Em minha postagem anterior desta série, demonstrei que nem todos os cenários de consulta podem se beneficiar das tecnologias OLTP na memória. Na verdade, usar o Hekaton em certos casos de uso pode realmente ter um efeito prejudicial no desempenho (clique para ampliar):

Perfil do monitor de desempenho durante a execução do procedimento armazenado
No entanto, eu poderia ter empilhado o baralho contra Hekaton nesse cenário, de duas maneiras:
- O tipo de tabela com otimização de memória que criei tinha uma contagem de buckets de 256, mas eu estava passando até 2.000 valores para comparar. Em uma postagem de blog mais recente da equipe do SQL Server, eles explicaram que superdimensionar a contagem de buckets é melhor do que subdimensioná-la – algo que eu sabia em geral, mas não percebi que também tinha efeitos significativos nas variáveis da tabela:Keep lembre-se de que, para um índice de hash, o bucket_count deve ser cerca de 1-2X o número de chaves de índice exclusivas esperadas. O superdimensionamento geralmente é melhor do que o subdimensionamento:se às vezes você insere apenas 2 valores nas variáveis, mas às vezes insere até 1.000 valores, geralmente é melhor especificar
BUCKET_COUNT=1000.
Eles não discutem explicitamente o motivo real para isso, e tenho certeza de que há muitos detalhes técnicos nos quais podemos nos aprofundar, mas a orientação prescritiva parece ser exagerada. - A chave primária era um índice de hash em duas colunas, enquanto o parâmetro com valor de tabela estava apenas tentando corresponder valores em uma dessas colunas. Muito simplesmente, isso significava que o índice de hash não poderia ser usado. Tony Rogerson explica isso com um pouco mais de detalhes em uma postagem recente no blog:O hash é gerado em todas as colunas contidas no índice, você também deve especificar todas as colunas no índice de hash em sua expressão de verificação de igualdade, caso contrário, o índice não pode ser usado .
Eu não mostrei isso antes, mas observe que o plano em relação à tabela com otimização de memória com o índice de hash de duas colunas realmente faz uma varredura de tabela em vez da busca de índice que você pode esperar no índice de hash não clusterizado (já que o principal a coluna eraSalesOrderID):
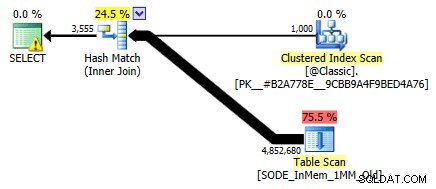
Plano de consulta envolvendo uma tabela na memória com duas colunas índice de hash
Para ser mais específico, em um índice de hash, a coluna inicial não significa um monte de beans por conta própria; o hash ainda é correspondido em todas as colunas, portanto, não funciona como um índice tradicional de árvore B (com um índice tradicional, um predicado envolvendo apenas a coluna inicial ainda pode ser muito útil na eliminação de linhas).
O que fazer?
Bem, primeiro, criei um índice de hash secundário apenas no
SalesOrderID coluna. Um exemplo de uma dessas tabelas, com um milhão de buckets:CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Lembre-se que nossos tipos de tabela são configurados desta forma:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Depois de preencher as novas tabelas com dados e criar um novo procedimento armazenado para fazer referência às novas tabelas, o plano que obtemos corretamente mostra uma busca de índice em relação ao índice de hash de coluna única:

Plano aprimorado usando o índice de hash de coluna única
Mas o que isso realmente significaria para o desempenho? Executei o mesmo conjunto de testes novamente – consultas nesta tabela com contagens de bucket de 16K, 131K e 1MM; usando TVPs clássicos e in-memory com 100, 1.000 e 2.000 valores; e no caso de TVP na memória, usando um procedimento armazenado tradicional e um procedimento armazenado compilado nativamente. Veja como foi o desempenho para 10.000 iterações por combinação:

Perfil de desempenho para 10.000 iterações em um índice de hash de coluna única, usando um TVP de 256 buckets
Você pode pensar, ei, esse perfil de desempenho não parece tão bom; pelo contrário, é muito melhor do que meu teste anterior no mês passado. Ele apenas demonstra que a contagem de buckets da tabela pode ter um grande impacto na capacidade do SQL Server de usar efetivamente o índice de hash. Nesse caso, usar uma contagem de buckets de 16K claramente não é ideal para nenhum desses casos e fica exponencialmente pior à medida que o número de valores no TVP aumenta.
Agora, lembre-se, a contagem de buckets do TVP era 256. Então, o que aconteceria se eu aumentasse isso, conforme orientação da Microsoft? Criei um segundo tipo de tabela com um tamanho de bucket mais apropriado. Como eu estava testando 100, 1.000 e 2.000 valores, usei a próxima potência de 2 para a contagem de buckets (2.048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Criei procedimentos de suporte para isso e executei a mesma bateria de testes novamente. Aqui estão os perfis de desempenho lado a lado:

Comparação do perfil de desempenho com TVPs de 256 e 2.048 buckets
A mudança na contagem de buckets para o tipo de tabela não teve o impacto que eu esperava, dada a declaração da Microsoft sobre dimensionamento. Realmente não teve nenhum efeito positivo; na verdade, para alguns cenários, foi um pouco pior. Mas, no geral, os perfis de desempenho são, para todos os efeitos, os mesmos.
O que teve um grande efeito, porém, foi criar o índice de hash *right* para dar suporte ao padrão de consulta. Fiquei grato por poder demonstrar que – apesar de meus testes anteriores que indicavam o contrário – uma tabela na memória e o TVP na memória poderiam superar a maneira antiga de realizar a mesma coisa. Vamos apenas pegar o caso mais extremo do meu exemplo anterior, quando a tabela tinha apenas um índice de hash de duas colunas:

Perfil de desempenho para 10 iterações em um índice de hash de duas colunas
A barra mais à direita mostra a duração de apenas 10 iterações do procedimento armazenado nativo que corresponde a um índice de hash inadequado – tempos de consulta variando de 735 a 1.601 milissegundos. Agora, no entanto, com o índice de hash correto, as mesmas consultas estão sendo executadas em um intervalo muito menor – de 0,076 milissegundos a 51,55 milissegundos. Se deixarmos de fora o pior caso (contagens de baldes de 16 mil), a discrepância é ainda mais pronunciada. Em todos os casos, isso é pelo menos duas vezes mais eficiente (pelo menos em termos de duração) que qualquer método, sem um procedimento armazenado compilado ingenuamente, em relação à mesma tabela com otimização de memória; e centenas de vezes melhor do que qualquer uma das abordagens contra nossa antiga tabela com otimização de memória com o único índice de hash de duas colunas.
Conclusão
Espero ter demonstrado que muito cuidado deve ser tomado ao implementar tabelas com otimização de memória de qualquer tipo e que, em muitos casos, usar um TVP com otimização de memória por conta própria pode não gerar o maior ganho de desempenho. Você vai querer considerar o uso de procedimentos armazenados compilados nativamente para obter o maior retorno possível e, para melhor escala, você realmente vai querer prestar atenção à contagem de buckets para os índices de hash em suas tabelas com otimização de memória (mas talvez não tanta atenção aos seus tipos de tabela com otimização de memória).
Para leitura adicional sobre a tecnologia OLTP na memória em geral, confira estes recursos:
- Blog da equipe do SQL Server (Tag:Hekaton e Tag:OLTP na memória – os nomes de código não são divertidos?)
- Blog de Bob Beauchemin
- Blog de Klaus Aschenbrenner