Usar o cluster Galera é uma ótima maneira de construir um ambiente altamente disponível para MySQL ou MariaDB. É um ambiente de cluster sem compartilhamento que pode ser dimensionado além de 12 a 15 nós. Galera tem algumas limitações, no entanto. Ele brilha em ambientes de baixa latência e, embora possa ser usado em WAN, o desempenho é limitado pela latência da rede. O desempenho do Galera também pode ser afetado se um dos nós começar a se comportar incorretamente. Por exemplo, a carga excessiva em um dos nós pode torná-lo mais lento, resultando em uma manipulação mais lenta das gravações e isso afetará todos os outros nós do cluster. Por outro lado, é praticamente impossível administrar um negócio sem analisar seus dados. Essa análise, normalmente, requer a execução de consultas pesadas, o que é bem diferente de uma carga de trabalho OLTP. Nesta postagem do blog, discutiremos uma maneira fácil de executar consultas analíticas para dados armazenados no Galera Cluster for MySQL ou MariaDB, de forma que não afete o desempenho do cluster principal.
Como executar consultas analíticas no Galera Cluster?
Como dissemos, executar consultas de longa duração diretamente em um cluster Galera é factível, mas talvez não seja uma boa ideia. Dependente de hardware, isso pode ser uma solução aceitável (se você usar um hardware forte e não executar uma carga de trabalho analítica multithread), mas mesmo que a utilização da CPU não seja um problema, o fato de um dos nós ter uma carga de trabalho mista ( OLTP e OLAP) por si só apresentarão alguns desafios de desempenho. As consultas OLAP removerão os dados necessários para sua carga de trabalho OLTP do pool de buffers, e isso tornará suas consultas OLTP mais lentas. Felizmente, existe uma maneira simples e eficiente de separar a carga de trabalho analítica das consultas regulares - um escravo de replicação assíncrona.
O escravo de replicação é uma solução muito simples - tudo que você precisa é apenas outro host que pode ser provisionado e a replicação assíncrona deve ser configurada do Galera Cluster para esse nó. Com a replicação assíncrona, o escravo não afetará o restante do cluster de forma alguma. Não importa se ele está muito carregado, usa hardware diferente (menos poderoso), ele apenas continuará a replicar a partir do cluster principal. O pior cenário é que o escravo de replicação começará a ficar para trás, mas cabe a você implementar a replicação multi-thread ou, eventualmente, aumentar o tamanho do escravo de replicação.
