Isso faz parte de uma série de operadores problemáticos internos do SQL Server. Certifique-se de ler a primeira postagem e a segunda postagem de Kalen sobre este tópico.
O SQL Server existe há mais de 30 anos e trabalho com o SQL Server há quase tanto tempo. Eu vi muitas mudanças ao longo dos anos (e décadas!) e versões deste produto incrível. Nestas postagens, compartilharei com você como vejo alguns dos recursos ou aspectos do SQL Server, às vezes com um pouco de perspectiva histórica.
Na última vez, falei sobre hash em um plano de consulta do SQL Server como um operador potencialmente problemático no diagnóstico do SQL Server. O hash é frequentemente usado para junções e agregação quando não há índice útil. E como as varreduras (sobre as quais falei no primeiro post desta série), há momentos em que o hash é realmente uma escolha melhor do que as alternativas. Para junções de hash, uma das alternativas é LOOP JOIN, sobre o qual também falei da última vez.
Neste post, vou falar sobre outra alternativa para hash. A maioria das alternativas ao hash requer que os dados sejam classificados, portanto, o plano precisa incluir um operador SORT ou os dados necessários já devem estar classificados devido aos índices existentes.
Diferentes tipos de junções para diagnósticos do SQL Server
Para operações JOIN, o tipo mais comum e útil de JOIN é um LOOP JOIN. Descrevi o algoritmo para um LOOP JOIN no post anterior. Embora os dados em si não precisem ser classificados para um LOOP JOIN, a presença de um índice na tabela interna torna a junção muito mais eficiente e, como você deve saber, a presença de um índice implica em alguma classificação. Enquanto um índice clusterizado classifica os dados em si, um índice não clusterizado classifica as colunas de chave de índice. Na verdade, na maioria dos casos, sem o índice, o otimizador do SQL Server optará por usar o algoritmo HASH JOIN. Vimos isso no exemplo da última vez, que sem índices, HASH JOIN foi escolhido, e com índices, obtivemos um LOOP JOIN.
O terceiro tipo de junção é um MERGE JOIN. Este algoritmo funciona em dois conjuntos de dados já ordenados. Se estivermos tentando combinar (ou JOIN) dois conjuntos de dados que já estão classificados, basta uma única passagem por cada conjunto para encontrar as linhas correspondentes. Aqui está o pseudocódigo para o algoritmo de junção de mesclagem:
get first row R1 from input 1 get first row R2 from input 2 while not at the end of either input begin if R1 joins with R2 begin output (R1, R2) get next row R2 from input 2 end else if R1 < R2 get next row R1 from input 1 else get next row R2 from input 2 end Embora MERGE JOIN seja um algoritmo muito eficiente, ele exige que ambos os conjuntos de dados de entrada sejam classificados pela chave de junção, o que geralmente significa ter um índice clusterizado na chave de junção para ambas as tabelas. Como você obtém apenas um índice clusterizado por tabela, escolher a coluna de chave clusterizada apenas para permitir que MERGE JOINS aconteça pode não ser a melhor escolha geral para chave de cluster.
Então, geralmente, eu não recomendo que você tente construir índices apenas para fins de MERGE JOINS, mas se você acabar obtendo um MERGE JOIN devido a índices já existentes, geralmente é uma coisa boa. Além de exigir que ambos os conjuntos de dados de entrada sejam classificados, MERGE JOIN também exige que pelo menos um dos conjuntos de dados tenha valores exclusivos para a chave de junção.
Vejamos um exemplo. Primeiro, recriaremos os Cabeçalhos e Detalhes tabelas:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Em seguida, observe o plano para uma junção entre essas tabelas:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Aqui está o plano:

Observe que, mesmo com um índice clusterizado em ambas as tabelas, obtemos um HASH JOIN. Podemos reconstruir um dos índices para ser UNIQUE. Nesse caso, deve ser o índice nos Cabeçalhos table, porque essa é a única que tem valores exclusivos para SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Agora, execute a consulta novamente e observe que o plano faz como um MERGE JOIN.

