Todo produto tem bugs e o SQL Server não é exceção. Usar os recursos do produto de uma maneira um pouco incomum (ou combinar recursos relativamente novos) é uma ótima maneira de encontrá-los. Os bugs podem ser interessantes e até educativos, mas talvez algumas das alegrias sejam perdidas quando a descoberta resultar em seu pager disparando às 4 da manhã, talvez depois de uma noite particularmente social com amigos…
O bug que é o assunto deste post provavelmente é razoavelmente raro na natureza, mas não é um caso clássico de borda. Conheço pelo menos um consultor que o encontrou em um sistema de produção. Sobre um assunto completamente não relacionado, devo aproveitar esta oportunidade para dizer "olá" ao Grumpy Old DBA (blog).
Vou começar com algumas informações relevantes sobre junções de mesclagem. Se você tem certeza de que já sabe tudo o que há para saber sobre junção de mesclagem, ou apenas quer ir direto ao assunto, sinta-se à vontade para rolar para baixo até a seção intitulada "O Bug".
Mesclar associação
A junção de mesclagem não é uma coisa muito complicada e pode ser muito eficiente nas circunstâncias certas. Requer que suas entradas sejam classificadas nas chaves de junção e tenha melhor desempenho no modo um para muitos (onde pelo menos suas entradas são exclusivas nas chaves de junção). Para junções de um para muitos de tamanho moderado, a junção de mesclagem serial não é uma má escolha, desde que os requisitos de classificação de entrada possam ser atendidos sem executar uma classificação explícita.
Evitar uma classificação é mais comumente alcançado explorando a ordenação fornecida por um índice. A junção de mesclagem também pode aproveitar a ordem de classificação preservada de uma classificação anterior e inevitável. Uma coisa legal sobre a junção de mesclagem é que ela pode parar de processar as linhas de entrada assim que uma das entradas ficar sem linhas. Uma última coisa:a junção de mesclagem não se importa se a ordem de classificação de entrada é crescente ou decrescente (embora ambas as entradas devam ser as mesmas). O exemplo a seguir usa uma tabela Numbers padrão para ilustrar a maioria dos pontos acima:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Observe que os índices que impõem as chaves primárias nessas duas tabelas são definidos como descendentes. O plano de consulta para o
INSERT tem uma série de recursos interessantes: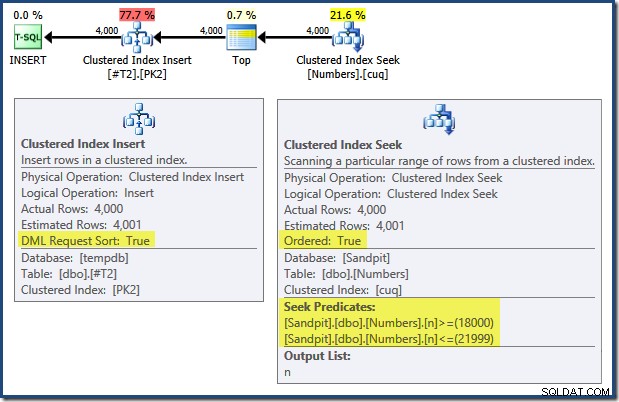
Lendo da esquerda para a direita (como é apenas sensato!) o Clustered Index Insert tem o conjunto de propriedades "DML Request Sort". Isso significa que o operador requer linhas na ordem de chave de índice clusterizado. O índice clusterizado (impondo a chave primária neste caso) é definido como
DESC , portanto, as linhas com valores mais altos precisam chegar primeiro. O índice clusterizado na minha tabela Numbers é ASC , portanto, o otimizador de consulta evita uma classificação explícita buscando primeiro a correspondência mais alta na tabela Numbers (21.999) e, em seguida, varrendo a correspondência mais baixa (18.000) na ordem inversa do índice. A visualização "Plan Tree" no SQL Sentry Plan Explorer mostra claramente a varredura reversa (para trás):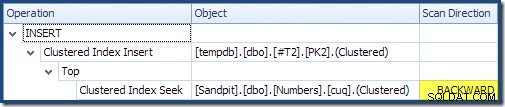