Assim que o escravo de replicação estiver funcionando, você deve executar as consultas mais pesadas nele e descarregar o cluster Galera. Isso pode ser feito de várias maneiras, dependendo da configuração e do ambiente. Se você usar o ProxySQL, poderá direcionar facilmente as consultas para o escravo analítico com base no host de origem, usuário, esquema ou até mesmo na própria consulta. Caso contrário, caberá ao seu aplicativo enviar consultas analíticas para o host correto.
Configurar um slave de replicação não é muito complexo, mas ainda pode ser complicado se você não for proficiente com MySQL e ferramentas como xtrabackup. Todo o processo consistiria em configurar o repositório em um novo servidor e instalar o banco de dados MySQL. Em seguida, você terá que provisionar esse host usando dados do cluster Galera. Você pode usar o xtrabackup para isso, mas outras ferramentas como mydumper/myloader ou mesmo mysqldump também funcionarão (desde que você as execute corretamente). Uma vez que os dados estejam lá, você terá que configurar a replicação entre um nó mestre Galera e o escravo de replicação. Finalmente, você teria que reconfigurar sua camada de proxy para incluir o novo escravo e rotear o tráfego para ele ou fazer ajustes em como seu aplicativo se conecta ao banco de dados para redirecionar parte da carga para o escravo de replicação.
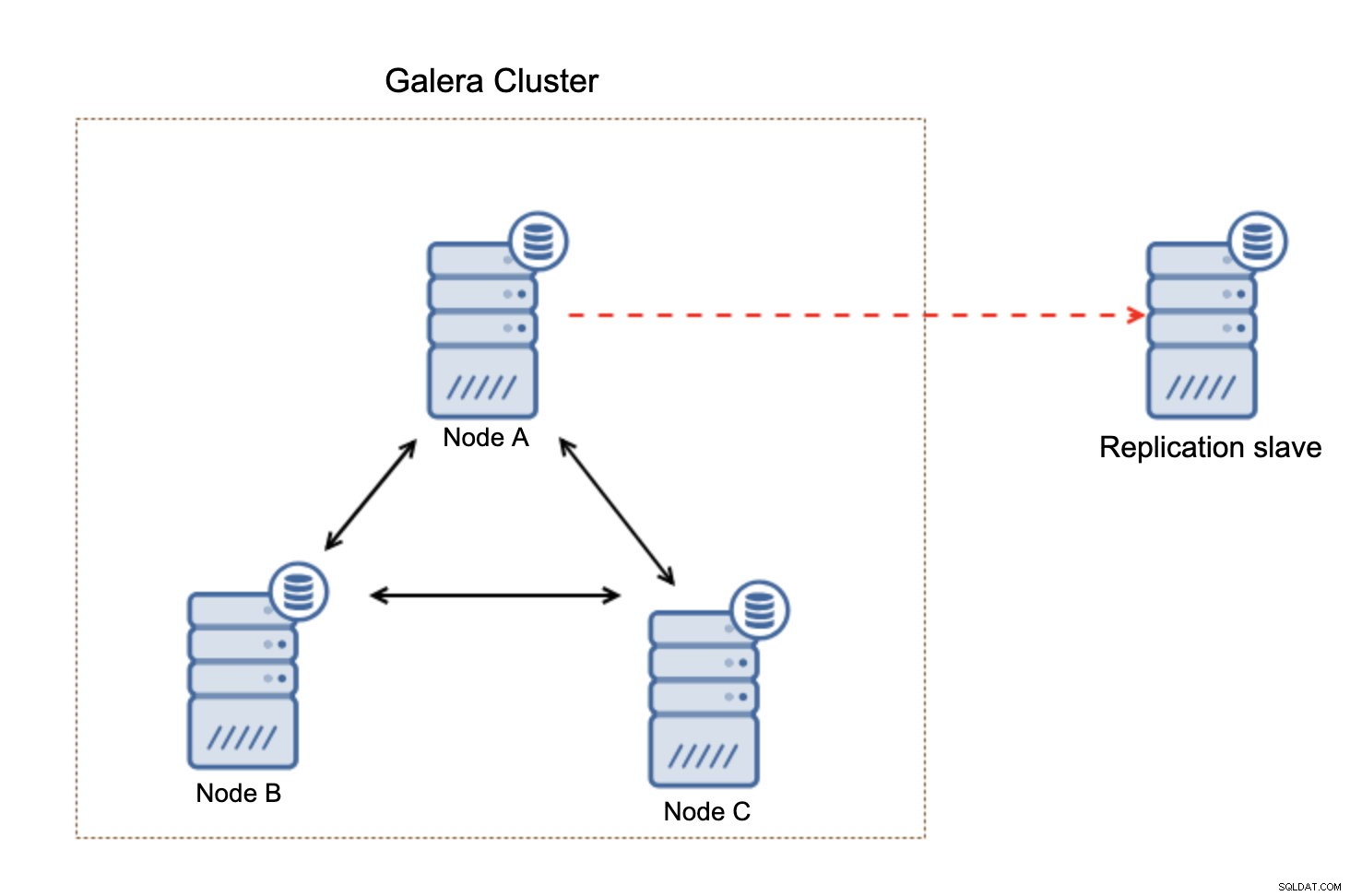
O que é importante ter em mente, essa configuração não é resiliente. Se o nó "mestre" do Galera ficar inativo, o link de replicação será quebrado e será executada uma ação manual para escravizar a réplica de outro nó mestre no cluster do Galera.
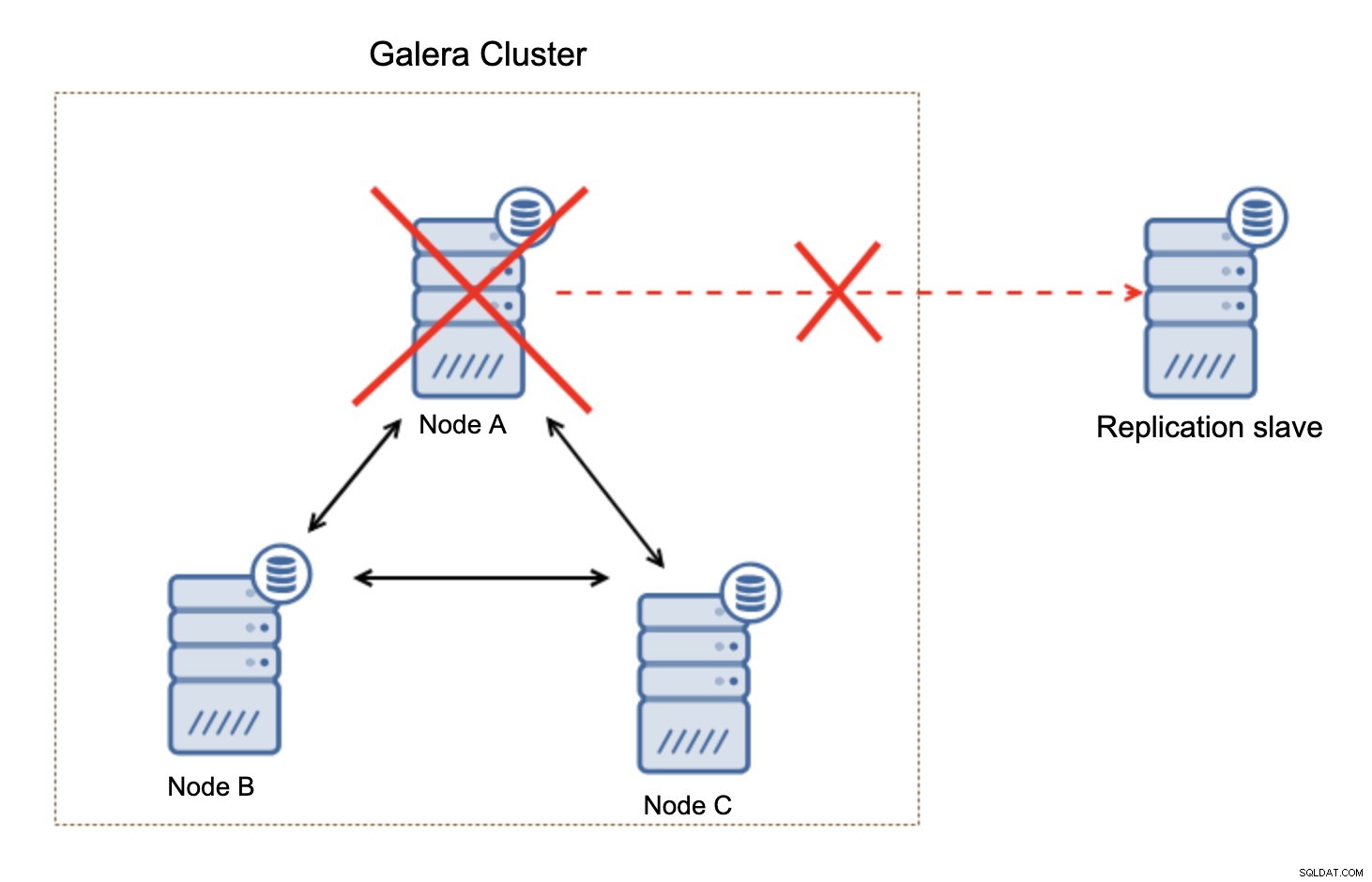
Isso não é grande coisa, especialmente se você usa a replicação com GTID (Global Transaction ID), mas precisa identificar que a replicação está quebrada e, em seguida, executar a ação manual.