Esses planos se beneficiam de ter os dados já classificados em um índice, pois o plano de execução pode aproveitar a classificação. Mas, às vezes, o SQL Server precisa classificar como parte de sua execução de consulta. Ocasionalmente, você pode ver um operador SORT aparecer em um plano, mesmo que não solicite uma saída classificada. Se o SQL Server achar que um MERGE JOIN pode ser uma boa opção, mas uma das tabelas não possui o índice clusterizado apropriado e é pequeno o suficiente para tornar a classificação muito barata, um SORT pode ser executado para permitir que MERGE JOIN seja usado.
Mas geralmente, o operador SORT aparece em consultas em que solicitamos dados classificados com ORDER BY, como no exemplo a seguir.
SELECT * FROM Details
ORDER BY ProductID;
GO

O índice clusterizado é verificado (que é o mesmo que verificar a tabela) e, em seguida, as linhas são classificadas conforme solicitado.
Lidando com o índice agrupado já classificado
Mas e se os dados já estiverem classificados em um índice clusterizado e a consulta incluir um ORDER BY na coluna de chave clusterizada? No exemplo acima, criamos um índice clusterizado em SalesOrderID na tabela Details. Observe as duas consultas a seguir:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Se executarmos essas consultas juntas, a janela de análise do pacote de ajuste do Quest Spotlight indica que os dois planos têm o mesmo custo; cada um é 50% do total. Então, qual é realmente a diferença entre eles?
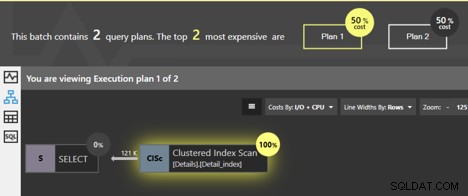
Ambas as consultas estão verificando o índice clusterizado e o SQL Server sabe que, se as páginas do nível folha forem seguidas em ordem, os dados retornarão na ordem das chaves clusterizadas. Nenhuma classificação adicional precisa ser feita, portanto, nenhum operador SORT é adicionado ao plano. Mas há uma diferença. Podemos clicar no operador Clustered Index Scan e obteremos algumas informações detalhadas.
Primeiro, veja as informações detalhadas do primeiro plano, da consulta sem ORDER BY.

Os detalhes nos dizem que a propriedade “Ordered” é False. Não há nenhuma exigência aqui de que os dados sejam retornados em ordem de classificação. Acontece que na maioria dos casos, a forma mais fácil de recuperar os dados é seguir as páginas do índice clusterizado, assim os dados acabarão sendo retornados em ordem, mas não há garantia. O que a propriedade False significa é que não é necessário que o SQL Server siga as páginas ordenadas para retornar o resultado. Na verdade, existem outras maneiras pelas quais o SQL Server pode obter todas as linhas da tabela, sem seguir o índice clusterizado. Se durante a execução, o SQL Server optar por usar um método diferente para obter as linhas, não veremos os resultados ordenados.
Para a segunda consulta, os detalhes são assim:
 Como a consulta incluiu um ORDER BY, há um requisito de que os dados sejam retornados em ordem ordenada e SQL Server seguirá as páginas do índice clusterizado, em ordem.
Como a consulta incluiu um ORDER BY, há um requisito de que os dados sejam retornados em ordem ordenada e SQL Server seguirá as páginas do índice clusterizado, em ordem.
A coisa mais importante a lembrar aqui é que NÃO há garantia de dados classificados se você não incluir ORDER BY em sua consulta. Só porque você tem um índice clusterizado, ainda não há garantia! Mesmo que todas as vezes no ano passado em que você executou a consulta, você tenha os dados em ordem sem o ORDER BY, não há garantia de que você continuará a recuperar os dados em ordem. Usar ORDER BY é a única maneira de garantir a ordem em que seus resultados são retornados.
Dicas para usar as operações de classificação
Então, um SORT é uma operação a ser evitada no diagnóstico do SQL Server? Assim como varreduras e operações de hash, a resposta é, claro, ‘depende’. A classificação pode ser muito cara, especialmente em grandes conjuntos de dados. A indexação adequada ajuda o SQL Server a evitar a execução de operações SORT porque um índice basicamente significa que seus dados são pré-classificados. Mas a indexação tem um custo. Há custo de armazenamento, além do custo de manutenção, para cada índice. Se seus dados estiverem muito atualizados, você precisará manter o número de índices no mínimo.
Se você achar que algumas de suas consultas de execução lenta mostram operações SORT em seus planos e se esses SORTs estiverem entre os operadores mais caros do plano, considere a criação de índices que permitem que o SQL Server evite a classificação. Mas você precisará fazer testes completos para garantir que os índices adicionais não diminuam a velocidade de outras consultas que são cruciais para o desempenho geral do aplicativo.