O SQL Server 2005 adicionou a capacidade de incluir colunas não chave em um índice não clusterizado. No SQL Server 2000 e anteriores, para um índice não clusterizado, todas as colunas definidas para um índice eram colunas de chave, o que significava que faziam parte de todos os níveis do índice, da raiz até o nível folha. Quando uma coluna é definida como uma coluna incluída, ela faz parte apenas do nível folha. Os Manuais Online observam os seguintes benefícios das colunas incluídas:
- Eles podem ser tipos de dados não permitidos como colunas de chave de índice.
- Eles não são considerados pelo Mecanismo de Banco de Dados ao calcular o número de colunas de chave de índice ou o tamanho da chave de índice.
Por exemplo, uma coluna varchar(max) não pode fazer parte de uma chave de índice, mas pode ser uma coluna incluída. Além disso, essa coluna varchar(max) não conta no limite de 900 bytes (ou 16 colunas) imposto para a chave de índice.
A documentação também observa o seguinte benefício de desempenho:
Um índice com colunas não-chave pode melhorar significativamente o desempenho da consulta quando todas as colunas da consulta são incluídas no índice como colunas-chave ou não-chave. Os ganhos de desempenho são alcançados porque o otimizador de consulta pode localizar todos os valores de coluna dentro do índice; dados de tabela ou índice clusterizado não são acessados, resultando em menos operações de E/S de disco.
Podemos inferir que se as colunas do índice são colunas-chave ou colunas não-chave, obtemos uma melhoria no desempenho em comparação com quando todas as colunas não fazem parte do índice. Mas, existe uma diferença de desempenho entre as duas variações?
A configuração
Instalei uma cópia do banco de dados AdventuresWork2012 e verifiquei os índices da tabela Sales.SalesOrderHeader usando a versão de sp_helpindex de Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Índices padrão para Sales.SalesOrderHeader
Começaremos com uma consulta direta para teste que recupera dados de várias colunas:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Se executarmos isso no banco de dados AdventureWorks2012 usando o SQL Sentry Plan Explorer e verificarmos o plano e a saída de E/S da tabela, veremos que obteremos uma verificação de índice clusterizado com 689 leituras lógicas:
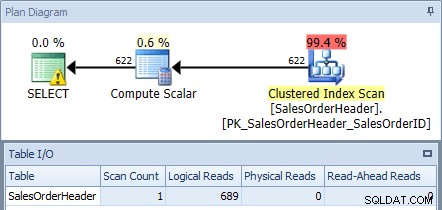
Plano de execução da consulta original
(No Management Studio, você pode ver as métricas de E/S usando
SET STATISTICS IO ON; .) O SELECT tem um ícone de aviso, pois o otimizador recomenda um índice para esta consulta:
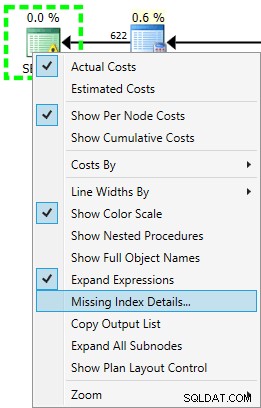
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Teste 1
Primeiro, criaremos o índice recomendado pelo otimizador (chamado NCI1_included), bem como a variação com todas as colunas como colunas-chave (chamada NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Se executarmos novamente a consulta original, uma vez sugerindo-a com NCI1 e uma vez sugerindo-a com NCI1_included, veremos um plano semelhante ao original, mas desta vez há uma busca de índice de cada índice não clusterizado, com valores equivalentes para Tabela I/ O, e custos semelhantes (ambos cerca de 0,006):
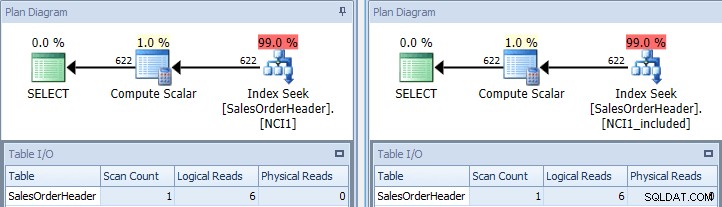
Consulta original com busca de índice – chave à esquerda, incluir em a direita
(A contagem de varredura ainda é 1 porque a busca de índice é na verdade uma varredura de intervalo disfarçada.)
Agora, o banco de dados AdventureWorks2012 não é representativo de um banco de dados de produção em termos de tamanho e, se observarmos o número de páginas em cada índice, veremos que são exatamente iguais:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
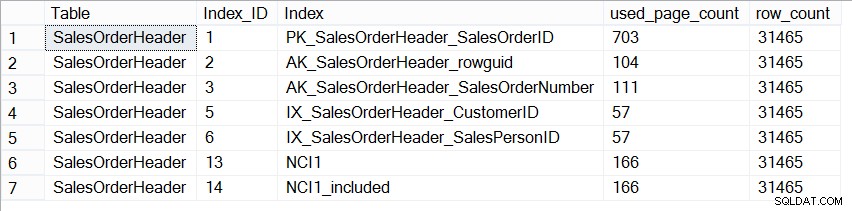
Tamanho dos índices em Sales.SalesOrderHeader
Se estivermos analisando o desempenho, é ideal (e mais divertido) testar com um conjunto de dados maior.