Como configurar o escravo assíncrono do Galera Cluster usando o ClusterControl?
Felizmente, se você usar o ClusterControl, todo o processo pode ser automatizado e requer apenas alguns cliques. O estado inicial já foi configurado usando ClusterControl - um cluster Galera de 3 nós com 2 nós ProxySQL e 2 nós Keepalived para alta disponibilidade do banco de dados e da camada proxy.
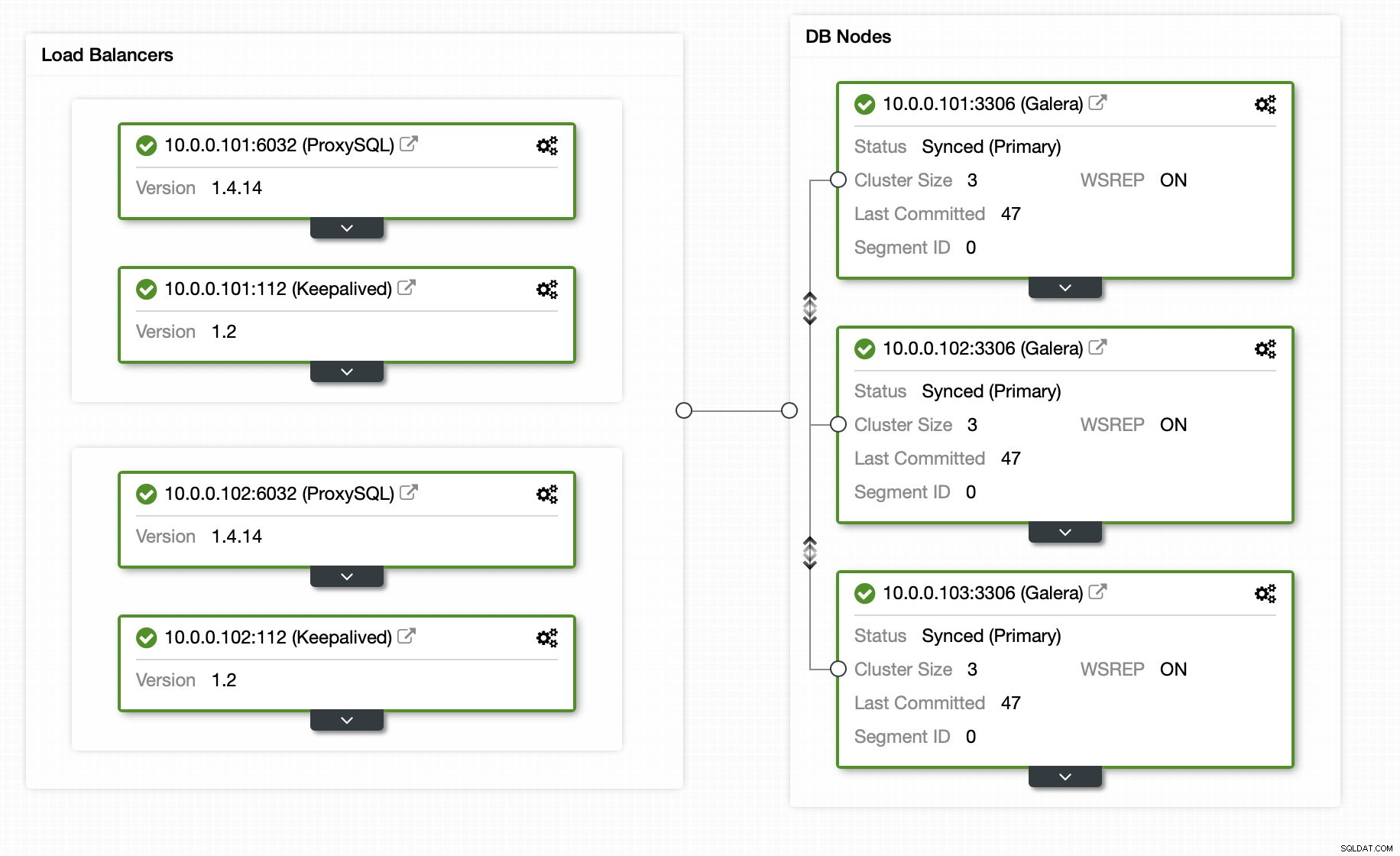
Adicionar o escravo de replicação está a apenas um clique de distância:
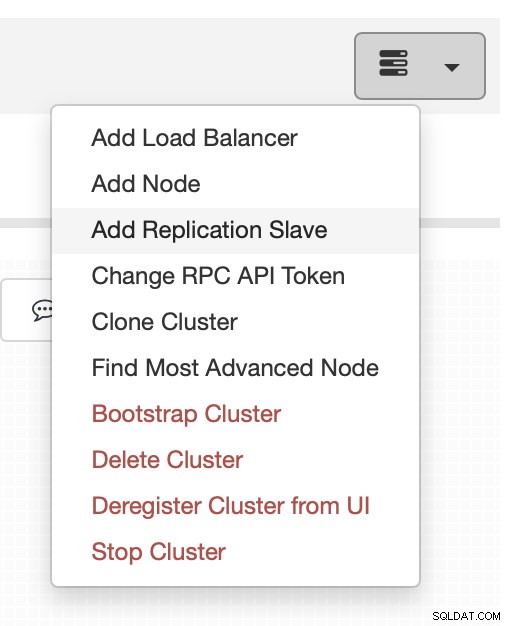
A replicação, obviamente, requer que os logs binários sejam habilitados. Se você não tiver logs binários habilitados