Nesta 3ª parte de Benchmarking Managed PostgreSQL Cloud Solutions , aproveitei a oferta de nível gratuito do GCP do Google. Foi uma experiência que valeu a pena e, como administrador de sistemas que passa a maior parte do tempo no console, não pude perder a oportunidade de experimentar o cloud shell, um dos recursos do console que diferencia o Google do provedor de nuvem com o qual estou mais familiarizado , Amazon Web Services.
Para recapitular rapidamente, na Parte 1, examinei as ferramentas de benchmark disponíveis e expliquei por que escolhi o AWS Benchmark Procedure for Aurora. Também fiz benchmarking do Amazon Aurora para PostgreSQL versão 10.6. Na Parte 2, revisei o AWS RDS for PostgreSQL versão 11.1.
Durante esta rodada, os testes baseados no AWS Benchmark Procedure for Aurora serão executados no Google Cloud SQL para PostgreSQL 9.6, pois a versão 11.1 ainda está em beta.
Instâncias de nuvem
Pré-requisitos
Conforme mencionado nos dois artigos anteriores, optei por deixar as configurações do PostgreSQL em seus padrões de GUC na nuvem, a menos que impeçam a execução de testes (veja mais abaixo). Lembre-se de artigos anteriores que a suposição era de que o provedor de nuvem deveria ter a instância do banco de dados configurada para fornecer um desempenho razoável.
O patch de tempo do AWS pgbench para PostgreSQL 9.6.5 foi aplicado de forma limpa à versão Google Cloud do PostgreSQL 9.6.10.
Usando as informações que o Google publicou em seu blog Google Cloud for AWS Professionals, combinei as especificações do cliente e das instâncias de destino com relação aos componentes de computação, armazenamento e rede. Por exemplo, o equivalente do Google Cloud ao AWS Enhanced Networking é obtido dimensionando o nó de computação com base na fórmula:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Quando se trata de configurar a instância de banco de dados de destino, de forma semelhante à AWS, o Google Cloud não permite réplicas, porém, o armazenamento é criptografado em repouso e não há opção de desativá-lo.
Por fim, para obter o melhor desempenho de rede, o cliente e as instâncias de destino devem estar localizados na mesma zona de disponibilidade.
Cliente
As especificações da instância do cliente que mais se aproximam da instância da AWS são:
- vCPU:32 (16 núcleos x 2 threads/núcleo)
- RAM:208 GiB (máximo para a instância de 32 vCPU)
- Armazenamento:disco permanente do Compute Engine
- Rede:16 Gbps (máximo de [32 vCPUs x 2 Gbps/vCPU] e 16 Gbps)
Detalhes da instância após a inicialização:
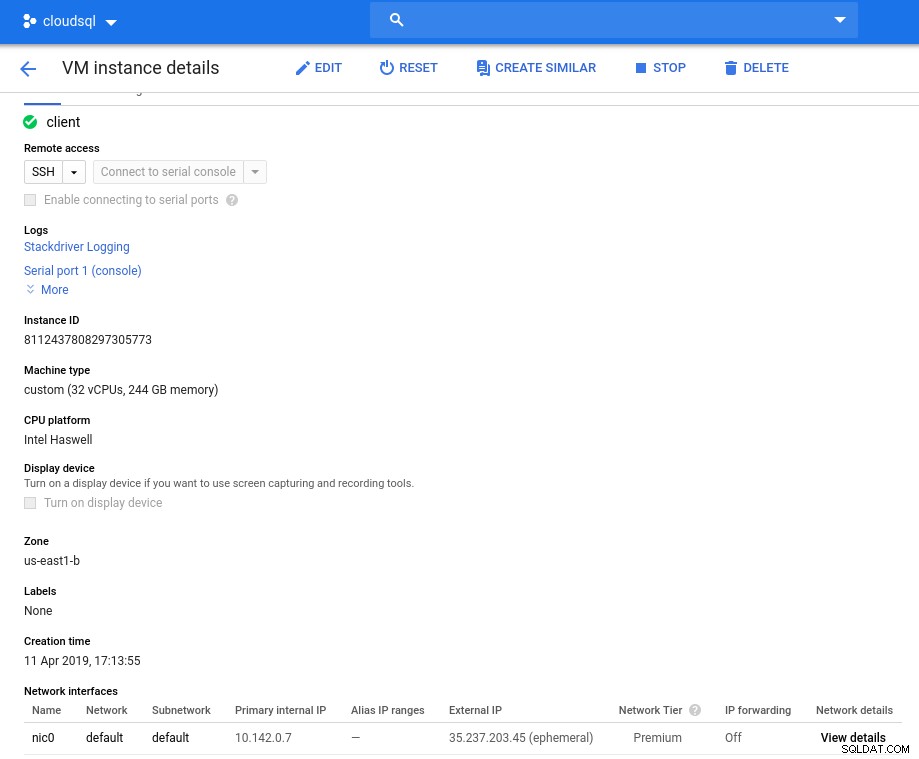 Instância de cliente:computação e rede
Instância de cliente:computação e rede Observação:por padrão, as instâncias são limitadas a 24 vCPUs. O suporte técnico do Google precisa aprovar o aumento da cota para 32 vCPUs por instância.