Teste 2
Eu tenho uma cópia do banco de dados AdventureWorks2012 que possui uma tabela SalesOrderHeader com mais de 200 milhões de linhas (script AQUI), então vamos criar os mesmos índices não clusterizados nesse banco de dados e executar novamente as consultas:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
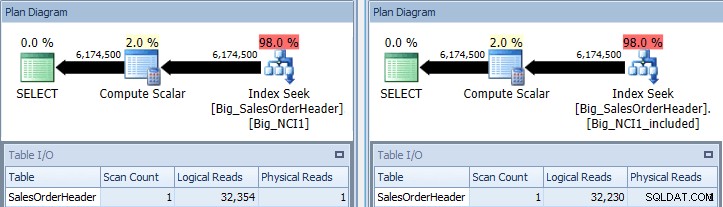
Consulta original com buscas de índice contra Big_NCI1 (l) e Big_NCI1_Included ( r)
Agora temos alguns dados. A consulta retorna mais de 6 milhões de linhas e a busca de cada índice requer pouco mais de 32.000 leituras, e o custo estimado é o mesmo para ambas as consultas (31.233). Ainda não há diferenças de desempenho e, se verificarmos o tamanho dos índices, veremos que o índice com as colunas incluídas possui 5.578 páginas a menos:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Tamanho dos índices em Sales.Big_SalesOrderHeader
Se nos aprofundarmos nisso e verificarmos dm_dm_index_physical_stats, podemos ver que existe diferença nos níveis intermediários do índice:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id]; 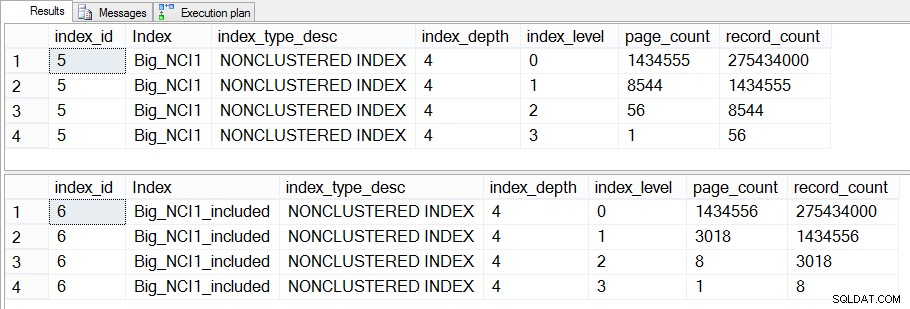
Tamanho dos índices (específico do nível) em Sales.Big_SalesOrderHeader
A diferença entre os níveis intermediários dos dois índices é de 43 MB, o que pode não ser significativo, mas provavelmente ainda estaria inclinado a criar o índice com colunas incluídas para economizar espaço – tanto no disco quanto na memória. Do ponto de vista da consulta, ainda não vemos uma grande mudança no desempenho entre o índice com todas as colunas na chave e o índice com as colunas incluídas.
Teste 3
Para este teste, vamos alterar a consulta e adicionar um filtro para
[SubTotal] >= 100 para a cláusula WHERE:SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
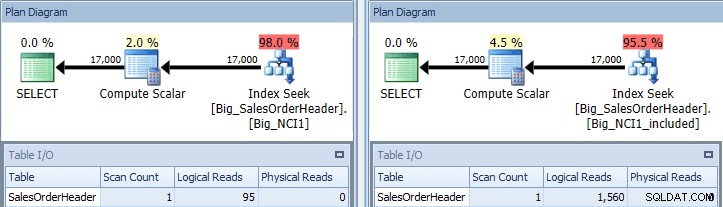
Plano de execução de consulta com predicado SubTotal em ambos os índices
Agora vemos uma diferença em E/S (95 leituras versus 1.560), custo (0,848 versus 1,55) e uma diferença sutil, mas notável, no plano de consulta. Ao usar o índice com todas as colunas da chave, o predicado de busca é o CustomerID e o SubTotal:
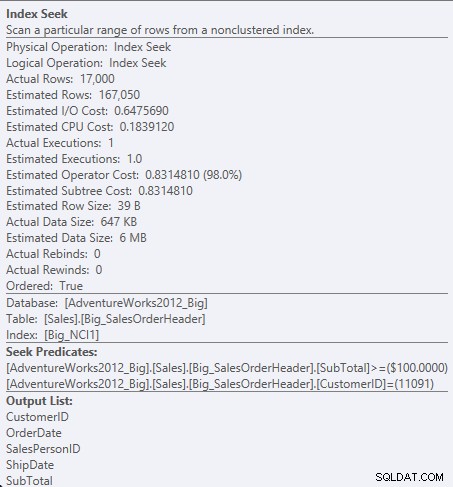
Procurar predicado contra NCI1
Como SubTotal é a segunda coluna na chave de índice, os dados são ordenados e o SubTotal existe nos níveis intermediários do índice. O mecanismo pode buscar diretamente o primeiro registro com CustomerID de 11091 e SubTotal maior ou igual a 100 e, em seguida, ler o índice até que não existam mais registros para CustomerID 11091.