em seus nós Galera, também poderá fazê-lo a partir do ClusterControl. Lembre-se de que a ativação de logs binários exigirá uma reinicialização do nó para aplicar as alterações de configuração.
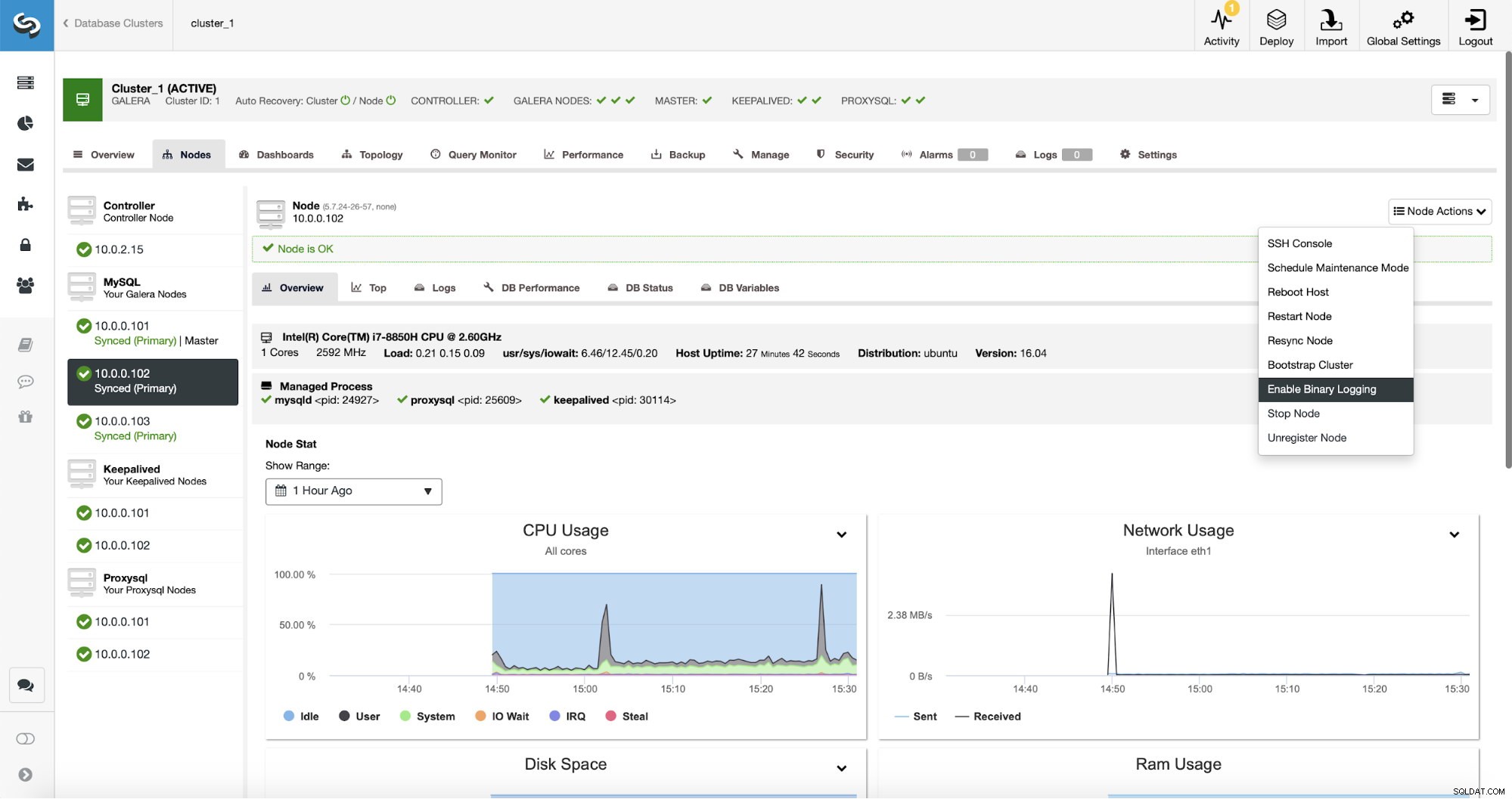
Mesmo que um nó no cluster tenha logs binários habilitados (marcados como "Mestre" na captura de tela acima), ainda é bom habilitar o log binário em pelo menos mais um nó. O ClusterControl pode fazer o failover automaticamente do slave de replicação depois de detectar que o nó mestre Galera travou, mas para isso, é necessário outro nó mestre com logs binários habilitados ou não terá nada para fazer o failover.
