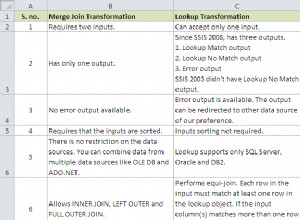
Quando os servidores estão inativos, isso pode causar interrupções em seus objetivos de negócios e resultar em perda de receita. Por exemplo, uma companhia aérea pode não conseguir reservar voos para clientes se instâncias e bancos de dados não estiverem disponíveis. Os sistemas podem falhar por vários motivos, como incêndio, erros humanos, falhas de computador, falhas de disco e erros de programação.
Para evitar interrupções e garantir que haja continuidade nos serviços de negócios, é extremamente importante ter estratégias de alta disponibilidade (HA) e recuperação de desastres (DR) implementadas. HA e DR são frequentemente discutidos juntos. A HA está preocupada em reduzir ao máximo o tempo de inatividade do servidor, mas como nenhum sistema é perfeito, a DR se concentra no processo de usar a mídia de backup para recuperar dados perdidos no caso de o sistema de banco de dados ficar inativo.
AlwaysOn é um termo de marca/marketing usado desde o SQL Server 2012 para descrever os recursos aprimorados de HADR da Microsoft. Antes do AlwaysOn, o mecanismo de banco de dados dava suporte a outras soluções proprietárias integradas, como espelhamento de banco de dados, cluster de failover e envio de logs. No entanto, cada uma dessas técnicas veio com benefícios e limitações. Muitas vezes, dependendo de seus objetivos, uma organização teve que combinar vários métodos para alcançar uma estratégia HADR desejável.
Os recursos AlwaysOn foram introduzidos para que você não precise lidar com tempo e recursos extras para implementar e introduzir complexidade na implantação para levar em conta a redundância do servidor e do banco de dados, ter problemas de dimensionamento ou ter hardware em espera que não está sendo usado com eficiência. Esses recursos combinam convenientemente muitas das práticas antigas e melhoram as áreas onde ficaram aquém. Para realmente entender o valor das ofertas AlwaysOn, é importante revisitar os conceitos básicos iniciais de como o mecanismo de banco de dados garantiu o HADR do sistema no passado.
Espelhamento de banco de dados
A redundância do banco de dados pode ser realizada por meio de espelhamento. Por exemplo, você pode ter um aplicativo cliente de front-end gerador de receita que permite que os alunos encomendem livros didáticos on-line. Um cliente seleciona sua compra e as solicitações são feitas no banco de dados PsychologyBooks no back-end. No caso de um desastre que torne o banco de dados PsychologyBooks indisponível, o aluno não poderá concluir seu pedido.
Para evitar essa interrupção, você pode ter uma instância principal implantada em produção que contém o banco de dados PsychologyBooks e ter uma cópia extra desse banco de dados PsychologyBooks em um servidor espelhado em espera. Os aplicativos cliente podem se reconectar à cópia espelhada em vez de sofrer interrupção e ter que aguardar a conclusão da recuperação no primário. A cópia acompanha as alterações feitas no original recebendo logs de transações e refazendo as alterações registradas.
As sessões de espelhamento podem operar em diferentes modos, dependendo do desempenho ou das justificativas de alta segurança. Convenientemente, o failover automático é suportado quando a sessão de espelhamento é operada no modo síncrono de alta segurança e o consenso de quorum é estabelecido com a presença de um servidor testemunha opcional.
Apesar dos benefícios do espelhamento, ele fica aquém porque fornece apenas redundância de banco de dados, não redundância de servidor. Isso significa que se a instância do servidor primário ficar inativa, ambas as instâncias ficarão inativas e não importará que haja uma cópia sobressalente dos dados no nível do banco de dados. O modo de espera não oferece suporte a operações do usuário e seriam necessários instantâneos para obter uma cópia somente leitura dos dados na instância espelhada. O banco de dados é protegido, mas os objetos de nível de servidor, como associação de função de servidor, informações de logon e trabalhos de agente, não.
Por exemplo, se houvesse uma grande equipe de marketing e cada membro tivesse seu próprio login, eles teriam que passar pelo processo de recriar logins para cada pessoa novamente. Quando o failover ocorre, é com base em um banco de dados independente e não como um grupo.
Agrupamento de failover
O clustering de failover oferece redundância no nível da instância e oferece proteção contra falhas de hardware e sistema operacional. Por exemplo, digamos que um nó em Queen Anne pegue fogo, causando uma falha no equipamento. A instância inteira — que inclui objetos em nível de instância, como logins ou trabalhos específicos que foram criados para realizar tarefas específicas — será protegida e poderá reiniciar automaticamente em outro nó pertencente ao cluster. Os aplicativos e serviços do cliente continuarão disponíveis para os clientes.
