De vez em quando vejo alguém expressar um requisito para criar um número aleatório para uma chave. Normalmente isso é criar algum tipo de substituto do Cliente ou UserID que é um número único dentro de algum alcance, mas não é emitido sequencialmente, e é, portanto, muito menos adivinhação do que um
IDENTITY valor. Vamos conjunto de lado, por um momento, que se alguém pode adivinhar um Cliente ou UserID deve ser em grande parte irrelevante - estes valores substitutos não devem ser expostas fora do aplicativo, e um usuário final não deve ser capaz de fazer algo diferente com o conhecimento (ou adivinhar!) de ID de outra pessoa. Afinal, mesmo se você gerar um número "aleatório" entre 1 e 100.000 ou 1 e 1.000.000, eu ainda podia adivinhar quaisquer valores de ID que já foram gerados, por exemplo, através da força bruta. E se eu posso fazer qualquer coisa com um jogo positivo, há algo seriamente quebrado com o aplicativo.
NEWID() resolve o problema de adivinhar, mas a penalidade de desempenho é geralmente um deal-breaker, especialmente quando agrupado:chaves muito mais amplas do que números inteiros, e divisões de página devido a valores não sequenciais. NEWSEQUENTIALID() resolve o problema página dividida, mas ainda é uma chave muito grande, e re-introduz o problema que você pode adivinhar o próximo valor (ou valores recém-emitidas) com algum nível de precisão. Como resultado, eles querem uma técnica para gerar um aleatório e inteiro único. Gerar um número aleatório por si só não é difícil, usando métodos como
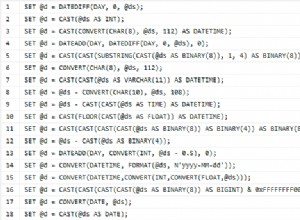
RAND() ou CHECKSUM(NEWID()) . O problema surge quando você tem que detectar colisões. Vamos dar uma rápida olhada em uma abordagem típica, assumindo que queremos valores CustomerID entre 1 e 1.000.000:DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END Como a tabela fica maior, não só a verificação de duplicatas ficar mais caro, mas suas chances de gerar uma duplicata subir também. Portanto, esta abordagem pode parecem funcionar bem quando a tabela é pequena, mas eu suspeito que deve doer mais e mais ao longo do tempo.
Uma abordagem diferente
Eu sou um grande fã de tabelas auxiliares; Eu tenho escrito publicamente sobre mesas de calendário e tabelas de números de uma década, e usá-los por muito mais tempo. E este é um caso onde eu acho uma tabela pré-preenchido poderia vir a calhar real. Por contar com geração de números aleatórios em tempo de execução e lidar com potenciais duplicados, quando você pode preencher todos esses valores com antecedência e sabe - com 100% de certeza, se você proteger suas tabelas de DML não autorizada - que o próximo valor que você selecionar nunca foi usado antes?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; Esta população levou 9 segundos para criar (em uma máquina virtual em um laptop), e ocuparam cerca de 17 MB no disco. Os dados nos olhares tabela como esta:
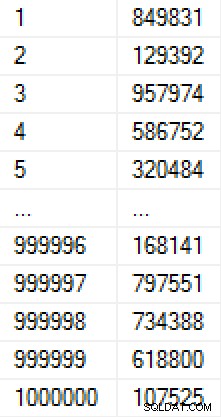
(Se nós estávamos preocupados sobre como os números estavam sendo povoada, poderíamos acrescentar uma restrição exclusiva na coluna Valor, o que tornaria o quadro 30 MB. Se tivéssemos aplicado compactação de página, teria sido 11 MB ou 25 MB, respectivamente. )
Eu criei uma outra cópia da tabela, e preenchida com os mesmos valores, para que eu pudesse testar dois métodos diferentes de derivar o valor seguinte:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Agora, quando nós queremos um novo número aleatório, que pode apenas pop um fora da pilha de números existentes, e excluí-lo. Isso nos impede de ter que se preocupar com duplicatas, e nos permite puxar números - usando um índice agrupado - que são, na verdade, já em ordem aleatória. (Estritamente falando, não temos a Excluir os números como nós usá-los; poderíamos adicionar uma coluna para indicar se um valor foi utilizado -. isso tornaria mais fácil para restabelecer e reutilizar esse valor no caso de um cliente depois é excluído ou algo sai errado desta transação, mas antes de estarem completamente criado)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Eu usei uma variável de tabela para manter a saída intermediária, porque há várias limitações com DML combináveis que podem fazer com que seja impossível para inserir na tabela clientes diretamente a partir do
DELETE (Por exemplo, a presença de chaves estrangeiras). Ainda assim, reconhecendo que não será sempre possível, eu também queria testar esse método:DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Note-se que nenhuma dessas soluções verdadeiramente garantir a ordem aleatória, especialmente se a tabela de números aleatórios tem outros índices (como um índice exclusivo na coluna Value). Não há maneira de definir uma ordem para um
DELETE usando TOP; a partir da documentação:Quando TOP é utilizada com a inserção, UPDATE MERGE ou eliminar, as linhas referenciadas não estão dispostas em qualquer ordem e a ordem na cláusula não pode ser directamente especificado nestas indicações. Se você precisar usar TOP para inserir, excluir ou modificar linhas em uma ordem cronológica significativa, você deve usar TOP junto com uma cláusula ORDER BY que é especificado em um comunicado subselect.