Embora essas solicitações geralmente sejam tratadas em dois dias úteis, tenho que dar um sinal de positivo aos Serviços de Suporte do Google por concluir minha solicitação em apenas duas horas.
Para os curiosos, a fórmula de velocidade da rede é baseada na documentação do mecanismo de computação mencionada neste blog do GCP.
Cluster de banco de dados
Abaixo estão as especificações da instância do banco de dados:
- vCPU:8
- RAM:52 GiB (máximo)
- Armazenamento:144 MB/s, 9.000 IOPS
- Rede:2.000 MB/s
Observe que a memória máxima disponível para uma instância de 8 vCPU é de 52 GiB. Mais memória pode ser alocada selecionando uma instância maior (mais vCPUs):
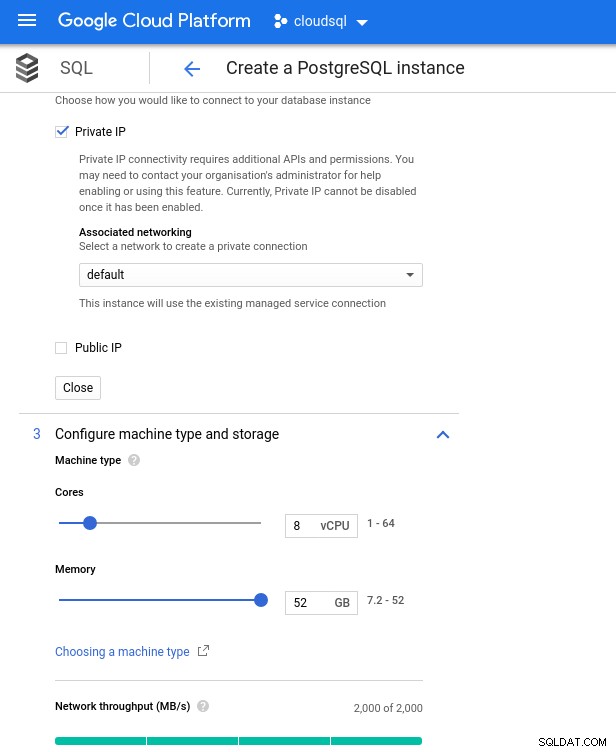 CPU do banco de dados e dimensionamento de memória
CPU do banco de dados e dimensionamento de memória Embora o Google SQL possa expandir automaticamente o armazenamento subjacente, que por sinal é um recurso muito legal, optei por desabilitar a opção para ser consistente com o conjunto de recursos da AWS e evitar um possível impacto de E/S durante a operação de redimensionamento. (“potencial”, pois não deve ter nenhum impacto negativo, porém na minha experiência redimensionar qualquer tipo de armazenamento subjacente aumenta a E/S, mesmo que por alguns segundos).