A varredura para trás inverte a ordem natural do índice. Uma varredura para trás de um
ASC a chave de índice retorna linhas em ordem decrescente de chave; uma varredura para trás de um DESC chave de índice retorna linhas em ordem crescente de chave. A "direção de varredura" não indica a ordem de chave retornada por si só - você precisa saber se o índice é ASC ou DESC para fazer essa determinação. Usando essas tabelas e dados de teste (
T1 tem 10.000 linhas numeradas de 10.000 a 19.999 inclusive; T2 tem 4.000 linhas numeradas de 18.000 a 21.999), a consulta a seguir une as duas tabelas e retorna os resultados em ordem decrescente de ambas as chaves:SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; A consulta retorna as 2.000 linhas correspondentes corretas, como seria de esperar. O plano pós-execução é o seguinte:
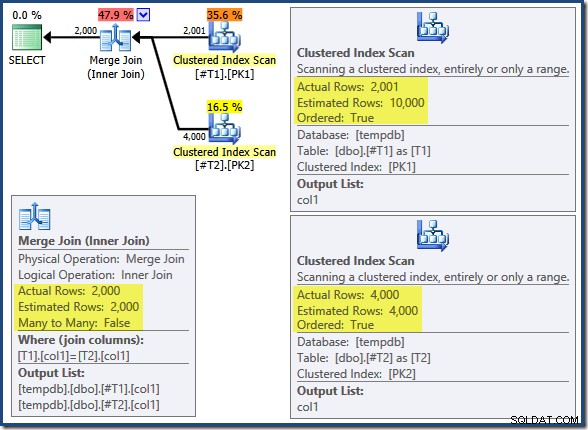
A junção de mesclagem não está sendo executada no modo muitos para muitos (a entrada superior é exclusiva nas teclas de junção) e a estimativa de cardinalidade de 2.000 linhas está exatamente correta. A varredura de índice clusterizado da tabela
T2 é ordenada (embora tenhamos que esperar um momento para descobrir se essa ordem é para frente ou para trás) e a estimativa de cardinalidade de 4.000 linhas também está exatamente correta. A varredura de índice clusterizado da tabela T1 também é ordenado, mas apenas 2.001 linhas foram lidas, enquanto 10.000 foram estimadas. A visualização em árvore do plano mostra que ambas as Varreduras de Índice Clusterizado são ordenadas para frente: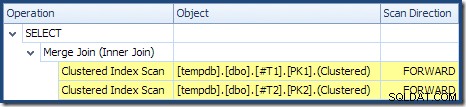
Lembre-se de ler um
DESC índice FORWARD produzirá linhas na ordem de chave inversa. Isso é exatamente o que é exigido pelo ORDER BY T1.col DESC, T2.col1 DESC cláusula, portanto, nenhuma classificação explícita é necessária. O pseudocódigo para um para muitos Merge Join (reproduzido do blog Merge Join de Craig Freedman) é:
A varredura de ordem decrescente de
T1 retorna linhas começando em 19.999 e indo até 10.000. A varredura de ordem decrescente de T2 retorna linhas começando em 21.999 e indo até 18.000. Todas as 4.000 linhas em T2 são eventualmente lidos, mas o processo de mesclagem iterativo para quando o valor da chave 17.999 é lido de T1 , porque T2 fica sem filas. O processamento de mesclagem, portanto, é concluído sem a leitura completa de T1 . Ele lê linhas de 19.999 até 17.999 inclusive; um total de 2.001 linhas, conforme mostrado no plano de execução acima. Sinta-se à vontade para executar novamente o teste com
ASC em vez disso, alterando também o ORDER BY cláusula de DESC para ASC . O plano de execução produzido será muito semelhante, não sendo necessário nenhum tipo de ordenação. Para resumir os pontos que serão importantes em um momento, o Merge Join requer entradas classificadas por chave de junção, mas não importa se as chaves são classificadas em ordem crescente ou decrescente.
