usando o PgBouncer, poderá escolhê-lo na caixa de combinação do tipo de instância.
Para evitar um único ponto de falha, você deve implantar pelo menos dois nós HAProxy e usar Keepalived, que permite usar um endereço IP virtual em seu aplicativo atribuído ao nó HAProxy ativo. Se esse nó falhar, o endereço IP virtual será migrado para o balanceador de carga secundário, para que seu aplicativo ainda funcione normalmente.
Implantação mantida
Para realizar uma implantação Keepalived, selecione a opção Add Load Balancer no menu Cluster Actions e, em seguida, vá para a aba Keepalived.
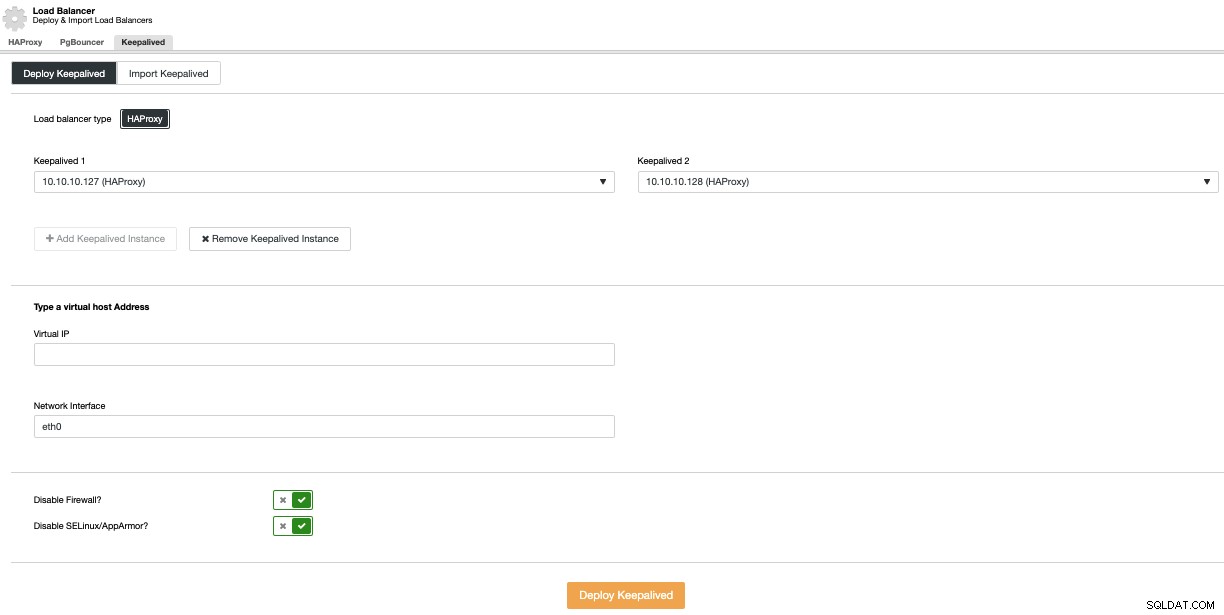
Aqui, selecione os nós HAProxy e especifique o endereço IP virtual que ser usado para acessar o banco de dados (ou pool de conexão).
Neste momento, você deve ter a seguinte topologia:
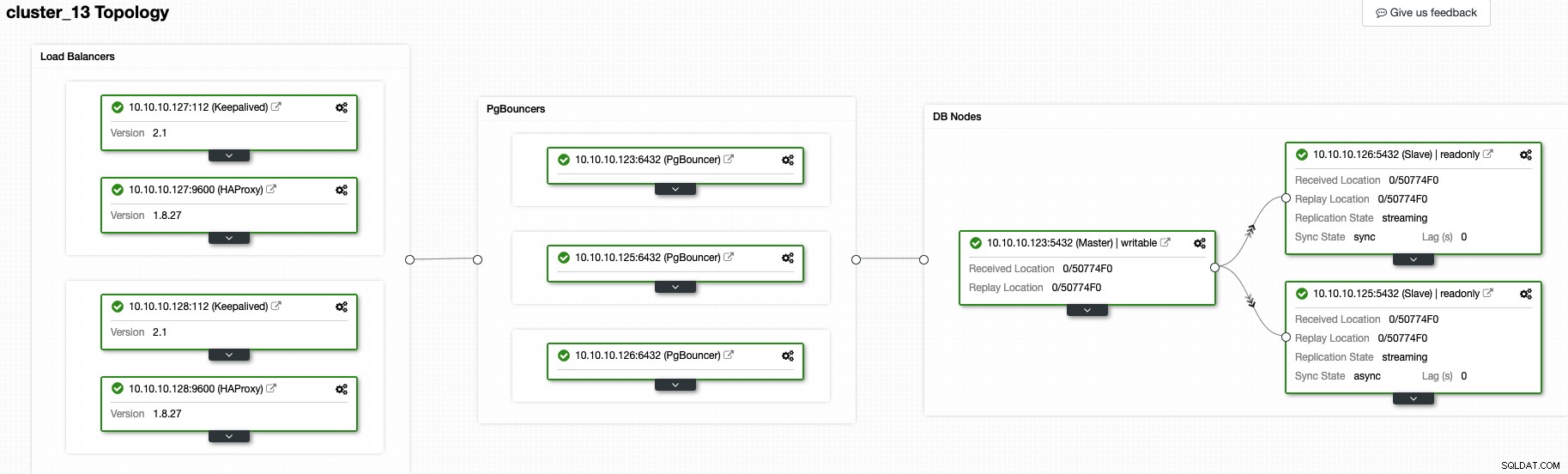
E isso significa:HAProxy + Keepalived -> PgBouncer -> Nós do banco de dados PostgreSQL , essa é uma boa topologia para seu cluster PostgreSQL.
Recurso de recuperação automática do ClusterControl
Em caso de falha, o ClusterControl promoverá o nó de espera mais avançado para primário, além de notificá-lo sobre o problema. Ele também faz failover do restante do nó em espera para replicar a partir do novo servidor primário.
Por padrão, o HAProxy é configurado com duas portas diferentes:leitura-gravação e somente leitura. Na porta de leitura e gravação, você tem o nó do banco de dados primário (ou PgBouncer) como online e o restante dos nós como offline, e na porta somente leitura, você tem os nós primário e de espera online.
Quando o HAProxy detecta que um de seus nós não está acessível, ele automaticamente o marca como off-line e não o considera para enviar tráfego para ele. A detecção é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Quando o ClusterControl promove um nó em espera, o HAProxy marca o primário antigo como offline para ambas as portas e coloca o nó promovido online na porta de leitura/gravação.
Se o seu HAProxy ativo, ao qual é atribuído um endereço IP virtual ao qual seus sistemas se conectam, falhar, o Keepalived migra esse endereço IP para seu HAProxy passivo automaticamente. Isso significa que seus sistemas podem continuar a funcionar normalmente.
Conclusão
Como você pode ver, ter uma boa topologia do PostgreSQL é fácil se você usar o ClusterControl e se estiver seguindo os conceitos básicos de práticas recomendadas para replicação do PostgreSQL. Claro que o melhor ambiente depende da carga de trabalho, hardware, aplicação, etc, mas você pode usar como exemplo e mover as peças conforme precisar.