Você está trabalhando com um desenvolvedor que está relatando um desempenho lento para a seguinte chamada de procedimento armazenado:
EXEC [dbo].[charge_by_date] '2/28/2013';
Você pergunta qual problema o desenvolvedor está vendo, mas a única informação adicional que você ouve de volta é que ele está "rodando lentamente". Então você salta para a instância do SQL Server e dá uma olhada no real plano de execução. Você faz isso porque está interessado não apenas na aparência do plano de execução, mas também no número estimado versus o número real de linhas para o plano:
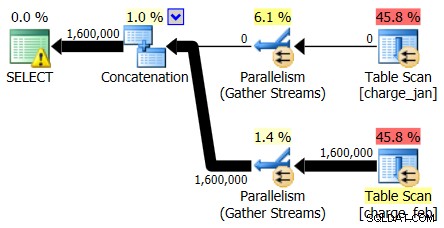
Olhando primeiro apenas para as operadoras de planos, você pode ver alguns detalhes dignos de nota:
- Há um aviso no operador raiz
- Há uma verificação de tabela para ambas as tabelas referenciadas no nível folha (charge_jan e charge_feb) e você se pergunta por que ambas ainda são heaps e não têm índices clusterizados
- Você vê que há apenas linhas passando pela tabela charge_feb e não pela tabela charge_jan
- Você vê zonas paralelas no plano
Quanto ao aviso no iterador raiz, você passa o mouse sobre ele e vê que há avisos de índice ausentes com uma recomendação para os seguintes índices:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Você pergunta ao desenvolvedor do banco de dados original por que não há um índice clusterizado e a resposta é "Não sei".
Continuando a investigação antes de fazer qualquer alteração, você olha para a guia Plan Tree no SQL Sentry Plan Explorer e realmente vê que há desvios significativos entre as linhas estimadas e reais para uma das tabelas:

Parece haver dois problemas:
- Uma subestimativa para linhas na verificação da tabela charge_jan
- Uma superestimativa de linhas na verificação da tabela charge_feb
Portanto, as estimativas de cardinalidade são distorcido, e você se pergunta se isso está relacionado ao sniffing de parâmetros. Você decide verificar o valor compilado do parâmetro e compará-lo com o valor do tempo de execução do parâmetro, que você pode ver na guia Parâmetros:

Na verdade, existem diferenças entre o valor de tempo de execução e o valor compilado. Você copia o banco de dados para um ambiente de teste do tipo prod e, em seguida, testa a execução do procedimento armazenado com o valor de tempo de execução de 28/02/2013 primeiro e depois 31/01/2013.
Os planos de 28/02/2013 e 31/01/2013 têm formas idênticas, mas fluxos de dados reais diferentes. O plano de 28/02/2013 e as estimativas de cardinalidade foram os seguintes:
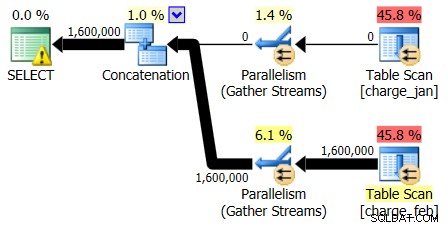

E enquanto o plano de 28/02/2013 não mostra nenhum problema de estimativa de cardinalidade, o plano de 31/01/2013:
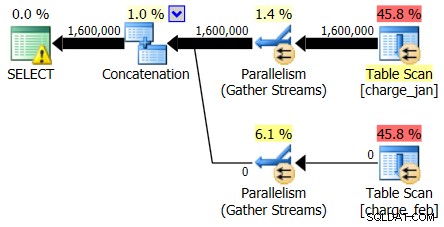

Portanto, o segundo plano mostra as mesmas estimativas acima e abaixo, apenas revertidas do plano original que você olhou.
Você decide adicionar os índices sugeridos ao ambiente de teste do tipo prod para as tabelas charge_jan e charge_feb e ver se isso ajuda. Executando os procedimentos armazenados na ordem de janeiro/fevereiro, você vê as seguintes novas formas de plano e estimativas de cardinalidade associadas:
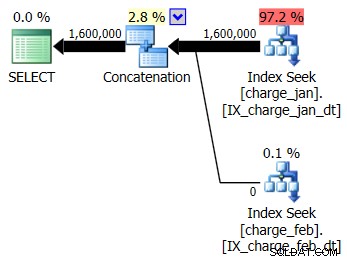