O erro
Para reproduzir o bug, pelo menos uma de nossas tabelas precisa ser particionada. Para manter os resultados gerenciáveis, este exemplo usará apenas um pequeno número de linhas, portanto, a função de particionamento também precisa de limites pequenos:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
A primeira tabela contém duas colunas e é particionada na PRIMARY KEY:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
); A segunda tabela não é particionada. Ele contém uma chave primária e uma coluna que se unirá à primeira tabela:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Os dados de amostra
A primeira tabela tem 14 linhas, todas com o mesmo valor no
SomeID coluna. SQL Server atribui a IDENTITY valores da coluna, numerados de 1 a 14. INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123); A segunda tabela é simplesmente preenchida com a
IDENTITY valores da tabela um:INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Os dados nas duas tabelas são assim:
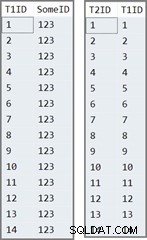
A consulta de teste
A primeira consulta simplesmente une as duas tabelas, aplicando um único predicado de cláusula WHERE (que coincide com todas as linhas neste exemplo bastante simplificado):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; O resultado contém todas as 14 linhas, conforme esperado:

Devido ao pequeno número de linhas, o otimizador escolhe um plano de junção de loops aninhados para esta consulta:
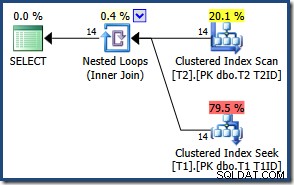
Os resultados são os mesmos (e ainda corretos) se forçarmos uma junção de hash ou mesclagem:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); 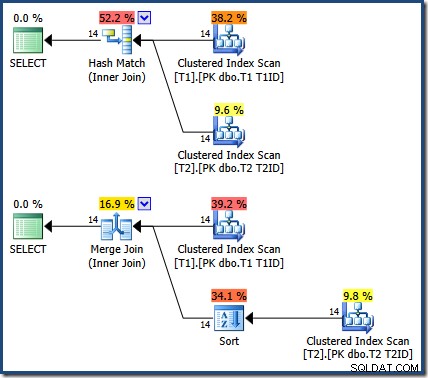
O Merge Join é um para muitos, com uma classificação explícita em
T1ID necessário para a tabela T2 . O problema do índice descendente
Tudo está bem até que um dia (por boas razões que não precisam nos preocupar aqui) outro administrador adiciona um índice descendente no
SomeID coluna da tabela 1:CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Nossa consulta continua a produzir resultados corretos quando o otimizador escolhe um Nested Loops ou Hash Join, mas é uma história diferente quando um Merge Join é usado. O seguinte ainda usa uma dica de consulta para forçar o Merge Join, mas isso é apenas uma consequência das baixas contagens de linhas no exemplo. O otimizador naturalmente escolheria o mesmo plano Merge Join com dados de tabela diferentes.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); O plano de execução é:
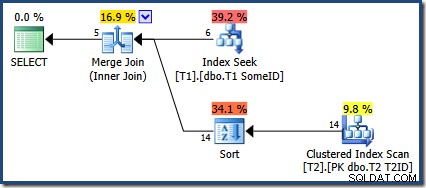
O otimizador optou por usar o novo índice, mas a consulta agora produz apenas cinco linhas de saída:

O que aconteceu com as outras 9 linhas? Para ser claro, este resultado está incorreto. Os dados não foram alterados, portanto, todas as 14 linhas devem ser retornadas (como ainda são com um plano de Loops Aninhados ou Junção de Hash).
Causa e explicação
O novo índice não clusterizado em
SomeID não é declarado como exclusivo, portanto, a chave de índice clusterizado é adicionada silenciosamente a todos os níveis de índice não clusterizados. SQL Server adiciona o T1ID column (a chave clusterizada) para o índice não clusterizado, como se tivéssemos criado o índice assim:CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Observe a falta de um
DESC qualificador no T1ID adicionado silenciosamente chave. As chaves de índice são ASC por padrão. Isso não é um problema em si (embora contribua). A segunda coisa que acontece com nosso índice automaticamente é que ele é particionado da mesma forma que a tabela base. Portanto, a especificação completa do índice, se escrevê-la explicitamente, seria:CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Esta é agora uma estrutura bastante complexa, com chaves em todos os tipos de ordens diferentes. É complexo o suficiente para o otimizador de consulta errar ao raciocinar sobre a ordem de classificação fornecida pelo índice. Para ilustrar, considere a seguinte consulta simples:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC; A coluna extra apenas nos mostrará a qual partição a linha atual pertence. Caso contrário, é apenas uma consulta simples que retorna
T1ID valores em ordem crescente, WHERE SomeID = 123 . Infelizmente, os resultados não são os especificados pela consulta: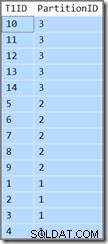
A consulta requer que
T1ID os valores devem ser retornados em ordem crescente, mas não é isso que obtemos. Obtemos valores em ordem crescente por partição , mas as próprias partições são retornadas na ordem inversa! Se as partições foram retornadas em ordem crescente (e o T1ID valores permaneciam classificados dentro de cada partição conforme mostrado), o resultado seria correto. O plano de consulta mostra que o otimizador ficou confuso com o
DESC principal key do índice e achei necessário ler as partições na ordem inversa para obter resultados corretos: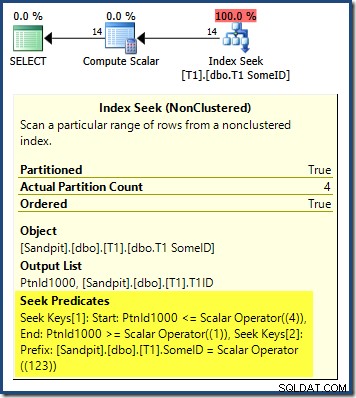
A busca de partição começa na partição mais à direita (4) e prossegue para a partição 1. Você pode pensar que podemos corrigir o problema classificando explicitamente no número da partição
ASC no ORDER BY cláusula:SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Esta consulta retorna os mesmos resultados (isto não é um erro de impressão ou um erro de copiar/colar):
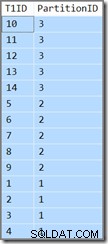
O ID da partição ainda está em decrescente ordem (não crescente, conforme especificado) e
T1ID é classificado apenas em ordem crescente dentro de cada partição. Essa é a confusão do otimizador, ele realmente pensa (respire fundo agora) que varrer o índice de chave inicial-descendente particionado em uma direção direta, mas com as partições invertidas, resultará na ordem especificada pela consulta. Não culpo, para ser franco, as várias considerações de ordem de classificação também fazem minha cabeça doer.