Lembre-se de que o backup da instância de banco de dados da AWS foi feito por um armazenamento EBS otimizado que fornecia no máximo:
- Largura de banda de 1.700 Mbps
- Taxa de transferência de 212,5 MB/s
- 12.000 IOPS
Com o Google Cloud, conseguimos uma configuração semelhante ajustando o número de vCPUs (veja acima) e a capacidade de armazenamento:
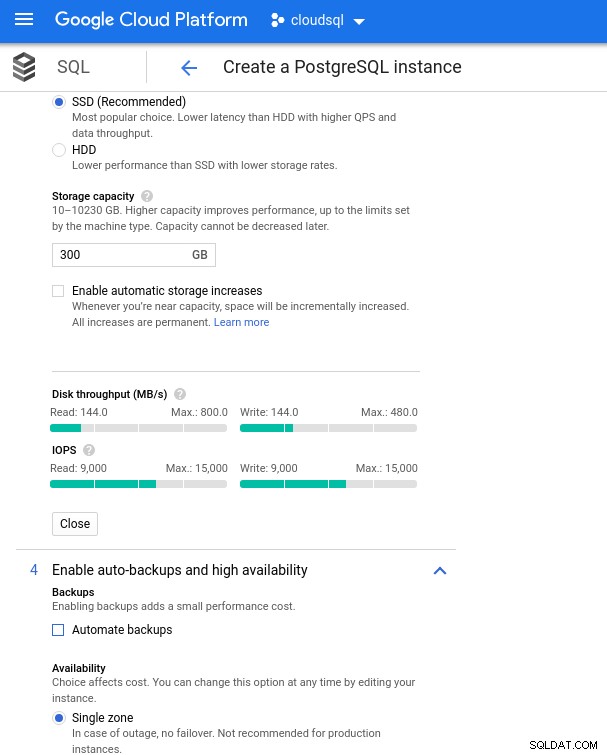 Configuração de armazenamento de banco de dados e configurações de backup
Configuração de armazenamento de banco de dados e configurações de backup Executando os comparativos de mercado
Configuração
Em seguida, instale as ferramentas de benchmark, pgbench e sysbench, seguindo as instruções do guia Amazon adaptado ao PostgreSQL versão 9.6.10.
Inicialize as variáveis de ambiente do PostgreSQL em .bashrc e defina os caminhos para os binários e bibliotecas do PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libLista de verificação de pré-voo:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)E estamos prontos para a decolagem:
pgbench
Inicialize o banco de dados pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000… e vários minutos depois:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Como estamos acostumados, o tamanho do banco de dados deve ser de 160 GB. Vamos verificar que:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Com todos os preparativos concluídos, inicie o teste de leitura/gravação:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsOps! Qual é o máximo?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Portanto, embora a AWS defina um max_connections bastante suficiente, pois não encontrei esse problema, o Google Cloud requer um pequeno ajuste...Volte ao console da nuvem, atualize o parâmetro do banco de dados, aguarde alguns minutos e verifique:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Reiniciando o teste, tudo parece estar funcionando bem:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998... mas há outro problema. Tive uma surpresa ao tentar abrir uma nova sessão do psql para contar o número de conexões:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsSerá que superuser_reserved_connections não está em seu padrão?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Esse é o padrão, então o que mais poderia ser?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Outra colisão de max_connections cuida disso, no entanto, exigiu que eu reinicie o teste do pgbench. E essa é a história por trás da aparente duplicata executada nos gráficos abaixo.
E, finalmente, os resultados estão em:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Preencha o banco de dados:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareSaída:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...E agora execute o teste:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runE os resultados:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Métricas de referência
O plug-in do PostgreSQL para Stackdriver foi descontinuado em 28 de fevereiro de 2019. Embora o Google recomende o Blue Medora, para os fins deste artigo, optei por não criar uma conta e confiar nas métricas disponíveis do Stackdriver.
