Em um tópico recente no StackExchange, um usuário teve o seguinte problema:
Quero uma consulta que retorne a primeira pessoa na tabela com GroupID =2. Se não existir ninguém com GroupID =2, quero a primeira pessoa com RoleID =2.
Vamos descartar, por enquanto, o fato de que "primeiro" é terrivelmente definido. Na verdade, o usuário não se importava com a pessoa que ele pegava, se veio aleatoriamente, arbitrariamente ou através de alguma lógica explícita além de seus critérios principais. Ignorando isso, digamos que você tenha uma tabela básica:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
No mundo real, provavelmente existem outras colunas, restrições adicionais, talvez chaves estrangeiras para outras tabelas e certamente outros índices. Mas vamos manter isso simples e fazer uma consulta.
Soluções prováveis
Com esse design de mesa, resolver o problema parece simples, certo? A primeira tentativa que você provavelmente faria é:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Isso usa
TOP e um ORDER BY condicional para tratar os usuários com GroupID =2 como prioridade mais alta. O plano para esta consulta é bastante simples, com a maior parte do custo acontecendo em uma operação de classificação. Aqui estão as métricas de tempo de execução em uma tabela vazia: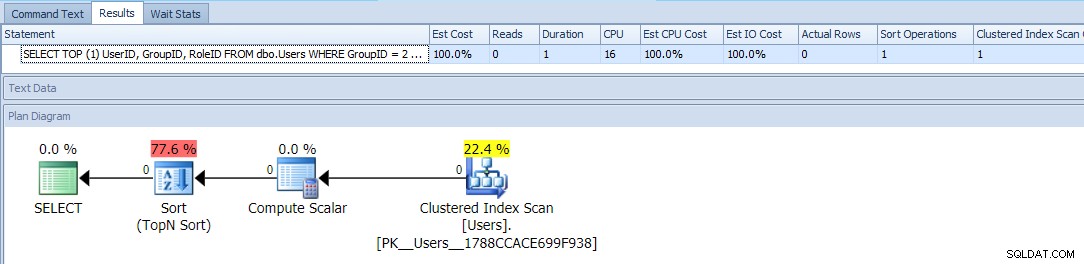
Isso parece ser o melhor que você pode fazer - um plano simples que verifica a mesa apenas uma vez, e que não seja um tipo irritante com o qual você deve ser capaz de conviver, sem problemas, certo?
Bem, outra resposta no tópico ofereceu essa variação mais complexa:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
À primeira vista, você provavelmente pensaria que essa consulta é extremamente menos eficiente, pois requer duas verificações de índice clusterizado. Você definitivamente estaria certo sobre isso; aqui estão as métricas do plano e do tempo de execução em relação a uma tabela vazia:
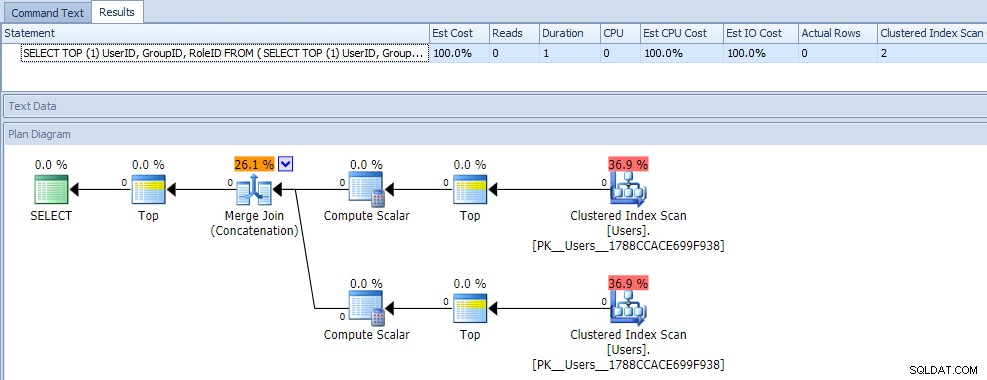
Mas agora, vamos adicionar dados
Para testar essas consultas, eu queria usar alguns dados realistas. Então, primeiro eu preenchi 1.000 linhas de sys.all_objects, com operações de módulo contra o object_id para obter uma distribuição decente:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Agora, quando executo as duas consultas, aqui estão as métricas de tempo de execução:

A versão UNION ALL vem com um pouco menos de E/S (4 leituras vs. 5), menor duração e menor custo geral estimado, enquanto a versão condicional ORDER BY tem menor custo estimado de CPU. Os dados aqui são muito pequenos para tirar conclusões; Eu só queria isso como uma estaca no chão. Agora, vamos alterar a distribuição para que a maioria das linhas atenda a pelo menos um dos critérios (e às vezes ambos):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Desta vez, a ordem condicional por tem os maiores custos estimados em CPU e E/S:

