A concatenação de dois ou mais conjuntos de dados é mais comumente expressa em T-SQL usando o
UNION ALL cláusula. Dado que o otimizador do SQL Server geralmente pode reordenar coisas como junções e agregações para melhorar o desempenho, é bastante razoável esperar que o SQL Server também considere reordenar as entradas de concatenação, onde isso forneceria uma vantagem. Por exemplo, o otimizador pode considerar os benefícios de reescrever A UNION ALL B como B UNION ALL A . Na verdade, o otimizador do SQL Server não faça isso. Mais precisamente, havia algum suporte limitado para reordenação de entrada de concatenação nas versões do SQL Server até 2008 R2, mas isso foi removido no SQL Server 2012 e não ressurgiu desde então.
SQL Server 2008 R2
Intuitivamente, a ordem das entradas de concatenação só importa se houver uma meta de linha . Por padrão, o SQL Server otimiza os planos de execução com base em que todas as linhas qualificadas serão retornadas ao cliente. Quando uma meta de linha está em vigor, o otimizador tenta encontrar um plano de execução que produza as primeiras linhas rapidamente.
As metas de linha podem ser definidas de várias maneiras, por exemplo, usando
TOP , um FAST n dica de consulta ou usando EXISTS (que por sua natureza precisa encontrar no máximo uma linha). Onde não há meta de linha (ou seja, o cliente requer todas as linhas), geralmente não importa em qual ordem as entradas de concatenação são lidas:Cada entrada será totalmente processada eventualmente em qualquer caso. O suporte limitado em versões até o SQL Server 2008 R2 se aplica onde há uma meta de exatamente uma linha . Nessa circunstância específica, o SQL Server reordenará as entradas de concatenação com base no custo esperado.
Isso não é feito durante a otimização baseada em custo (como se poderia esperar), mas sim como uma reescrita pós-otimização de última hora da saída normal do otimizador. Esse arranjo tem a vantagem de não aumentar o espaço de busca de planos baseado em custo (potencialmente uma alternativa para cada reordenamento possível), enquanto ainda produz um plano que é otimizado para retornar a primeira linha rapidamente.
Exemplos
Os exemplos a seguir usam duas tabelas com conteúdo idêntico:Um milhão de linhas de inteiros de um a um milhão. Uma tabela é um heap sem índices não clusterizados; o outro tem um índice clusterizado exclusivo:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Sem meta de linha
A consulta a seguir procura as mesmas linhas em cada tabela e retorna a concatenação dos dois conjuntos:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; O plano de execução produzido pelo otimizador de consultas é:
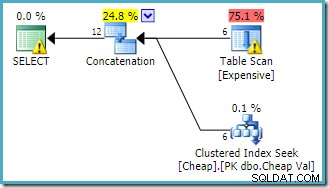
O aviso na raiz
SELECT O operador está nos alertando sobre o óbvio índice ausente na tabela de heap. O aviso no operador Table Scan é adicionado pelo Sentry One Plan Explorer. Está chamando nossa atenção para o custo de E/S do predicado residual oculto na varredura. A ordem das entradas para a Concatenação não importa aqui, porque não definimos uma meta de linha. Ambas as entradas serão totalmente lidas para retornar todas as linhas de resultados. De interesse (embora isso não seja garantido) observe que a ordem das entradas segue a ordem textual da consulta original. Observe também que a ordem das linhas do resultado final também não é especificada, pois não usamos um
ORDER BY de nível superior cláusula. Assumiremos que é deliberado e que a ordenação final é irrelevante para a tarefa em mãos. Se invertermos a ordem escrita das tabelas na consulta assim:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; O plano de execução segue a mudança, acessando primeiro a tabela clusterizada (novamente, isso não é garantido):
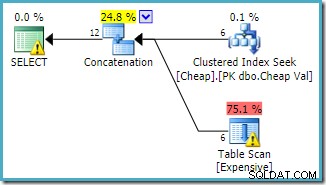
Espera-se que ambas as consultas tenham as mesmas características de desempenho, pois realizam as mesmas operações, apenas em uma ordem diferente.