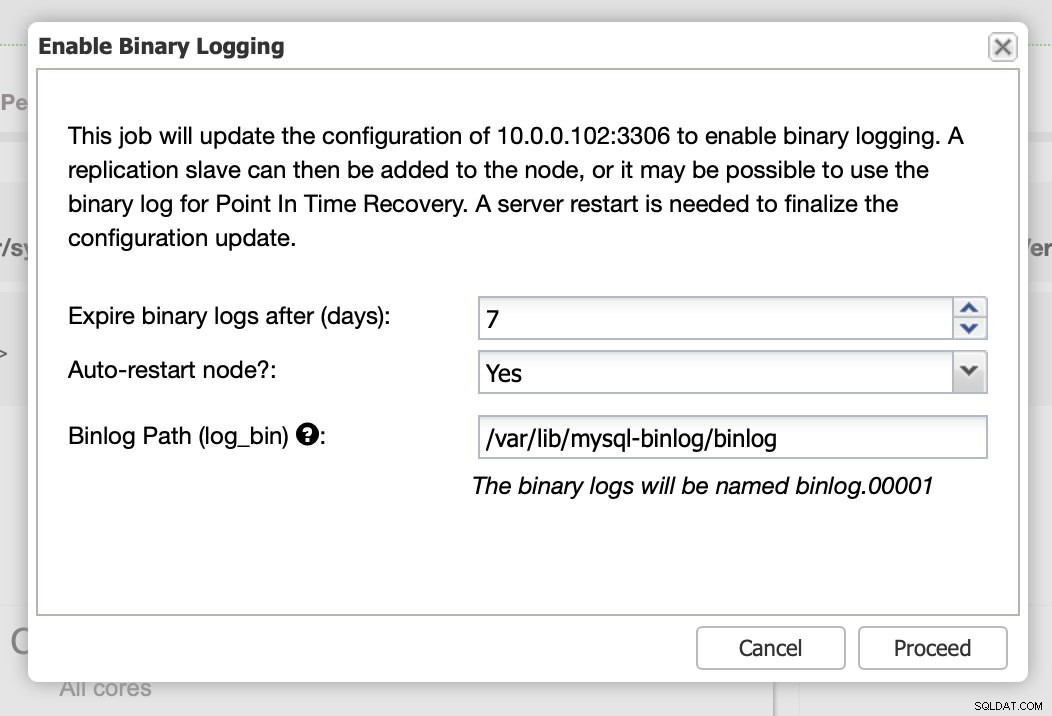
Como afirmamos, habilitar logs binários requer reinicialização. Você pode realizá-lo imediatamente ou apenas fazer as alterações de configuração e reiniciar em outro momento.
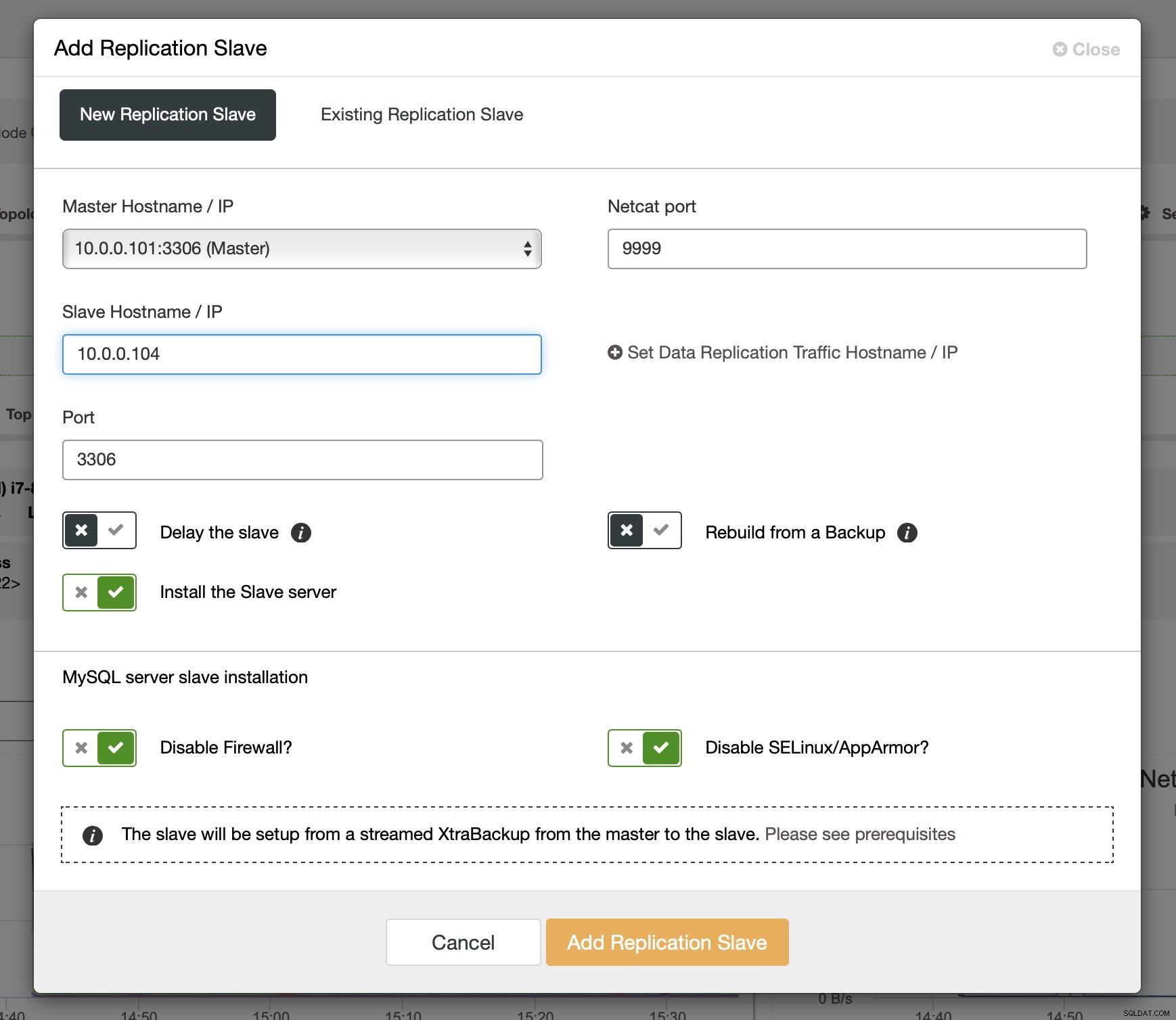
Após os logs binários terem sido habilitados em alguns nós do Galera, você pode continuar adicionando o escravo de replicação. Na caixa de diálogo você deve escolher o host mestre, passar o nome do host ou o endereço IP do escravo. Se você tiver backups recentes em mãos (o que você