Os planos de execução fornecem uma rica fonte de informações que podem nos ajudar a identificar maneiras de melhorar o desempenho de consultas importantes. As pessoas geralmente procuram coisas como grandes varreduras e pesquisas como forma de identificar possíveis otimizações de caminho de acesso a dados. Esses problemas geralmente podem ser resolvidos rapidamente criando um novo índice ou estendendo um já existente com mais colunas incluídas.
Também podemos usar planos pós-execução para comparar as contagens de linhas reais com as esperadas entre os operadores do plano. Onde houver uma variação significativa, podemos tentar fornecer melhores informações estatísticas ao otimizador atualizando as estatísticas existentes, criando novos objetos de estatísticas, utilizando estatísticas em colunas computadas ou talvez dividindo uma consulta complexa em componentes menos complexos partes.
Além disso, também podemos analisar operações caras no plano, principalmente aquelas que consomem memória, como classificação e hash. Às vezes, a classificação pode ser evitada por meio de alterações de indexação. Outras vezes, podemos ter que refatorar a consulta usando uma sintaxe que favoreça um plano que preserve uma determinada ordenação desejada.
Às vezes, o desempenho ainda não será bom o suficiente mesmo depois que todas essas técnicas de ajuste de desempenho forem aplicadas. Um possível próximo passo é pensar um pouco mais sobre o plano como um todo . Isso significa dar um passo atrás, tentando entender a estratégia geral escolhida pelo otimizador de consultas, para ver se podemos identificar uma melhoria algorítmica.
Este artigo explora esse último tipo de análise, usando um problema de exemplo simples de encontrar valores de coluna exclusivos em um conjunto de dados moderadamente grande. Como costuma acontecer em problemas análogos do mundo real, a coluna de interesse terá relativamente poucos valores exclusivos, em comparação com o número de linhas na tabela. Há duas partes nessa análise:criar os dados de amostra e escrever a própria consulta de valores distintos.
Criando os dados de amostra
Para fornecer o exemplo mais simples possível, nossa tabela de teste tem apenas uma única coluna com um índice clusterizado (esta coluna conterá valores duplicados para que o índice não possa ser declarado exclusivo):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data); Para escolher alguns números do ar, escolheremos carregar dez milhões de linhas no total, com uma distribuição uniforme em mil valores distintos . Uma técnica comum para gerar dados como esse é fazer a junção cruzada de algumas tabelas do sistema e aplicar o
ROW_NUMBER função. Também usaremos o operador módulo para limitar os números gerados aos valores distintos desejados:INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); O plano de execução estimado para essa consulta é o seguinte (clique na imagem para ampliá-la se necessário):

Isso leva cerca de 30 segundos para criar os dados de amostra no meu laptop. Isso não é um período de tempo enorme, mas ainda é interessante considerar o que podemos fazer para tornar esse processo mais eficiente…
Análise do plano
Começaremos entendendo para que serve cada operação do plano.
A seção do plano de execução à direita do operador Segmento está relacionada à fabricação de linhas por junção cruzada de tabelas do sistema:

O operador Segment está lá caso a função de janela tenha um
PARTITION BY cláusula. Esse não é o caso aqui, mas ele aparece no plano de consulta de qualquer maneira. O operador Sequence Project gera os números de linha e o Top limita a saída do plano a dez milhões de linhas:
O Compute Scalar define a expressão que aplica a função módulo e adiciona um ao resultado:

Podemos ver como os rótulos de expressão Sequence Project e Compute Scalar se relacionam usando a guia Expressions do Plan Explorer:

Isso nos dá uma ideia mais completa do fluxo deste plano:o Projeto Sequência numera as linhas e rotula a expressão
Expr1050; o Compute Scalar rotula o resultado do cálculo do módulo e mais um como Expr1052 . Observe também a conversão implícita na expressão Compute Scalar. A coluna da tabela de destino é do tipo integer, enquanto o ROW_NUMBER A função produz um bigint, portanto, é necessária uma conversão de restrição. O próximo operador no plano é um Sort. De acordo com as estimativas de custo do otimizador de consultas, espera-se que esta seja a operação mais cara (88,1% estimado ):