O cenário acima funciona porque o armazenamento é compartilhado entre servidores físicos redundantes em um grupo de cluster de failover do Windows Server (WSFC). Tanto o SO quanto o SQL Server trabalham juntos para que apenas um nó possua o grupo de recursos WSFC por vez.
Infelizmente, com um armazenamento comum, esta solução não fornece a redundância de banco de dados que a estratégia de espelhamento anterior oferecia. Ter um armazenamento compartilhado apresenta risco porque resulta em um único ponto de falha. Por exemplo, os discos externos podem conter a única cópia do importante banco de dados PsychologyBooks e, apesar de a instância ter feito failover com sucesso para o nó Ballard, ainda haveria interrupção nos objetivos de negócios se o único componente de armazenamento fosse comprometido. O clustering de failover também propõe restrições em termos de escalabilidade porque os aplicativos cliente não conseguem lidar com uma quantidade crescente de trabalho que se expande além do cluster.
Envio de registros
Outro método para obter redundância de banco de dados é por meio do envio de logs. Os logs de transações são copiados no servidor primário e enviados para um ou vários servidores secundários para serem restaurados. Ao contrário do espelhamento, os bancos de dados secundários podem ser qualificados para atividade somente leitura e a frequência de envio de logs pode ser configurada para intervalos diferentes. Há um benefício de desempenho em cenários em que os bancos de dados secundários não precisam necessariamente estar sincronizados com o banco de dados primário em tempo real.
Por exemplo, executar um relatório de resumo estatístico no final da noite para ver quais livros de psicologia são vendidos ao longo do dia não exige que o banco de dados de cópias esteja exatamente sincronizado com o banco de dados primário. A atividade de leitura intensa coloca bloqueios em objetos de banco de dados e pode aumentar os tempos de espera. Portanto, a execução de relatórios em um servidor secundário aliviaria a demanda de carga de trabalho no servidor gerador de receita primário.
A desvantagem é que o envio de logs não oferece suporte a failover automático. Portanto, se o servidor de origem falhar, o banco de dados precisará ser recuperado manualmente. Assim como o espelhamento, o envio de logs não fornece redundância de servidor e é uma solução em nível de banco de dados.
Compreendendo o AlwaysOn
As tecnologias antigas têm seus benefícios e compensações. Mas a implementação de uma solução HADR personalizada pode se tornar rapidamente complicada e exigir mais gerenciamento, pois essas diferentes estratégias são arbitrariamente misturadas e combinadas para atender às necessidades de negócios. Portanto, os recursos AlwaysOn foram introduzidos e fornecem uma versão aprimorada e já combinada de estratégias anteriores.
O SQL Server oferece dois recursos:Grupos de Disponibilidade AlwaysOn (AG) e Instâncias de Cluster de Failover AlwaysOn (FCI). Ambos exigem que o cluster de failover do Windows Server (WSFC) seja implementado.

Um AG é um grupo de bancos de dados que farão failover juntos. Você precisará de vários nós físicos redundantes com uma instância do SQL Server instalada em cada um dos nós para hospedar as réplicas de disponibilidade. Cada réplica deve estar em um nó diferente do mesmo WSFC. No esquema acima, a réplica primária está hospedada no nó 01 e todas as outras réplicas secundárias são elegíveis para failover quando o WSFC detecta que há um problema.
A maneira como as réplicas secundárias permanecem sincronizadas com a primária é enviando logs de transações e refazendo as alterações. AG oferece suporte ao modo de confirmação assíncrona e síncrona. A réplica primária está qualificada para leitura e gravação, enquanto as réplicas secundárias estão qualificadas para somente leitura. Os backups podem ser executados no local secundário.
Imediatamente, há benefícios com AlwaysOn AG. Lembre-se de que algumas das falhas do espelhamento de banco de dados são que um banco de dados só pode ser espelhado para um servidor secundário e que, quando ocorre failover, cada banco de dados é espelhado independentemente. Com o AG, os bancos de dados são redundantes em muitos lugares, como o Nó 02, Nó 03, Nó 04 e Nó 05 no exemplo acima. O suporte à disponibilidade do banco de dados permite até nove réplicas de disponibilidade.
Além disso, o envio de logs seria necessário para obter dados somente leitura no servidor secundário. Mas com AG, os dados somente leitura já são contabilizados. Atividades de leitura intensa, como relatórios, podem ser executadas em qualquer uma das réplicas secundárias. Observe também que não há uma restrição de armazenamento compartilhado.
No entanto, o AG pode ser combinado com o AlwaysOn FCI para permitir a redundância do servidor. Uma instância FCI pode ser usada para hospedar as réplicas de disponibilidade para que os objetos de nível de servidor, como logons e trabalhos de agente, também possam ser protegidos. Essa abordagem exigirá armazenamento compartilhado. No entanto, inconvenientes como ter que realizar reconfigurações para os aplicativos clientes serão eliminados.