Então, se você quiser garantir ordenação aleatória, você poderia fazer algo parecido com isto em vez disso:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Outra consideração aqui é que, para estes testes, as tabelas clientes têm uma chave primária agrupado na coluna CustomerID; isso irá certamente levar a divisões de página assim que você inserir valores aleatórios. No mundo real, se você tivesse este requisito, você provavelmente acabar agrupamento em uma coluna diferente.
Note que eu também deixado de fora transações e manipulação de erro aqui, mas estes também deve ser uma consideração para o código de produção.
Performance Testing
Para estabelecer algumas comparações de desempenho realista, criei cinco procedimentos armazenados, representando os seguintes cenários (teste de velocidade, a distribuição, e a frequência de colisão dos diferentes métodos aleatórios, bem como a velocidade de utilização de uma tabela predefinida de números aleatórios):
- geração Runtime usando
CHECKSUM(NEWID()) - geração Runtime usando
CRYPT_GEN_RANDOM() - geração Runtime usando
RAND() - predefinidos números mesa com variável de tabela
- predefinidos números mesa com inserção direta
Eles usam uma tabela de registro para rastrear duração e número de colisões:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
O código para os procedimentos a seguir (clique para exibir / ocultar):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO E, a fim de testar isso, gostaria de executar cada procedimento armazenado 1.000.000 vezes:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
