O endereço IP virtual é um endereço IP que não corresponde a uma interface de rede física real. Ele flutua entre várias interfaces de rede e apenas uma interface ativa manterá o endereço IP para tolerância a falhas e mobilidade. O ClusterControl usa Keepalived para fornecer integração de endereço IP virtual com balanceadores de carga de banco de dados para eliminar qualquer ponto único de falha (SPOF) no nível do balanceador de carga.
Nesta postagem do blog, mostraremos como o ClusterControl configura o endereço IP virtual e o que você pode esperar quando ocorre failover ou failback. Compreender esse comportamento é vital para minimizar qualquer interrupção de serviço e facilitar as operações de manutenção que precisam ser realizadas ocasionalmente.
Requisitos
Existem alguns requisitos para executar o Keepalived em sua rede:
- O protocolo IP 112 (Virtual Router Redundancy Protocol - VRRP) deve ser suportado na rede. Algumas redes desabilitam o suporte para VRRP, especialmente comunicações entre VLANs. Verifique isso com o administrador da rede.
- Se você usa multicast, a rede deve suportar solicitação de multicast (use ip a | grep -i multicast). Caso contrário, você pode usar o unicast via unicast_src_ip e unicast_peer opções. O uso de multicast é útil quando você tem um ambiente dinâmico, como um ambiente de nuvem, ou quando a atribuição de IP é realizada por meio de DHCP.
- Um conjunto de instâncias de VRRP deve usar um virtual_router_id exclusivo valor, que não pode ser compartilhado entre outras instâncias. Caso contrário, você verá pacotes falsos e provavelmente interromperá a troca master-backup.
- Se você estiver executando em um ambiente de nuvem como AWS, provavelmente precisará usar um script externo (dica:use a opção "notificar") para dissociar e associar o endereço IP virtual (IP Elastic) para que seja reconhecido e roteável por o roteador.
Implantando Keepalived
Para instalar o Keepalived por meio do ClusterControl, você precisa de dois ou mais balanceadores de carga instalados ou importados para o ClusterControl. Para uso em produção, é altamente recomendável que o software do balanceador de carga seja executado em um host autônomo e não colocado junto aos nós do banco de dados.
Após ter pelo menos dois load balancers gerenciados pelo ClusterControl, para instalar o Keepalived e habilitar o endereço IP virtual, basta acessar ClusterControl -> escolher o cluster -> Manage -> Load Balancer -> Keepalived:
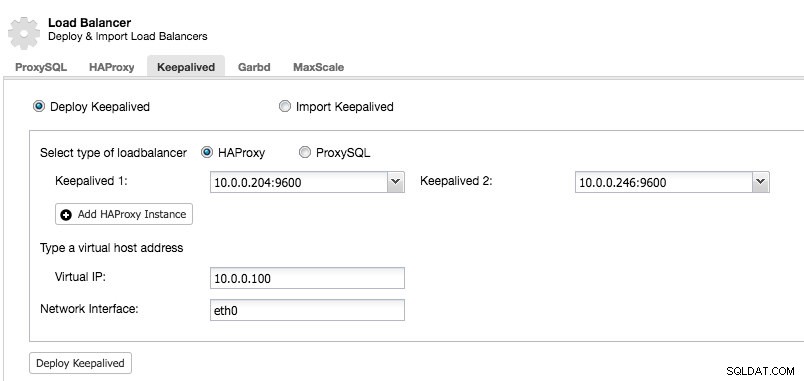
A maioria dos campos são autoexplicativos. Você pode implantar um novo conjunto de Keepalived ou importar instâncias Keepalived existentes. Os campos importantes incluem o endereço IP virtual real e a interface de rede onde o endereço IP virtual existirá. Se os hosts estiverem usando dois nomes de interface diferentes, especifique o nome da interface do host Keepalived 1 e modifique manualmente o arquivo de configuração no Keepalived 2 com um nome de interface correto posteriormente.
Instância VRRP
No momento em que escrevo, o ClusterControl v1.5.1 instala o Keepalived v1.3.5 (dependendo do sistema operacional do host) e o seguinte é o que está configurado para a instância VRRP:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl configura a instância VRRP para se comunicar por meio de unicast. Com unicast, devemos definir todos os peers unicast dos outros nós Keepalived. É menos dinâmico, mas funciona na maioria das vezes. Com multicast, você pode remover essas linhas (unicast_*) e confiar no endereço IP multicast para descoberta e emparelhamento de host. É mais simples, mas geralmente é bloqueado pelos administradores de rede.
A próxima parte é o endereço IP virtual. Você pode especificar vários endereços IP virtuais por instância VRRP, separados por uma nova linha. O balanceamento de carga no HAProxy/ProxySQL e Keepalived ao mesmo tempo também requer a capacidade de se associar a um endereço IP não local, o que significa que ele não está atribuído a um dispositivo no sistema local. Isso permite que uma instância do balanceador de carga em execução seja vinculada a um IP que não seja local para failover. Assim, o ClusterControl também configura net.ipv4.ip_nonlocal_bind=1 dentro de /etc/sysctl.conf.
A próxima diretiva é a track_script , onde você pode especificar o script para o processo de verificação de integridade que é explicado na próxima seção.