Pode não ser imediatamente óbvio por que esse plano apresenta classificação, já que não há nenhum requisito de pedido explícito na consulta. O Sort é adicionado ao plano para garantir que as linhas cheguem ao operador Clustered Index Insert na ordem do índice clusterizado. Isso promove gravações sequenciais, evita a divisão de página e é um dos pré-requisitos para
INSERT minimamente registrado operações. Todas essas são coisas potencialmente boas, mas o Sort em si é bastante caro. De fato, verificar o plano de execução pós-execução ("real") revela que o Sort também ficou sem memória no tempo de execução e teve que se espalhar para o tempdb físico disco:

O derramamento de classificação ocorre apesar do número estimado de linhas estar exatamente correto e apesar do fato de a consulta ter recebido toda a memória solicitada (como visto nas propriedades do plano para a raiz
INSERT nó):
Os derramamentos de classificação também são indicados pela presença de
IO_COMPLETION esperas na guia de estatísticas de espera do Plan Explorer PRO:
Por fim, para esta seção de análise de plano, observe o
DML Request Sort A propriedade do operador Clustered Index Insert é definida como verdadeira:
Este sinalizador indica que o otimizador requer que a subárvore abaixo de Insert forneça linhas em ordem de classificação de chave de índice (daí a necessidade do operador Sort problemático).
Evitando a classificação
Agora que sabemos por que o Sort aparece, podemos testar para ver o que acontece se o removermos. Existem maneiras de reescrever a consulta para "enganar" o otimizador em pensar que menos linhas seriam inseridas (portanto, a classificação não valeria a pena), mas uma maneira rápida de evitar a classificação diretamente (apenas para fins experimentais) é usar o sinalizador de rastreamento não documentado 8795. Isso define a
DML Request Sort para false, de modo que as linhas não sejam mais necessárias para chegar ao Clustered Index Insert na ordem de chave clusterizada:TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); O novo plano de consulta pós-execução é o seguinte (clique na imagem para ampliar):

O operador Sort desapareceu, mas a nova consulta é executada por mais de 50 segundos (comparado com 30 segundos antes). Existem algumas razões para isso. Primeiro, perdemos qualquer possibilidade de inserções minimamente registradas porque elas exigem dados classificados (DML Request Sort =true). Segundo, um grande número de divisões de página "ruins" ocorrerá durante a inserção. Caso isso pareça contra-intuitivo, lembre-se de que, embora o
ROW_NUMBER função números linhas sequencialmente, o efeito do operador módulo é apresentar uma sequência repetida de números 1 a 1000 para a inserção de índice clusterizado. O mesmo problema fundamental ocorre se usarmos truques T-SQL para diminuir a contagem de linhas esperada para evitar a classificação em vez de usar o sinalizador de rastreamento sem suporte.
Evitando a classificação II
Olhando para o plano como um todo, parece claro que gostaríamos de gerar linhas de uma maneira que evite uma classificação explícita, mas que ainda colha os benefícios do registro mínimo e da prevenção de divisão de página ruim. Simplificando:queremos um plano que apresente linhas em ordem de chave agrupada, mas sem classificação.
Armados com esse novo insight, podemos expressar nossa consulta de uma maneira diferente. A consulta a seguir gera cada número de 1 a 1.000 e junções cruzadas definidas com 10.000 linhas para produzir o grau de duplicação necessário. A idéia é gerar um conjunto de inserção que apresenta 10.000 linhas numeradas '1' depois 10.000 numeradas '2'... e assim por diante.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Infelizmente, o otimizador ainda produz um plano com uma classificação:

Não há muito a ser dito em defesa do otimizador aqui, este é apenas um plano idiota. Ele optou por gerar 10.000 linhas e, em seguida, cruzar aquelas com números de 1 a 1.000. Isso não permite que a ordem natural dos números seja preservada, portanto, a classificação não pode ser evitada.
Evitando a classificação – Finalmente!
A estratégia que o otimizador perdeu é pegar os números de 1 a 1000 primeiro , e faça junção cruzada de cada número com 10.000 linhas (fazendo 10.000 cópias de cada número em sequência). O plano esperado evitaria uma classificação usando uma junção cruzada de loops aninhados que preserva a ordem das linhas na entrada externa.
Podemos alcançar esse resultado forçando o otimizador a acessar as tabelas derivadas na ordem especificada na consulta, usando o
FORCE ORDER dica de consulta:TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Finalmente, temos o plano que estávamos procurando:
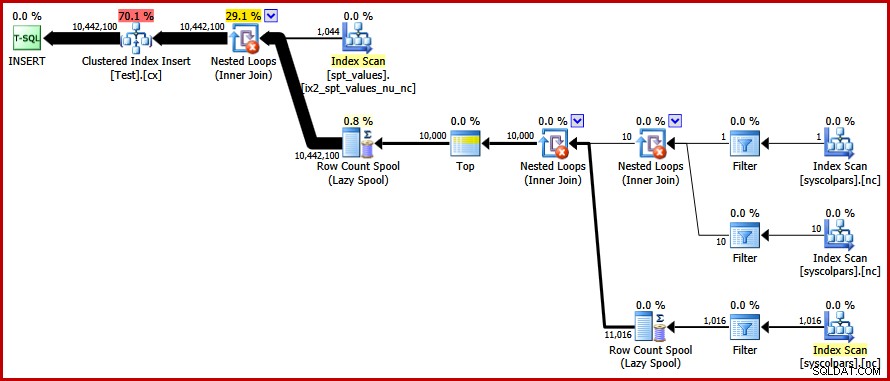
Este plano evita uma classificação explícita enquanto ainda evita divisões de página "ruins" e permite inserções minimamente registradas no índice clusterizado (assumindo que o banco de dados não está usando o
FULL modelo de recuperação). Ele carrega todas as dez milhões de linhas em cerca de 9 segundos no meu laptop (com um único disco giratório SATA de 7200 rpm). Isso representa um ganho de eficiência acentuado nos 30-50 segundos tempo decorrido visto antes da reescrita. Encontrando os valores distintos
Agora que temos os dados de amostra criados, podemos voltar nossa atenção para escrever uma consulta para encontrar os valores distintos na tabela. Uma maneira natural de expressar esse requisito em T-SQL é a seguinte:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
O plano de execução é muito simples, como seria de esperar:

Isso leva cerca de 2.900 ms para ser executado em minha máquina e requer 43.406 leituras lógicas:

Removendo o
MAXDOP (1) dica de consulta gera um plano paralelo:
Isso é concluído em cerca de 1500 ms (mas com 8.764 ms de tempo de CPU consumido) e 43.804 leituras lógicas:

Os mesmos planos e resultados de desempenho se usarmos
GROUP BY em vez de DISTINCT . Um algoritmo melhor
Os planos de consulta mostrados acima lêem todos os valores da tabela base e os processam por meio de um Stream Aggregate. Pensando na tarefa como um todo, parece ineficiente verificar todas as 10 milhões de linhas quando sabemos que existem relativamente poucos valores distintos.
Uma estratégia melhor pode ser encontrar o único valor mais baixo na tabela, depois encontrar o próximo mais alto, e assim por diante até ficarmos sem valores. Fundamentalmente, essa abordagem se presta à busca de singletons no índice, em vez de varrer todas as linhas.
Podemos implementar essa ideia em uma única consulta usando um CTE recursivo, onde a parte âncora encontra o menor valor distinto, então a parte recursiva encontra o próximo valor distinto e assim por diante. Uma primeira tentativa de escrever esta consulta é:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Infelizmente, essa sintaxe não compila:

Ok, então funções agregadas não são permitidas. Em vez de usar
MIN , podemos escrever a mesma lógica usando TOP (1) com um ORDER BY :WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); 
Ainda sem alegria.
Acontece que podemos contornar essas restrições reescrevendo a parte recursiva para numerar as linhas candidatas na ordem necessária e, em seguida, filtrar a linha numerada como 'um'. Isso pode parecer um pouco tortuoso, mas a lógica é exatamente a mesma:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Esta consulta faz compila e produz o seguinte plano de pós-execução:

Observe o operador Top na parte recursiva do plano de execução (destacado). Não podemos escrever um T-SQL
TOP na parte recursiva de uma expressão de tabela comum recursiva, mas isso não significa que o otimizador não possa usar uma! O otimizador introduz o Top com base no raciocínio sobre o número de linhas que ele precisará verificar para encontrar o número '1'. O desempenho desse plano (não paralelo) é muito melhor do que a abordagem Stream Aggregate. Ele é concluído em cerca de 50 ms , com 3007 leituras lógicas na tabela de origem (e 6.001 linhas lidas na tabela de trabalho de spool), em comparação com o melhor anterior de 1.500 ms (8764 ms de tempo de CPU em DOP 8) e 43.804 leituras lógicas:


Conclusão
Nem sempre é possível obter avanços no desempenho da consulta considerando elementos individuais do plano de consulta por conta própria. Às vezes, precisamos analisar a estratégia por trás de todo o plano de execução e depois pensar lateralmente para encontrar um algoritmo e uma implementação mais eficientes.