- Utilização da CPU:
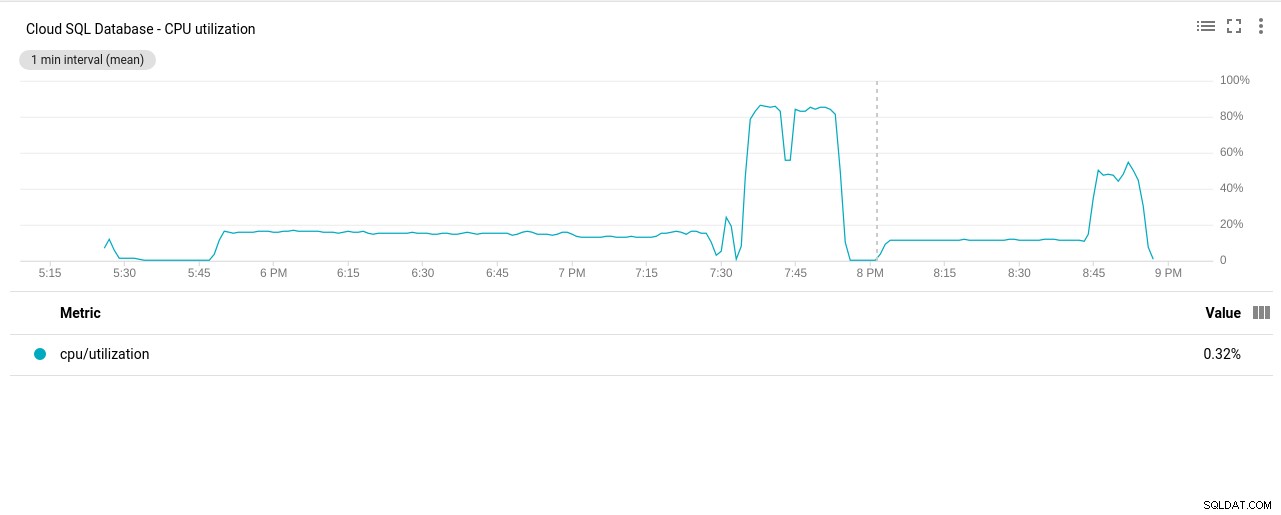 Autor da foto Google Cloud SQL:PostgreSQL CPU Utilization
Autor da foto Google Cloud SQL:PostgreSQL CPU Utilization - Operações de leitura/gravação de disco:
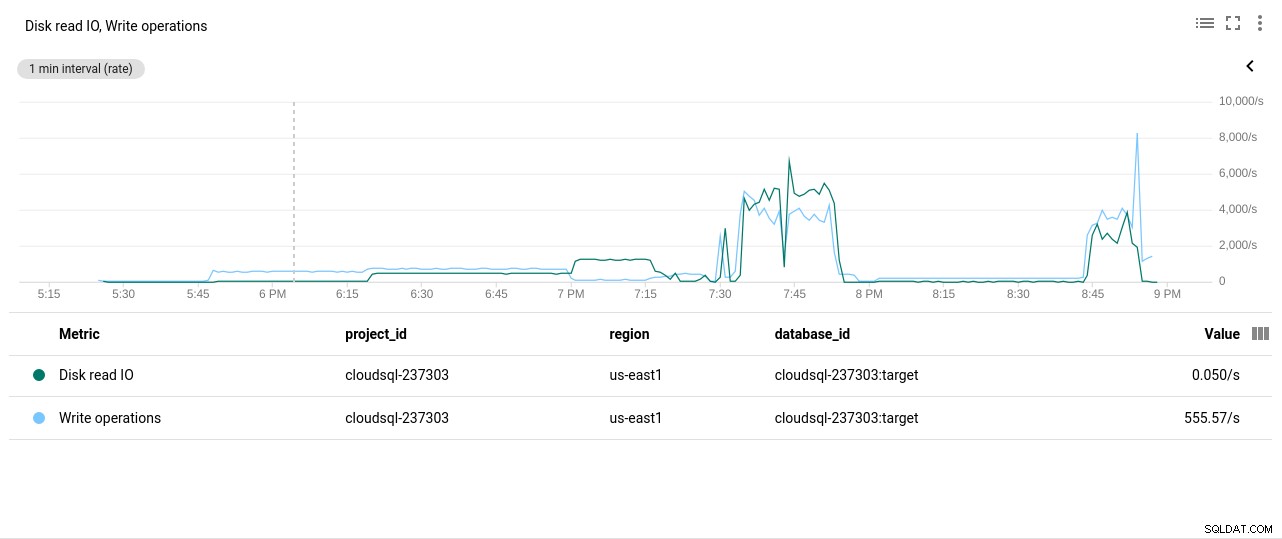 Autor da foto Google Cloud SQL:operações de leitura/gravação de disco PostgreSQL
Autor da foto Google Cloud SQL:operações de leitura/gravação de disco PostgreSQL - Bytes enviados/recebidos da rede:
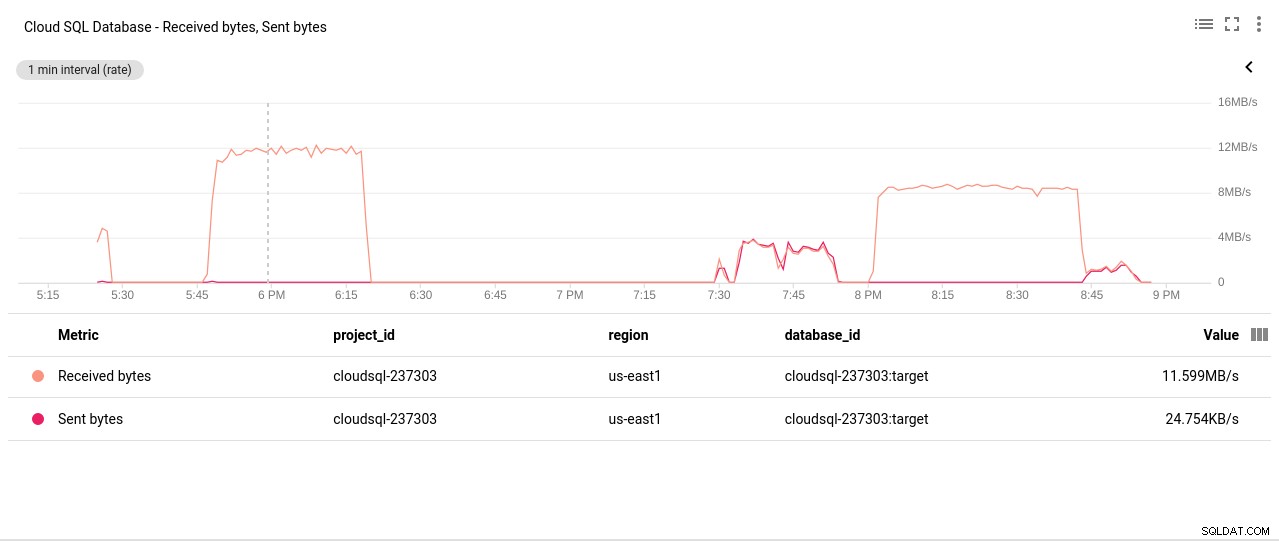 Autor da foto Google Cloud SQL:PostgreSQL Network Sent/Received bytes