deve fazer), você pode usar um para provisionar o escravo. Caso contrário, o ClusterControl irá provisioná-lo usando xtrabackup - todos os dados mestres recentes serão transmitidos para o escravo e, em seguida, a replicação será configurada.
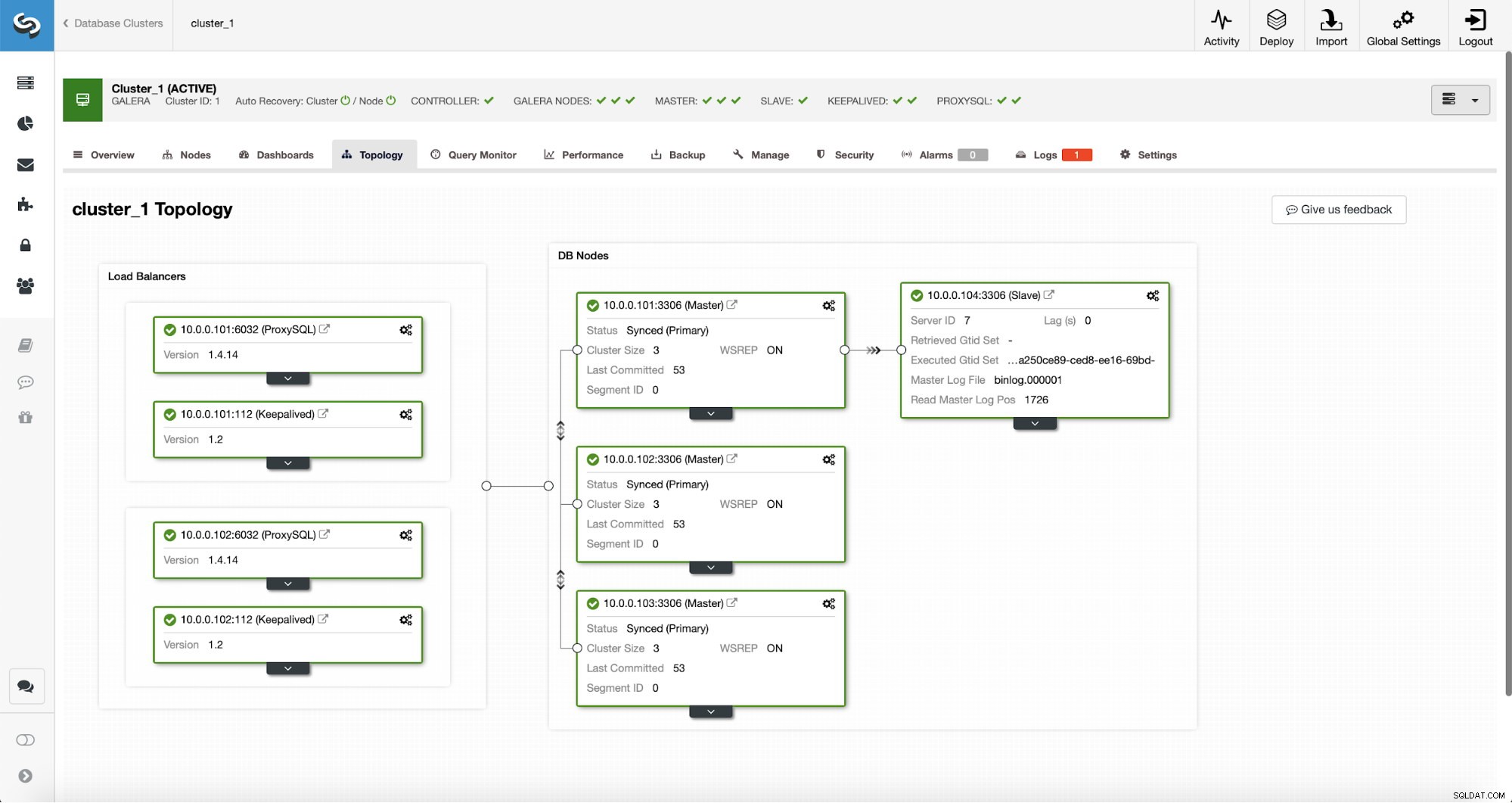
Após a conclusão do trabalho, um escravo de replicação foi adicionado ao cluster. Como dito anteriormente, se o 10.0.0.101 morrer, outro host no cluster Galera será escolhido como o mestre e o ClusterControl automaticamente escravizará o 10.0.0.104 de outro nó.