Não surpreendentemente, os métodos que utilizam a tabela predefinida de números aleatórios levou um pouco mais longo * no início do teste *, uma vez que teve de realizar tanto ler e escrever I / O de cada vez. Tendo em mente que estes números estão em microssegundos , Aqui estão as durações médias para cada procedimento, em diferentes intervalos ao longo do caminho (em média durante os primeiros 10.000 execuções, Oriente 10.000 execuções, os últimos 10.000 execuções, e os últimos 1.000 execuções):
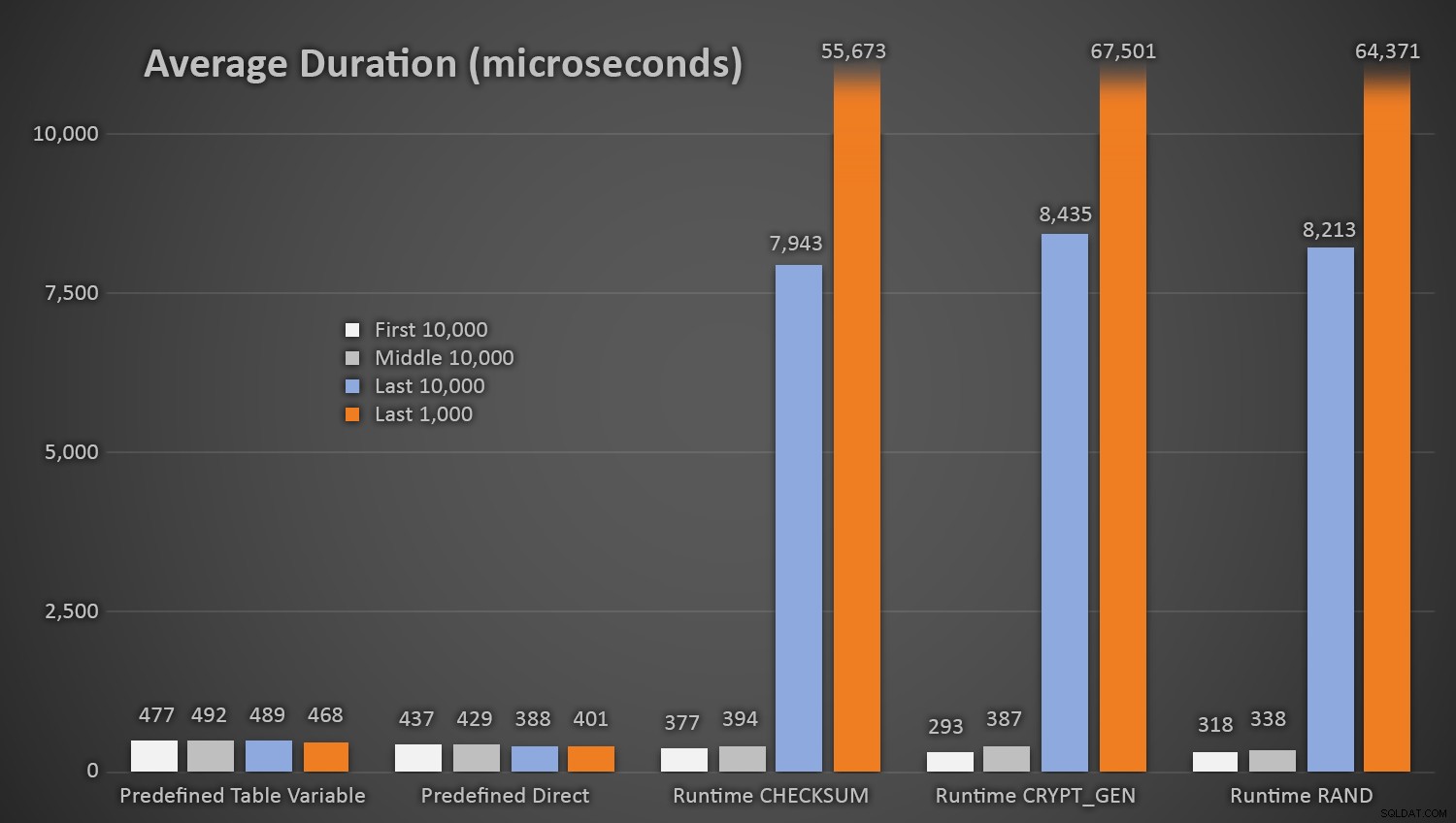
Isso funciona bem para todos os métodos quando há poucas linhas na tabela de clientes, mas como a mesa fica maior e maior, o custo de verificar o novo número aleatório com os dados existentes a partir dos métodos de tempo de execução aumenta substancialmente, tanto por causa do aumento I / o e também porque o número de colisões sobe (forçando-o a tentar e tentar novamente). Compare a duração média quando nos seguintes intervalos de contagem de colisão (e lembre-se que este padrão afeta somente os métodos de tempo de execução):
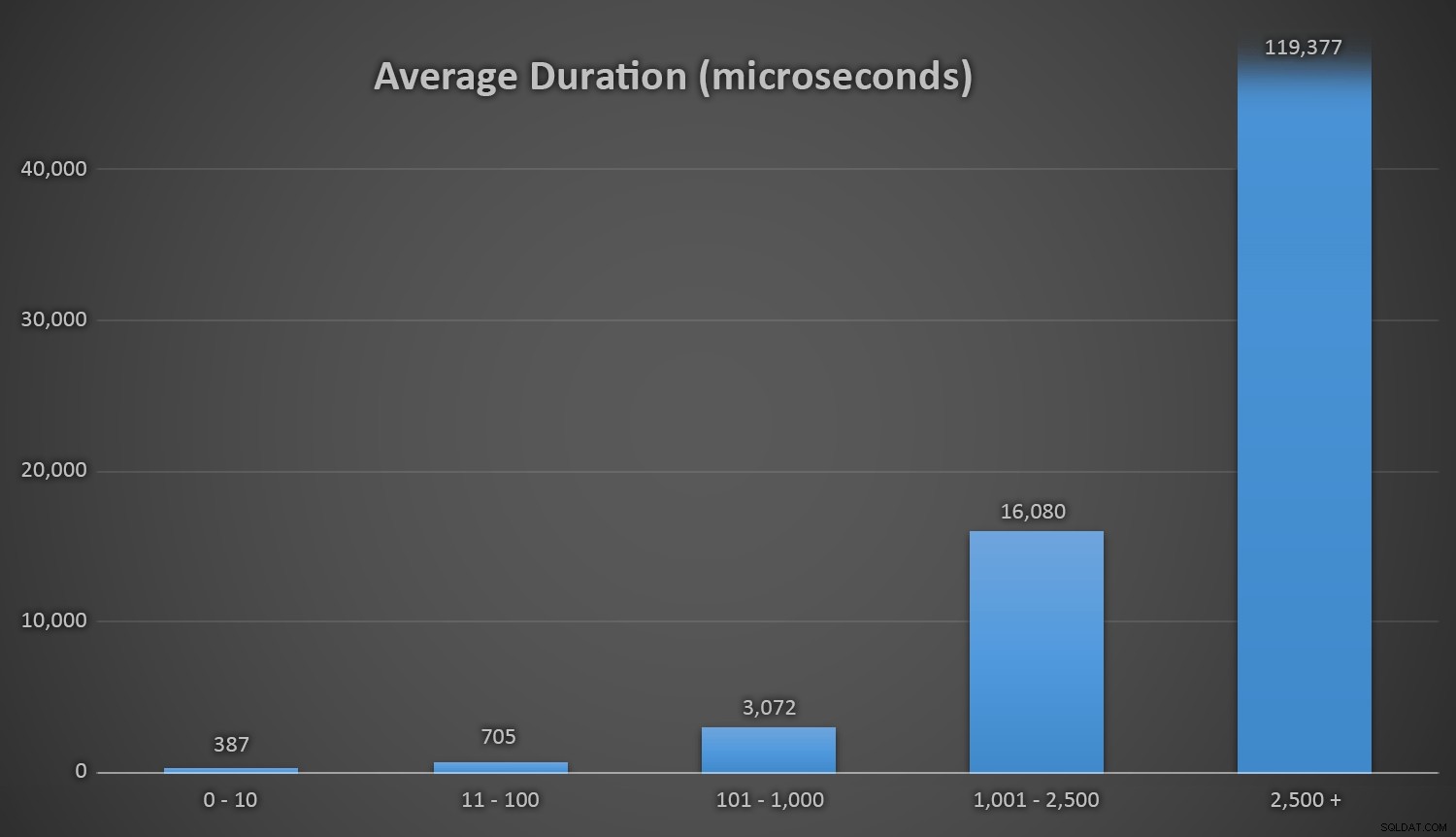
Eu gostaria que houvesse uma simples maneira de duração gráfico contra as contagens de colisão. Vou deixá-lo com este boato:nos últimos três inserções, os seguintes métodos de execução teve que realizar isso muitas tentativas antes de finalmente tropeçou no último identificação única que eles estavam procurando, e este é o tempo que levou:
| Número de colisões | Duração (microssegundos) | ||
|---|---|---|---|
| checksum (NEWID ()) | 3 a última linha | 63545 | 639.358 |
| segundo a última linha | 164.807 | 1.605.695 | |
| Última linha | 30630 | 296.207 | |
| CRYPT_GEN_RANDOM () | 3 a última linha | 219.766 | 2.229.166 |