Verificações de integridade
O ClusterControl configura o Keepalived para realizar verificações de integridade examinando o código de erro retornado pelo track_script. No arquivo de configuração Keepalived, que por padrão está localizado em /etc/keepalived/keepalived.conf, você deve ver algo assim:
track_script {
chk_proxysql
}Onde ele chama chk_proxysql que contém:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}O comando "killall -0" retorna o código de saída 0 se houver um processo chamado "proxysql" em execução no host. Caso contrário, a instância teria que se rebaixar e iniciar o failover conforme explicado na próxima seção. Observe que o Keepalived também oferece suporte a componentes do Linux Virtual Server (LVS) para realizar verificações de integridade, onde também é capaz de balancear a carga de conexões TCP/IP, semelhante ao HAProxy, mas isso está fora do escopo desta postagem de blog.
Simulando failover
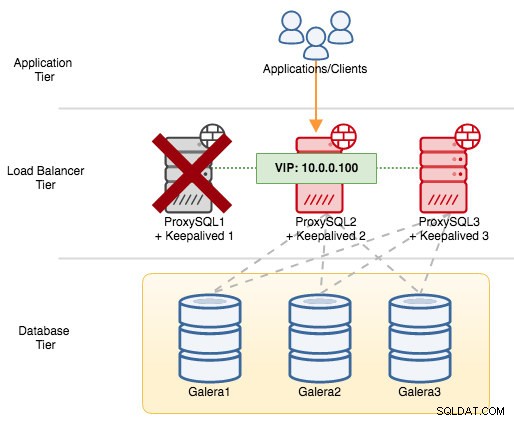
Para componentes VRRP, Keepalived usa o protocolo VRRP (protocolo IP 112) para se comunicar entre instâncias VRRP. O valor de prioridade mais alto de um MASTER significa que o mestre sempre terá o privilégio mais alto para manter o endereço IP virtual, a menos que você configure a instância com "nopreempt". Vamos usar um exemplo para explicar melhor o fluxo de failover e failback. Considere o seguinte diagrama:
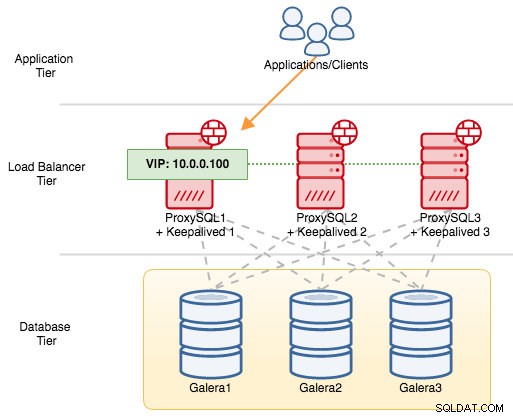
Existem três instâncias do ProxySQL na frente de três nós do MySQL Galera. Cada host ProxySQL é configurado com Keepalived como MASTER com o seguinte número de prioridade:
- ProxySQL1 - prioridade 101
- ProxySQL2 - prioridade 100
- ProxySQL3 - prioridade 99
Quando o Keepalived é iniciado como MASTER, ele primeiro anuncia o número de prioridade para os membros e depois se associa ao endereço IP virtual. Ao contrário da instância BACKUP, ela apenas observará o anúncio e só atribuirá o endereço IP virtual depois de confirmar que pode se elevar a um MASTER.
Observe que, se você matar o processo "proxysql" ou "haproxy" manualmente por meio do comando kill, o gerenciador de processos do systemd, por padrão, tentará recuperar o processo que está sendo interrompido de maneira desajeitada. Além disso, se você tiver a recuperação automática do ClusterControl ativada, o ClusterControl sempre tentará iniciar o processo mesmo se você executar um desligamento limpo via systemd (systemctl stop proxysql). Para melhor simular a falha, sugerimos que o usuário desative o recurso de recuperação automática do ClusterControl ou simplesmente desligue o servidor ProxySQL para interromper a comunicação.
Se desligarmos o ProxySQL1, o endereço IP virtual passará por failover para o próximo host com maior prioridade naquele momento específico (que é o ProxySQL2):
Você veria o seguinte no syslog do nó com falha:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Enquanto no nó secundário, aconteceu o seguinte:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.Nesse caso, o failover levou cerca de 3 segundos, com o tempo máximo de failover seria intervalo + advert_int . Nos bastidores, o endpoint do banco de dados mudou e o tráfego do banco de dados está sendo roteado pelo ProxySQL2 sem que os aplicativos percebam.
Quando o ProxySQL1 voltar a ficar online, ele forçará uma nova eleição MASTER e assumirá o endereço IP devido à prioridade mais alta:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Ao mesmo tempo, o ProxySQL2 se rebaixa ao estado BACKUP e remove o endereço IP virtual da interface de rede:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.Nesse ponto, o ProxySQL1 está novamente online e se torna o balanceador de carga ativo que atende às conexões de aplicativos e clientes. O VRRP normalmente irá antecipar um servidor de prioridade mais baixa quando um servidor de prioridade mais alta ficar online. Se você quiser que o endereço IP permaneça no ProxySQL2 depois que o ProxySQL1 ficar online, use a opção "nopreempt". Isso permite que a máquina de prioridade mais baixa mantenha a função de mestre, mesmo quando uma máquina de prioridade mais alta voltar a ficar online. No entanto, para que isso funcione, o estado inicial dessa entrada deve ser BACKUP. Caso contrário, você notará a seguinte linha:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERComo por padrão o ClusterControl configura todos os nós como MASTER, você deve configurar a seguinte opção de configuração para a respectiva instância VRRP de acordo:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Reinicie o processo Keepalived para carregar essas alterações. O endereço IP virtual só terá failover para ProxySQL1 ou ProxySQL3 (dependendo da prioridade e de qual nó está disponível naquele momento) se a verificação de integridade falhar no ProxySQL2. Em muitos casos, executar o Keepalived em dois hosts será suficiente.