Como exemplo final, considere:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Os resultados são:

Novamente, o
T1ID ordem de classificação dentro de cada partição está descendo corretamente, mas as próprias partições são listadas para trás (elas vão de 1 a 3 nas linhas). Se as partições fossem retornadas na ordem inversa, os resultados seriam corretamente 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 . Voltar para a junção de mesclagem
A causa dos resultados incorretos com a consulta Merge Join agora é aparente:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); 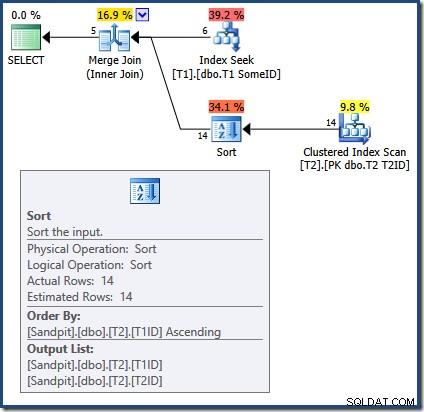
O Merge Join requer entradas classificadas. A entrada de
T2 é classificado explicitamente por T1TD então tudo bem. O otimizador raciocina incorretamente que o índice em T1 pode fornecer linhas em T1ID pedido. Como vimos, este não é o caso. O Index Seek produz a mesma saída de uma consulta que já vimos:SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC; 
Apenas as primeiras 5 linhas estão em
T1ID pedido. O próximo valor (5) certamente não está em ordem crescente, e o Merge Join interpreta isso como fim de fluxo em vez de produzir um erro (pessoalmente, eu esperava uma afirmação de varejo aqui). De qualquer forma, o efeito é que o Merge Join incorretamente termina o processamento mais cedo. Como lembrete, os resultados (incompletos) são:
Conclusão
Este é um bug muito sério na minha opinião. Uma busca de índice simples pode retornar resultados que não respeitam o
ORDER BY cláusula. Mais especificamente, o raciocínio interno do otimizador está completamente quebrado para índices não clusterizados não exclusivos particionados com uma chave à esquerda decrescente. Sim, este é um ligeiramente arranjo incomum. Mas, como vimos, resultados corretos podem ser subitamente substituídos por resultados incorretos apenas porque alguém adicionou um índice descendente. Lembre-se de que o índice adicionado parecia inocente o suficiente:nenhum
ASC/DESC explícito incompatibilidade de chave e nenhum particionamento explícito. O bug não está limitado a junções de mesclagem. Potencialmente, qualquer consulta que envolva uma tabela particionada e que dependa da ordem de classificação do índice (explícito ou implícito) pode ser vítima. Este bug existe em todas as versões do SQL Server de 2008 a 2014 CTP 1 inclusive. O Banco de Dados Windows SQL Azure não oferece suporte ao particionamento, portanto, o problema não surge. O SQL Server 2005 usou um modelo de implementação diferente para particionamento (com base em
APPLY ) e também não sofre deste problema. Se você tiver um momento, considere votar no meu item Connect para este bug.
Resolução
A correção para esse problema já está disponível e documentada em um artigo da Base de Dados de Conhecimento. Observe que a correção requer uma atualização de código e o sinalizador de rastreamento 4199 , que permite várias outras alterações do processador de consulta. É incomum que um bug de resultados incorretos seja corrigido em 4199. Pedi esclarecimentos sobre isso e a resposta foi:
Mesmo que esse problema envolva resultados incorretos, como outros hotfixes envolvendo o Query Processor, apenas habilitamos essa correção no sinalizador de rastreamento 4199 para SQL Server 2008, 2008 R2 e 2012. No entanto, essa correção está "ativada" por padrão sem o sinalizador de rastreamento no SQL Server 2014 RTM.