| segundo a última linha | 255.463 | 2.681.468 | |
| Última linha | 136.342 | 1.434.725 | |
| RAND () | 3 a última linha | 129.764 | 1.215.994 |
| segundo a última linha | 220.195 | 2.088.992 | |
| Última linha | 440.765 | 4.161.925 | |
É interessante notar que a última linha nem sempre é a que produz o maior número de colisões, de modo que este possa começar a ser um problema real muito antes de você usou-se 999,000+ valores.
Outra consideração
Você pode querer considerar a criação de algum tipo de alerta ou notificação quando a tabela de RandomNumbers começa a ficar abaixo de um determinado número de linhas (em que ponto você pode voltar a preencher a tabela com um novo conjunto de 1.000.001 - 2.000.000, por exemplo). Você teria que fazer algo semelhante se estivesse a geração de números aleatórios na mosca - se você está mantendo isso para dentro de um intervalo de 1 - 1.000.000, então você teria que mudar o código para gerar números a partir de uma gama diferente uma vez que você' usei-se todos esses valores.
Se você estiver usando o número aleatório pelo método de tempo de execução, então você pode evitar esta situação, mudando constantemente o tamanho da piscina a partir do qual você desenhar um número aleatório (que também deve estabilizar e reduzir drasticamente o número de colisões). Por exemplo, em vez de:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Você poderia basear a piscina no número de linhas já na tabela:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0); Agora, sua preocupação única real é quando você se aproxima do limite superior para
INT … Nota:. Eu também recentemente escreveu uma dica sobre isso em MSSQLTips.com