Autor da foto Google Cloud SQL:PostgreSQL Network Sent/Received bytes - Contagem de conexões do PostgreSQL:
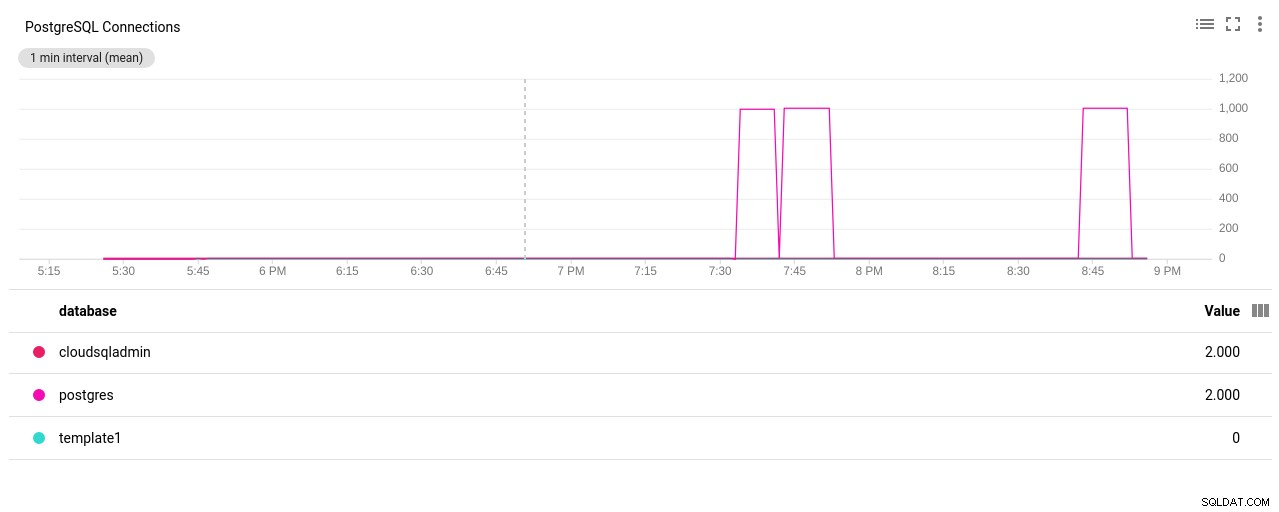 Autor da foto Google Cloud SQL:contagem de conexões do PostgreSQL
Autor da foto Google Cloud SQL:contagem de conexões do PostgreSQL
Resultados do comparativo de mercado
Inicialização do pgbench
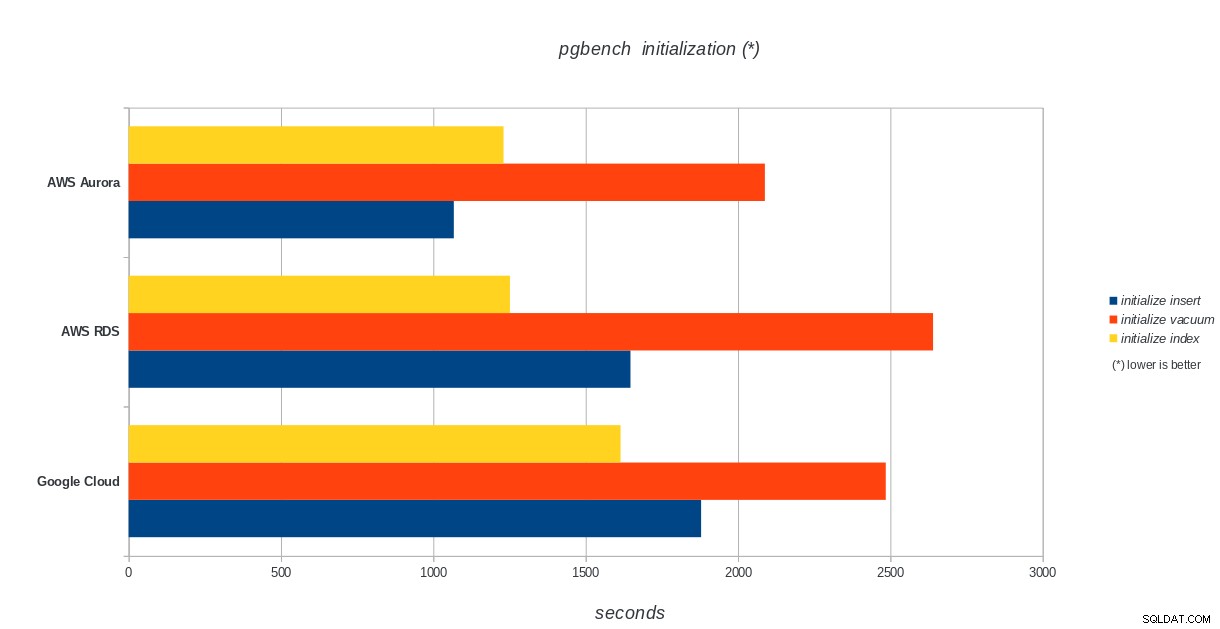 AWS Aurora, AWS RDS, Google Cloud SQL:resultados da inicialização do PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:resultados da inicialização do PostgreSQL pgbench execução do pgbench