Com uma meta de linha
Claramente, a falta de indexação na tabela de heap normalmente tornará a localização de linhas específicas mais cara, em comparação com a mesma operação na tabela em cluster. Se pedirmos ao otimizador um plano que retorne a primeira linha rapidamente, esperaríamos que o SQL Server reordenasse as entradas de concatenação para que a tabela clusterizada barata fosse consultada primeiro.
Usando a consulta que menciona a tabela de heap primeiro e uma dica de consulta FAST 1 para especificar a meta da linha:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); O plano de execução estimado produzido em uma instância do SQL Server 2008 R2 é:
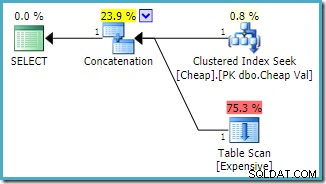
Observe que as entradas de concatenação foram reordenadas para reduzir o custo estimado de retorno da primeira linha. Observe também que os avisos de índice ausente e de E/S residual desapareceram. Nenhum problema é importante com esta forma de plano quando o objetivo é retornar uma única linha o mais rápido possível.
A mesma consulta executada no SQL Server 2016 (usando qualquer modelo de estimativa de cardinalidade) é:
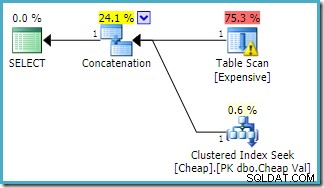
O SQL Server 2016 não reordenou as entradas de concatenação. O aviso de E/S do Plan Explorer retornou, mas infelizmente o otimizador não produziu um aviso de índice ausente desta vez (embora seja relevante).
Reordenação geral
Conforme mencionado, a reescrita pós-otimização que reordena as entradas de concatenação só é efetiva para:
- SQL Server 2008 R2 e versões anteriores
- Uma meta de linha de exatamente uma
Se realmente quisermos apenas uma linha retornada, em vez de um plano otimizado para retornar a primeira linha rapidamente (mas que ainda retornará todas as linhas), podemos usar um
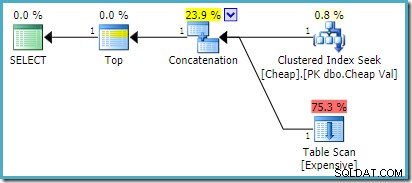
TOP cláusula com uma tabela derivada ou expressão de tabela comum (CTE):SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; No SQL Server 2008 R2 ou anterior, isso produz o plano de entrada reordenada ideal:
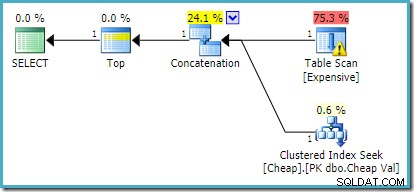
No SQL Server 2012, 2014 e 2016 não ocorre reordenação pós-otimização:
Se quisermos que mais de uma linha seja retornada, por exemplo, usando
TOP (2) , a reescrita desejada não será aplicada no SQL Server 2008 R2 mesmo se um FAST 1 dica também é usada. Nessa situação, precisamos recorrer a truques como usar TOP com uma variável e um OPTIMIZE FOR dica:DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint A dica de consulta é suficiente para definir uma meta de linha de um, enquanto o valor de tempo de execução da variável garante que o número desejado de linhas (2) seja retornado.
O plano de execução real no SQL Server 2008 R2 é:
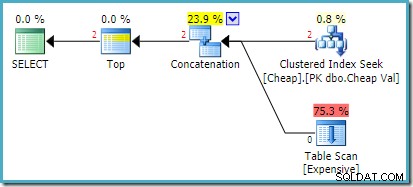
Ambas as linhas retornadas vêm da entrada de busca reordenada e o Table Scan não é executado. O Plan Explorer mostra as contagens de linhas em vermelho porque a estimativa era para uma linha (devido à dica), enquanto duas linhas foram encontradas em tempo de execução.