Como usamos o ProxySQL, precisamos configurá-lo. Adicionaremos um novo servidor ao ProxySQL.
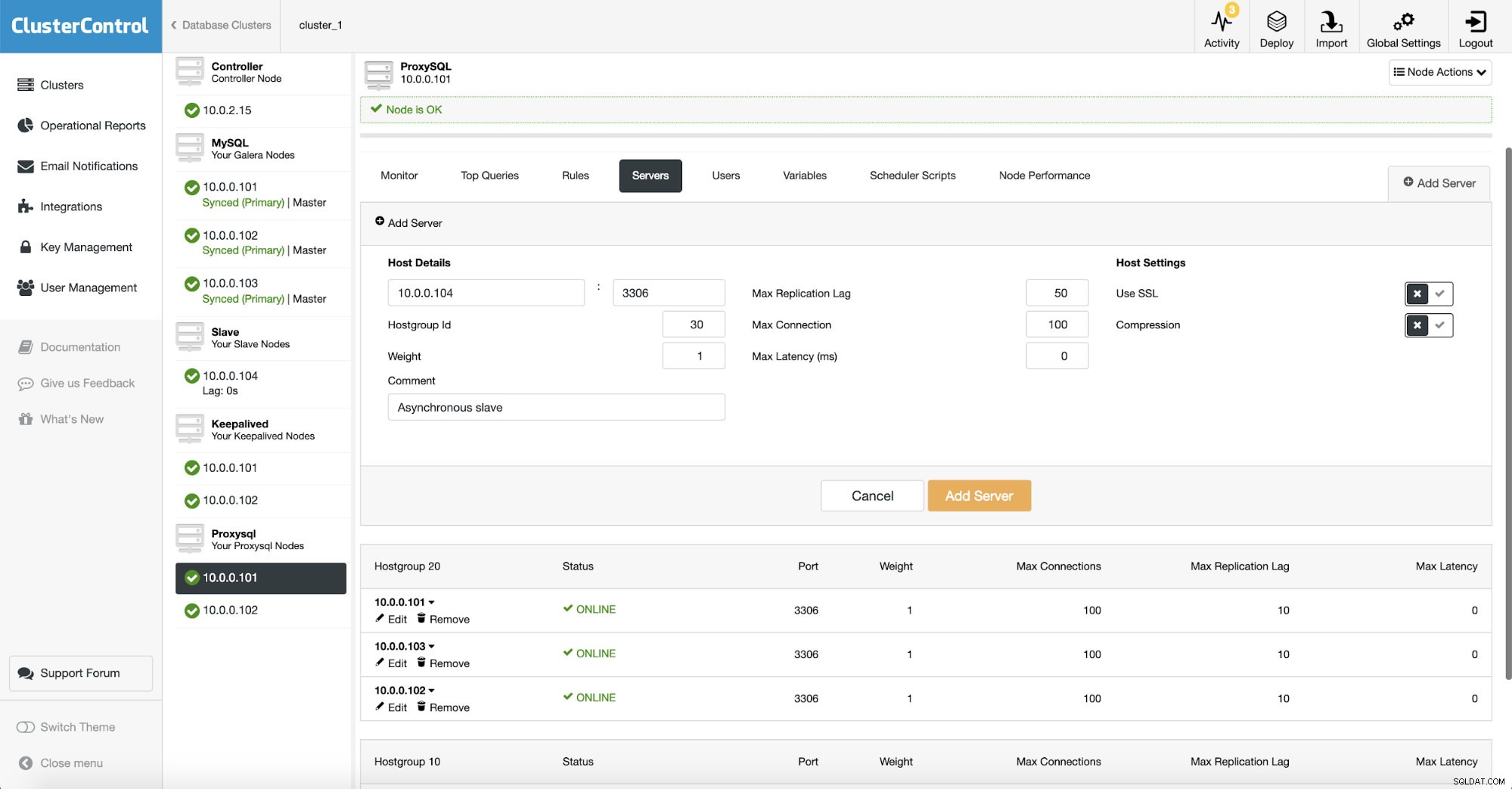
Criamos outro hostgroup (30) onde colocamos nosso slave assíncrono. Também aumentamos o “Max Replication Lag” para 50 segundos do padrão 10. Depende de seus requisitos de negócios o quanto o escravo de análise pode estar atrasado antes de se tornar um problema.