Mas, novamente, com esse tamanho de dados, há um impacto relativamente inconsequente na duração e nas leituras e, além dos custos estimados (que são amplamente compostos de qualquer maneira), é difícil declarar um vencedor aqui.
Então, vamos adicionar muito mais dados
Embora eu goste de construir dados de amostra a partir das visualizações do catálogo, já que todo mundo tem isso, desta vez vou desenhar na tabela Sales.SalesOrderHeader Ampliado de AdventureWorks2012, expandido usando este script de Jonathan Kehayias. No meu sistema, esta tabela tem 1.258.600 linhas. O script a seguir inserirá um milhão dessas linhas em nossa tabela dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
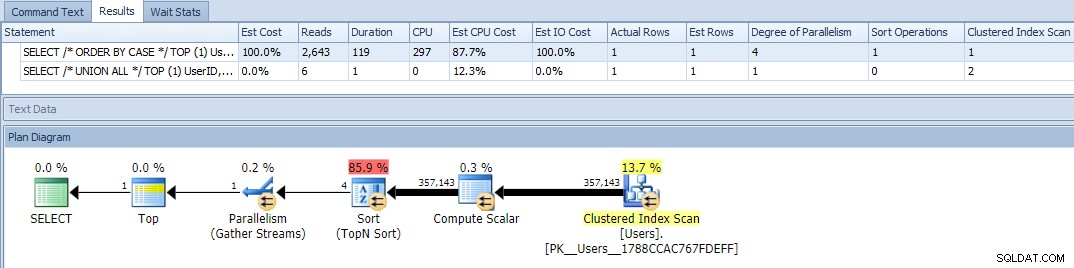
Ok, agora quando executamos as consultas, vemos um problema:a variação ORDER BY ficou paralela e obliterou as leituras e a CPU, gerando uma diferença de quase 120X na duração:
Eliminar o paralelismo (usando MAXDOP) não ajudou:
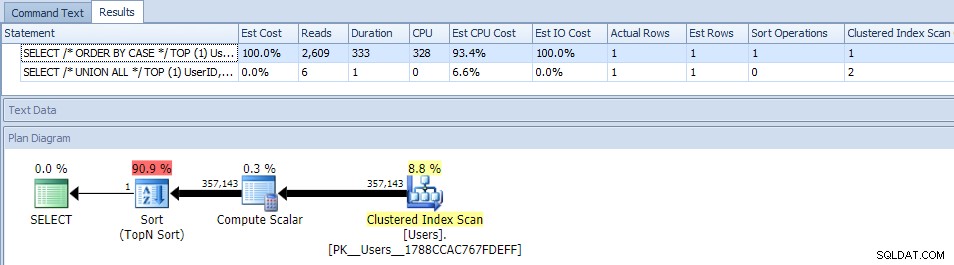
(O plano UNION ALL ainda parece o mesmo.)
E se alterarmos a inclinação para par, onde 95% das linhas atendem a pelo menos um critério:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
As consultas ainda mostram que o tipo é proibitivamente caro:

E com MAXDOP =1 foi muito pior (basta olhar a duração):

Por fim, como cerca de 95% de inclinação em qualquer direção (por exemplo, a maioria das linhas atende aos critérios GroupID ou a maioria das linhas atende aos critérios RoleID)? Este script garantirá que pelo menos 95% dos dados tenham GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Os resultados são bastante semelhantes (vou parar de tentar o MAXDOP de agora em diante):

E então, se inclinarmos para o outro lado, onde pelo menos 95% dos dados têm RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultados:

Conclusão
Em nenhum caso que eu pudesse fabricar, a consulta ORDER BY "mais simples" - mesmo com uma varredura de índice clusterizado a menos - superou a consulta UNION ALL mais complexa. Às vezes, você precisa ter muito cuidado com o que o SQL Server precisa fazer ao introduzir operações como classificações em sua semântica de consulta e não confiar apenas na simplicidade do plano (não importa qualquer preconceito que você possa ter com base em cenários anteriores).
Seu primeiro instinto pode muitas vezes estar correto, mas aposto que há momentos em que há uma opção melhor que parece, na superfície, que não poderia funcionar melhor. Como neste exemplo. Estou ficando um pouco melhor em questionar suposições que fiz a partir de observações e não fazer declarações gerais como "scans nunca funcionam bem" e "consultas mais simples sempre são mais rápidas". Se você eliminar as palavras nunca e sempre do seu vocabulário, você pode se ver colocando mais dessas suposições e declarações gerais à prova, e terminar muito melhor.