Para o índice com as colunas incluídas, o SubTotal existe apenas no nível folha do índice, portanto CustomerID é o predicado de busca e SubTotal é um predicado residual (apenas listado como Predicate na captura de tela):
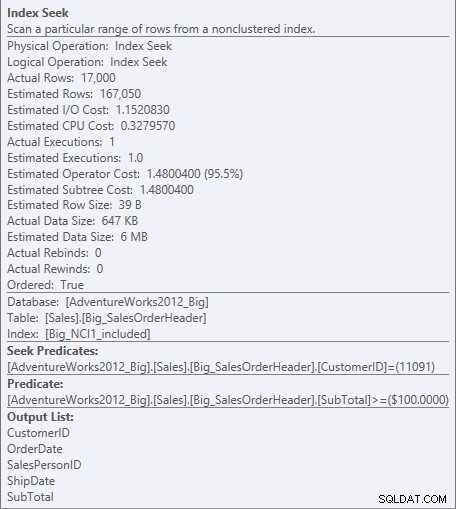
Procurar predicado e predicado residual contra NCI1_included
O mecanismo pode buscar diretamente no primeiro registro em que CustomerID é 11091, mas depois ele precisa examinar todos registro para CustomerID 11091 para ver se o Subtotal é 100 ou superior, porque os dados são ordenados por CustomerID e SalesOrderID (chave de cluster).
Teste 4
Tentaremos mais uma variação de nossa consulta e, desta vez, adicionaremos um ORDER BY:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
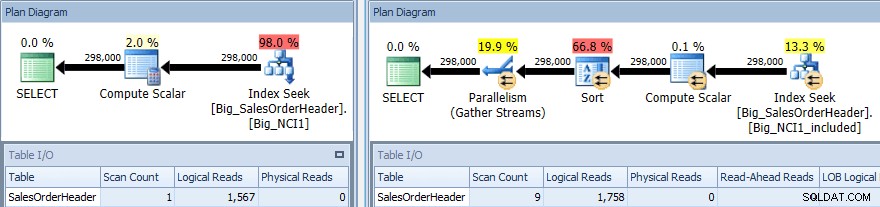
Plano de execução de consulta com SORT nos dois índices
Novamente, temos uma mudança na E/S (embora muito pequena), uma mudança no custo (1,5 vs 9,3) e uma mudança muito maior na forma do plano; também vemos um número maior de varreduras (1 vs 9). A consulta requer que os dados sejam classificados por SubTotal; quando SubTotal faz parte da chave de índice, ele é classificado, portanto, quando os registros para CustomerID 11091 são recuperados, eles já estão na ordem solicitada.
Quando SubTotal existe como uma coluna incluída, os registros para CustomerID 11091 devem ser classificados antes de poderem ser retornados ao usuário, portanto, o otimizador intervém um operador Sort na consulta. Como resultado, a consulta que usa o índice Big_NCI1_included também solicita (e recebe) uma concessão de memória de 29.312 KB, o que é notável (e encontrado nas propriedades do plano).
Resumo
A pergunta original que queríamos responder era se veríamos uma diferença de desempenho quando uma consulta usasse o índice com todas as colunas na chave, versus o índice com a maioria das colunas incluídas no nível folha. Em nosso primeiro conjunto de testes não houve diferença, mas em nosso terceiro e quarto teste houve. Em última análise, depende da consulta. Analisamos apenas duas variações – uma tinha um predicado adicional, a outra um ORDER BY – existem muitas outras.
O que os desenvolvedores e DBAs precisam entender é que há alguns grandes benefícios em incluir colunas em um índice, mas eles nem sempre terão o mesmo desempenho que os índices que têm todas as colunas na chave. Pode ser tentador mover colunas que não fazem parte de predicados e junções para fora da chave e apenas incluí-las, para reduzir o tamanho geral do índice. No entanto, em alguns casos, isso requer mais recursos para execução de consultas e pode prejudicar o desempenho. A degradação pode ser insignificante; pode não ser... você não saberá até testar. Portanto, ao projetar um índice, é importante pensar nas colunas após a principal – e entender se elas precisam fazer parte da chave (por exemplo, porque manter os dados ordenados trará benefícios) ou se podem servir ao seu propósito conforme incluído colunas.
Como é típico da indexação no SQL Server, você precisa testar suas consultas com seus índices para determinar a melhor estratégia. Continua sendo uma arte e uma ciência – tentar encontrar o número mínimo de índices para satisfazer o maior número possível de consultas.