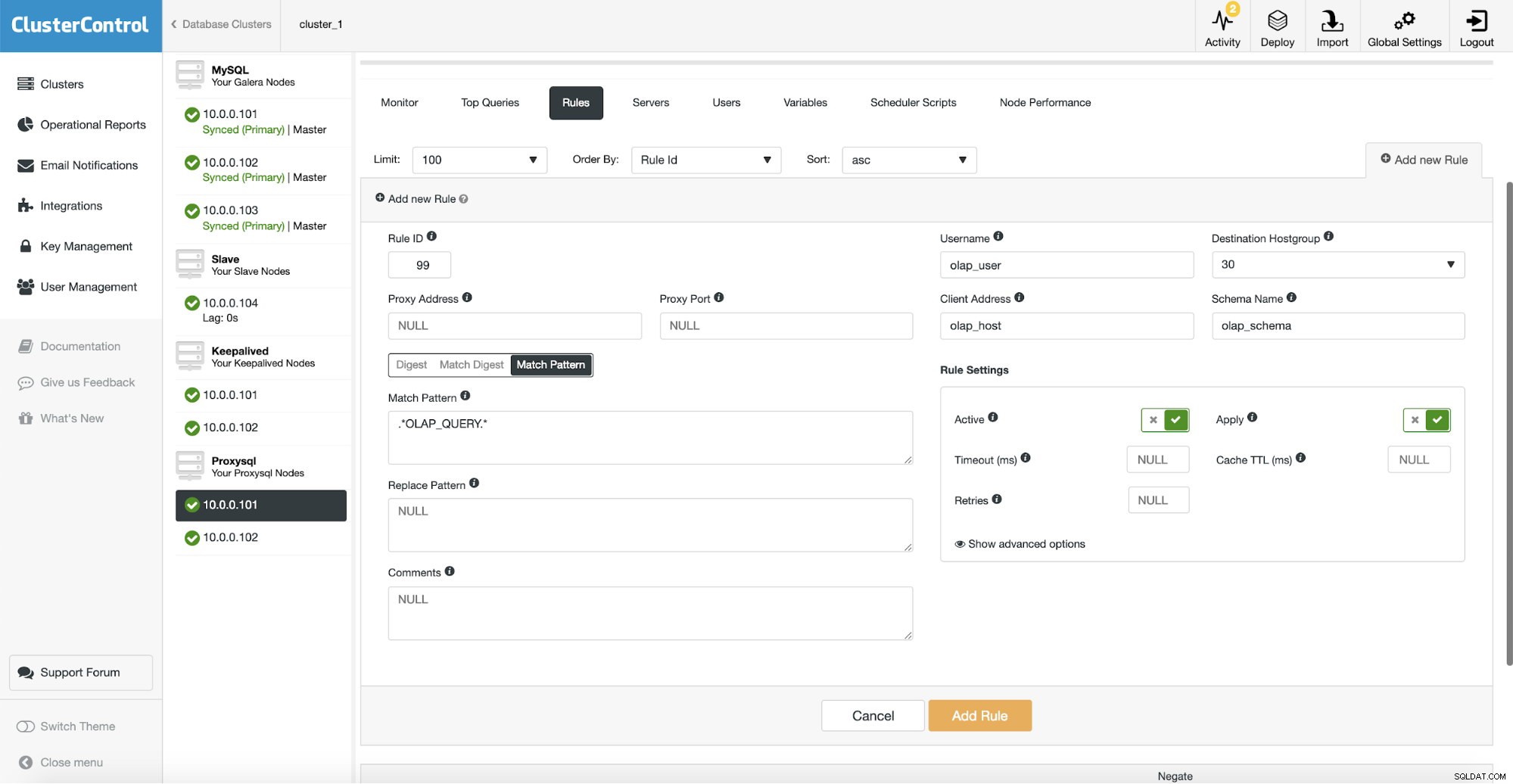
Depois disso, temos que configurar uma regra de consulta que corresponda ao nosso tráfego OLAP e encaminhá-lo para o hostgroup OLAP (30). Na captura de tela acima, preenchemos vários campos - isso não é obrigatório. Normalmente você precisará usar um, dois deles no máximo. A captura de tela acima serve como um exemplo para que possamos ver facilmente que você pode combinar consultas usando esquema (se tiver um esquema separado com dados analíticos), nome do host/IP (se as consultas OLAP forem executadas de algum host específico), usuário (se o aplicativo usar Você também pode combinar consultas diretamente passando uma consulta completa ou marcando-as com comentários SQL e permitindo que o ProxySQL encaminhe todas as consultas com uma string “OLAP_QUERY” para nosso grupo de hosts analíticos.
Como você pode ver, graças ao ClusterControl, conseguimos implantar um escravo de replicação no Galera Cluster em apenas alguns cliques. Alguns podem argumentar que o MySQL não é o banco de dados mais adequado para carga de trabalho analítica e tendemos a concordar. Você pode facilmente estender essa configuração usando o ClickHouse e configurando uma replicação do escravo assíncrono para o armazenamento de dados colunar do ClickHouse para um desempenho muito melhor das consultas analíticas. Descrevemos essa configuração em uma das postagens anteriores do blog.