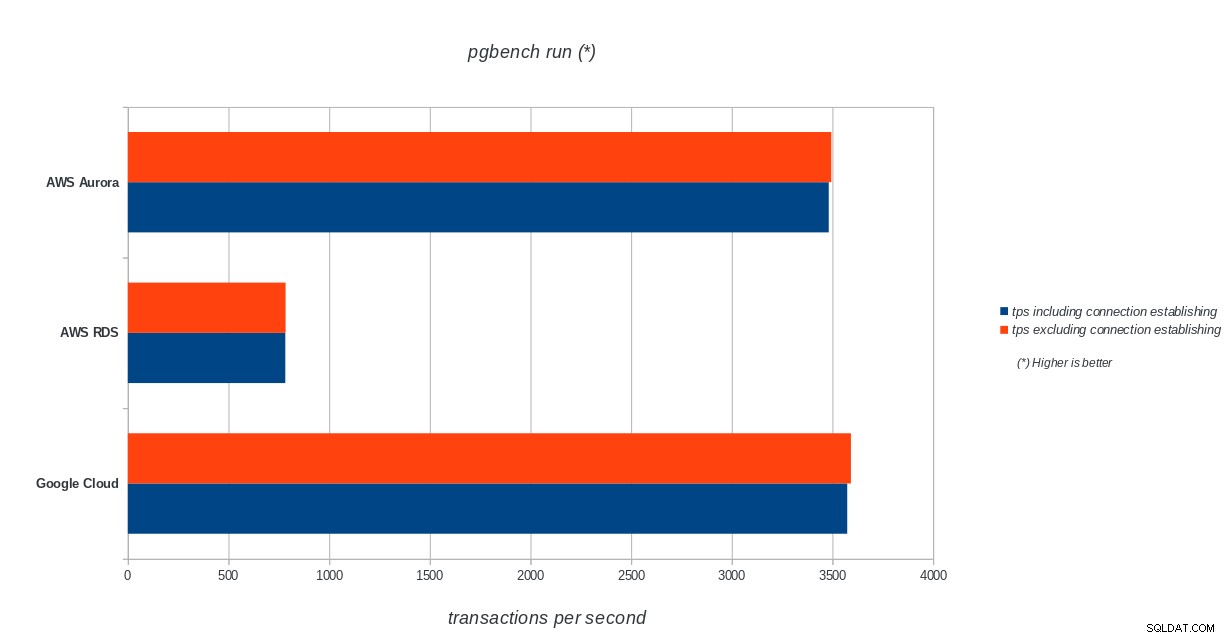 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run results
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run results sysbench
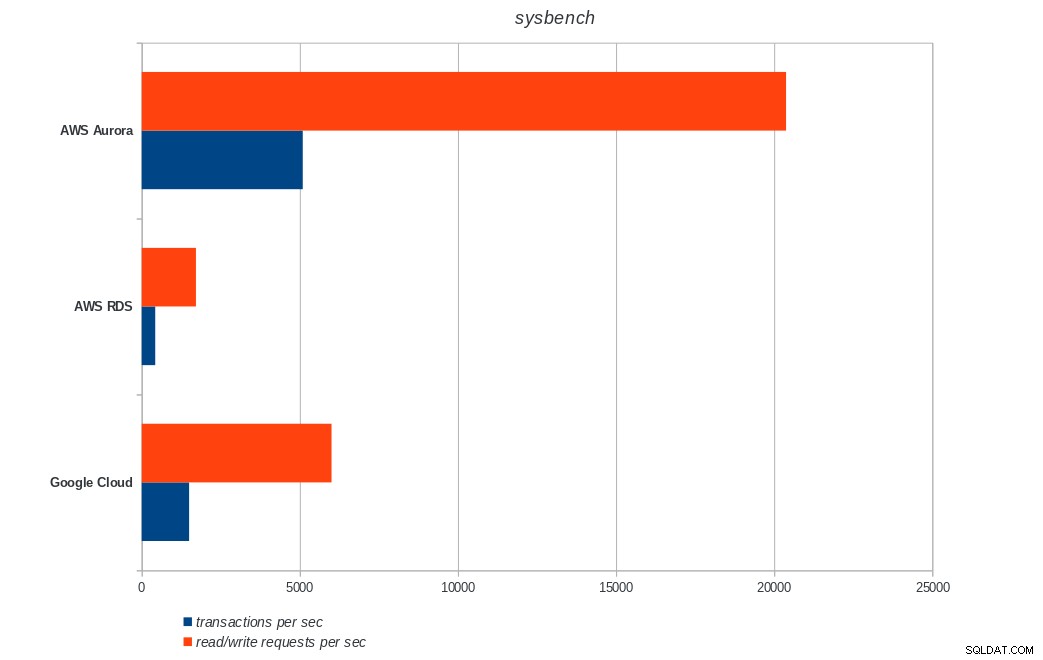 AWS Aurora, AWS RDS, Google Cloud SQL:resultados do PostgreSQL sysbench
AWS Aurora, AWS RDS, Google Cloud SQL:resultados do PostgreSQL sysbench Conclusão
O Amazon Aurora vem em primeiro lugar em testes pesados de gravação (sysbench), enquanto está no mesmo nível do Google Cloud SQL nos testes de leitura/gravação do pgbench. O teste de carga (inicialização do pgbench) coloca o Google Cloud SQL em primeiro lugar, seguido pelo Amazon RDS. Com base em uma análise superficial dos modelos de preços do AWS Aurora e do Google Cloud SQL, eu arriscaria dizer que o Google Cloud pronto para uso é a melhor escolha para o usuário médio, enquanto o AWS Aurora é mais adequado para ambientes de alto desempenho. Mais análises seguirão após a conclusão de todos os benchmarks.
A próxima e última parte desta série de benchmarks será no Microsoft Azure PostgreSQL.
Obrigado por ler e por favor comente abaixo se você tiver feedback.