Em minhas postagens deste ano, discuti as reações instintivas a vários tipos de espera e, nesta postagem, continuarei com o tema de estatísticas de espera e discutirei o
PAGEIOLATCH_XX esperar. Eu digo "espere", mas existem vários tipos de PAGEIOLATCH espera, que eu signifiquei com o XX no final. Os exemplos mais comuns são:PAGEIOLATCH_SH– (SH estão) esperando que uma página de arquivo de dados seja trazida do disco para o buffer pool para que seu conteúdo possa ser lidoPAGEIOLATCH_EXouPAGEIOLATCH_UP– (EX clusivo ou UP date) esperando que uma página de arquivo de dados seja trazida do disco para o buffer pool para que seu conteúdo possa ser modificado
Destes, de longe o tipo mais comum é
PAGEIOLATCH_SH . Quando esse tipo de espera é o mais prevalente em um servidor, a reação automática é que o subsistema de E/S deve ter um problema e é aí que as investigações devem ser focadas.
A primeira coisa a fazer é comparar o
PAGEIOLATCH_SH contagem de espera e duração em relação à sua linha de base. Se o volume de esperas for mais ou menos o mesmo, mas a duração de cada espera de leitura se tornar muito mais longa, eu estaria preocupado com um problema de subsistema de E/S, como:- Uma configuração incorreta/mau funcionamento no nível do subsistema de E/S
- Latência da rede
- Outra carga de trabalho de E/S causando contenção com nossa carga de trabalho
- Configuração de replicação/espelho do subsistema de E/S síncrona
Na minha experiência, o padrão geralmente é que o número de
PAGEIOLATCH_SH esperas aumentou substancialmente a partir da quantidade de linha de base (normal) e a duração da espera também aumentou (ou seja, o tempo para uma E/S de leitura aumentou), porque o grande número de leituras sobrecarrega o subsistema de E/S. Este não é um problema de subsistema de E/S – é o SQL Server que está conduzindo mais E/S do que deveria. O foco agora precisa mudar para o SQL Server para identificar a causa das E/Ss extras. Causas de um grande número de E/Ss de leitura
O SQL Server tem dois tipos de leituras:E/Ss lógicas e E/Ss físicas. Quando a parte de Métodos de Acesso do Mecanismo de Armazenamento precisa acessar uma página, ele solicita ao Buffer Pool um ponteiro para a página na memória (chamado de E/S lógica) e o Buffer Pool verifica seus metadados para ver se essa página está já na memória.
Se a página estiver na memória, o Buffer Pool fornece o ponteiro aos métodos de acesso e a E/S permanece uma E/S lógica. Se a página não estiver na memória, o Buffer Pool emite uma E/S "real" (chamada de E/S física) e o encadeamento precisa aguardar a conclusão - incorrendo em um
PAGEIOLATCH_XX esperar. Assim que a E/S for concluída e o ponteiro estiver disponível, o thread será notificado e poderá continuar em execução. Em um mundo ideal, toda a sua carga de trabalho caberia na memória e, assim, uma vez que o pool de buffers "aquecesse" e retivesse toda a carga de trabalho, não seriam necessárias mais leituras, apenas gravações de dados atualizados. Porém, não é um mundo ideal, e a maioria de vocês não tem esse luxo, então algumas leituras são inevitáveis. Contanto que o número de leituras permaneça em torno do valor da linha de base, não há problema.
Quando um grande número de leituras é necessário repentina e inesperadamente, isso é um sinal de que há uma mudança significativa na carga de trabalho, na quantidade de memória do buffer pool disponível para armazenar cópias de páginas na memória ou em ambos.