Sem UNIÃO TODOS
Esse problema também não se limita a consultas escritas explicitamente com
UNION ALL . Outras construções como EXISTS e OR também pode resultar na introdução de um operador de concatenação pelo otimizador, que pode sofrer com a falta de reordenação de entrada. Houve uma pergunta recente no Database Administrators Stack Exchange exatamente com esse problema. Transformando a consulta dessa pergunta para usar nossas tabelas de exemplo:SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; O plano de execução no SQL Server 2016 tem a tabela de heap na primeira entrada:
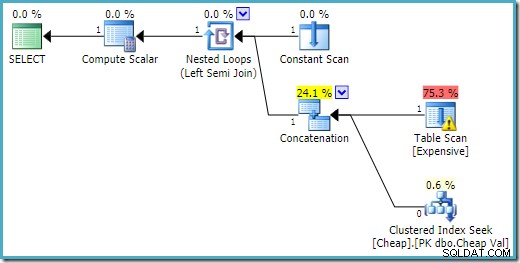
No SQL Server 2008 R2, a ordem das entradas é otimizada para refletir a meta de linha única da semijunção:
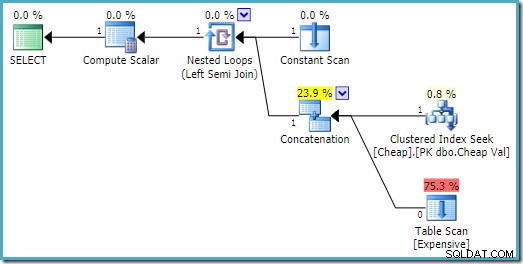
No plano mais ideal, a varredura de heap nunca é executada.
Soluções alternativas
Em alguns casos, será evidente para o escritor de consultas que uma das entradas de concatenação sempre será mais barata de executar do que as outras. Se isso for verdade, é bastante válido reescrever a consulta para que as entradas de concatenação mais baratas apareçam primeiro na ordem escrita. É claro que isso significa que o criador de consultas precisa estar ciente dessa limitação do otimizador e preparado para confiar no comportamento não documentado.
Uma questão mais difícil surge quando o custo das entradas de concatenação varia com as circunstâncias, talvez dependendo dos valores dos parâmetros. Usando
OPTION (RECOMPILE) não ajudará no SQL Server 2012 ou posterior. Essa opção pode ajudar no SQL Server 2008 R2 ou anterior, mas somente se o requisito de meta de linha única também for atendido. Se houver preocupações sobre confiar no comportamento observado (entradas de concatenação do plano de consulta que correspondem à ordem textual da consulta), um guia de plano pode ser usado para forçar a forma do plano. Onde diferentes ordens de entrada são ideais para diferentes circunstâncias, vários guias de plano podem ser usados, onde as condições podem ser codificadas com precisão com antecedência. Isso dificilmente é o ideal.
Considerações finais
O otimizador de consulta do SQL Server contém, de fato, um baseado em custo regra de exploração,
UNIAReorderInputs , que é capaz de gerar variações de ordem de entrada de concatenação e explorar alternativas durante a otimização baseada em custo (não como uma reescrita pós-otimização de disparo único). Esta regra não está atualmente habilitada para uso geral. Até onde eu sei, ele só é ativado quando um guia de plano ou
USE PLAN dica está presente. Isso permite que o mecanismo force com êxito um plano que foi gerado para uma consulta qualificada para a reescrita de reordenação de entrada, mesmo quando a consulta atual não se qualifica. Minha sensação é que essa regra de exploração é deliberadamente limitada a esse uso, porque as consultas que se beneficiariam da reordenação de entrada de concatenação como parte da otimização baseada em custo não são consideradas suficientemente comuns, ou talvez porque há uma preocupação de que o esforço extra não compensaria fora. Minha opinião é que a reordenação de entrada do operador de concatenação deve sempre ser explorada quando uma meta de linha está em vigor.
Também é uma pena que a reescrita de pós-otimização (mais limitada) não seja eficaz no SQL Server 2012 ou posterior. Isso pode ter ocorrido devido a um bug sutil, mas não consegui encontrar nada sobre isso na documentação, base de conhecimento ou no Connect. Adicionei um novo item do Connect aqui.
Atualização em 9 de agosto de 2017 :Isso agora está consertado no sinalizador de rastreamento 4199 para SQL Server 2014 e 2016, consulte KB 4023419:
CORREÇÃO:a consulta com UNION ALL e uma meta de linha pode ser executada mais lentamente no SQL Server 2014 ou versões posteriores quando comparada ao SQL Server 2008 R2