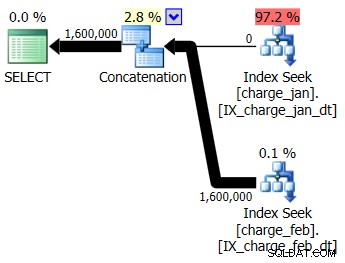

O novo plano usa uma operação Index Seek de cada tabela, mas você ainda vê zero linhas fluindo de uma tabela e não da outra, e ainda vê desvios de estimativa de cardinalidade com base na detecção de parâmetros quando o valor do tempo de execução está em um mês diferente da compilação valor do tempo.
Sua equipe tem uma política de não adicionar índices sem comprovação de benefício suficiente e testes de regressão associados. Você decide, por enquanto, remover os índices não clusterizados que acabou de criar. Embora você não resolva imediatamente o clustered ausente index, você decide que cuidará disso mais tarde.
Neste ponto, você percebe que precisa analisar mais a definição do procedimento armazenado, que é o seguinte:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Em seguida, você observa a definição do objeto charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
A exibição faz referência a dados de cobrança separados em diferentes tabelas por data. E então você se pergunta se a segunda distorção do plano de execução da consulta pode ser evitada alterando a definição do procedimento armazenado.
Talvez se o otimizador souber em tempo de execução qual é o valor, o problema da estimativa de cardinalidade desaparecerá e melhorará o desempenho geral?
Você vai em frente e redefine a chamada do procedimento armazenado da seguinte forma, adicionando uma dica RECOMPILE (sabe que você também ouviu que isso pode aumentar o uso da CPU, mas como este é um ambiente de teste, você se sente seguro em tentar):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Em seguida, execute novamente o procedimento armazenado usando o valor de 31/01/2013 e, em seguida, o valor de 28/02/2013.
A forma do plano permanece a mesma, mas agora o problema de estimativa de cardinalidade foi removido.
Os dados da estimativa de cardinalidade de 31/01/2013 mostram:

E os dados da estimativa de cardinalidade de 28/02/2013 mostram:

Isso deixa você feliz por um momento, mas depois percebe que a duração da execução geral da consulta parece relativamente a mesma de antes. Você começa a ter dúvidas de que o desenvolvedor ficará feliz com seus resultados. Você resolveu a distorção da estimativa de cardinalidade, mas sem o aumento de desempenho esperado, não tem certeza se ajudou de alguma forma significativa.
É nesse ponto que você percebe que o plano de execução da consulta é apenas um subconjunto das informações de que pode precisar e, portanto, expande ainda mais sua exploração examinando a guia Table I/O. Você vê a seguinte saída para a execução de 31/01/2013:

E para a execução de 28/02/2013 você vê dados semelhantes:

É nesse ponto que você se pergunta se as operações de acesso a dados para ambos tabelas são necessárias em cada plano. Se o otimizador sabe que você só precisa de linhas de janeiro, por que acessar fevereiro e vice-versa? Você também se lembra de que o otimizador de consultas não tem garantias de que não haja linhas reais dos outros meses na tabela "errada", a menos que tais garantias tenham sido feitas explicitamente por meio de restrições na própria tabela.
Você verifica as definições de tabela por meio de sp_help para cada tabela e não vê nenhuma restrição definida para nenhuma tabela.
Então, como teste, você adiciona as duas restrições a seguir:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Você reexecuta os procedimentos armazenados e vê as seguintes formas de plano e estimativas de cardinalidade.
Execução em 31/01/2013:
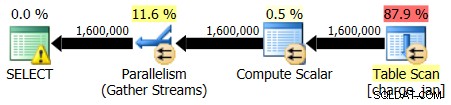

Execução em 28/02/2013:


Observando a Tabela I/O novamente, você vê a seguinte saída para a execução de 31/01/2013:

E para a execução de 28/02/2013 você vê dados semelhantes, mas para a tabela charge_feb:

Lembrando que você ainda tem o RECOMPILE na definição do procedimento armazenado, tente removê-lo e veja se vê o mesmo efeito. Depois de fazer isso, você verá o retorno de acesso de duas tabelas, mas sem leituras lógicas reais para a tabela que não possui linhas (em comparação com o plano original sem as restrições). Por exemplo, a execução de 31/01/2013 mostrou a seguinte saída de E/S da Tabela:

Você decide avançar com o teste de carga das novas restrições CHECK e solução RECOMPILE, removendo o acesso à tabela inteiramente do plano (e dos operadores de plano associados). Você também se prepara para um debate sobre a chave de índice clusterizado e um índice não clusterizado de suporte adequado que acomodará um conjunto mais amplo de cargas de trabalho que atualmente acessam as tabelas associadas.