Aqui estão algumas possíveis causas raiz (não uma lista exaustiva):
- Pressão de memória externa do Windows no SQL Server fazendo com que o gerenciador de memória reduza o tamanho do pool de buffer
- Planejar o excesso de cache fazendo com que a memória extra seja emprestada do buffer pool
- Um plano de consulta fazendo uma verificação de tabela/índice clusterizado (em vez de uma busca de índice) devido a:
- um aumento no volume de carga de trabalho
- um problema de detecção de parâmetros
- um índice não clusterizado obrigatório que foi descartado ou alterado
- uma conversão implícita
Um padrão para procurar que sugeriria uma verificação de tabela/índice clusterizado sendo a causa também é ver um grande número de
CXPACKET aguarda junto com o PAGEIOLATCH_SH espera. Este é um padrão comum que indica a ocorrência de grandes varreduras de tabela paralela/índice clusterizado. Em todos os casos, você pode ver qual plano de consulta está causando o erro
PAGEIOLATCH_SH espera usando o sys.dm_os_waiting_tasks e outros DMVs, e você pode obter o código para fazer isso no meu post aqui. Se você tiver uma ferramenta de monitoramento de terceiros disponível, ela poderá ajudá-lo a identificar o culpado sem sujar as mãos. Exemplo de fluxo de trabalho com SQL Sentry e Plan Explorer
Em um exemplo simples (obviamente planejado), vamos supor que eu esteja em um sistema cliente usando o conjunto de ferramentas do SQL Sentry e veja um pico nas esperas de E/S na visualização do painel do SQL Sentry, conforme mostrado abaixo:
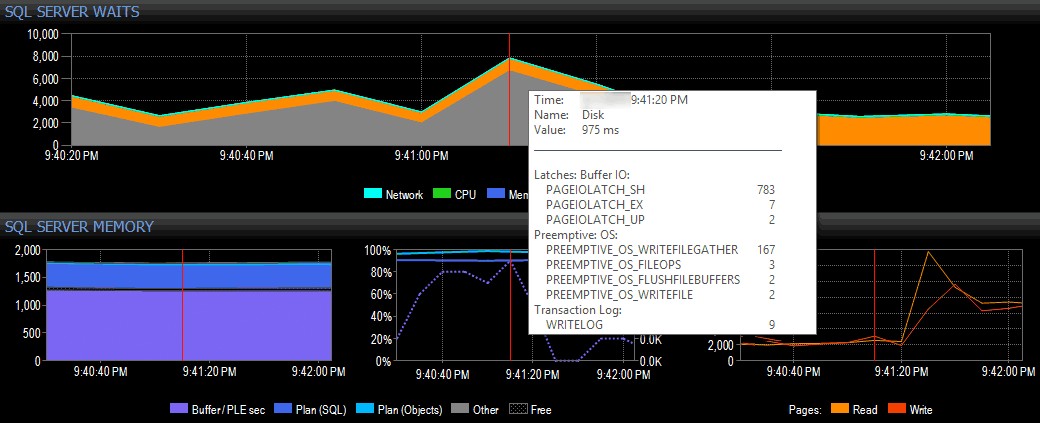
Identificando um pico nas esperas de E/S no SQL Sentry
Decido investigar clicando com o botão direito do mouse em um intervalo de tempo selecionado na hora do pico e, em seguida, pulando para a visualização Top SQL, que me mostrará as consultas mais caras que foram executadas:
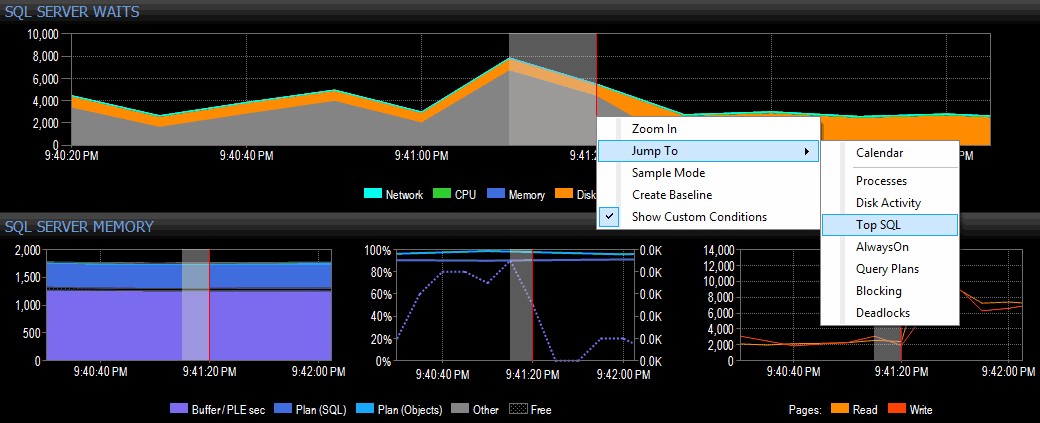
Destacar um intervalo de tempo e navegar para o SQL principal
Nessa exibição, posso ver quais consultas de E/S de execução longa ou alta estavam em execução no momento em que o pico ocorreu e, em seguida, optar por detalhar seus planos de consulta (neste caso, há apenas uma consulta de execução longa, que durou quase um minuto):
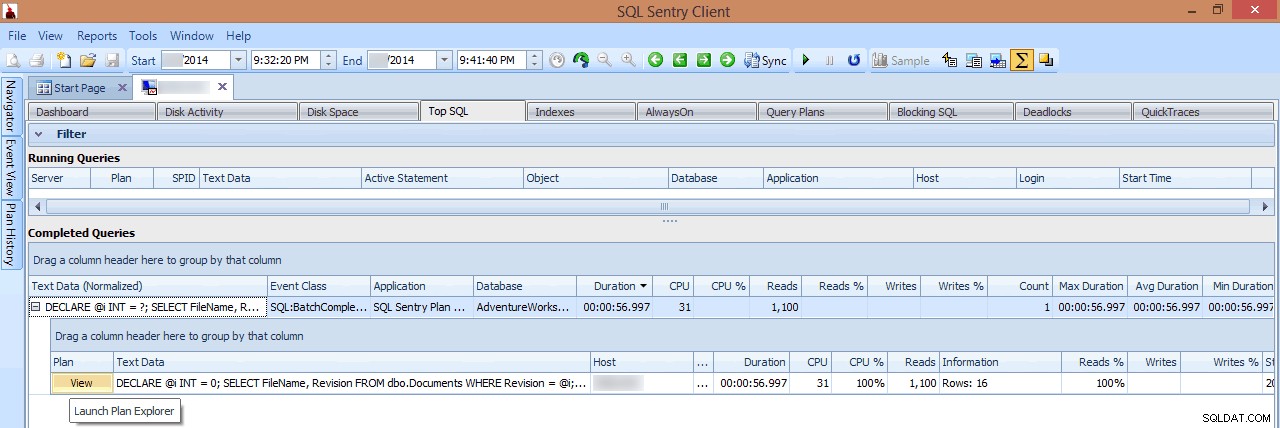
Revisando uma consulta de longa duração no Top SQL
Se eu olhar para o plano no cliente SQL Sentry ou abri-lo no SQL Sentry Plan Explorer, imediatamente vejo vários problemas. O número de leituras necessárias para retornar 7 linhas parece muito alto, o delta entre as linhas estimadas e reais é grande e o plano mostra uma verificação de índice ocorrendo onde eu esperava uma busca:
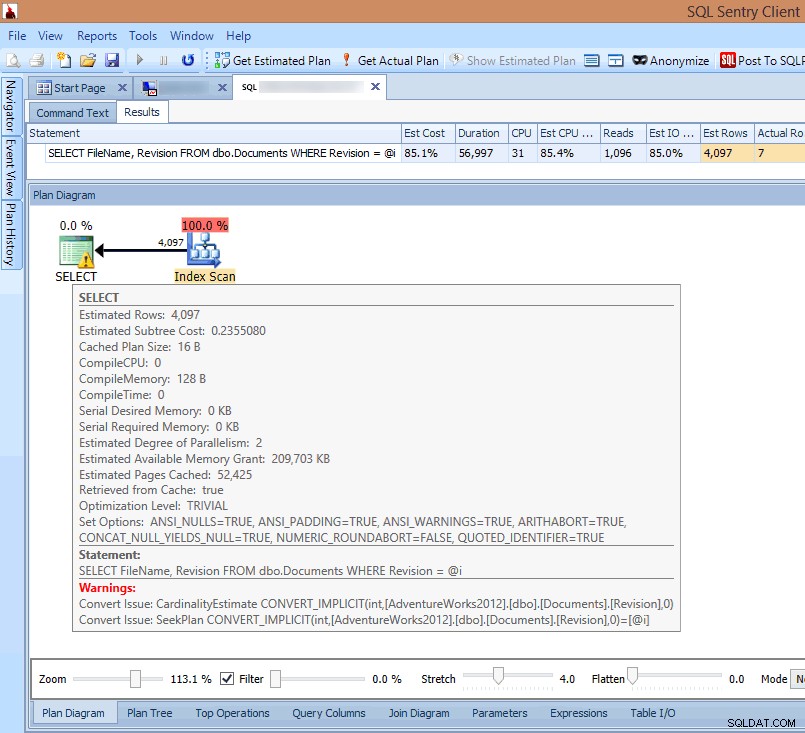
Vendo avisos de conversão implícita no plano de consulta
A causa de tudo isso é destacada no aviso no
SELECT operador:É uma conversão implícita! As conversões implícitas são um problema insidioso causado por uma incompatibilidade entre o tipo de dados do predicado de pesquisa e o tipo de dados da coluna que está sendo pesquisada ou um cálculo executado na coluna da tabela em vez do predicado de pesquisa. Em ambos os casos, o SQL Server não pode usar uma busca de índice na coluna da tabela e deve usar uma verificação.
Isso pode surgir em um código aparentemente inocente, e um exemplo comum é usar um cálculo de data. Se você tem uma tabela que armazena a idade dos clientes e deseja realizar um cálculo para ver quantos têm 21 anos ou mais hoje, você pode escrever um código como este:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Com esse código, o cálculo está na coluna da tabela e, portanto, uma busca de índice não pode ser usada, resultando em uma expressão não pesquisável (tecnicamente conhecida como expressão não SARGable) e uma verificação de tabela/índice clusterizado. Isso pode ser resolvido movendo o cálculo para o outro lado do operador:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Em termos de quando uma comparação básica de colunas requer uma conversão de tipo de dados que pode causar uma conversão implícita, meu colega Jonathan Kehayias escreveu uma excelente postagem no blog que compara todas as combinações de tipos de dados e observa quando uma conversão implícita será necessária.
Resumo
Não caia na armadilha de pensar que
PAGEIOLATCH_XX excessivo as esperas são causadas pelo subsistema de E/S. Na minha experiência, eles geralmente são causados por algo relacionado ao SQL Server e é aí que eu começaria a solucionar problemas. No que diz respeito às estatísticas gerais de espera, você pode encontrar mais informações sobre como usá-las para solucionar problemas de desempenho em:
- Minha série de postagens do blog SQLskills, começando com as estatísticas de espera, ou diga-me onde dói
- Minha biblioteca de tipos de espera e classes de trava aqui
- Meu curso de treinamento on-line Pluralsight SQL Server:solução de problemas de desempenho usando estatísticas de espera
- SQL Sentinela
No próximo artigo da série, discutirei outro tipo de espera que é uma causa comum de reações instintivas. Até então, feliz solução de problemas!